AWS Big Data Blog
Visualize MongoDB data from Amazon QuickSight using Amazon Athena Federated Query
In this post, you will learn how to use Amazon Athena Federated Query to connect a MongoDB database to Amazon QuickSight in order to build dashboards and visualizations.
Amazon Athena is a serverless interactive query service, based on Presto, that provides full ANSI SQL support to query a variety of standard data formats, including CSV, JSON, ORC, Avro, and Parquet, that are stored on Amazon Simple Storage Service (Amazon S3). For data that isn’t stored on Amazon S3, you can use Athena Federated Query to query the data in place or build pipelines that extract data from multiple data sources and store it in Amazon S3. With Athena Federated Query, you can run SQL queries across data that is stored in relational, non-relational, object, and custom data sources.
MongoDB is a popular NoSQL database option for websites and API endpoints. You can choose to deploy MongoDB as a self-hosted or fully-managed database. Databases are a popular choice for UI applications for managing user profiles, product catalogs, profile views, clickstream events, events from a connected device, and so on. QuickSight is a serverless business analytics service with built-in machine learning (ML) capabilities that can automatically look for patterns and outliers, and has the flexibility to embed dashboards in applications for a data-driven experience. You can also use QuickSight Q to allow users to ask questions using natural language and find answers to business questions immediately.
Overview of Athena Federated Query
Athena Federated Query uses data source connectors that run on AWS Lambda to run federated queries to other data sources. Prebuilt data source connectors are available for native stores, like Amazon Timestream, Amazon CloudWatch Logs, Amazon DynamoDB, and external sources like Vertica and SAP Hana. You can also write a connector by using the Athena Query Federation SDK. You can customize Athena’s prebuilt connectors for your own use, or modify a copy of the source code to create your own AWS Serverless Application Repository package.
Solution overview
The following architecture diagram shows the components of the Athena Federated Query MongoDB connector. It contains the following components:
- A virtual private cloud (VPC) configured with public and private subnets across three Availability Zones.
- A MongoDB cluster with customizable Amazon Elastic Block Store (Amazon EBS) storage deployed in private subnets and NAT gateways in a public subnet for outbound internet connectivity for MongoDB instances.
- Bastion hosts in an auto scaling group with Elastic IP addresses to allow inbound SSH access.
- An AWS Identity and Access Management (IAM)
MongoDBnoderole with Amazon Elastic Compute Cloud (Amazon EC2) and Amazon S3 permissions. - Security groups to enable communication within the VPC.
- Lambda functions deployed in a private subnet accessing S3 buckets. Athena invokes the Lambda function, which in turn fetches the data from MongoDB and maps the response back to Athena.
- AWS Secrets Manager through a VPC endpoint.

Prerequisites
To implement the solution, you need the following:
- An AWS account to access AWS services.
- An IAM user with permission to
CreateRole,ListRoles,GetPolicy, andAttachRolePolicy. - An IAM user with an access key and secret key to configure an integrated development environment (IDE).
- A MongoDB database. You can deploy a hosted MongoDB on Amazon EC2 or MongoDB Atlas in a VPC.
- If you don’t have a QuickSight subscription configured, sign up for one. You can access the QuickSight free trial as part of the AWS Free Tier option.
- A new secret in Secrets Manager to store your MongoDB user name and password.
- Data loaded into your MongoDB database. For this example, we used an airline dataset. Load the sample data either from the MongoDB command line or the MongoDB Atlas user interface, if using MongoDB Atlas.
Configure a Lambda connector
The first step in the deployment is to set up the connector environment. Athena uses data source connectors that run on Lambda to run federated queries. To connect with MongoDB, use the Amazon Athena DocumentDB Connector, which also works with any endpoint that is compatible with MongoDB.
To configure a Lambda connector, complete the following steps:
- On the Athena console, choose Data sources in the navigation pane.
- To view a published list of data sources for Athena, select Amazon DocumentDB.
- Choose Next.

- In the Data source details section, give your data source a unique name; for example,
ds_mongo.
This will be the connection name that appears under Data sources for Athena.

- Choose Create Lambda function.
This launches the Create function page in Lambda. The connector is deployed by using AWS Serverless Application Repository.

- For SecretNameOrPrefix, enter
mongo. - For SpillBucket, enter
spl-mongo-athena-test. - For AthenaCatalogName, enter
us-west-mongo-cat. - For DocDBConnectionString (the MongoDB connection), enter the following:
- For SecurityGroupIds, choose the security group that you want to associate with the function. Make sure that the security group of the MongoDB instance allows traffic from the Lambda function.
- For SpillPrefix, enter
athena-spill. - For Subnetids, enter the subnet IDs of subnets with MongoDB instances.
