AWS Database Blog
Improving generative AI accuracy with vector and graph search hybrid queries
Many artificial intelligence (AI) applications begin the same way: choose a vector database, generate embeddings, and build a retrieval pipeline. This works well until it doesn’t. Vector search excels at finding what is semantically similar, but it cannot reveal what is structurally connected. And in many real-world scenarios, the most important context is not only semantically close to your query, it is linked through relationships that similarity search can’t navigate. Knowing when to combine graph databases with vector search can make the difference between an AI application with good context and one with richer context. In this post, we discuss the differences between vector search and graph search, how to combine the two for hybrid querying, and use cases that benefit from hybrid querying.
Understanding vector search
Vector search has become foundational to modern AI applications, because it excels at finding semantically similar things. Embedding models transform raw data into a mathematical representation, capturing the semantic features within it. When you query a vector database, it returns words, phrases, or chunks of data with the same meaning to your input. This makes vector search particularly effective for enterprise search applications, where finding content with similar intent is the primary goal. For example, vector embeddings representing terms in the same domain will typically be close together in vector space. Vector space can be thought of as similar to a geographical map, but instead of 2 dimensions (latitude and longitude), you have the same number of dimensions as your embeddings.
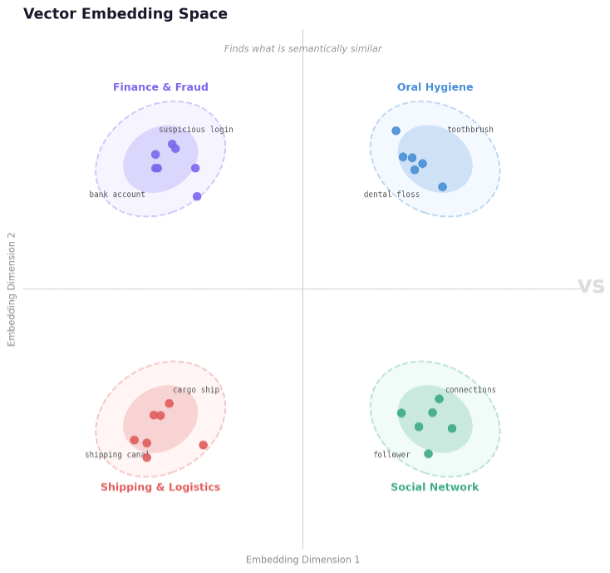
AWS offers several options for vector storage, including Amazon ElastiCache for Valkey, Amazon OpenSearch Service, Amazon Relational Database Service (Amazon RDS) for PostgreSQL with pgvector, and Amazon S3 Vectors, to name a few. These services have become the starting point for most AI workshops and tutorials, making them familiar territory for developers entering the generative AI space. However, semantic similarity alone leaves a critical gap. Not all relevant information shares similar meaning. Sometimes the most important context is related through connections, not semantic resemblance.
Understanding graph search
Graph databases solve a fundamentally different problem. Rather than finding similar content, graphs reveal how information connects. These connections can represent various relationships: parent-child hierarchies, cause-and-effect chains, sequential ordering of events, or even taxonomic categorizations. You can even have graphs that connect all of that information into a single view.
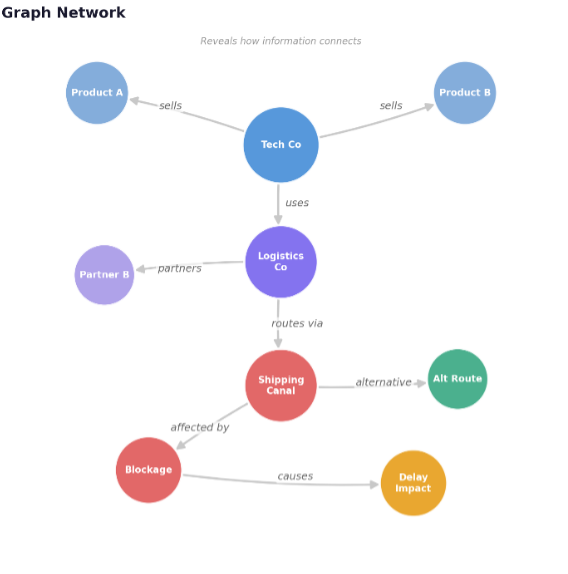
A classic example of a graph is the social network. On platforms like LinkedIn or Facebook, you have friends, your friends have friends, and their friends have additional connections. This creates a highly interconnected network where relationships matter more than similarity.
