AWS Database Blog
Category: Amazon DynamoDB

How Shaadi.com reduced costs and improved performance with DynamoDB
Shaadi.com is the flagship brand for People Interactive. It is the largest matchmaking platform in the world and has lead this space for last 20 years. It has been built on one simple idea of helping people find a life partner, discover love and share joy. Their vision is to bring people together through technology. […]

Enhanced AWS Backup features for Amazon DynamoDB
Amazon Web Services (AWS) recently announced new features in AWS Backup for Amazon DynamoDB on-demand backups that can help you meet your compliance, business continuity, and cost-optimization needs. In this post, we describe these features and provide a step-by-step guide for using them to copy DynamoDB backups across AWS Regions and across accounts, configure your […]

Use parallelism to optimize querying large amounts of data in Amazon DynamoDB
In this post, I demonstrate how to optimize querying a large amount of data in Amazon DynamoDB by using parallelism – splitting the original query into multiple parallel subqueries – to meet these strict performance SLAs for large DynamoDB database queries. During our engagements with customers, we often need to retrieve a large number of […]

Import and export CloudFormation templates and CSV sample data with NoSQL Workbench for Amazon DynamoDB
NoSQL Workbench for DynamoDB is a client-side application with a point-and-click interface that helps you design, visualize, and query non-relational data models for Amazon DynamoDB. NoSQL Workbench clients are available for Windows, macOS, and Linux. Over time, NoSQL Workbench has added many features, such as the ability to use it with Amazon Keyspaces for (Apache […]

Archive data from Amazon DynamoDB to Amazon S3 using TTL and Amazon Kinesis integration
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In this post, we share how you can use Amazon Kinesis integration and the Amazon DynamoDB Time to Live (TTL) feature to design data archiving. Archiving old […]

Amazon DynamoDB session videos from AWS re:Invent 2021
Amazon DynamoDB is a fully managed NoSQL database service that delivers single-digit millisecond performance at any scale and is used by many of the world’s most demanding applications. This blog post recaps the keynotes and breakout sessions that featured DynamoDB at AWS re:Invent 2021, including links to watch the videos on-demand. The 10th annual conference […]
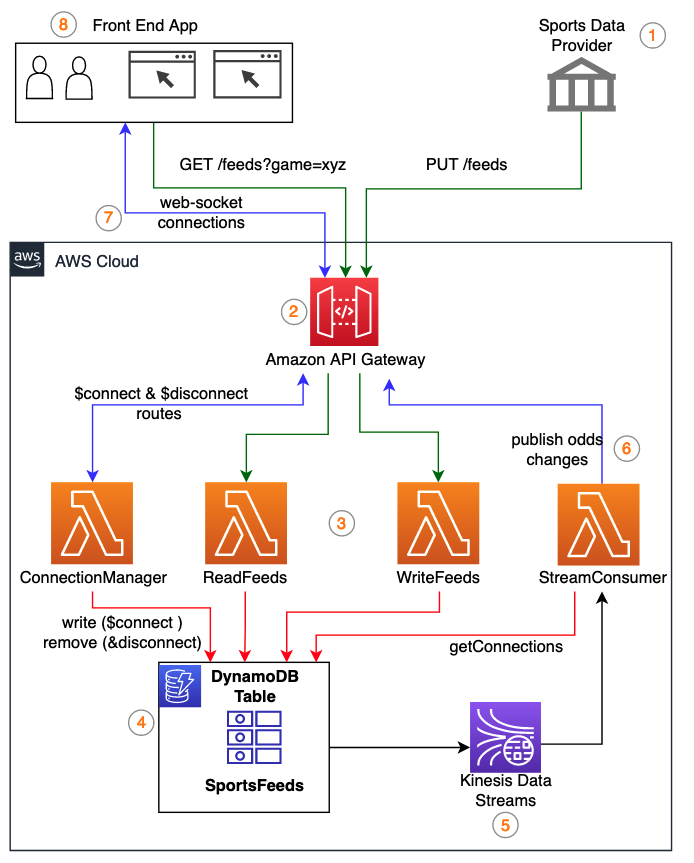
Store and stream sports data feeds using Amazon DynamoDB and Amazon Kinesis Data Streams
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Online bookmakers are innovating to offer their clients continuously updated sports data feeds that allow betting throughout the duration of matches. In this post, we walk through […]

AWS named a Leader in 2021 Gartner Magic Quadrant for Cloud Database Management Systems
Industry analyst firm Gartner has published its annual report evaluating cloud-based data and analytics services, the 2021 Magic Quadrant for Cloud Database Management Systems. AWS was once again named a Leader and placed highest among 20 recognized vendors for its “Ability to Execute.” We’re honored by the recognition from the highly respected technology adviser, and […]

Build faster with Amazon DynamoDB and PartiQL: SQL-compatible operations
In November 2020, we launched DynamoDB support for PartiQL. With PartiQL, you can codify your DynamoDB data operations using familiar SQL syntax and get the fast, consistent performance that DynamoDB customers have long depended on. In this post, we explain how DynamoDB’s PartiQL support helps new DynamoDB developers learn faster and provides existing DynamoDB developers […]

Build a fault-tolerant, serverless data aggregation pipeline with exactly-once processing
The business problem of real-time data aggregation is faced by customers in various industries like manufacturing, retail, gaming, utilities, and financial services. In a previous post, we discussed an example from the banking industry: real-time trade risk aggregation. Typically, financial institutions associate every trade that is performed on the trading floor with a risk value […]