AWS Big Data Blog
Use the default IAM role in Amazon Redshift to simplify accessing other AWS services
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse, and can expand to petabyte scale. Today, tens of thousands of AWS customers use Amazon Redshift to run mission-critical business intelligence dashboards, analyze real-time streaming data, and run predictive analytics jobs.
Many features in Amazon Redshift access other services, for example, when loading data from Amazon Simple Storage Service (Amazon S3). This requires you to create an AWS Identity and Access Management (IAM) role and grant that role to the Amazon Redshift cluster. Historically, this has required some degree of expertise to set up access configuration with other AWS services. For details about IAM roles and how to use them, see Create an IAM role for Amazon Redshift.
This post discusses the introduction of the default IAM role, which simplifies the use of other services such as Amazon S3, Amazon SageMaker, AWS Lambda, Amazon Aurora, and AWS Glue by allowing you to create an IAM role from the Amazon Redshift console and assign it as the default IAM role to new or existing Amazon Redshift cluster. The default IAM role simplifies SQL operations that access other AWS services (such as COPY, UNLOAD, CREATE EXTERNAL FUNCTION, CREATE EXTERNAL SCHEMA, CREATE MODEL, or CREATE LIBRARY) by eliminating the need to specify the Amazon Resource Name (ARN) for the IAM role.
Overview of solution
The Amazon Redshift SQL commands for COPY, UNLOAD, CREATE EXTERNAL FUNCTION, CREATE EXTERNAL TABLE, CREATE EXTERNAL SCHEMA, CREATE MODEL, or CREATE LIBRARY historically require the role ARN to be passed as an argument. Usually, these roles and accesses are set up by admin users. Most data analysts and data engineers using these commands aren’t authorized to view cluster authentication details. To eliminate the need to specify the ARN for the IAM role, Amazon Redshift now provides a new managed IAM policy AmazonRedshiftAllCommandsFullAccess, which has required privileges to use other related services such as Amazon S3, SageMaker, Lambda, Aurora, and AWS Glue. This policy is used for creating the default IAM role via the Amazon Redshift console. End-users can use the default IAM role by specifying IAM_ROLE with the DEFAULT keyword. When you use the Amazon Redshift console to create IAM roles, Amazon Redshift keeps track of all IAM roles created and preselects the most recent default role for all new cluster creations and restores from snapshots.
The Amazon Redshift default IAM role simplifies authentication and authorization with the following benefits:
- It allows users to run SQL commands without providing the IAM role’s ARN
- It avoids the need to use multiple AWS Management Console pages to create the Amazon Redshift cluster and IAM role
- You don’t need to reconfigure default IAM roles every time Amazon Redshift introduces a new feature, which requires additional permission, because Amazon Redshift can modify or extend the AWS managed policy, which is attached to the default IAM role, as required
To demonstrate this, first we create an IAM role through the Amazon Redshift console that has a policy with permissions to run SQL commands such as COPY, UNLOAD, CREATE EXTERNAL FUNCTION, CREATE EXTERNAL TABLE, CREATE EXTERNAL SCHEMA, CREATE MODEL, or CREATE LIBRARY. We also demonstrate how to make an existing IAM role the default role, and remove a role as default. Then we show you how to use the default role with various SQL commands, and how to restrict access to the role.
Create a new cluster and set up the IAM default role
The default IAM role is supported in both Amazon Redshift clusters and Amazon Redshift Serverless (preview). To create a new cluster and configure our IAM role as the default role, complete the following steps:
- On the Amazon Redshift console, choose Clusters in the navigation pane.
This page lists the clusters in your account in the current Region. A subset of properties of each cluster is also displayed.
- Choose Create cluster.
- Follow the instructions to enter the properties for cluster configuration.
- If you know the required size of your cluster (that is, the node type and number of nodes), choose I’ll choose.
- Choose the node type and number of nodes.
If you don’t know how large to size your cluster, choose Help me choose. Doing this starts a sizing calculator that asks you questions about the size and query characteristics of the data that you plan to store in your data warehouse.
- Follow the instructions to enter properties for database configurations.
- Under Associated IAM roles, on the Manage IAM roles menu, choose Create IAM role.
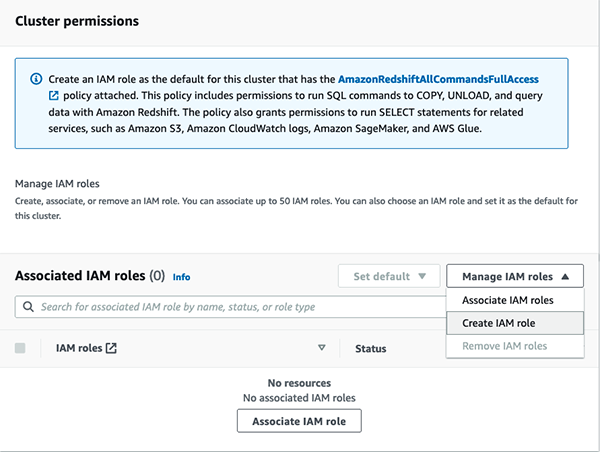
- To specify an S3 bucket for the IAM role to access, choose one of the following methods:
- Choose No additional S3 bucket to create the IAM role without specifying specific S3 buckets.
- Choose Any S3 bucket to allow users that have access to your Amazon Redshift cluster to also access any S3 bucket and its contents in your AWS account.
- Choose Specific S3 buckets to specify one or more S3 buckets that the IAM role being created has permission to access. Then choose one or more S3 buckets from the table.
- Choose Create IAM role as default.

