AWS Database Blog
How Zepto scales to millions of orders per day using Amazon DynamoDB
Named after a microscopic unit of time representing 10⁻²¹, Zepto is an Indian quick-commerce venture launched in 2021. The company specializes in lightning-fast delivery services, bringing groceries and essential items to urban consumers in just minutes through its technology platform and optimized logistics network. Operating in multiple cities across India, Zepto has a comprehensive catalog, including fresh produce, electronics, beauty products, clothing, and toys.
Since its launch in 2021, Zepto has undergone significant growth, evolving from initial operations with a single micro-warehouse to now operating more than 1,000 stores and processing millions of orders daily.
Amazon Web Services (AWS) has been a partner in Zepto’s growth journey, providing reliable and scalable services and infrastructure that has helped it grow. To learn more, watch the video Zepto and AWS.
In this post, we describe how Zepto transformed its data infrastructure from a centralized relational database to a distributed system for select use cases. We discuss the challenges encountered with Zepto’s original architecture to support the business scale, the shift towards using key-value storage for cases where eventual consistency was acceptable, and Zepto’s adoption of Amazon DynamoDB—a fully managed, serverless, key-value NoSQL database that delivers single digit milli second latency at any scale. We also discuss how Zepto overcame various challenges, including roll out to production, and the lessons learned.
Previous architecture at Zepto
Born in the cloud, Zepto initially had architected with a simple monolithic application serving its mobile and web applications requests called Zepto Storefront that had its transactional data stored and served from Amazon Aurora PostgreSQL-Compatible Edition, a fully managed, PostgreSQL-compatible, and ACID-compliant relational database engine that combines the speed, reliability, and manageability of Amazon Aurora with the simplicity and cost-effectiveness of open source databases. It had multiple modules, like Order Management, Inventory Management, Payments Service, and more, packaged together as a single web application and deployed on a set of Amazon Elastic Compute Cloud (Amazon EC2) instances, an AWS service that provides sizable compute capacity in the cloud.