AWS solutions for graph databases
Amazon Neptune is a fully managed graph database service that supports both property graph and Resource Description Framework (RDF) graph models, providing high availability, ACID transactions, and support for graph query languages Gremlin and openCypher (for property graphs) and SPARQL (for RDF graphs). Amazon Neptune Analytics is a memory-optimized graph database engine for analytics that extends these capabilities by providing integrated vector storage alongside graph data in a unified data store, so you can run both graph traversals and vector similarity searches in the same query. Neptune Analytics supports the openCypher query language, as well as loading property graph data and RDF data serialized as ntriples.
To implement graph search with these services, you would:
- Model your entities and relationships to define nodes and edges.
- Set up a Neptune Database cluster and choose your graph model.
- Ingest your data using bulk loading or streaming.
- Query with Gremlin, openCypher, or SPARQL to explore connections.
When evaluating whether a graph database fits your use case, consider two key factors:
Many-to-many connections: Does your dataset contain complex interconnections? In social networks, one person might have five friends, but if those friends are celebrities with thousands of connections each, you quickly see the explosive growth of relationship data.
Connection-dependent queries: Do your questions require knowledge of how things connect? If you only need to fetch individual records, a simple key-value store suffices. But if you need to find friends-of-friends recommendations or identify community clusters, graph databases become essential.
Beyond social networks, graph databases excel in fraud detection and financial crimes investigation. A user’s login event and a suspicious transaction might have no semantic similarity, yet their connection through timing and location patterns reveals critical insights that vector search would miss.
Hybrid query patterns
The real power emerges when combining vector and graph search, which requires a graph store and a vector store. Neptune Database can be used alongside other vector stores—for example, OpenSearch Service or Amazon RDS for PostgreSQL with pgvector. Alternatively, Neptune Analytics can be used as a single data store, because it can store both graph data and vectors and supports hybrid vector-graph search that combines semantic similarity with relationship traversal in the same query.
Two query patterns make this possible:
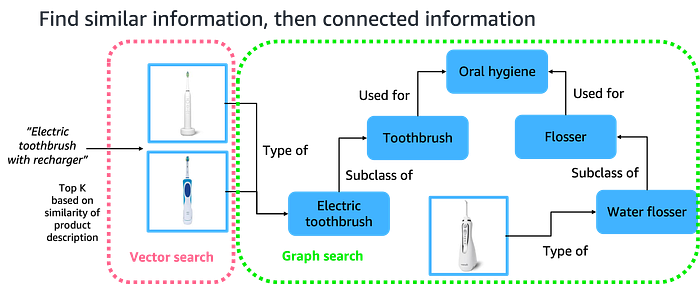
Vector first, then graph
This pattern uses vector search to find similar information, then graph traversals to discover related context. Consider an ecommerce platform where a customer searches for “rechargeable electric toothbrush.” Vector search excels at matching product descriptions to surface relevant toothbrush models with those features.
Once the customer adds a toothbrush to their cart, graph databases can surface complementary product recommendations. A product ontology in the graph shows that electric toothbrushes belong to the oral hygiene category, which also includes water flossers, toothpaste, and dental floss. These products might not be semantically similar enough to “electric toothbrush” to be surfaced in the top K search, but they’re highly relevant because they serve related purposes.
This approach enhances customer experience by surfacing items that pure vector search would never return, because they don’t match the original search terms.
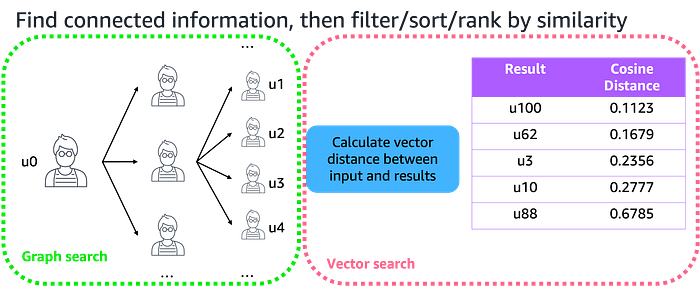
Graph first, then vector
This pattern reverses the flow, using graph search to find connected information, then applying vector similarity to filter and rank results. For example, in a social networking platform, a friends-of-friends algorithm might return thousands of potential connections. Without filtering, this list becomes overwhelming. You only want to recommend the top few people that are most likely to form a friendship.
Vector similarity can provide a solution. By generating embeddings from user profile descriptions, interests, and activities, you can then rank those thousands of candidates by semantic similarity to the original user’s profile description, interests, and activities. Semantic similarity between candidate friends and the original user can then be measured by calculating the vector distance, using a method such as cosine similarity. This helps make sure recommendations are both connected through the social graph and aligned with the user’s interests.
GraphRAG: combining both approaches
GraphRAG is the natural evolution of retrieval-augmented generation (RAG), and uses hybrid graph and vector queries. Vector-based RAG finds semantically similar chunks of text to provide context for large language models (LLMs). GraphRAG adds a key layer: discovering relevant but dissimilar information through graph relationships.