In this case, LambdaMemory and LambdaTimeout have been set to the maximum values, but these can vary depending on the query run and memory requirements. SpillBucket is an S3 bucket in your account to store data that exceeds the Lambda function response size limits. - Keep the rest as defaults.
- Select the acknowledgement check box choose Deploy.
The connection function is launched based on the given parameters.
- Create a VPC endpoint to allow the Lambda function to access Amazon S3 through an endpoint.
This is for the spill bucket. The spill bucket is a staging area for copying the results of the queries that are performed on MongoDB via Athena federation. This is so that the Lambda function in the VPC can access Amazon S3. - Go back to the Athena console.
- Under Connection details, for Lambda function, choose the newly created Lambda function.
- Choose Next.
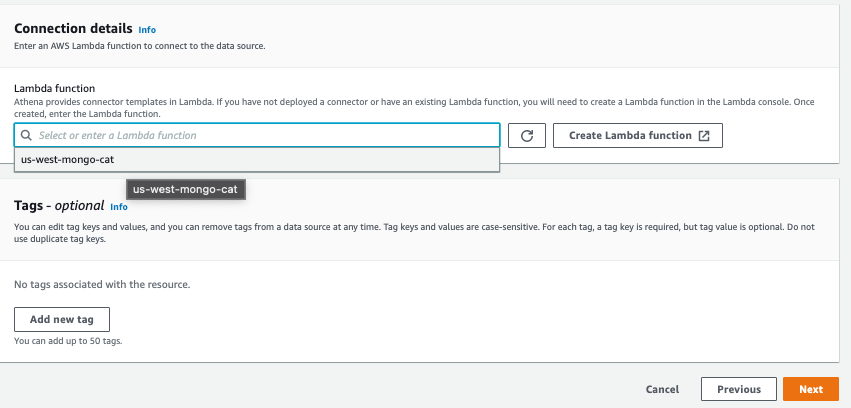
- To verify the connection, on the Athena console, choose Data sources, then choose
ds_mongo.
Associated databases from the connection should be listed.

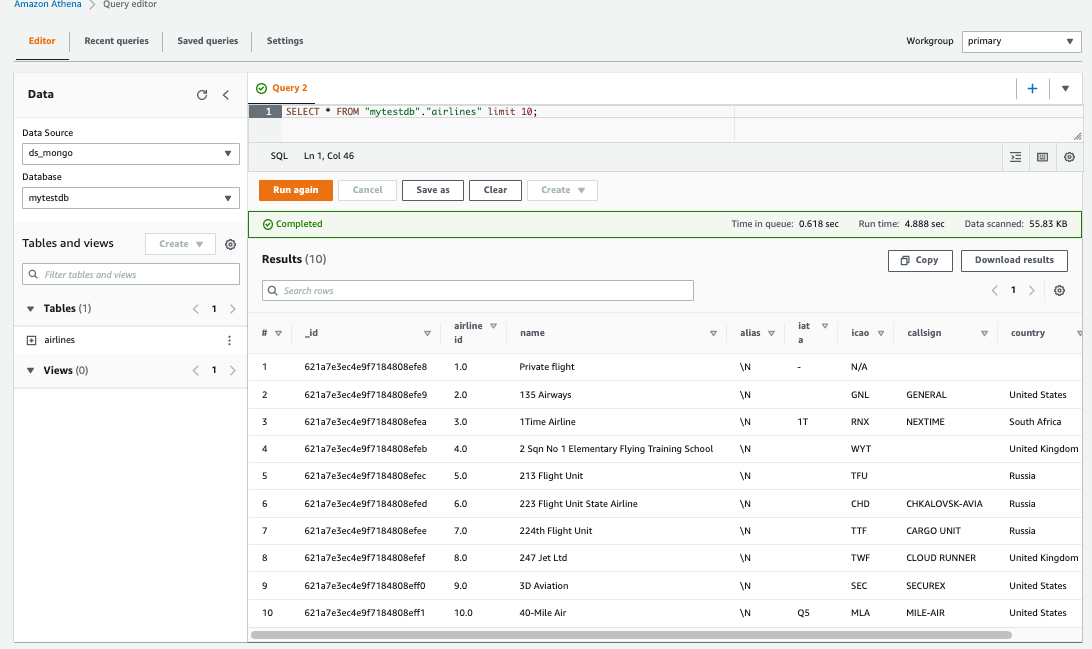
You should now be able to query the datasets from the Athena query editor by using SQL. - In the query editor, for Data Source, choose
ds_mongo.
Athena federates the query using the connector, which invokes the Lambda function. Then the query is performed by the function on MongoDB, and the query results are translated back to Athena. The following is a sample query that was performed on the airlines dataset.
Create a dataset on QuickSight to read the data from MongoDB
Before you launch QuickSight for the first time in an AWS account, you must set up an account. For instructions, see Signing in to Amazon QuickSight.
