AWS Database Blog
Build persistent memory for agentic AI applications with Mem0 Open Source, Amazon ElastiCache for Valkey, and Amazon Neptune Analytics
Today, we’re announcing a new integration between Mem0 Open Source, Amazon ElastiCache for Valkey, and Amazon Neptune Analytics to provide persistent memory capabilities to agentic AI applications. This integration solves a critical challenge when building agentic AI applications: without persistent memory, agents forget everything between conversations, making it impossible to deliver personalized experiences or complete multi-step tasks effectively.
In this post, we show how you can use this new Mem0 integration with AWS databases to perform the following actions:
- Store and retrieve conversation history across multiple sessions using the high-performance vector storage of ElastiCache for Valkey
- Track complex entity relationships with Neptune Analytics for richer and more contextual responses
- Scale memory operations to handle millions of requests with sub-millisecond latency
This integration works with agentic frameworks compatible with Mem0 Open Source and can be hosted using Amazon Bedrock AgentCore Runtime. AgentCore Runtime is framework agnostic and enables your agent to run with different large language models (LLM), such as models offered by Amazon Bedrock, Anthropic Claude, Google Gemini, and OpenAI.
We walk through a simple implementation to get you started. The sample creates a GitHub repository research agent built with Strands Agents, a framework to build AI agents. We will show you the architecture, code, and performance improvements you can expect from this integration. You can download the sample code to follow this post from the Mem0 examples repository.
With this integration, you can build a self-managed memory layer that combines the capabilities of Mem0 with the storage capabilities of ElastiCache for Valkey and Neptune Analytics. If you prefer a managed solution, you can use Mem0 Platform or AgentCore Memory.
Understanding the challenge of stateless AI agents
An agentic AI application is a system that takes actions and makes decisions based on input. These agents use external tools, APIs, and multi-step reasoning to complete complex tasks. However, agents don’t retain memory between conversations by default, which limits their ability to provide personalized responses or maintain context across sessions.
Agentic memory handles the persistence, encoding, storage, retrieval, and summarization of knowledge gained through user interactions. This memory system is a critical part of the context management component of an agentic AI application, enabling agents to learn from past conversations and apply that knowledge to future interactions.
Agentic memory consists of two main types:
- Short-term memory – Maintains context within a single session, tracking the current conversation flow and recent interactions
- Long-term memory – Stores information across multiple sessions, enabling agents to remember user preferences, past decisions, and historical context for future conversations
Solution overview
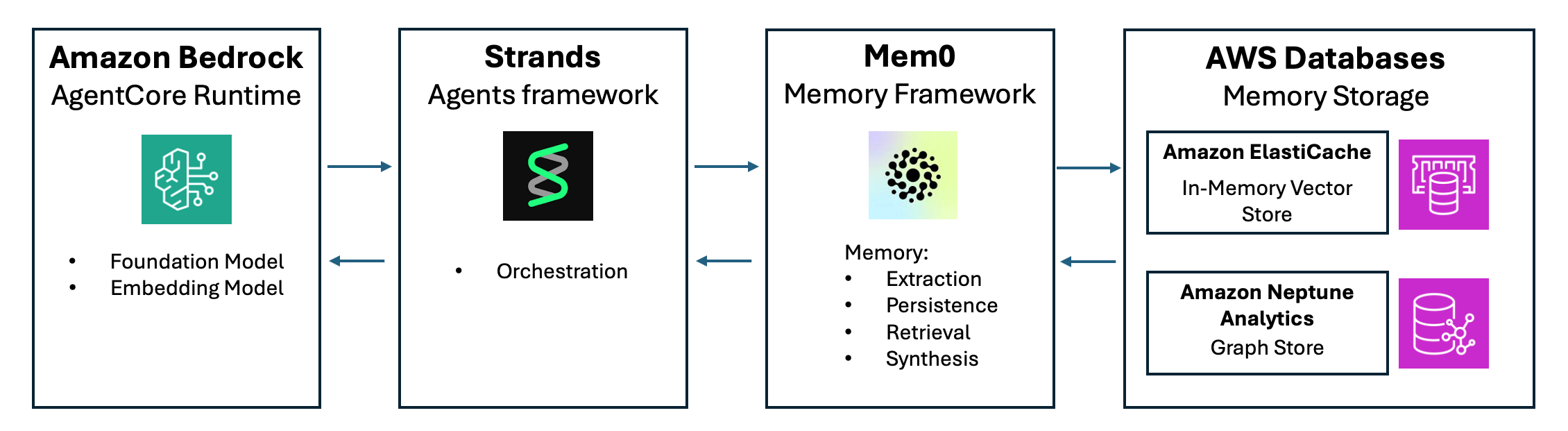
This memory-enabled agent architecture uses five components that work together to store, retrieve, and manage persistent memory:
- Amazon Bedrock AgentCore Runtime – AgentCore Runtime provides a hosting environment for deploying and running our agent. It provides access to the LLM and embedding models required for our architecture.