We found the monolithic architecture wasn’t supporting Zepto’s growing scale and business demands. To address this, Zepto started decomposing the Zepto Storefront application with a set of simplified, scalable, and robust microservices that have their own purpose-built data stores, deployed on Amazon Elastic Kubernetes Service (Amazon EKS). Amazon EKS is a fully managed Kubernetes service that you can use to run Kubernetes in both the AWS Cloud and on-premises data centers.
With the journey of breaking up the monolithic application halfway through, Zepto application requests were served from both the Zepto Storefront (the monolith) application and the microservices, as shown in the following architectural diagram.
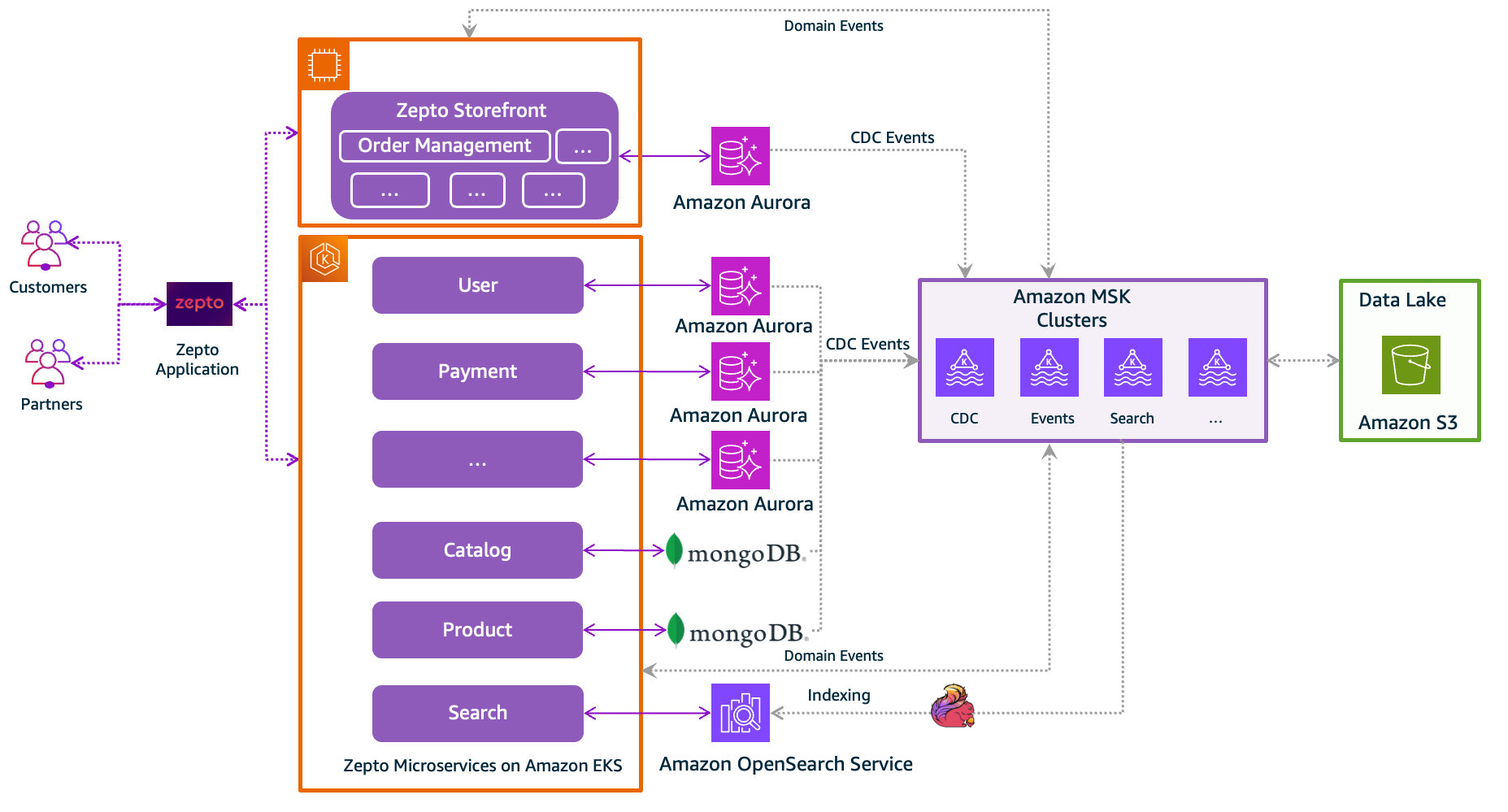
The following are some of the key data stores backing Zepto’s microservices and the Zepto Storefront application:
- Aurora PostgreSQL-Compatible – The microservices—User Management, Payment Services, and more—and the Zepto Storefront application where the Order Management Service (OMS) and other modules exist have their transactional data stored in their own databases set up in Aurora PostgreSQL clusters.
- Amazon OpenSearch Service – Amazon OpenSearch Service is an AWS managed service that you can use to run and scale OpenSearch clusters without having to worry about managing, monitoring, and maintaining your infrastructure, is used by the Search Service that serves Zepto’s products search and discovery use cases.
- MongoDB – The microservices – Catalog, Product Service and more uses MongoDB as the primary data store for storing product, and category related information.
Zepto’s data lake is set up on Amazon Simple Storage Service (Amazon S3), an object storage service that offers industry-leading scalability, data availability, security, and performance. It is kept synchronized with Zepto’s transactional data stores—Aurora PostgreSQL Compatible and MongoDB—with the help of streaming change data capture (CDC) through a Kafka cluster set up with Amazon Managed Streaming for Apache Kafka (Amazon MSK). Amazon MSK is a streaming data service that manages Apache Kafka infrastructure and operations, making it simple for developers and DevOps managers to run Kafka applications and Kafka Connect connectors on AWS. Multiple MSK clusters support Zepto’s requirements, such as the events cluster that facilitates communication between the applications (Zepto Storefront and the microservices), the search cluster that receive batch inference data after data analytics and processing, the CDC cluster, and more.
Challenges
In this section, we discuss the challenges Zepto faced with its Storefront monolithic application, specifically around OMS, one of the core modules, which managed the end-to-end lifecycle of an order.