Amazon Redshift automatically creates and sets the IAM role as the default for your cluster.

- Choose Create cluster to create the cluster.
The cluster might take several minutes to be ready to use. You can verify the new default IAM role under Cluster permissions.

You can only have one IAM role set as the default for the cluster. If you attempt to create another IAM role as the default for the cluster when an existing IAM role is currently assigned as the default, the new IAM role replaces the other IAM role as default.
Make an existing IAM role the default for your new or existing cluster
You can also attach your existing role to the cluster and make it default IAM role for more granular control of permissions with customized managed polices.
- On the Amazon Redshift console, choose Clusters in the navigation pane.
- Choose the cluster you want to associate IAM roles with.
- Under Associated IAM roles, on the Manage IAM roles menu, choose Associated IAM roles.
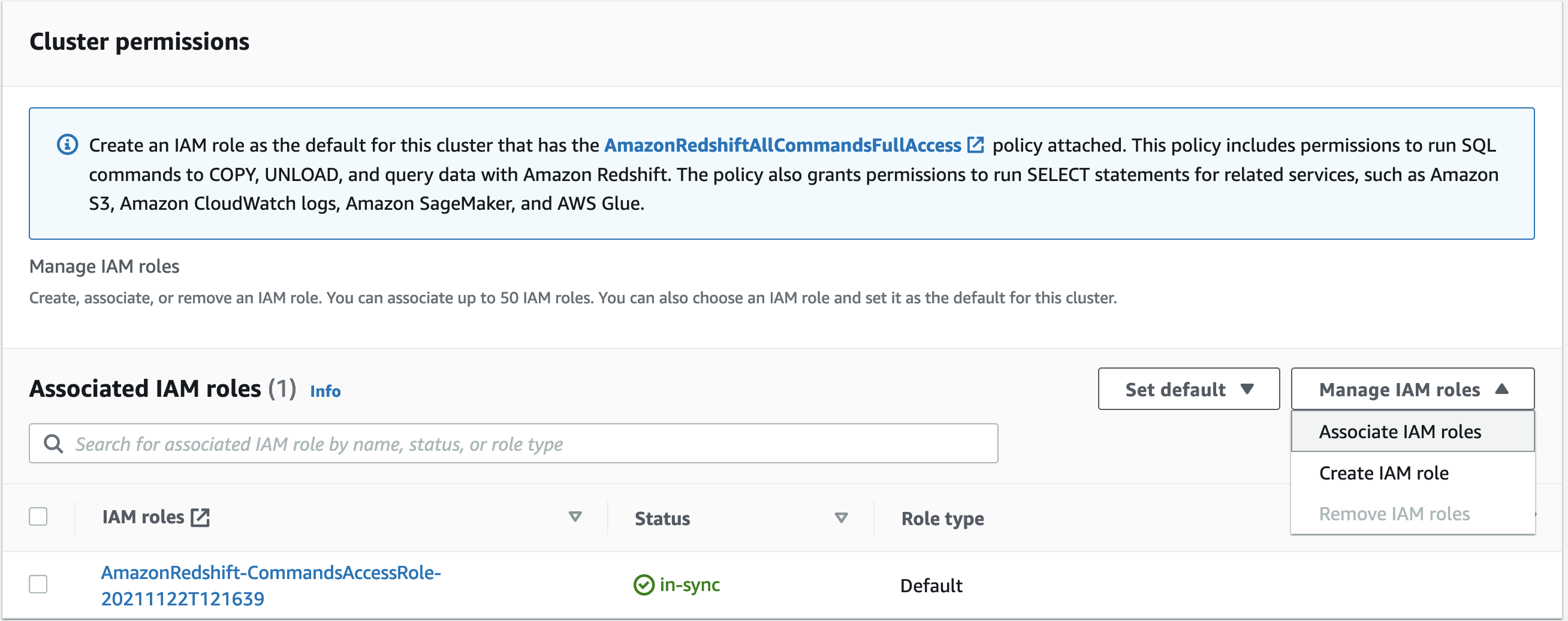
- Select an IAM role that you want make the default for the cluster.
- Choose Associate IAM roles.