- Strands Agents – Strands is a code-first framework for building agents. Strands manages LLM invocations, tool execution, and user conversations. It supports multiple LLMs, including those from Amazon Bedrock, Anthropic, Gemini, and OpenAI. In this example, Strands orchestrates an agent that uses an HTML tool to browse the web, but you can use it to build multi-agent systems. Strands includes integration with Mem0 for memory management.
- Mem0 – This memory orchestration layer sits between AI agents and storage systems. Mem0 manages the memory lifecycle, from extracting information from agent interactions to storing and retrieving it efficiently. It provides unified APIs for working with different memory types, including episodic, semantic, procedural, and associative memories. Mem0 handles memory operations such as automatic filtering to prevent memory bloat, decay mechanisms that remove irrelevant information over time, and cost optimization features that reduce LLM expenses through prompt injection and semantic caching.
- Amazon ElastiCache for Valkey – This managed in-memory data store serves as the vector storage component of this memory architecture. ElastiCache for Valkey uses Valkey’s open source vector similarity search capabilities to store high-dimensional vector embeddings. This enables semantic memory retrieval, allowing agents to find relevant memories based on meaning rather than exact keyword matches. ElastiCache for Valkey provides microsecond-level latency for memory operations, making it suitable for real-time agent interactions. The service supports real-time index updates so new memories become immediately searchable, and includes semantic caching capabilities that reduce LLM costs by identifying and reusing responses to similar queries.
- Amazon Neptune Analytics – This in-memory graph analytics store supports querying complex entity relationships and associations. Neptune Analytics represents the connections between people, concepts, events, and ideas as a knowledge graph. This enables multi-hop reasoning across connected memories, allowing agents to traverse relationship paths to discover relevant context beyond what vector similarity search alone can find. The service supports hybrid retrieval strategies that combine graph traversal with vector similarity search.
The following diagram illustrates the data flow from AgentCore Runtime to Mem0 and AWS databases for persistence.
In the following sections, we show how to build a GitHub repository research agent that helps developers find relevant projects and remembers the key metrics for the project and the parts of the project where different users work.
Prerequisites
Prerequisites to this post include:
- Get credentials to grant programmatic access to use the Bedrock APIs. The AWS Access Key ID and AWS Secret Access Key must be configured variables in your environment.
- A ElastiCache cluster running Valkey 8.2. Valkey 8.2 includes support for Vector Similarity Search. Follow the steps in the ElastiCache documentation to create one.
- A Neptune Graph configured to support vector indexes and public access. Follow the steps in the Neptune documentation to create your graph.
- (Optional) The code used to run this sample agent can be found in the Mem0 examples repository. Follow the instructions in the code to install the required libraries and to configure your environment.
Create demo agent
To create our demo agent using Strands, complete the following steps:
- Install Strands and the tools development packages:
- Initialize your agent and call it with the user prompt:
Without memory, the agent performs the same research tasks repeatedly for each request. The following screenshot shows how the agent works without memory capabilities. The agent makes three tool calls to answer the request, using 70,373 tokens and taking 9.25 seconds to complete.

Add memory capabilities with ElastiCache for Valkey
Now let’s add Mem0 to store the agent’s memories in AWS databases. We use Mem0 with ElastiCache for Valkey as the vector store to save and retrieve memories for each repository the agent discovers. When the agent finds a repository, it stores that information as a memory for future use.
To add Mem0 with ElastiCache for Valkey, complete the following steps:
- Follow the instructions to access your ElastiCache cluster so you can connect to clusters from your development desktop.
- Install
mem0aiand the Valkey vector store connector in your project: - Configure Valkey as the vector store. ElastiCache for Valkey supports vector search capabilities starting with version 8.2. Configure the Valkey connector for Mem0 following the instructions in the Mem0 documentation:
- Now you can add two new tools to the Strands agent so it can store and search for memories. The
@tooldecorator provides a straightforward way to transform regular Python functions into tools that the agent can use. The agent initialization must happen after the tool definition.