Performance challenges
When Zepto received orders, each order was created as a new entry in the Aurora Customer_Orders table with an initial status of ORDER_RECEIVED. Due to the high volume of daily order processing over multiple years, the table started accumulating billions of records. This resulted in the following challenges:
- Expensive reads – Although most orders process successfully, some transactions can be delayed or disrupted by various factors, such as payment failures and gateway delays. To manage these cases, Zepto’s automated monitoring jobs regularly scan the
Customer_Orderstable to detect problematic transactions and trigger appropriate responses, including listening to payment service events, triggering orders cancellation for payment failures and more. However, as the table size grew substantially, the frequent execution of these monitoring queries began to experience performance degradation. - Expensive writes – When orders move through different stages from creation to fulfillment, their status needs to be updated in the
Customer_Orderstable, for exampleORDER_RECEIVED,PAYMENT_SUCCESSFULand,ORDER_CONFIRMED. These status updates, triggered by events from MSK topics, required locking the corresponding order records in the table for updating. As a result, multiple concurrent updates often compete for these locks, which led to increased write latency. - Autovacuum during peak hours – Although autovacuum helps improve the performance by invoking VACUUM and ANALYZE commands for removing obsolete data or tuples from the tables and updating query statistics, several parameters can affect when the process gets triggered. Zepto witnessed autovacuum triggered on the
Customer_Orderstable during peak hours, which competed with regular database operations for system resources and eventually impacted read and write operations on the table. Zepto also witnessed autovacuum not keeping up with very frequent data modifications that caused the query planner to use outdated statistics, resulting in inefficient query plans and slower query runtimes.
Operational challenges
To support Zepto’s micro-warehouses operating around the clock, the team faced several operational challenges:
- Autovacuum configuration complexity – The team frequently invested time optimizing various autovacuum parameters for critical large tables, like the
Customer_Orderstable. However, this optimization process grew more complex over time, because team had to constantly adjust settings to handle tables with high data modification rates and evolving usage patterns driven by frequent feature additions to meet business needs. - Monitoring challenges – Beyond autovacuum configuration, the team needed to continuously monitor and adjust numerous database parameters to optimize the
