AWS Big Data Blog
Tag: Amazon Redshift

Amazon Redshift Engineering’s Advanced Table Design Playbook: Preamble, Prerequisites, and Prioritization
Part 1: Preamble, Prerequisites, and Prioritization (Translated into Japanese) Part 2: Distribution Styles and Distribution Keys Part 3: Compound and Interleaved Sort Keys Part 4: Compression Encodings Part 5: Table Data Durability Amazon Redshift is a fully managed, petabyte scale, massively parallel data warehouse that offers simple operations and high performance. AWS customers use Amazon […]

Using pgpool and Amazon ElastiCache for Query Caching with Amazon Redshift
In this blog post, we’ll use a real customer scenario to show you how to create a caching layer in front of Amazon Redshift using pgpool and Amazon ElastiCache.
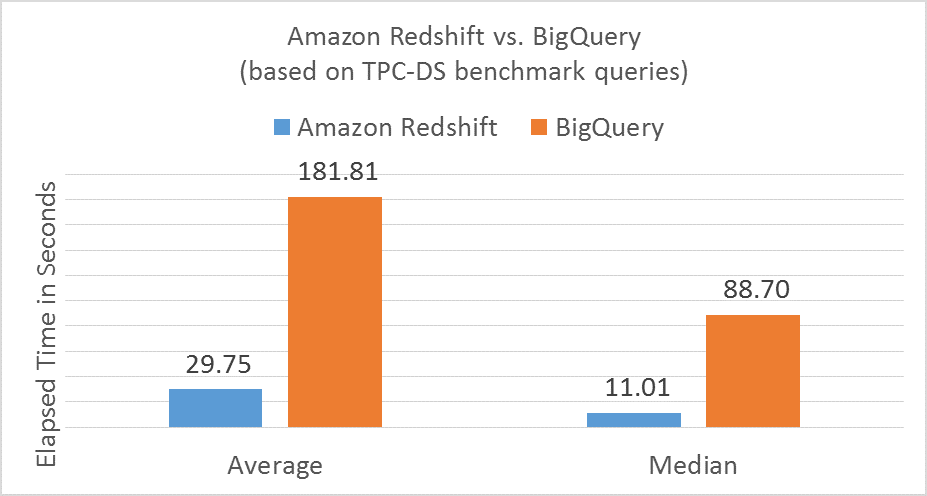
Fact or Fiction: Google BigQuery Outperforms Amazon Redshift as an Enterprise Data Warehouse?
Publishing misleading performance benchmarks is a classic old guard marketing tactic. It’s not surprising to see old guard companies (like Oracle) doing this, but we were kind of surprised to see Google take this approach, too. So, when Google presented their BigQuery vs. Amazon Redshift benchmark results at a private event in San Francisco on September 29, 2016, it piqued our interest and we decided to dig deeper.

Simplify Management of Amazon Redshift Snapshots using AWS Lambda
NOTE: Amazon Redshift now supports creating an automatic snapshot schedule using the snapshot scheduler. For more information, please review this “What’s New” post. ———————————- Ian Meyers is a Solutions Architecture Senior Manager with AWS Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse that makes it simple and cost-effective to analyze all your data […]

JOIN Amazon Redshift AND Amazon RDS PostgreSQL WITH dblink
Tony Gibbs is a Solutions Architect with AWS (Update: This blog post has been translated into Japanese) When it comes to choosing a SQL-based database in AWS, there are many options. Sometimes it can be difficult to know which one to choose. For example, when would you use Amazon Aurora instead of Amazon RDS PostgreSQL […]

Real-time in-memory OLTP and Analytics with Apache Ignite on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Babu Elumalai is a Solutions Architect with AWS Organizations are generating tremendous amounts of data, and they increasingly need tools and systems that help them use this data to make decisions. The […]

Encrypt Your Amazon Redshift Loads with Amazon S3 and AWS KMS
Russell Nash is a Solutions Architect with AWS Have you been looking for a straightforward way to encrypt your Amazon Redshift data loads? Have you wondered how to safely manage the keys and where to perform the encryption? In this post, I will walk through a solution that meets these requirements by showing you how […]

Amazon Redshift UDF repository on AWSLabs
Christopher Crosbie is a Healthcare and Life Science Solutions Architect with Amazon Web Services Zach Christopherson, an Amazon Redshift Database Engineer, contributed to this post Did you ever have a need for complex string parsing in Amazon Redshift and wish you could simply add f_parse_url_query_string(url) to your SQL query? Have you ever tried to weigh which would be less […]

Agile Analytics with Amazon Redshift
Nick Corbett is a Big Data Consultant for AWS Professional Services What makes outstanding business intelligence (BI)? It needs to be accurate and up-to-date, but this alone won’t differentiate a solution. Perhaps a better measure is to consider the reaction you get when your latest report or metric is released to the business. Good BI […]

Query Routing and Rewrite: Introducing pgbouncer-rr for Amazon Redshift and PostgreSQL
This post was last reviewed and updated August, 2022 with a section on Deploying pgbouncer in Elastic Kubernetes Service (EKS). NOTE: You can now use federated queries in Amazon Redshift to query and analyze data across operational databases, data warehouses, and data lakes. For more information, please review the Amazon Redshift documentation article, “Querying Data […]