AWS Database Blog
Category: Artificial Intelligence

Migrate relational-style data from NoSQL to Amazon Aurora DSQL
In this post, we demonstrate how to efficiently migrate relational-style data from NoSQL to Aurora DSQL, using Kiro CLI as our generative AI tool to optimize schema design and streamline the migration process.
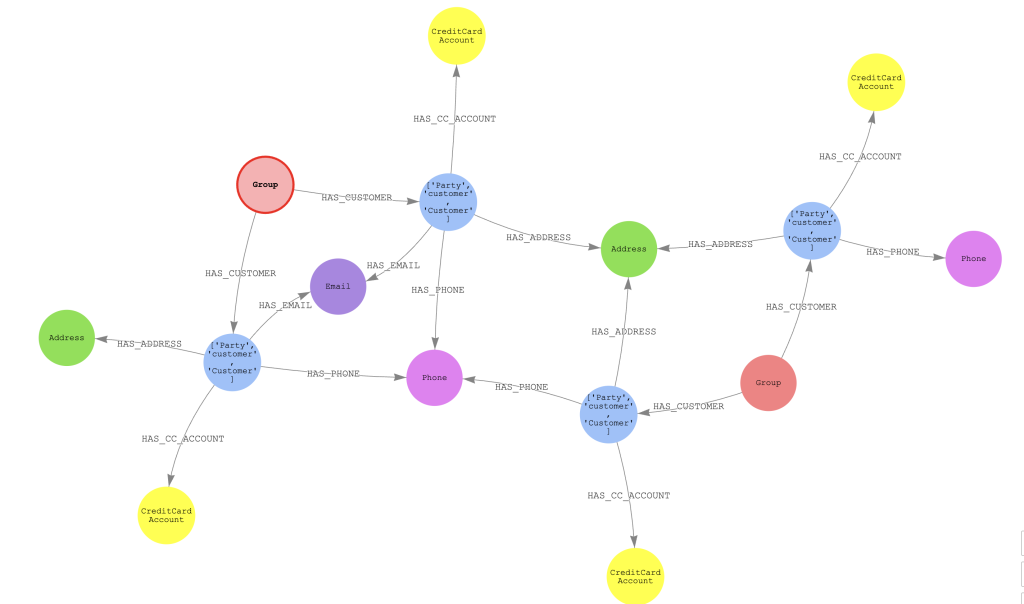
Build fraud detection systems using AWS Entity Resolution and Amazon Neptune Analytics
In this post, we show how you can use graph algorithms to analyze the results of AWS Entity Resolution and related transactions for the CNP use case. We use several AWS services, including Neptune Analytics, AWS Entity Resolution, Amazon SageMaker notebooks, and Amazon S3.