Consider a research scenario analyzing sales prospects for a new tech company in the UK. A document repository contains articles about the company’s products, logistics partnerships, shipping routes, and current events affecting transportation infrastructure.

The vector RAG limitation
Vector RAG searches for chunks semantically similar to “sales prospects,” “example corp,” and “UK.” It successfully retrieves articles about anticipated holiday demand and product innovations. Based on this context, an LLM predicts excellent sales prospects.

However, we can see from the preceding diagram that vector search misses important information. Articles about the company’s logistics partner, the shipping canal that partner uses, and recent blockages affecting that canal are all semantically dissimilar to the query. Yet these details significantly affect the actual sales outlook.
The GraphRAG solution
GraphRAG solves this context gap by representing entity relationships. The graph connects the tech company to its logistics partner, the partner to the shipping canal it uses, and the canal to current blockage incidents. When traversing these connections, GraphRAG surfaces all relevant context: both the semantically similar optimistic projections and the dissimilar but connected supply chain disruptions.
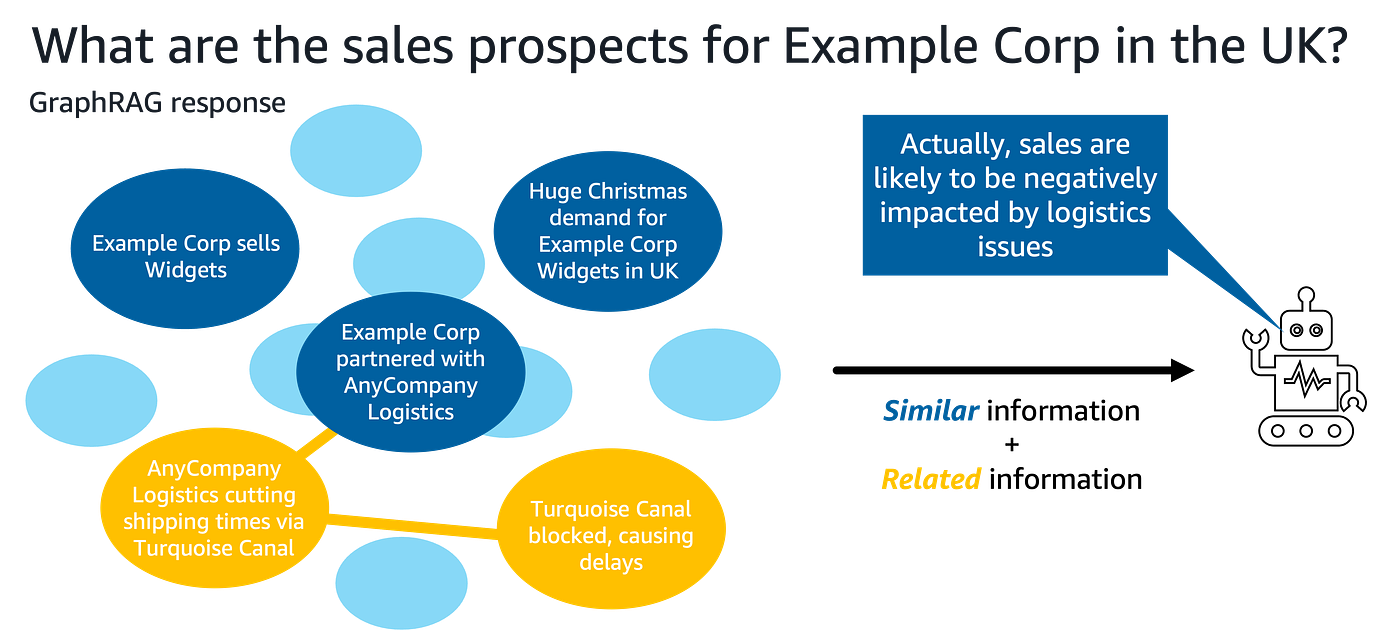
With this enriched context, the LLM now provides a nuanced response acknowledging both positive demand signals and challenging logistics realities. This difference in the final response is critical. If we were an analyst researching whether or not to invest in Example Corp, we would take very different decisions based on the vector RAG outcome compared to the GraphRAG outcome.
GraphRAG architecture
The architecture for GraphRAG builds on traditional RAG workflows with these key additions:
- Entity extraction adds depth. Beyond chunking, the system extracts entities (such as companies, locations, products) and their relationships from the text.
- Graph construction captures connections. Entities become nodes and relationships become edges, creating a knowledge graph that maps not only how concepts interconnect, but also how entities connect.
- Hybrid retrieval combines vector search with graph search. At query time, vector search identifies semantically similar starting points, and a graph traversal explores connected information to build comprehensive context.
