AWS Compute Blog
Architecting for DR on AWS Outposts with CloudEndure
April 19, 2024: This post is considered deprecated. Updated guidance can be found at Architecting for Disaster Recovery on AWS Outposts Racks with AWS Elastic Disaster Recovery.
This post is written by Scott Howe – Sr. Secure Hybrid Edge Solutions Architect and Schneider Larbi – Sr. Partner Solutions Architect (VMware & Outposts)
AWS Outposts is a fully managed offering that extends AWS infrastructure into your data center to facilitate workloads requiring local processing, data residency, minimal application latency, and 2-step migration journeys. Due to the nature of these workloads, they are often some of the most demanding in terms of durability and availability requirements.
Like deployments to AWS Regions, it is critical to plan for failures. Outposts are designed with resiliency in mind, providing redundant power, networking, and are available to order with N+M active compute instance capacity. In other words, for every physical N compute server, you have the option of including M redundant hosts capable of handling the workload during a failure. When leveraging CloudEndure DR with AWS Outposts, it is possible to plan for larger scale failure modes, such as data center outages, by replicating mission-critical workloads to remote locations.
In this blog post, I examine several Outposts-centric deployment patterns enabled by CloudEndure, their benefits, and associated architectures capable of facilitating Disaster Recovery (DR) on AWS Outposts.
Prerequisites
For each of these deployment patterns, it requires the following prerequisites:
- AWS Outposts installed on-premises
- Amazon S3 on Outposts (required for all CloudEndure replication destinations)
- The CloudEndure Agent Installed at the source
Planning for failure
Disasters come in many forms. It could be an overzealous backhoe operator taking out the WAN, a surge suppressor catching fire under the floor of a data center, or even naturally occurring events like earthquakes, among other things.
Regardless of whether your workload resides on-premises or in an AWS Region, it is critical to define the Recovery Time Objective (RTO) and Recovery Point Objective (RPO). These two values, defined by your organization are often workload-specific, profile how long a service can be down during recovery and quantify the acceptable amount of data loss. RTO and RPO guide you in choosing the appropriate strategy such as backup and recovery, pilot light, warm standby, or a hot standby approach.
How CloudEndure integrates with AWS Outposts
CloudEndure uses an agent at the source to capture the workload and transfers it to a lightweight staging area, which resides on an Outposts equipped with Amazon S3 on Outposts. This method also provides the ability to perform low-effort, non-disruptive DR drills before making the final cutover.
Keep in mind that once an Outpost’s subnet is selected as the target, all associated CloudEndure components remain within the Outpost, including the conversion servers. These servers convert source disks of servers being migrated to be able boot and run in the target infrastructure, Amazon EBS volumes, snapshots, and replication servers. The replication servers replicate the disks to the target infrastructure.
CloudEndure DR provides nearly continuous replication for mission critical workloads and supports deployment patterns including on-premises to Outposts, Outposts to Region, Region to Outposts, and between two logical Outposts through local networks.
Let’s discuss these deployment patterns.
DR from on-premises to Outposts
AWS Outposts facilitates workloads with challenging data residency requirements, including the ability to act as a DR solution. By deploying an Outpost in a disparate data center or colocation with meaningful distances from the source, it is possible to replicate workloads across great distances and increase resiliency of the data all while ensuring adherence to data residency policies or legislation.

In the preceding architecture diagram, on-premises sources replicate traffic from a LAN to a staging area residing on an Outpost subnet via the local gateway. This allows workloads to failover from their on-premises environment to an AWS Outpost in a different physical location during a disaster.
The staging areas and replication servers run on Amazon EC2 with Amazon EBS volumes and require Amazon S3 on Outposts where the Amazon EBS snapshots reside.
The agent is responsible for providing nearly continuous, block-level replication from your LAN using TCP/1500 with traffic routing to EC2 instances using the Outposts local gateway.