Optimize LLM response costs and latency with effective caching
In this post, we talk about the benefits of caching in generative AI applications. We also elaborated on a few implementation strategies that can help you create and maintain an effective cache for your application.
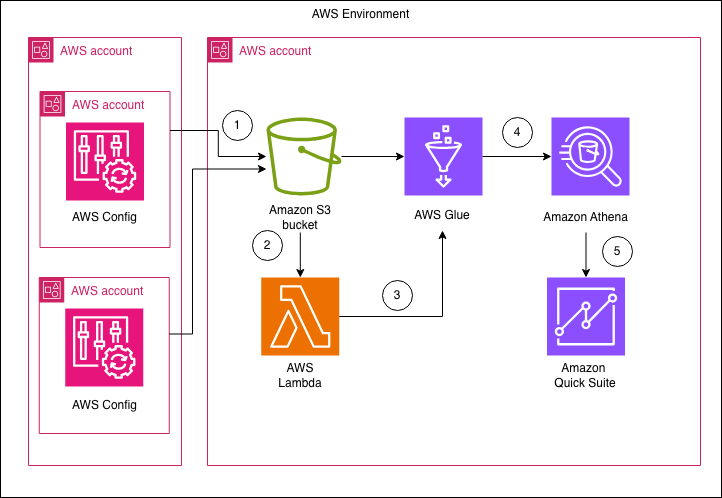
Enhance the visibility of Amazon RDS instances and configuration with AWS Config and Amazon Quick Suite
In this post, we show you how to build a centralized dashboard for monitoring Amazon RDS configurations across your organization by using AWS Config and Amazon Quick Suite. This solution delivers detailed insights across different areas, such as summary metrics, backup configurations, security posture, engine and support information, extended configurations, and resource tagging.
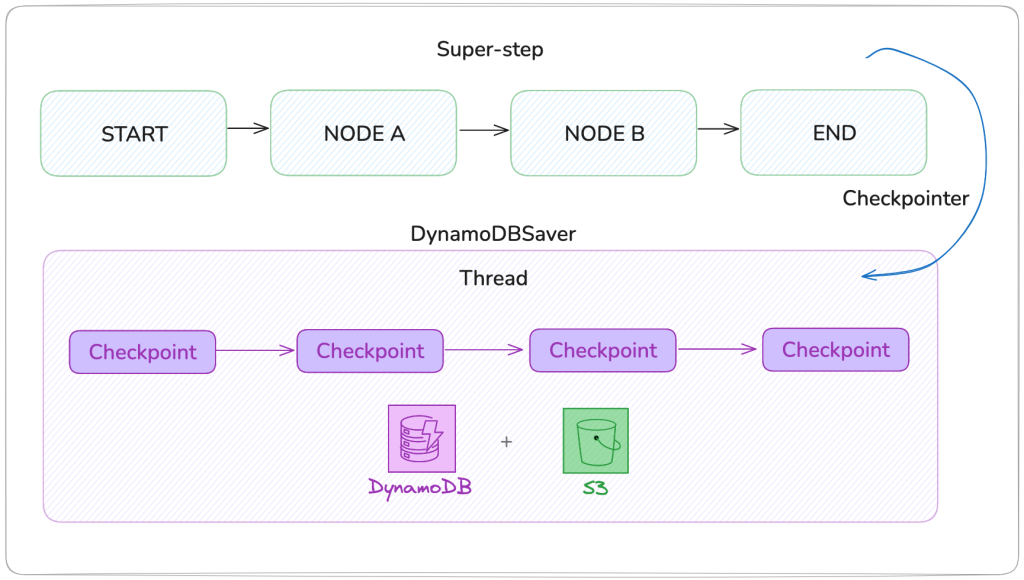
Build durable AI agents with LangGraph and Amazon DynamoDB
In this post we show you how to build production-ready AI agents with durable state management using Amazon DynamoDB and LangGraph with the new DynamoDBSaver connector, a LangGraph checkpoint library maintained by AWS for Amazon DynamoDB.

Introducing Amazon Aurora powers for Kiro
In this post, we show how you can turn your ideas into full-stack applications with Kiro powers for Aurora. We explore how a new innovation, Kiro powers, can help you use Amazon Aurora best practices built into your development workflow, automatically implementing configurations and optimizations that make sure your database layer is production-ready from day one.

Build a fitness center management application with Kiro using Amazon DocumentDB (with MongoDB compatibility)
In this post, we walk through how we used Kiro, an agentic Integrated Development Environment (IDE), to build a complete fitness center management application that digitizes paper-based fitness tracking. We explore Kiro’s spec-driven development workflow and see how it transforms complex application development into a streamlined, iterative process. Our solution uses Amazon DocumentDB as the backend.

Lower cost and latency for AI using Amazon ElastiCache as a semantic cache with Amazon Bedrock
This post shows how to build a semantic cache using vector search on Amazon ElastiCache for Valkey. As detailed in the Impact section of this post, our experiments with semantic caching reduced LLM inference cost by up to 86 percent and improved average end-to-end latency for queries by up to 88 percent.

Accelerate generative AI use cases with Amazon Bedrock and Oracle Database@AWS
In this post, we walk through the steps of integrating Oracle Database@AWS (ODB@AWS) with Amazon Bedrock for by creating a RAG assistant application using an Amazon Titan embedding model in Amazon Bedrock and vectors stored in Oracle AI Database 26ai.

AI-powered tuning tools for Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL databases: PI Reporter
In this post, we explore an artificial intelligence and machine learning (AI/ML)-powered database monitoring tool for PostgreSQL, using a self-managed or managed database service such as Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL.