AWS Database Blog
How Shaadi.com reduced costs and improved performance with DynamoDB
Shaadi.com is the flagship brand for People Interactive. It is the largest matchmaking platform in the world and has lead this space for last 20 years. It has been built on one simple idea of helping people find a life partner, discover love and share joy. Their vision is to bring people together through technology. Shaadi.com has helped over 7 million people in finding a life partner and touched the lives of over 50 million people globally.
Like any social platform, Shaadi.com relies on the quality of match recommendations and user communication tools to create an engaging experience.
In this post, you learn how Shaadi.com reduced costs and modernized the database used to store user connections and communication by migrating from a self-managed MySQL on Amazon Elastic Compute Cloud (Amazon EC2) to Amazon DynamoDB.
The challenge
Shaadi.com uses a large group of MySQL clusters—100,000 records per day across 320 tables—to store profile connection requests and user communication, including direct messages, chats, and video calls. As new features like video chat were added, the database schema had to evolve to support them. Like any SQL database, crucial decisions had to be made, such as when to create a new table or add a column, and choosing the level of normalization and how much duplication of data to allow. Choices that might have been inconsequential when they were made created technical debt for the life of the database.
“This database is often one of the reasons why we haven’t been able to add exciting new features to our product or have caused significant delays in time to market. Impact on existing consumers of this data is one of the significant issues apart from over-indexing and data bloating causing severe performance degradation. Moreover, our DBAs were forever were stuck in firefighting and bug solving cycle managing replica lag, monitoring and trying to find stop gap measures to fix latencies during traffic spikes. This was a major operational overhead for us.”
– Sanket Shah, Sr. Director of Technology at Shaadi.com
Figure 1 that follows describes the data flow from the customer facing applications (web and mobile apps) and the customer relationship management (CRM) system to the self-managed MySQL database. These applications are connected to the database via several business layer APIs which internally use data layer object-relational mapping (ORM) service to communicate.

Figure 1: Old architecture with Amazon EC2-managed MySQL cluster
Issues with the old design
Let’s talk about some issues with the old database design and the traditional ORM layer approach.
Partitioning
Partition-to-USER ID mapping is stored in a separate lookup table. The object-relational mapping (ORM) layer decides in which table the connection or message will be stored after looking up the association. There are hundreds of table variations created for the user profile table to enable partitioning. However, this design led to hot partitions on some read replicas as new users use the application more actively than established users. This overloaded some read replicas in the cluster.
ORM microservice
ORM microservice layer added an unnecessary hop from the client to the database, which increased latency. Moreover, this legacy service frequently became a bottleneck when there were spikes in traffic, which led to loss of connections.
Scaling
Adding capacity was a tedious and time-consuming task as Shaadi.com had to manually remove one of the read replicas from the replication group, create an Amazon Machine Image (AMI) and then ensure the new server and the one that was removed were brought back in sync with the primary database instance. Unused capacity was rarely removed during periods of low traffic because there was no way to rebalance the connections, which led to a lot of underutilized resources.
Solutions considered and decisions made
Because the original database was slowing development and causing operational problems, Shaadi.com set out to compare various databases (open source and proprietary) that would enable a short time-to-market for new features, offer high read/write performance, and provide high reliability while reducing the overall cost.
Ajay Poddar, VP of Engineering at Shaadi.com, said when starting this project, “We evaluate 3 core principles before taking up a modernization initiative: 1. Long term sustainability of the new technology 2. Learning and development of our engineers 3. Reducing overall cost while improving significant performance.”
Hence, this became our guiding markers for evaluating options.
Directly migrating to a managed database like Amazon Aurora MySQL-Compatible Edition would have been the simplest option. But the question Shaadi.com asked themselves was if MySQL was purpose-built for this use case, and if they would have considered the same option if they were designing and building the service today.