DR from Outpost to Region
Since its initial release, AWS Outposts has supported Amazon EBS snapshots written to Amazon S3 located in the AWS Region. Backup to an AWS Region is one of the most cost-effective and easiest to configure DR approaches, and ensures data redundancy outside of your Outpost and data center.
This method also offers flexibility for restoration within an AWS Region if the original deployment is irrecoverable. However, depending on the frequency of the snapshots and the timing of the failure, backup, and recovery to the Region has the potential to have an RPO/RTO spanning hours depending on the throughput of the service link.
For critical workloads, it is possible for CloudEndure DR to reduce RTO to minutes and RPO in the subsecond range. After creating an initial replication of workloads that reside on the Outposts, CloudEndure DR provides nearly continuous, block-level replication in the Region. Just like replication from non-AWS virtual machines or bare metal servers, CloudEndure resources, including Replication Servers, Converters, EBS Volumes, and Snapshots reside in the Region.
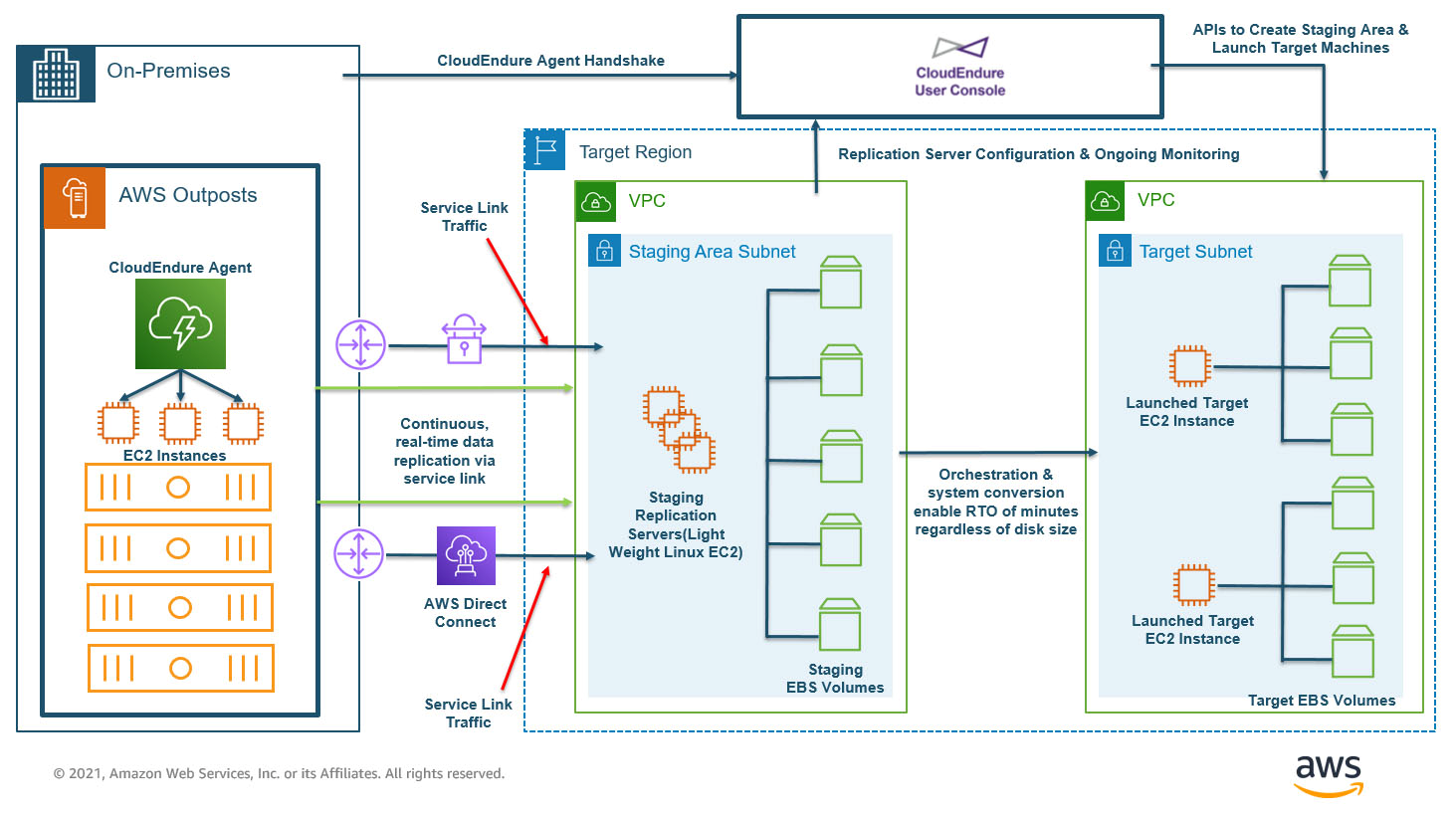
In the preceding architecture diagram, I highlight data replication over the service link from EC2 instances running locally on an Outpost to an AWS Region. The service link traverses either public Region connectivity or AWS Direct Connect.
