AWS Database Blog
Netflix consolidates relational database infrastructure on Amazon Aurora, achieving up to 75% improved performance
Netflix operates a global streaming service that serves hundreds of millions of users through a distributed microservices architecture. To effectively serve these customers, the engineering organization relies on its infrastructure teams that build internal tools and abstractions to accelerate developer productivity while maintaining operational excellence.
The Online Data Stores (ODS) team is one such group, managing persistent data store solutions across the organization. They evaluate developer requirements, assess production workloads, and provide subject matter expertise for data store decisions. In this post, we examine the technical and operational challenges encountered by the ODS team with their current self-managed distributed PostgreSQL-compatible database, the evaluation criteria used to select a database solution, and why they chose to migrate to Amazon Aurora PostgreSQL-Compatible Edition to meet their current and future performance needs. The migration to Aurora PostgreSQL improved their database infrastructure, achieving up to 75% increase in performance and 28% cost savings across critical applications: Spinnaker achieved 50% average latency reduction and Policy Engine reduced average latency by 75% (from 26.72 milliseconds to 6.51 milliseconds).
Business challenge
The ODS team’s objective is to build data infrastructure solutions that accelerate developer productivity, reduce operational overhead for both infrastructure and application teams, deliver consistent and reliable performance under varying loads, and provide scalability to support growing data volumes and user bases. However, they recognized that their fragmented relational database strategy was undermining these objectives. Managing multiple PostgreSQL-compatible engines, including a licensed self-managed distributed PostgreSQL-compatible database as their primary relational database solution, created operational inefficiencies that impacted both infrastructure teams and the developer community.
The infrastructure team was burdened with self-managed databases on Amazon Elastic Compute Cloud (Amazon EC2), consuming valuable time with operational overhead from deployments, patching, scaling, and maintenance activities while facing rising licensing costs. The developer experience was equally impacted from this fragmented approach. Engineers faced inconsistent database deployment processes across multiple engines, which slowed application development. Additionally, manual scaling procedures during traffic spikes led to performance degradation and production incidents. The diverse database landscape also required teams to maintain expertise across multiple systems, making it challenging to establish unified best practices and specialization. Recognizing these challenges, the ODS team initiated an evaluation of database solutions to consolidate their infrastructure and improve both operational efficiency and developer experience.
Database evaluation criteria
To assess database options, Netflix established evaluation criteria aligned with their team principles across four key dimensions. First, for developer productivity, the solution needed to use existing developers’ PostgreSQL expertise to minimize learning curves, maintain PostgreSQL compatibility to enable application portability with minimal code changes, and integrate with existing business intelligence (BI) and developer tools. Second, their operational efficiency requirements focused on reducing management complexity through simplified replica management, which adapts to Netflix’s unpredictable traffic patterns. Netflix needed full infrastructure abstraction that removes backup, failover, and infrastructure management concerns, so engineers can focus on innovation rather than maintenance.
Third, the team’s performance reliability criteria emphasized high availability to support Netflix’s stringent uptime requirements with near-zero downtime during upgrades, automatic storage scaling capabilities for enhanced operational experience, performance consistency that matches or improves upon existing infrastructure, and multi-Region reader support for cross-Region read replicas enabling low-latency local reads. Finally, scalability considerations centered on cost- efficiency through lower total cost of ownership compared to legacy database licensing, combined with the ability to support expanding workloads and accommodate future use cases as Netflix’s data ecosystem continues to grow.
After evaluating multiple database solutions against these criteria, Netflix selected Aurora PostgreSQL as the preferred database solution for relational workloads.
Why Netflix chose Aurora
In this section, we discuss the key reasons why Netflix chose Aurora for its database infrastructure.
Meeting data infrastructure performance requirements
The evaluation revealed that most use cases were single-Region workloads, whereas others required multi-Region support that could be served by Aurora Global Database, which uses asynchronous storage-based replication, with typically less than 1 second cross-Region replication lag. This enables low-latency read operations for applications connecting from geographically distributed locations. Among the single-Region workloads, they identified an optimization opportunity to simplify the replication model used by the self-managed distributed PostgreSQL-compatible database and remove the coordination of Raft-style consensus, resulting in lower write latencies, reduced operational cost, and improved overall performance. The Aurora architecture delivered the performance improvements needed through the following features:
- Log-based write operations – Aurora uses a log-based approach that sends only redo log records to the distributed storage layer instead of writing full data pages, unlike conventional database engines. These log records are written in parallel to a quorum of storage nodes across three Availability Zones (requiring four of six nodes to acknowledge), enabling higher write throughput and lower latency while maintaining durability.