A cloud-native SQL database like Amazon Aurora would have met the performance, reliability, and cost optimization requirements, but it wouldn’t have provided the flexibility in traffic patterns and schema changes this use case demanded. The single biggest challenge Shaadi.com developers faced over the years was fitting new features like video calls into a table schema designed for inbox messages, partly because of the effect new features had on downstream services. This lack of flexibility can lead to substandard design, which would force additional compromises on performance. From a product standpoint, the lack of flexibility would increase time-to-market for new features.
Shaadi.com’s basic requirements for a database included:
- The ability to scale based on read and write traffic independently and without downtime.
- The ability to handle sudden spikes in traffic while maintaining consistent latencies in an efficient and cost-effective manner.
- Little to no operational effort to manage the database.
- Support for dynamic schema and nested structures without impacting performance.
- Database-native features for implementing an effective data lifecycle policy.
After multiple rounds of deliberation, DynamoDB emerged as a good choice for this use case as it met most of the requirements. However, it was important to validate our hypothesis through a testing framework that mimicked production traffic patterns.
Figure 2 that follows describes the proposed architecture, showing the switch from using a self-managed MySQL database to DynamoDB in a phased manner using a message broker that pushes the changes to both databases while the migration is completed.
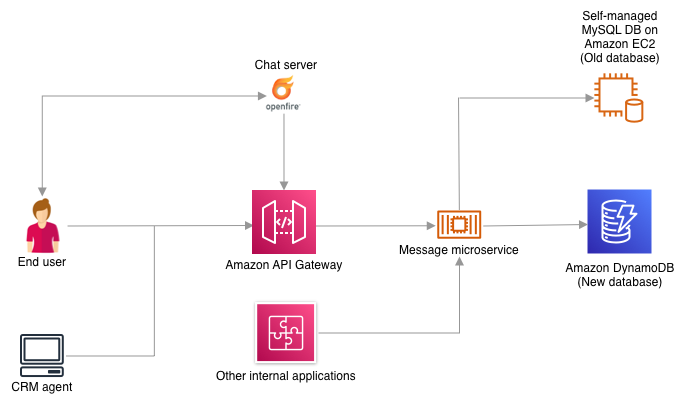
Figure 2: Migration to new architecture with DynamoDB using message broker and a strangler pattern
Validating the new design
Once a database was selected, Shaadi.com spent 6–8 weeks validating the new approach in a test environment.
Schema design and validation by testing access patterns
Shaadi.com had to be careful while porting the schema from the MySQL database to Amazon DynamoDB. While maintaining the data integrity, it had to be ensured that the right design patterns for a NoSQL database were used. This required careful planning around strategies for global secondary indexes, sharding, index overloading, relational modeling with composite keys, and running transactional workflows. Shaadi.com used an automation script to test the revision against all the access patterns at scale. The script included the top 10 user queries, which accounted for 70 percent of the traffic on the current database with instrumentation on p50 and p90 metrics for their respective latencies. This helped them constantly refine the schema from what looked like an RDBMS port to a NoSQL design using the unique features of DynamoDB.
Migration strategy
Shaadi.com wanted to eliminate the redundant ORM layer in the new architecture and have the applications communicate directly with the database. However, this brought about a new challenge. There are more than eight applications that connect to the database and it was impossible to update all the applications at the same time. Moreover, this would have created an additional risk for migration with so many moving pieces requiring precise co-ordination among the application teams to release together. Shaadi.com solved the challenge by using a strangler pattern approach where all the consumer applications were slowly moved to DynamoDB. For this, Shaadi.com had to write a service that would simultaneously write all new changes to both MySQL and DynamoDB. This meant 100 percent of the write traffic was sent through the message service. This message service was used to slowly migrate one application at a time to the new database. This approach helped reduce the risk of sending 100 percent of the read traffic to DynamoDB at once while also providing a way to quickly resolve issues that might arise as more of the data was moved to the new solution.