Customer_Orderstable’s performance. This extensive parameter tuning and maintenance work consumed significant time that could have been better spent on core business activities. - Off-peak hours activities – Scheduling resource-intensive operations on the
Customer_Orderstable, such as creating and dropping indexes, had to be performed during off-peak hours.
Data re-architecture
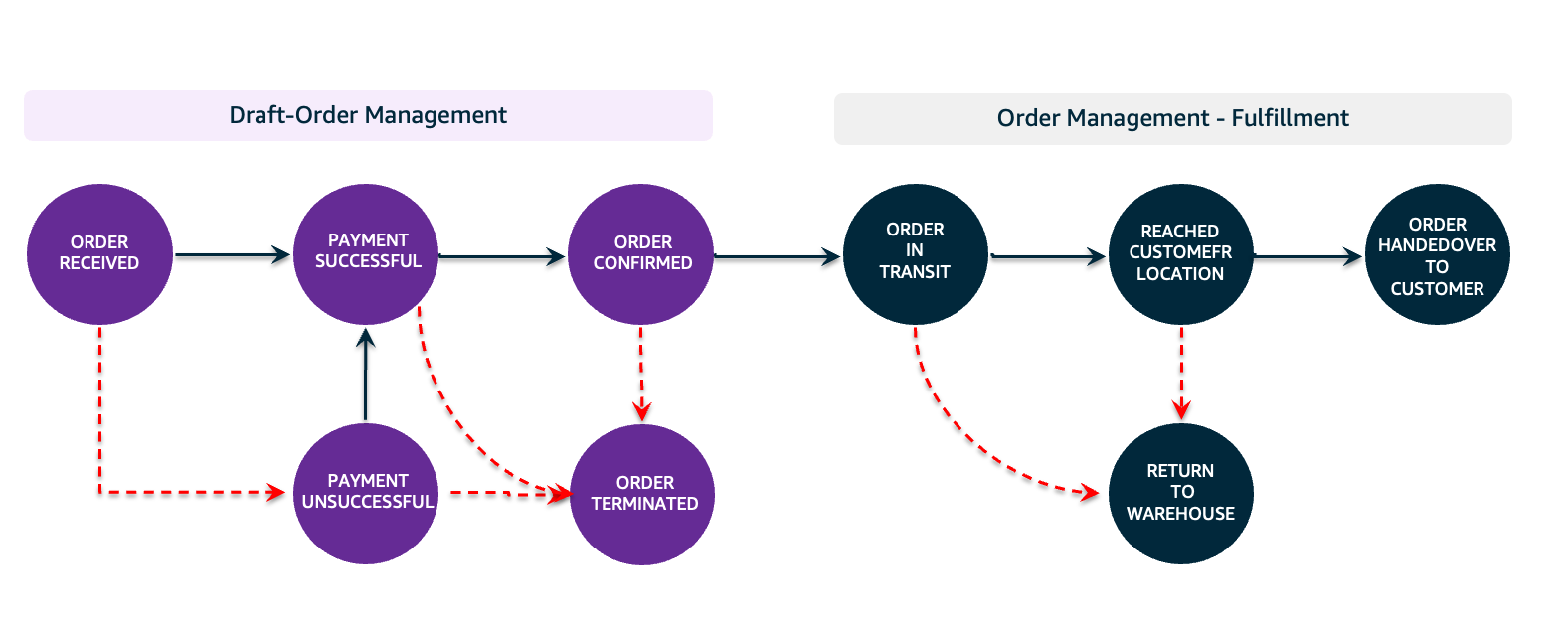
Zepto began exploring methods to restructure its OMS to resolve the challenges related to performance, scalability, and operations through the microservices architecture. Because the OMS can’t be functionally broken down into microservices all in one stage due to other legacy system dependencies, we came up with a hybrid approach: maintaining strongly relational use cases in Aurora PostgreSQL-Compatible while moving non-relational use cases to key-value stores like DynamoDB, which provides consistent performance regardless of scale. This initiative resulted in the creation of a new microservice called Draft-Order service, which handles orders (both successful and unsuccessful) before passing the confirmed orders for which the payment went through to the OMS. This lightweight Draft-Order service is aimed to accept orders regardless of their payment status and provide logical separation between payment-related order status updates from the order fulfillment process. The following diagram represents the order management workflow.
Zepto’s teams have extensive experience with Aurora PostgreSQL-Compatible and its broad application versatility within their applications, but we chose DynamoDB for two key reasons:
- DynamoDB delivers consistent single-digit millisecond performance at any scale
- DynamoDB’s serverless nature brings in operational excellence like no provisioning servers, no version upgrades, no maintenance windows, no patching, no downtime maintenance and more
- Cost analysis based on Zepto’s throughput requirements indicated DynamoDB to be more cost effective.
With those insights, we started designing the Draft-Order service with a DynamoDB table to manage the orders through the following workflow:
- When a new order is received, an entry is added to the DynamoDB table
- The service monitors order-related events from payment services from the events cluster and updates the order status accordingly, such as
PAYMENT_SUCCESSFULorPAYMENT_UNSUCCESSFUL - When the order reaches the successful payment completion status, the service
- calls an idempotent OMS Create Order API that creates an entry in the Aurora PostgreSQL
Customer_Orderstable for fulfillment and other processes - marks the order status as
ORDER_CONFIRMED - publishes the status to the events cluster
- calls an idempotent OMS Create Order API that creates an entry in the Aurora PostgreSQL
This way, payment-related update and read processes that previously happened on the Customer_Orders table through OMS are offloaded to the DynamoDB table through Draft-Order service.