- Under Associated IAM roles, on the Set default menu, choose Make default.

- When prompted, choose Set default to confirm making the specified IAM role the default.
- Choose Confirm.

Your IAM role is now listed as default.

Make an IAM role no longer default for your cluster
You can make an IAM role no longer the default role by changing the cluster permissions.
- On the Amazon Redshift console, choose Clusters in the navigation pane.
- Choose the cluster that you want to associate IAM roles with.
- Under Associated IAM roles, select the default IAM role.
- On the Set default menu, choose Clear default.

- When prompted, choose Clear default to confirm.
Use the default IAM role to run SQL commands
Now we demonstrate how to use the default IAM role in SQL commands like COPY, UNLOAD, CREATE EXTERNAL FUNCTION, CREATE EXTERNAL TABLE, CREATE EXTERNAL SCHEMA, and CREATE MODEL using Amazon Redshift ML.
To run SQL commands, we use Amazon Redshift Query Editor V2, a web-based tool that you can use to explore, analyze, share, and collaborate on data stored on Amazon Redshift. It supports data warehouses on Amazon Redshift and data lakes through Amazon Redshift Spectrum. However, you can use the default IAM role with any tools of your choice.
For additional information, see Introducing Amazon Redshift Query Editor V2, a Free Web-based Query Authoring Tool for Data Analysts.
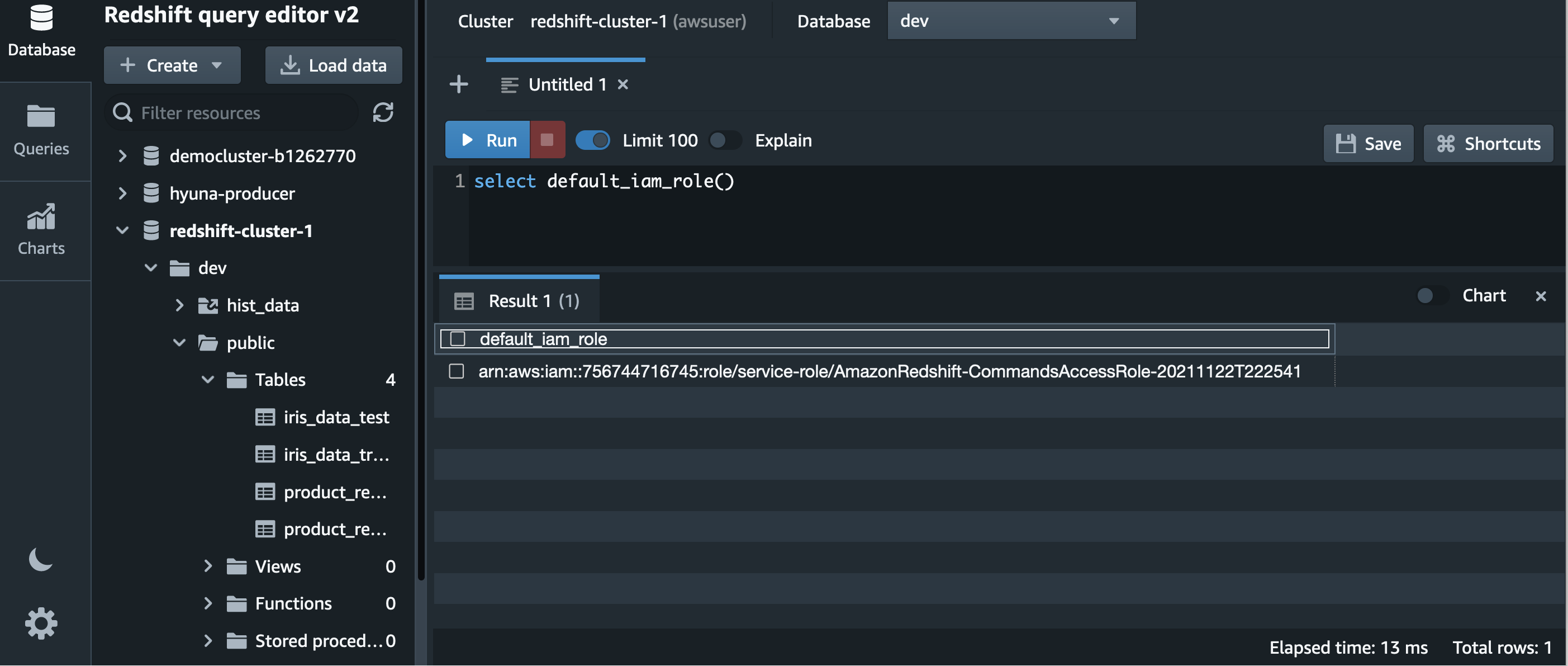
First verify the cluster is using the default IAM role, as shown in the following screenshot.
Load data from Amazon S3
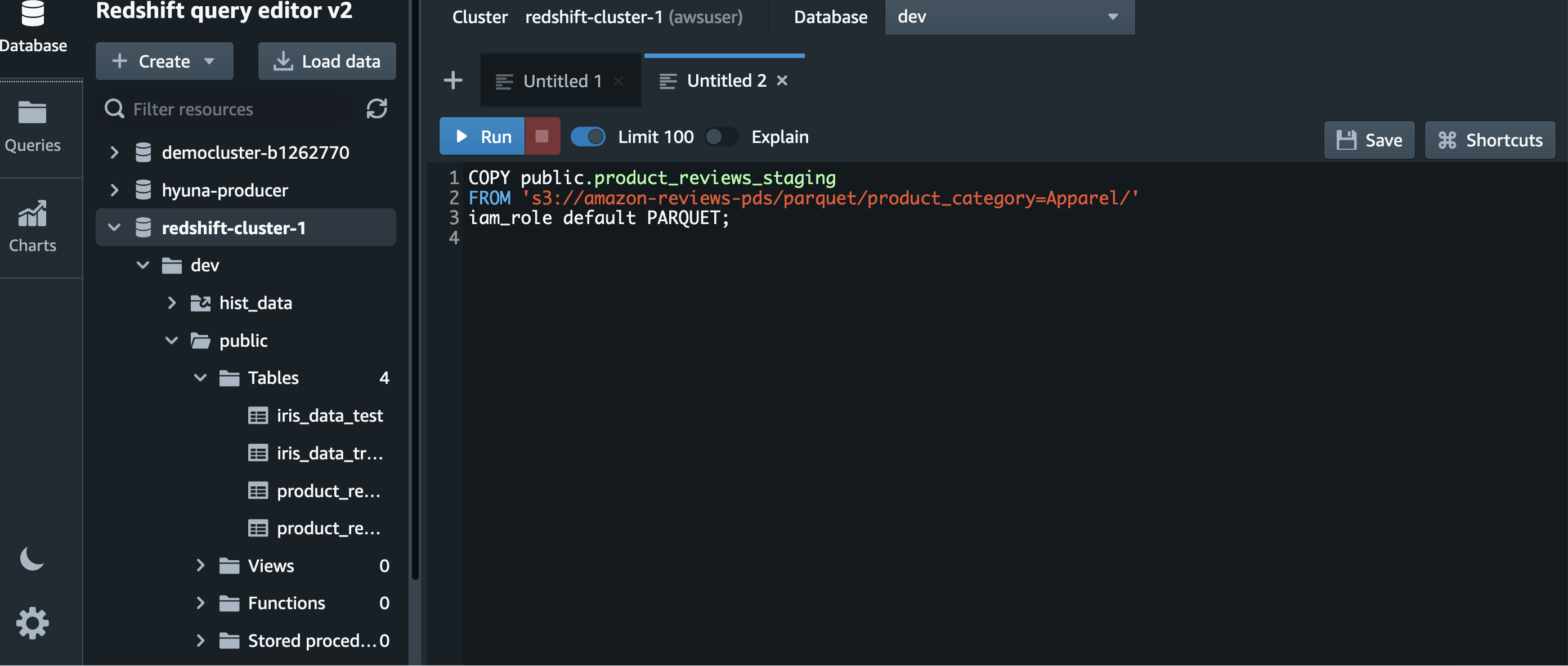
The SQL in the following screenshot describes how to load data from Amazon S3 using the default IAM role.
Unload data to Amazon S3
With an Amazon Redshift lake house architecture, you can query data in your data lake and write data back to your data lake in open formats using the UNLOAD command. After the data files are in Amazon S3, you can share the data with other services for further processing.
The SQL in the following screenshot describes how to unload data to Amazon S3 using the default IAM role.