After the initial setup, you can create a dataset with Athena as the source. The QuickSight service role needs permission to invoke the Lambda function that connects MongoDB. The aws-quicksight-service-role-v0 service role is automatically created with the QuickSight account.
To create a dataset in QuickSight, complete the following steps:
- On the IAM console, in the navigation pane, choose Roles.
- Search for the role
aws-quicksight-service-role-v0and add the permissionLambda _fullaccess.
In an organization, there could be different data stores based on data load and consumption patterns. Examples include catalog or manual data that is associated with products in a MongoDB or key-value index store, transactions or sales data in a SQL database, and images or video clips that are associated with the product in an object store.
 In this case, an
In this case, an airlinestable from MongoDB is joined with a flat file that contains information on the airports. - Use the QuickSight cross-data store feature to join data from different sources on common fields.
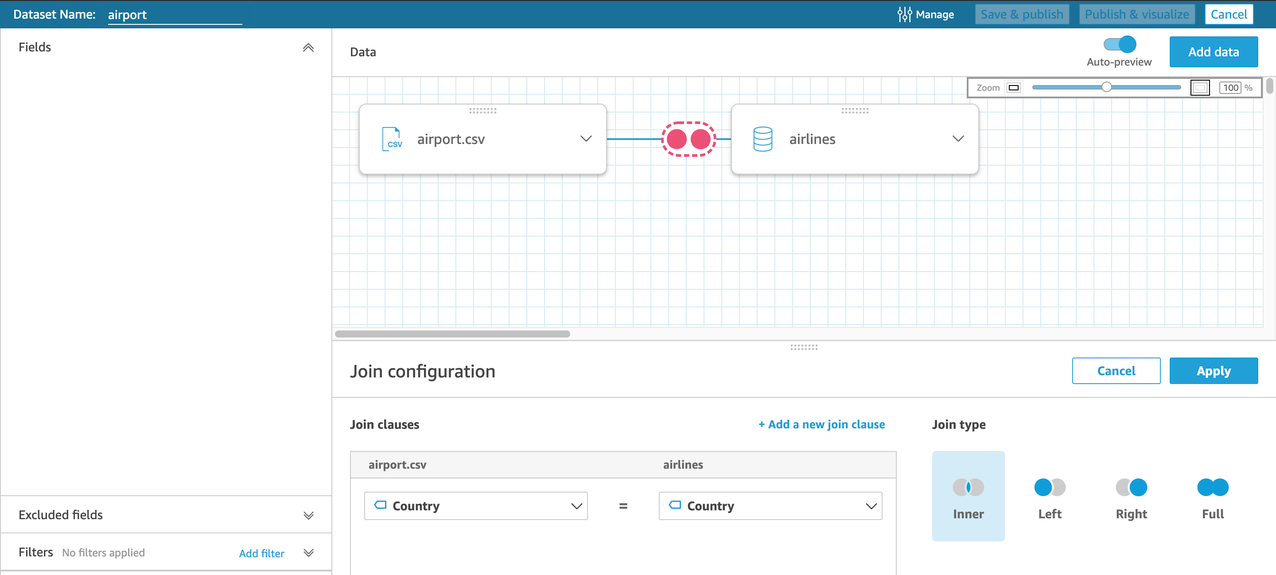
- We then update the data types for our geographic fields like fields like city, country, latitude, and longitude so we can build maps later.
- You can also create calculated fields while preparing your dataset, which allows you to reuse them in other QuickSight analyses.