Query access patterns
DynamoDB differs from relational databases because it requires upfront knowledge of query patterns to provide single-digit query performance at scale and efficient use of read/write capacity units; see First steps for modeling relational data in DynamoDB for more details. Therefore, our first step was to identify specific query access patterns:
- Get order – Get the order using
ORDER_ID, a unique identifier of an order used throughout as the referential key in other Aurora PostgreSQL tables - Update order – Update the order item attributes like order status using
ORDER_ID - Get orders where payment was unsuccessful – Get orders that have remained in a specific status longer than the given time. This is particularly useful for identifying orders with extended payment processing issues or incomplete transactions beyond a timeframe, allowing for appropriate follow-up actions
DynamoDB schema modeling
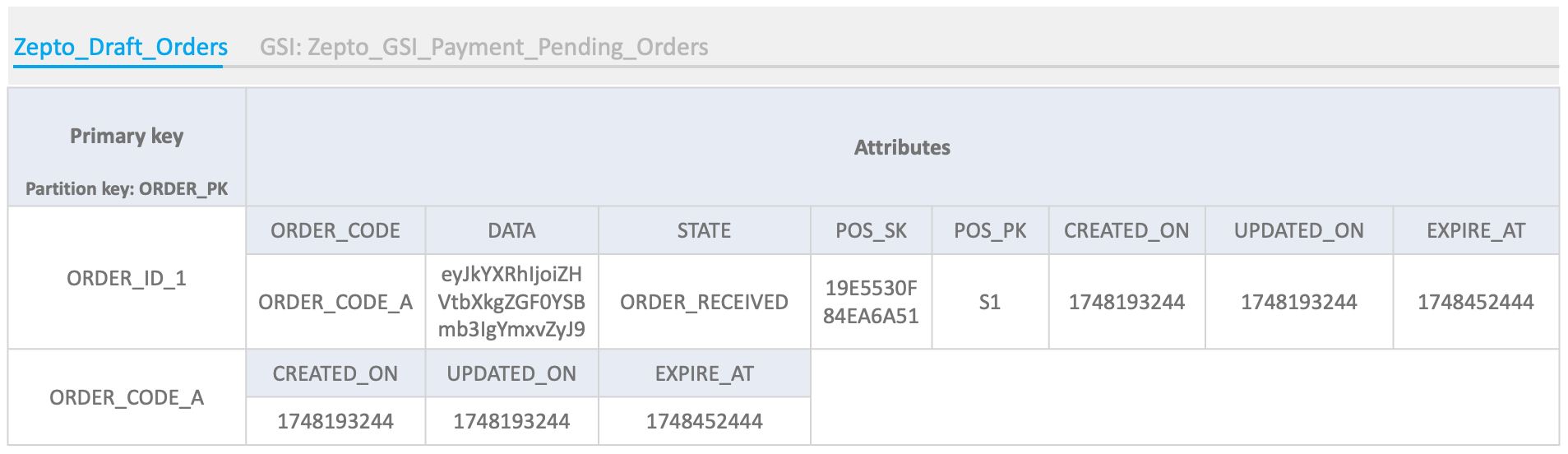
After we had identified the access patterns, we moved forward with the schema design in collaboration with the AWS team. The Draft_Orders table is the base table that stores the required details of the orders placed by Zepto’s customers, with ORDER_PK (unique identifier of an order) as the partition key, and other attributes:
- ORDER_PK – The partition key that can have one of two types of order identifiers:
- ORDER_ID: A unique identifier used for internal service-to-service communication
- ORDER_CODE: A human-readable unique identifier
The prefix “ORDER_ID” or “ORDER_CODE” is added to the value for identification.
- STATE – Order status like
ORDER_RECEIVED,PAYMENT_SUCCESSFUL,ORDER_CONFIRMEDand more. - EXPIRE_AT – Time to live (TTL)
- DATA – Snapshot of the attributes of the order that will be stored in the Aurora PostgreSQL
Customer_Orderstable upon successful payment completion - POS_PK– Pending Order Scan Partition Key, an attribute that helps in keeping orders in the global secondary index (GSI) uniformly across partitions. See Using Global Secondary Indexes in DynamoDB for more details.
- POS_SK – A time ordered key
- CREATED_ON and UPDATED_ON – Creation and update timestamp
The following screenshot illustrates these details.
Most of the values of keys and the attributes size are limited in size, except for the values of the DATA attribute, which vary in the range of tens of KBs, which required careful consideration while designing the schema; see Best practices for storing large items and attributes in DynamoDB for additional details. Because of this, we choose Snappy, a fast and efficient data compression and decompression technique for the DATA attribute values. See Example: Handling binary type attributes using the AWS SDK for Java document API for details on how to implement compression logic for binary type attributes.
DynamoDB’s Time To Live (TTL) feature helps in automatically removing items within a few days after their specified expiration timestamp. The Draft_Orders table uses the TTL feature where each order is configured with an EXPIRE_AT attribute. So, the order entries get deleted within few days of their expiration, leaving the table with the latest orders. During this window, scheduled jobs periodically check for orders that have remained beyond a typical timeframe, and they trigger appropriate actions to ensure all the orders reach either ORDER_CONFIRMED or ORDER_TERMINATED status.