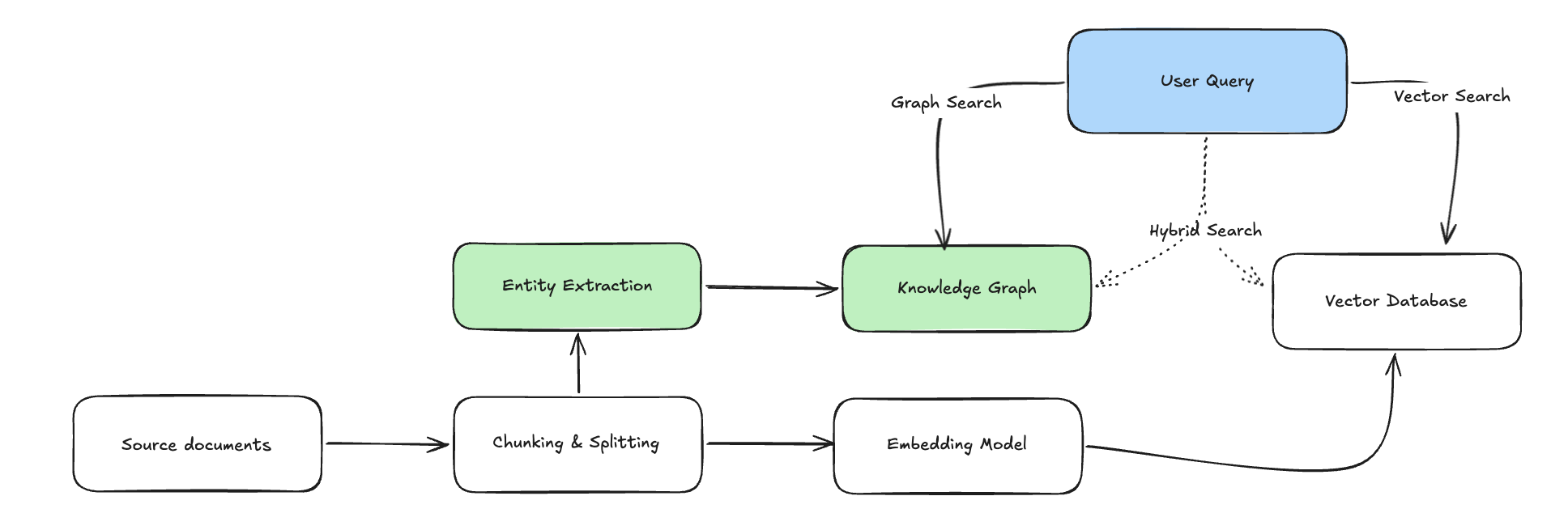
By combining both a vector search and a graph search, we provide enhanced context to our LLM, which in turn improves accuracy. The LLM receives both similar and related information, producing more comprehensive and accurate responses.
You can build a GraphRAG application using Amazon Bedrock Knowledge Bases GraphRAG, which is a fully managed solution that uses Neptune Analytics for the underlying graph and vector store. Alternatively, open-source tools like the GraphRAG Toolkit provide frameworks for building graph-enhanced generative AI applications. These tools simplify common tasks like entity extraction, relationship mapping, and hybrid query execution. If you’re interested in getting started with GraphRAG with Amazon Neptune, refer to these examples. For more information about using hybrid queries, download and work through this sample Jupyter notebook.
Real-world applications
Graph databases and GraphRAG are finding applications across diverse industries:
- Financial services use graphs for fraud detection, identifying suspicious patterns across accounts, transactions, and shared attributes like addresses or IP addresses.
- Cybersecurity platforms map relationships between threats, vulnerabilities, and assets to understand threat behaviors and risk exposure.
- Healthcare systems connect patient records, treatments, outcomes, and research to support clinical decision-making.
- Retail platforms build product ontologies to power recommendations and improve search relevance.
- Enterprise knowledge management links documents, concepts, and organizational relationships to help employees find information through multiple pathways.
Graph databases aren’t niche technology. They’re a general-purpose tool for any domain where context lives in connections.
Conclusion
In this post, we showed the differences between vector search and graph search, how to combine the two for hybrid querying, and use cases that benefit from hybrid querying, such as GraphRAG.
Vector databases changed how we build AI applications. Graph databases, especially when combined with vector search through hybrid queries and GraphRAG, represent the next evolution. They allow AI systems to reason not only about what’s similar, but about what’s connected, delivering more comprehensive, accurate, and contextually rich results.
The key is recognizing when your use case benefits from understanding connections, not only similarity. If your questions require knowing how information relates, if your recommendations depend on complementary rather than similar items, or if your analysis needs to follow chains of cause and effect, graph databases belong in your architecture.