- Shared storage architecture – Aurora separates compute and storage layers through a fault-tolerant distributed system that spans three Availability Zones in an AWS Region. This architecture addressed the data infrastructure’s core requirements while maintaining high availability and durability.
Eliminating operational overhead
Aurora is a fully managed relational database engine that alleviates the manual deployment, patching, scaling, and maintenance efforts previously required with self-managed PostgreSQL-compatible databases on Amazon EC2. Aurora read replicas serve dual purposes as both read scaling solutions and automatic failover targets, sharing the same storage volume as the writer instance while consuming the log stream asynchronously. This lag is usually much less than 100 milliseconds after the primary instance has written an update. When the primary writer instance experiences issues, Aurora automatically fails over to one of up to 15 read replicas within the same Region, which assumes the writer role without data loss by using the shared storage architecture. This automated failover capability avoids the complex failover scenarios and partial outage recovery procedures that previously required manual intervention, providing continuous availability without operational overhead. Moreover, with Aurora PostgreSQL, developers can use their existing PostgreSQL expertise without retraining. Applications required minimal or no code changes during migration due to PostgreSQL compatibility. This compatibility preserved development velocity while enabling teams to maintain productivity throughout the transition and benefit from performance improvements without disrupting existing workflows.
Ammar Khaku, Staff Software Engineer on the Netflix Online Data Stores team, stated
“We no longer have to build and deploy custom binaries on EC2 with internal security and metrics-related patches. Switching to off-the-shelf managed Aurora PostgreSQL lets us focus on business logic and data access patterns.”
Enhancing application responsiveness and developer experience
Aurora significantly improved the developer experience by minimizing cross-AZ latency overhead that had reduced application and development tool responsiveness in the self-managed distributed PostgreSQL-compatible database. The distributed nature of the prior solution required simple read queries to be redirected from coordinator nodes to other cluster nodes across different Availability Zones, creating multiple network hops and increased latency. The shared storage architecture in Aurora serves reads locally while maintaining data consistency, allowing the database engine to allocate 75% of instance memory to shared buffers by default. This higher allocation compared to the typical 25–40% in standard PostgreSQL is because Aurora avoids double buffering between PostgreSQL’s shared buffers and the operating system page cache, which allows more queries to be served from memory rather than disk. These architectural improvements minimized network overhead and delivered up to 75% faster response times.
Achieving cost-efficiency
Aurora’s pay-as-you-go pricing model delivered 28% cost savings compared to license-based pricing. As a fully managed database service, Aurora reduces heavy lifting through capabilities like storage auto-scaling up to 256 TB and continuous incremental backup to Amazon Simple Storage Service (Amazon S3) with up to 35 days retention for automated backups, removing manual capacity management and backup procedures that previously required dedicated operational resources. Additionally, read replicas incur no additional storage costs because instances share the underlying storage volume, further lowering the cost while maintaining high availability and performance.
Migration results
As of October 2025, Netflix has migrated several applications from the self-managed distributed PostgreSQL-compatible database to Aurora PostgreSQL. In this section, we review the performance after migration of two applications: Spinnaker (Front50) and Policy Engine.
Spinnaker (Front50)
Front50 is the metadata microservice for Spinnaker, the continuous delivery system used across Netflix. The workload involves storing and retrieving orchestration components such as pipelines. Quicker querying of pipeline states directly affects Spinnaker UI responsiveness, making the management of deployments faster for nearly all Netflix developers. Front50 saw the following benefits from the migration:
- Average latency – Approximately 50% reduction (from 67.57 milliseconds to 41.70 milliseconds)
- Maximum latency – Approximately 70% reduction with fewer spikes
- Stability – Much more consistent performance patterns
The following graph shows the latency improvements for the Front50 microservice.