While the first three access patterns are well served with pointed queries on Draft_Orders table, the fourth access pattern requires retrieving orders that remained in ORDER_RECEIVED status longer than the given time. While it can be achieved by querying the base table using attributes that are not part of the primary key, it may not be efficient; hence, we created a GSI with POS_PK as the partition key, and POS_SK as the sort key. In addition, we selected only the CREATED_ON attribute in the GSI that is required for fetching the orders basis their creation time, rather than including all the base table attributes. This targeted approach helps minimize storage and write costs, since a smaller index with fewer projected attributes is more cost-efficient; see GSI Attribute projections for additional details. The following screenshot illustrates the GSI keys and projected attributes’ details.

To prevent hot partition issues and for distributing the orders evenly across partitions, we use POS_PK; see Designing partition keys to distribute your workload in DynamoDB for more details. Additionally, this POS_PK helps filter and maintain only those orders that still need payment completion in the GSI. It is achieved by nullifying the POS_PK value in the base table upon both successful and unsuccessful payment by the Draft-Order service. When the POS_PK value is nullified in the base table, the corresponding entry eventually gets removed from the GSI, leaving only the orders requiring payment to be completed in the GSI.
To take action on payment incomplete orders, the Draft-Order service runs scheduled jobs for every 5 minutes that query the GSI for payment pending orders. Some of them might get through with orders marked ORDER_CONFIRMED because their payments succeed with alternate payments during the process, whereas some might not, which eventually get marked as ORDER_TERMINATED after the configured number of retries.
Current architecture
Zepto continued to refactor its Storefront into purpose-built microservices with their own data stores. Bringing in the Draft-Order service backed by DynamoDB became a natural fit with the existing system of microservices, as shown in the following architectural diagram.
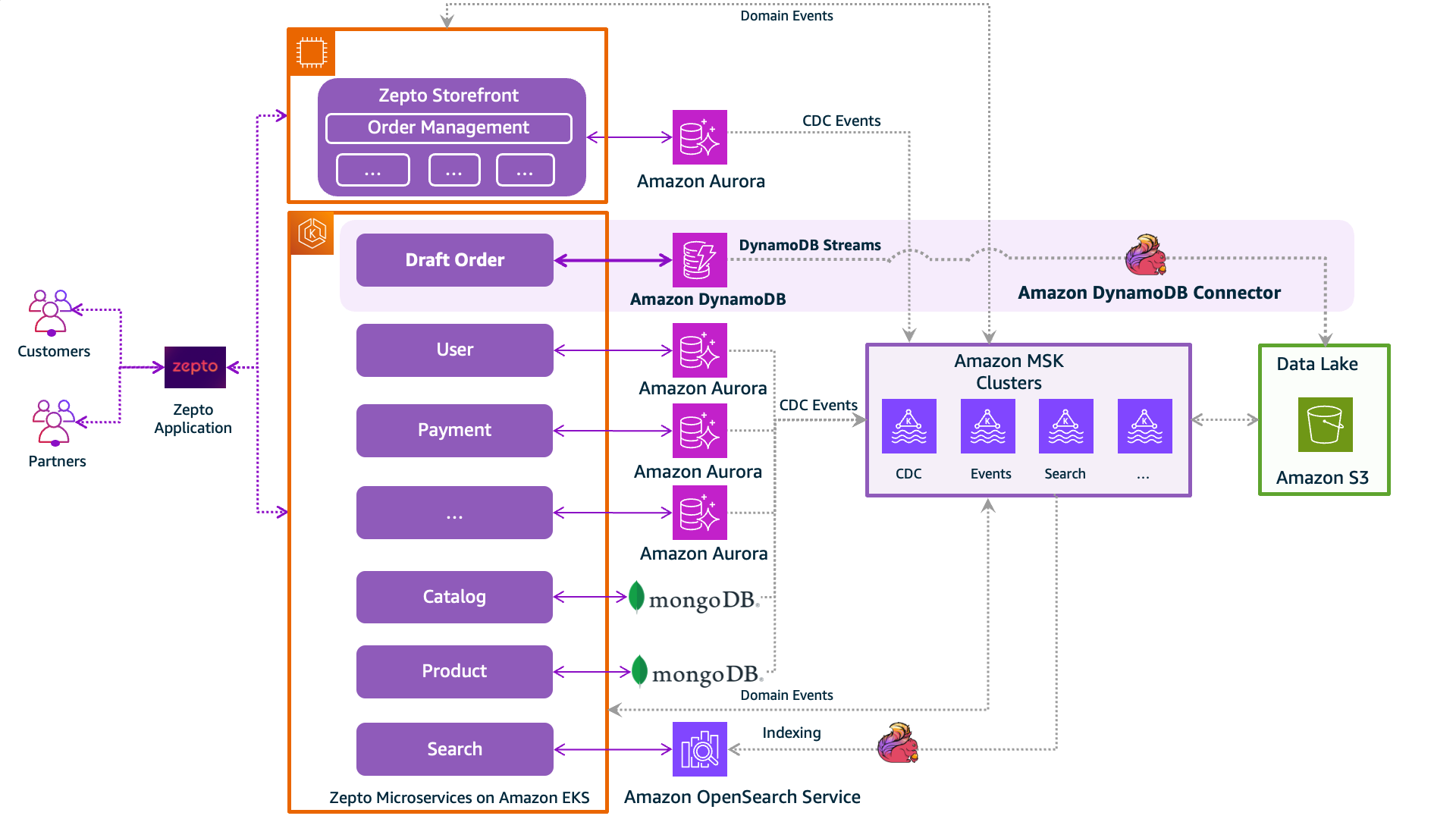
By enabling Amazon DynamoDB Streams, which captures a time-ordered sequence of item-level modifications in the Draft_Orders table, Zepto processes the CDC logs using the Apache Flink connector for DynamoDB that writes the stream data into the data lake for further processing. See DynamoDB Streams and Apache Flink for additional details.
Rollout to production
The new architecture with the DynamoDB table is designed to hold the last few days of orders, and hence data migration and back-filling from the Customer_Orders table have been completely skipped. With this new architecture in place, initially 10% of read and write operations were offloaded from the Aurora PostgreSQL Customer_Orders table to a DynamoDB Draft_Orders table.
To maintain the uniqueness in the Draft_Orders table for both ORDER_CODE and ORDER_ID for any order, the team had combined two operations within a single transaction using TransactWriteItems API, as shown in the following code (see Managing complex workflows with DynamoDB transactions for additional details):