I recommend Direct Connect because it provides low latency and consistent bandwidth for the service link back to a Region, which also improves the reliability of transmission for CloudEndure replication traffic.
The service link is comprised of redundant, encrypted VPN tunnels. Replication traffic can also be sent privately without traversing the public internet by leveraging Private Virtual Interfaces with Direct Connect for the Service Link.
With this architecture in place, disasters can be mitigated and downtime reduced by failing over to the AWS Region using CloudEndure DR.
DR from Region to Outposts
AWS provides multiple Availability Zones (AZs) within a Region and isolated AWS Regions globally for the greatest possible fault tolerance and stability. The reliability pillar of AWS’s Well-Architected Framework encourages distributing workloads across AZs and replicating data between Regions when the need for distances exceeds those of AZs.
CloudEndure supports nearly continuous replication of workloads from a Region onto Outposts within your data center for DR. This deployment model provides increased durability from a source AWS Region to an Outpost anchored to a different Region.
In this model, CloudEndure components remain on-premises within the Outposts, but note that data charges are applicable as data egresses from the Region back to the data center and Amazon S3 on Outposts is required on the destination Outposts.
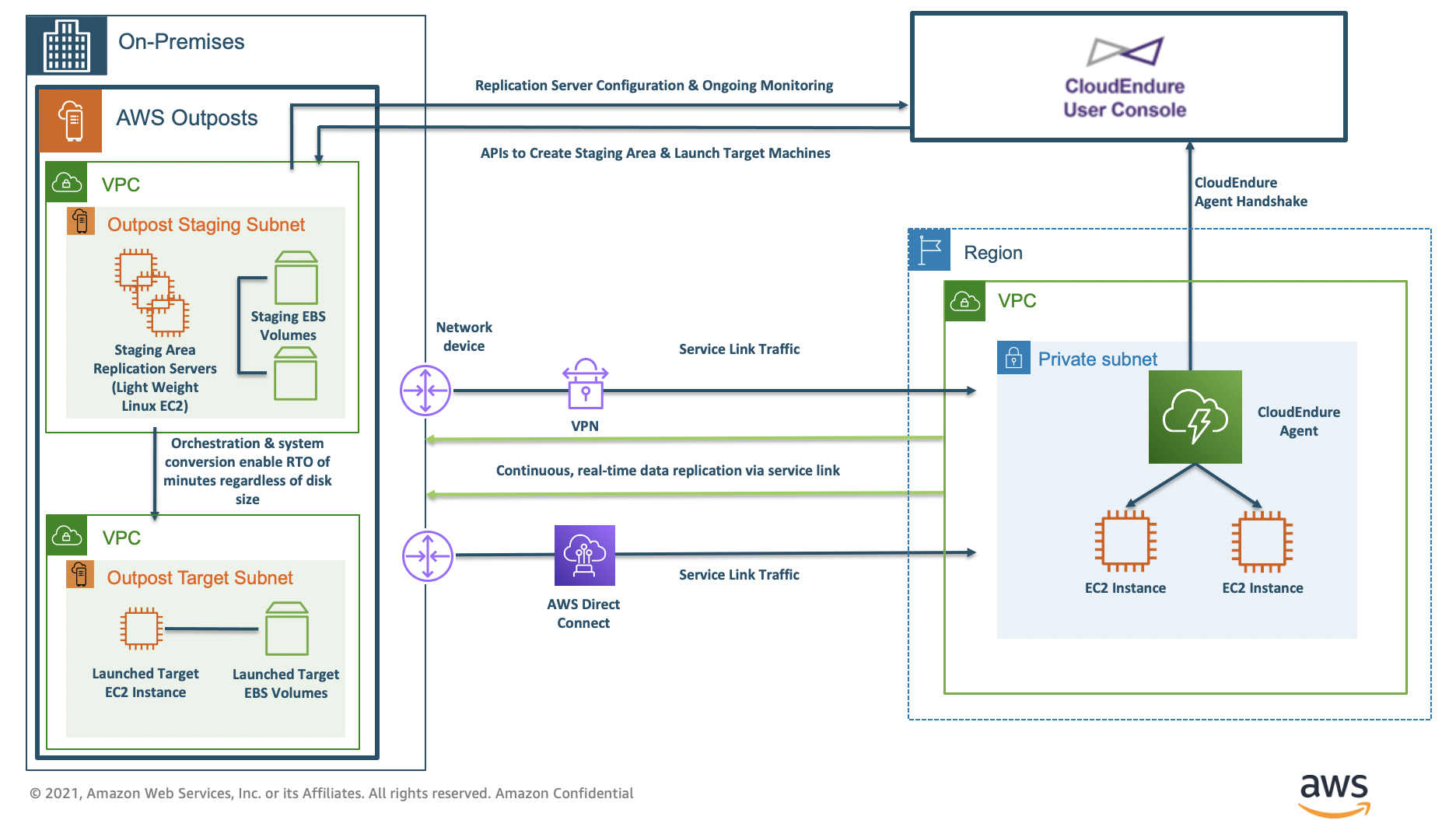
Implementing the preceding architecture diagram enables failover of critical workloads from the Region to on-premises Outposts in a seamless way. Keep in mind that AWS Regions provide the management and control plane for Outposts, making it critical to consider probability and frequency of interruptions as a part of your DR planning. Scenarios such as warm standby with pre-allocated EC2 and Amazon EBS resources may prove more resilient during service link disruptions.
DR between two Outposts
Logical Outposts are comprised of one or more physical racks, are independent colocations of one another, and support deployments in disparate data centers or colocation. You can elect to have logical Outposts anchored to different Availability Zones or Regions. CloudEndure DR unlocks options for replication between two logical Outposts, leading to increased resiliency and reducing the impact of your data center as a single point of failure. In the following architecture, nearly continuous replication captured from a single AWS Outpost source is applied at a second logical Outpost.