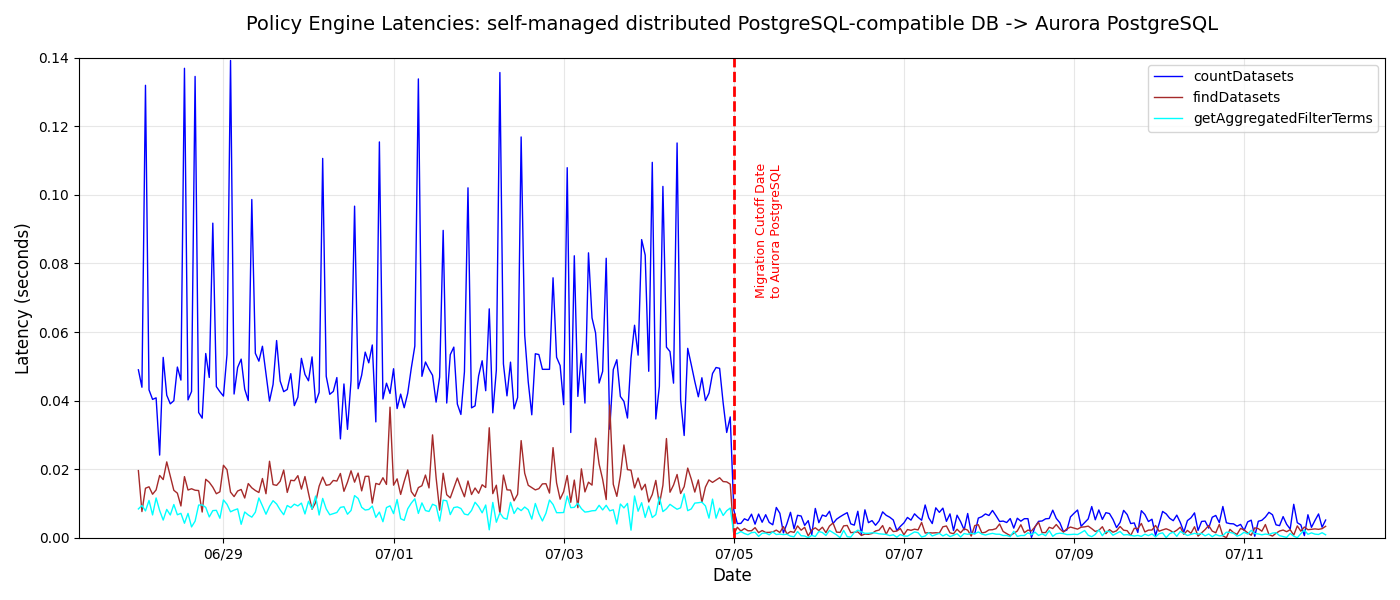
Policy Engine
Policy Engine is a rules engine and state machine for Netflix, providing a framework for implementing, evaluating, and enforcing data governance and efficiency policies across data store systems used at Netflix. The workload involves flagging data assets (tables, databases, clusters) for policy violations, managing violation state machines that automatically execute remediation actions, and notifying stakeholders. Reduction in latency allows Policy Engine jobs to run faster, reducing the time it takes to triage alerts ensuring compliance gaps are closed more swiftly. Policy Engine saw the following latency improvements from the migration:
- Overall improvement – Decreased latency across all endpoints from the July 4, 2025, migration date
- Specific endpoints – Notable decreased latency in the following endpoints:
countDatasetsreduced from approximately 5.40 milliseconds to 1.90 millisecondsfindDatasetsreduced from approximately 26.72 milliseconds to 6.51 millisecondsgetAggregatedFilterTermsreduced from approximately 12.11 milliseconds to 3.51 milliseconds
- Stability – Consistent latencies reduced to under 0.02 seconds compared to previous 0.04–0.08 seconds with frequent spikes
The following graph shows the latency improvements across key Policy Engine endpoints.
Conclusion
Netflix’s strategic migration from a self-managed distributed PostgreSQL-compatible database to Aurora PostgreSQL demonstrates a comprehensive approach to database consolidation that delivered measurable results across performance, cost, and operational efficiency. The migration achieved up to 75% performance improvements and 28% cost savings, while eliminating the operational overhead of self-managed databases. Following their migration efforts to Aurora PostgreSQL, Netflix has reduced performance spikes while providing predictable latency patterns for developer-focused systems that support Netflix’s internal operations and development processes. These improvements, combined with Aurora’s fully managed capabilities, have established Aurora PostgreSQL as the preferred relational database solution for Netflix’s developer community.
To evaluate Aurora PostgreSQL for your own database workloads, refer to Getting started with Amazon Aurora and Best Practices with Amazon Aurora to understand implementation guidance and optimization techniques.