Cost optimization
Shaadi.com used a two-pronged approach to optimize the cost of the new database. In the beginning, the database was provisioned in on-demand mode for 3 months to ensure that the performance wasn’t restricted while studying the write capacity unit (WCU) and read capacity unit (RCU) behavior. This was also driven by the fact that the traffic patterns weren’t really known on the new database and be sure there were no performance dips at any point in time. Figure 3 that follows shows the graph Shaadi.com used to understand the WCU and RCU patterns over 3 months.

Figure 3: Graph of WCU and RCU over 3 months
The graph in Figure 3 shows that the application is read heavy with both the WCUs and RCUs following a saw-tooth pattern. The peaks and valleys were used from the graph to derive the right provisioned capacity settings. The valleys were used to set the minimum for WCU and RCU, and the peaks plus 25 percent were used to set the maximum value for the auto-scaling policy for provisioned capacity mode.

Figure 4: Cost explorer view for DynamoDB OnDemand compared to provisioned capacity mode
The preceding figure—Figure 4—shows cost optimization of at least 60 percent by switching to provisioned capacity mode without compromising performance. Provisioned capacity was one of the most crucial strategies to ensure read/write performance for the latency-sensitive consumer applications connected to this database.
Performance comparison
One of the most important factors in the decision to go with a purpose-built database instead of a lift-and-shift migration to a managed service was to improve the performance of the application and avoid the technical debt accrued through the years of patchwork on the SQL schema. Shaadi.com used the API for fetching the messages between two users—the most common access pattern in the old database—to evaluate the performance of the new design.
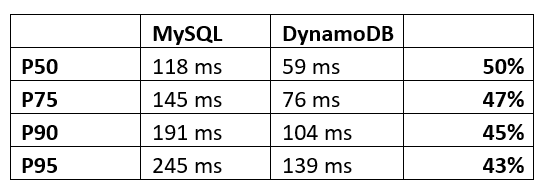
Figure 5: Read performance comparison for GetMessages API before and after moving to DynamoDB showing a 43–50 percent performance improvement.
The preceding figure—Figure 5—shows a more than 40 percent improvement in performance at peak usage in the p50 to p95 values of the GetMessage API compared to the old system. The GetMessage API accounts for the top 10 most frequently called read queries and so the performance improvement in that API has a major impact on overall database performance.
Conclusion
This project was a great example of how choosing a database that is purpose-built for the use case can provide a better outcome than migrating to an equivalent managed service. Performing a detailed analysis of the application and the underlying query patterns led to choosing a purpose-built database that reduced maintenance requirements and enabled accelerated development while significantly improving performance and reducing costs. While moving to a completely new database can be a lot of work, Amazon Web Services (AWS) was able to help Shaadi.com strategize and course-correct at the right times to meet deadlines and objectives. By working backwards from the most common access patterns, Shaadi.com was able to design a purpose-built schema for DynamoDB using database-specific features, evaluate the right provisioned capacity based on the usage patterns, and meet their cost and performance goals for a successful migration.
About the Authors
 Vatsal Shah is a Senior Solutions Architect at AWS based out of Mumbai, India. He has more than 9 years of industry experience, including leadership roles in product engineering, SRE and cloud architecture. He currently focuses on enabling large startups to streamline their cloud operations and help them scale on the cloud. He also specializes in AI and Machine Learning use cases.
Vatsal Shah is a Senior Solutions Architect at AWS based out of Mumbai, India. He has more than 9 years of industry experience, including leadership roles in product engineering, SRE and cloud architecture. He currently focuses on enabling large startups to streamline their cloud operations and help them scale on the cloud. He also specializes in AI and Machine Learning use cases.
 Sanket Shah is a Senior Director technology at People Interactive Pvt. Ltd. based out of Mumbai, India. He has over 15 years of experience in IT project management, application architecture & software development. He has a keen interest in solving complex problems, designing the database, implementing scalable solutions & modernizing legacy systems.
Sanket Shah is a Senior Director technology at People Interactive Pvt. Ltd. based out of Mumbai, India. He has over 15 years of experience in IT project management, application architecture & software development. He has a keen interest in solving complex problems, designing the database, implementing scalable solutions & modernizing legacy systems.