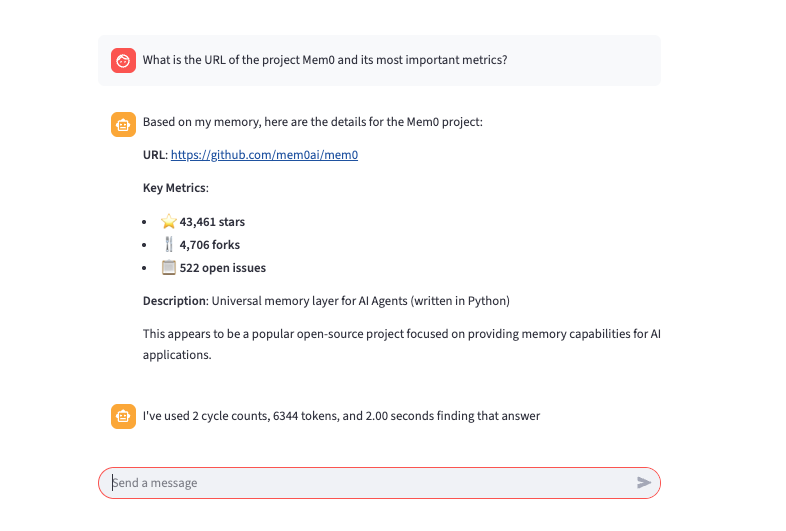
With memory enabled, the agent remembers repository information from previous searches. When you make the same request again, the agent retrieves the information from memory instead of making tool calls, using only 6,344 tokens and completing the request in 2 seconds. This is 12 times fewer tokens and more than 3 times faster than without memory because the agent no longer needs to scan the web looking for this information.
Enhance with graph memory using Neptune Analytics
Using the graph extension in Mem0 outperforms traditional memory systems by using graph-based memory representations. it can capture complex relationships between entities and support advanced reasoning across interconnected facts. Compared to traditional systems, graph memory excels in temporal and open-domain tasks, achieving higher accuracy and better semantic coherence. It also offers structured relational clarity, which is particularly beneficial for tasks requiring nuanced contextual and temporal integration. You can use Neptune Analytics as the graph store in Mem0 for memory retrieval and reasoning, enabling long-term memory for AI agents across richly connected graphs—powering more personalized and context-aware AI experiences. It enables graph-based long-term memory for LLMs by using Neptune as an external memory store, improving response quality through multi-hop graph reasoning, and supporting hybrid retrieval across graph, vector, and keyword modalities.
Let’s improve our agent to support more complicated queries that consider graph relationships. We will allow our agent to store information about users of a repository in a graph data store so it can later help us ask questions about where different users work, and their areas of expertise.To add support for memories using Neptune Analytics graphs, complete the following steps:
- Install the Mem0 graph extension:
- Configure Neptune Analytics as the graph store. Neptune Analytics supports vector search indexes for graph data. For instructions to configure the Neptune Analytics connector for Mem0, refer to the Mem0 documentation.
- Add memory tools for graph relationships. This enables the agent to pick the best destination for their memories based on the type of data it’s storing.
The research agent can now use a graph-based memory system to store and retrieve information. It represents developer preferences and project details as entities (nodes) and their relationships (edges) in a knowledge graph. When retrieving relevant projects, the agent identifies key entities (such as developer preferences and project attributes) and uses embeddings to find similar nodes. It then traverses the relationships between these nodes to construct a subgraph of relevant projects and preferences based on the user’s history.
Let’s test our agent’s ability to store information in a knowledge graph. We start by asking our agent to find are the top contributors for Mem0 and the modules where they’ve worked the most. We also ask the agent to store this information in a graph. The following screenshot shows our results.

Now we can test how good our agent is at using this newly created graph of memories by asking information that requires traversing the graph. We ask who works in the core packages and the SDK updates.

Finally, we can ask who the contributors are for the core package.

Clean up
You can remove any unnecessary resources once you are finished testing this agent, including the ElastiCache cluster and Neptune graph used to store agentic memories.
Conclusion
The integration between Mem0, ElastiCache for Valkey, and Neptune Analytics provides a production-ready solution for adding persistent memory to your AI agents. By combining vector storage for semantic memory with graph-based relationship tracking, you can build agents that remember user preferences, maintain conversation context, and deliver personalized experiences across sessions.
You can dive deeper into agentic memory concepts by exploring the Mem0 documentation, reviewing the Strands Agents user guide, and learning more about Valkey vector search and Neptune graph queries in the AWS documentation.