The team’s initial tests showed that the above statements in the DynamoDB Transaction had an average latency of approximately 18 milliseconds. After investigating, we discovered that including non-essential synchronous operations within a transaction was causing performance issues. To improve performance, we removed these operations from the transaction and instead used two separate PutItem API calls – one for creating the order with ORDER_CODE without any order related details followed by creating the order with the ORDER_ID, ORDER_CODE and other order related details in sequence. This change delivered two main benefits.
- Response times became consistently fast, staying under 10 milliseconds per DynamoDB API call
- We cut DynamoDB’s Write Capacity Unit consumption in half since we eliminated the transaction overhead. Note: Transactions in DynamoDB require two read/write operations per item, as explained in Capacity management for transactions.
The key lesson from this experience was to avoid bundling operations in transactions unless absolutely necessary. See Best practices for transactions for additional details.
Following these improvements, Zepto implemented the changes gradually: first to 30% of production traffic and then expanding to full production deployment.
Benefits of adopting DynamoDB
The new architecture offered several improvements over the previous monolithic architecture using Aurora PostgreSQL:
- Improved performance:
- The Create Order API’s performance improved by 60% on average, and 40% for p99
- Zepto experienced consistent, single-digit millisecond performance for operations on the DynamoDB table, which wasn’t the case with the previous architecture
- Reduced operational overhead: Zepto engineers were freed from the undifferentiated heavy lifting operational tasks like cluster maintenance, including patching, upgrading, and parameter fine-tuning based on multiple metrics
- Improved scalability: DynamoDB’s serverless nature enables Zepto to scale from quiet late-night deliveries to high-demand festival rushes and sports event peaks – all without managing servers.
Conclusion
In this post, we shared the challenges that Zepto experienced with its monolithic data management architecture, and how it adopted DynamoDB with a microservices-based architecture. With this migration, Zepto now handles millions of orders daily while cutting costs, achieving a 60% faster Create Order API and enhanced operational efficiency and scalability. Given these positive outcomes, Zepto is now looking to implement DynamoDB in other areas of their business.
It is common to see developer teams trying to find the one-size-fits all database, which doesn’t exist. We recommend developers to find a database that matches their specific application needs. AWS database services are specialized for handling specific data models and access patterns, offering optimized performance, scalability, and cost-effectiveness compared to general-purpose databases. To explore AWS’ purpose-built database offerings, refer to AWS Cloud Databases.