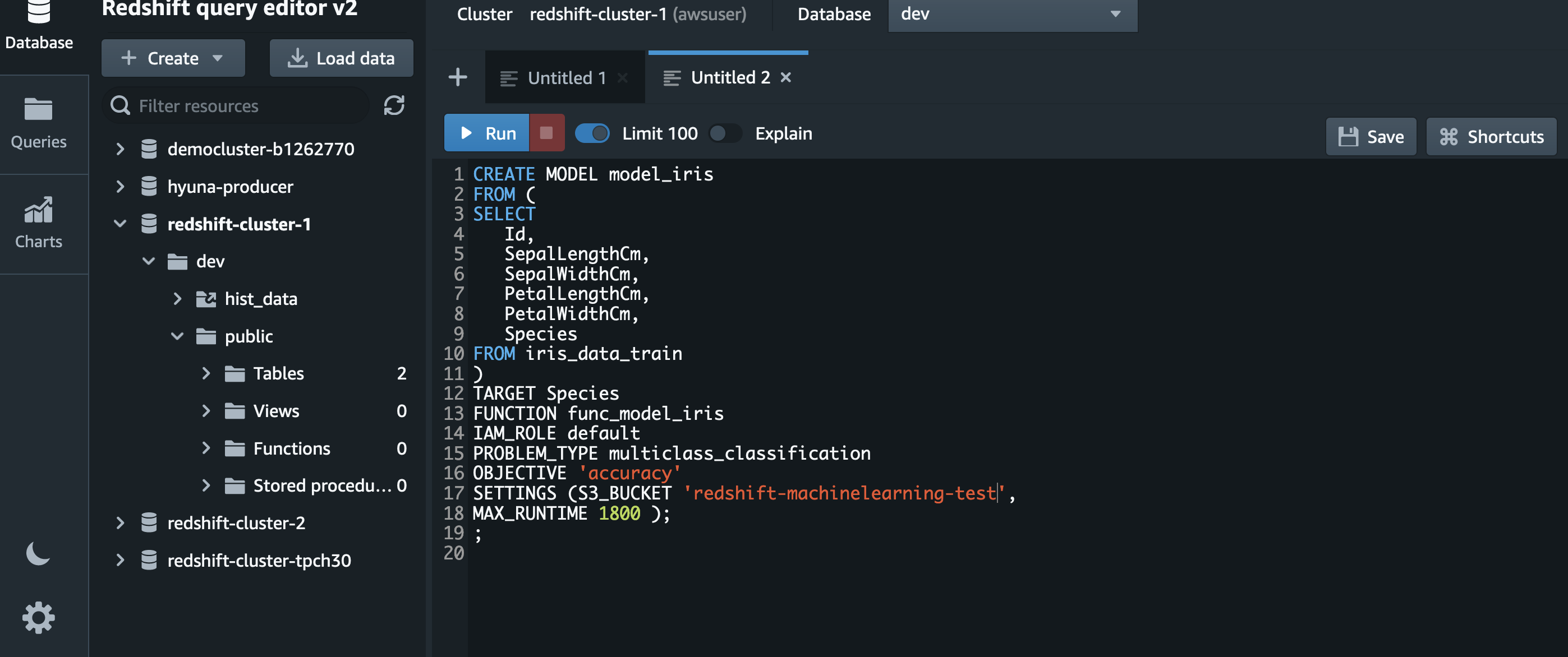
Create an ML model
Redshift ML enables SQL users to create, train, and deploy machine learning (ML) models using familiar SQL commands. The SQL in the following screenshot describes how to build an ML model using the default IAM role. We use the Iris dataset from the UCI Machine Learning Repository.
Create an external schema and external table
Redshift Spectrum is a feature of Amazon Redshift that allows you to perform SQL queries on data stored in S3 buckets using external schema and external tables. This eliminates the need to move data from a storage service to a database, and instead directly queries data inside an S3 bucket. Redshift Spectrum also expands the scope of a given query because it extends beyond a user’s existing Amazon Redshift data warehouse nodes and into large volumes of unstructured S3 data lakes.
The following SQL describes how to use the default IAM role in the CREATE EXTERNAL SCHEMA command. For more information, see Querying external data using Amazon Redshift Spectrum
The default IAM role requires redshift as part of the catalog database name or resources tagged with the Amazon Redshift service tag due to security considerations. You can customize the policy attached to default role as per your security requirement. In the following example, we use the AWS Glue Data Catalog name redshift_data.