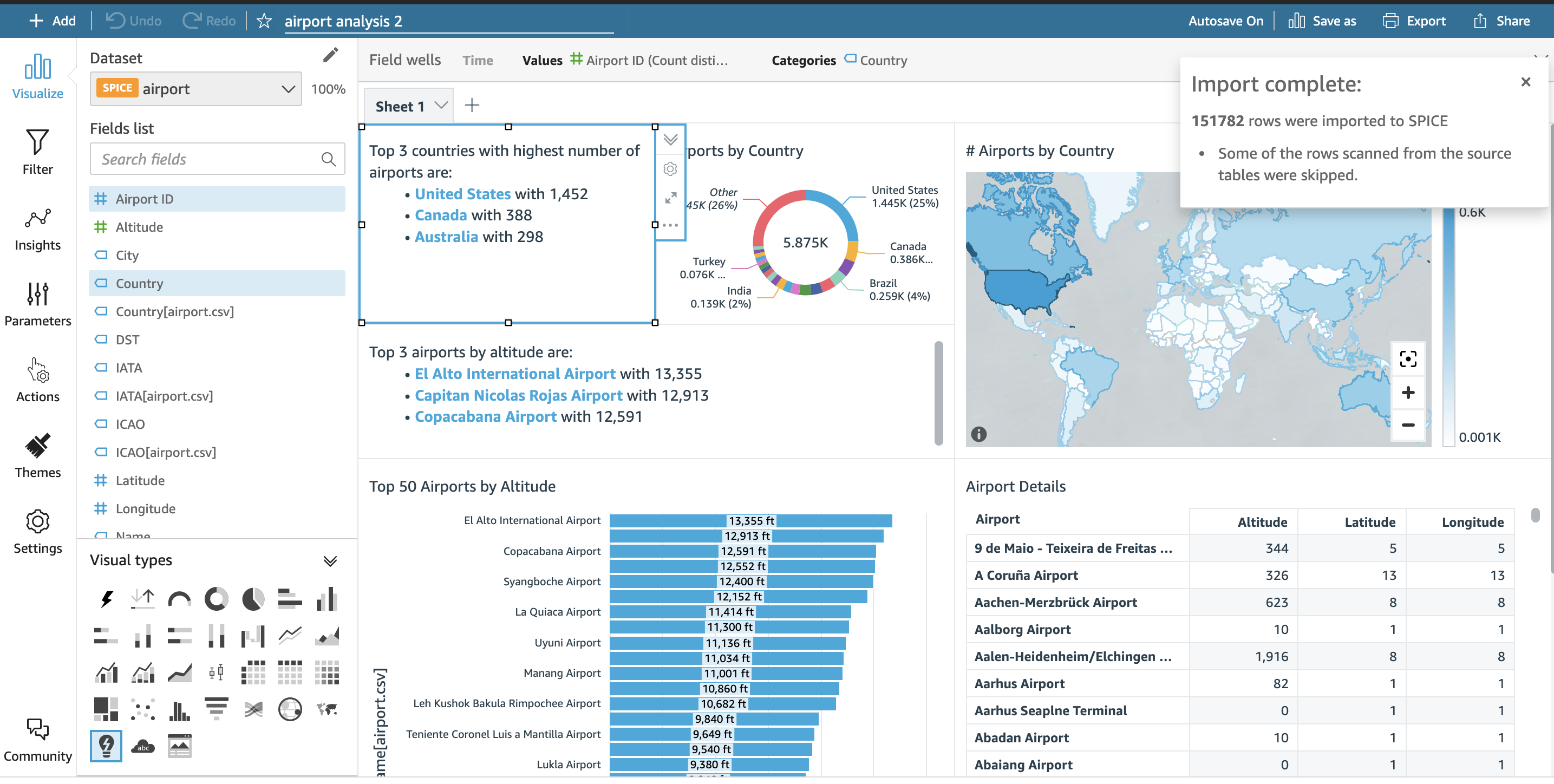
With a few clicks, you should be able to create a dashboard with the published dataset. For instance, you can plot your data on a map, show trends in a line chart, and add autonarratives from the list of Suggested Insights to create the analysis shown in the following screenshot.
Clean up
Make sure to clean up your resources to avoid resource spend and associated costs. You need to delete the EC2 instances with MongoDB. In the case of MongoDB Atlas, you can delete the databases and tables. Delete the Athena data source ds_mongo and unsubscribe your QuickSight account from the Manage QuickSight admin page.
Conclusion
With QuickSight and Athena Federated Query, organizations can access additional data sources beyond those already supported by QuickSight. If you have data in sources other than Amazon S3, you can use Athena Federated Query to analyze the data in place or build pipelines that extract and store data in Amazon S3. Athena now also supports cross-account federated queries to enable teams of analysts, data scientists, and data engineers to query data stored in other AWS accounts. Try connecting to proprietary data formats and sources, or build new user-defined functions, with the Athena Query Federation SDK.
About the Author
 Soujanya Konka is a Solutions Architect and Analytics specialist at AWS, focused on helping customers build their ideas on cloud. Expertise in design and implementation of business information systems and Data warehousing solutions. Before joining AWS, Soujanya has had stints with companies such as HSBC, Cognizant.
Soujanya Konka is a Solutions Architect and Analytics specialist at AWS, focused on helping customers build their ideas on cloud. Expertise in design and implementation of business information systems and Data warehousing solutions. Before joining AWS, Soujanya has had stints with companies such as HSBC, Cognizant.
 Nilesh Parekh is a Partner Solution Architect with ISV India segment. Nilesh help assist partner to review and remediate their workload running on AWS based on the AWS Well-Architected and Foundational Technical Review best practices. He also helps assist partners on Application Modernizations and delivering POCs.
Nilesh Parekh is a Partner Solution Architect with ISV India segment. Nilesh help assist partner to review and remediate their workload running on AWS based on the AWS Well-Architected and Foundational Technical Review best practices. He also helps assist partners on Application Modernizations and delivering POCs.