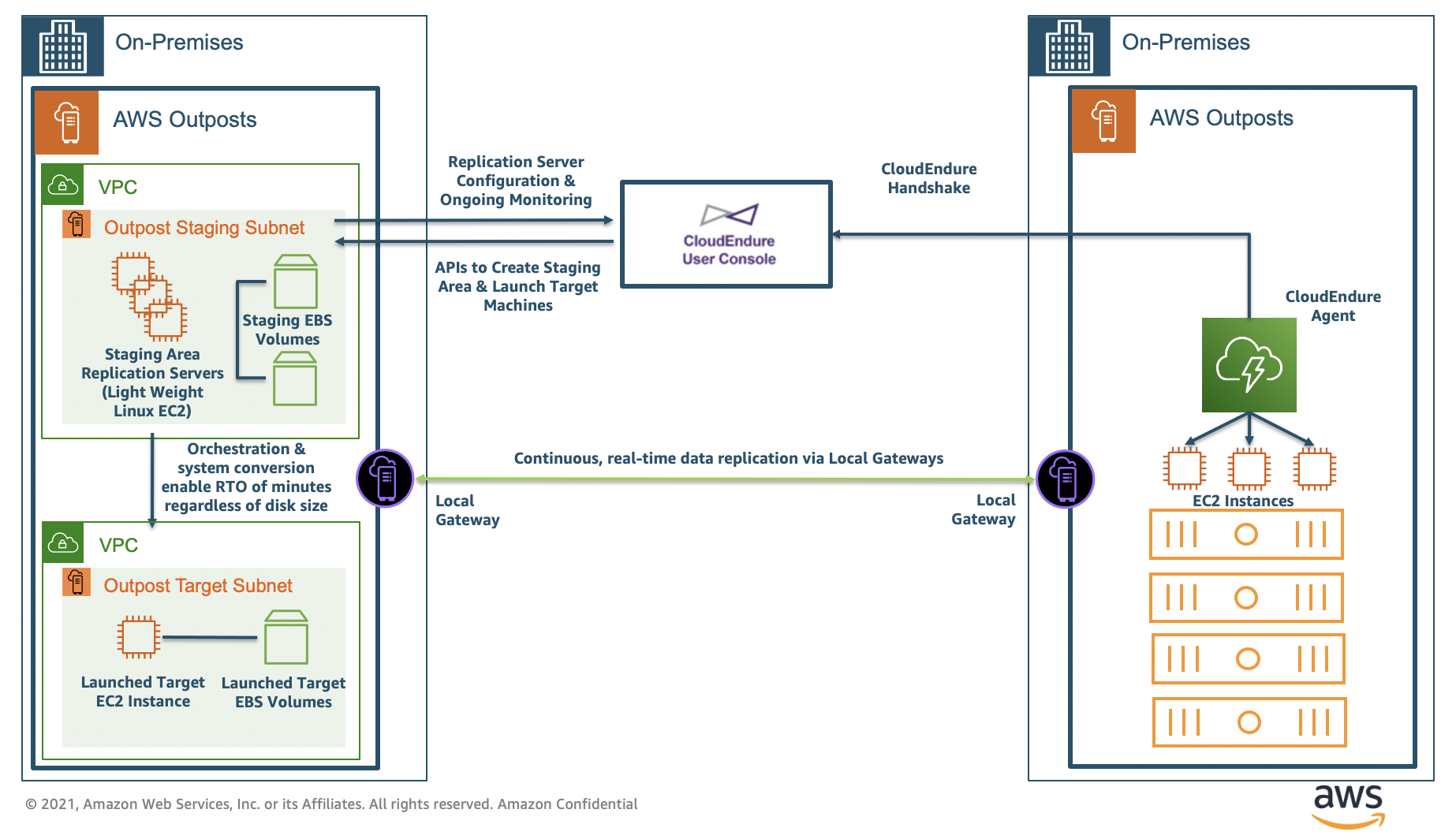
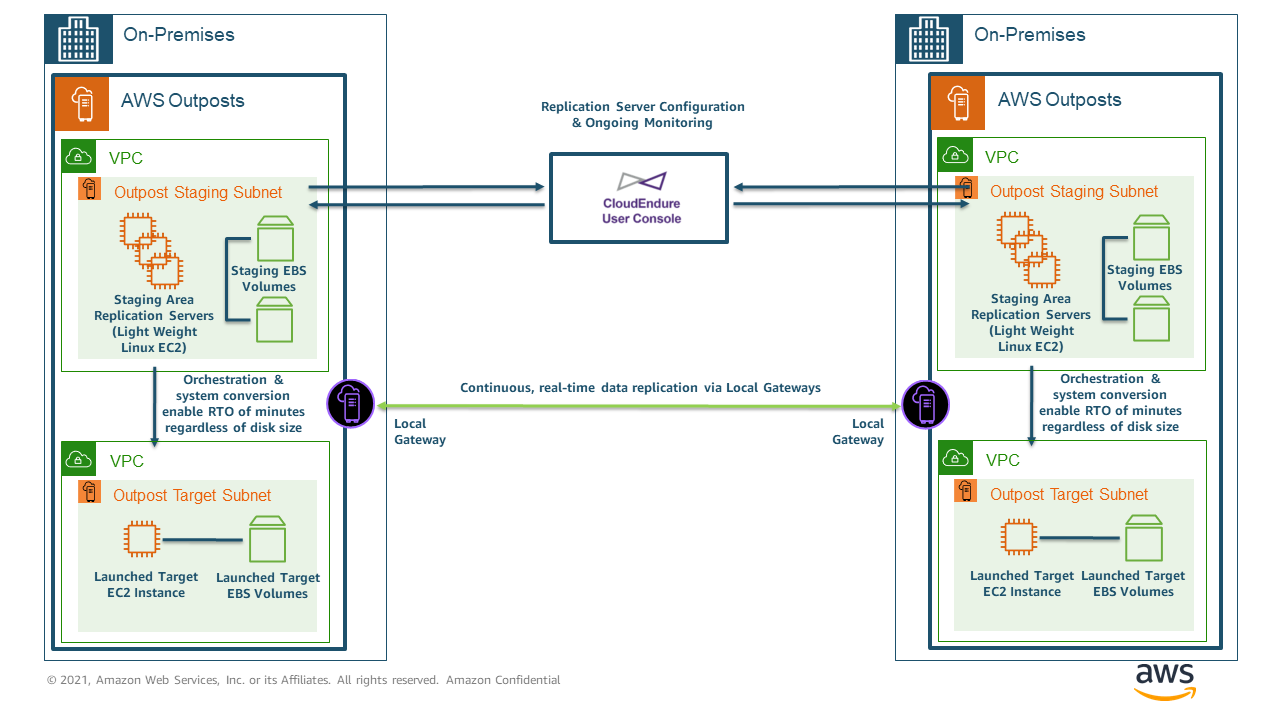
Supporting both directional and bidirectional replication between Outposts ensures that events that take down a data center, Availability Zone, or even the entire Region result in minimal disruption. In the following architecture diagram, bidirectional data replication occurs between the Outposts by routing traffic via the local gateways, avoiding any outbound data charges from the Region and allowing for more direct routing between deployments sites that could potentially span significant distances. CloudEndure cannot communicate with resources directly utilizing a customer-owned IP address pool (CoIP pool).
Architecture considerations
When planning an Outposts deployment leveraging CloudEndure, it is critical to consider the impact on storage. As a general best practice, AWS recommends planning for a 2:1 ratio consisting of EBS volumes used for nearly continuous replication and Amazon EBS snapshots on Amazon S3 for point-in-time recovery. While it is unlikely that all servers would require recovery simultaneously, it is also important to allocate a reserve of EBS volume capacity leveraged when launched at the time of recovery. Local S3 is required for each Outposts used as a replication destination.
Amazon CloudWatch has integrated metrics for EC2, Amazon EBS, and Amazon S3 capacity on Outposts, making it easy to create custom tailored dashboards and integrate with Simple Notification Service (Amazon SNS) for alerts at defined thresholds. Monitoring these metrics are critical to ensure that proper free space is available for data replication to occur unimpeded.
Consider taking advantage of Recovery Plans within CloudEndure to ensure that related services are recovered in a particular order. For example, during a DR event it might be critical to first bring up a database before recovering application tiers. Recovery plans provide the ability to group related services and apply wait times to individual targets.
Conclusion
AWS Outposts enables low latency, data residency, or data gravity constrained workloads by supplying managed compute and storage services within your data center or colocation. When coupled with CloudEndure DR, it is possible to decrease RPO and RTO through a variety of flexible deployment models with sources and destinations ranging from on premises, the Region, or another AWS Outposts.