Restrict access to the default IAM role
To control access privileges of the IAM role created and set it as default for your Amazon Redshift cluster, use the ASSUMEROLE privilege. This access control applies to database users and groups when they run commands such as COPY and UNLOAD. After you grant the ASSUMEROLE privilege to a user or group for the IAM role, the user or group can assume that role when running these commands. With the ASSUMEROLE privilege, you can grant access to the appropriate commands as required.

Best practices
Amazon Redshift uses the AWS security frameworks to implement industry-leading security in the areas of authentication, access control, auditing, logging, compliance, data protection, and network security. For more information, refer to Security in Amazon Redshift and Security best practices in IAM.
Conclusion
This post showed you how the default IAM role simplifies SQL operations that access other AWS services by eliminating the need to specify the ARN for the IAM role. This new functionality helps make Amazon Redshift easier than ever to use, and reduces reliance on an administrator to wrangle these permissions.
As an administrator, you can start using the default IAM role to grant IAM permissions to your Redshift cluster and allow your end-users such as data analysts and developers to use default IAM role with their SQL commands without having to provide the ARN for the IAM role.
About the Authors
 Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
 Evgenii Rublev is a Software Development Engineer on the AWS Redshift team. He has worked on building end-to-end applications for over 10 years. He is passionate about innovations in building high-availability and high-performance applications to drive a better customer experience. Outside of work, Evgenii enjoys spending time with his family, traveling, and reading books.
Evgenii Rublev is a Software Development Engineer on the AWS Redshift team. He has worked on building end-to-end applications for over 10 years. He is passionate about innovations in building high-availability and high-performance applications to drive a better customer experience. Outside of work, Evgenii enjoys spending time with his family, traveling, and reading books.
 Debu Panda, a Principal Product Manager at AWS, is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world. Debu has published numerous articles on analytics, enterprise Java, and databases and has presented at multiple conferences such as re:Invent, Oracle Open World, and Java One. He is lead author of the EJB 3 in Action (Manning Publications 2007, 2014) and Middleware Management (Packt).
Debu Panda, a Principal Product Manager at AWS, is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world. Debu has published numerous articles on analytics, enterprise Java, and databases and has presented at multiple conferences such as re:Invent, Oracle Open World, and Java One. He is lead author of the EJB 3 in Action (Manning Publications 2007, 2014) and Middleware Management (Packt).