AWS Database Blog
Creating a proof of concept using Amazon Aurora
As customers move to the cloud, they’re looking for the best tools to run their applications. When considering relational databases, Amazon Aurora is a frequent choice. This is no surprise, given that Amazon Aurora is MySQL and PostgreSQL wire-compatible and that it can provide greater throughput than either. Aurora provides up to five times the […]

Introducing Gremlin query hints for Amazon Neptune
Amazon Neptune is a fast, reliable, fully managed graph database, optimized for storing and querying highly connected data. It is ideal for online applications that rely on navigating and leveraging connections in their data. Amazon Neptune supports W3C RDF graphs that can be queried using the SPARQL query language. It also supports Apache TinkerPop property […]

Design patterns for high-volume, time-series data in Amazon DynamoDB
Time-series data shows a pattern of change over time. For example, you might have a fleet of Internet of Things (IoT) devices that record environmental data through their sensors, as shown in the following example graph. This data could include temperature, pressure, humidity, and other environmental variables. Because each IoT device tracks these values over […]

Deploy an Amazon Aurora PostgreSQL DB cluster with recommended best practices using AWS CloudFormation
In this blog post, I cover how to build a quick start reference deployment of Amazon Aurora PostgreSQL cluster. The cluster is based on AWS best practices for security and high availability and you can create it quickly by using AWS CloudFormation. I walk through a set of sample CloudFormation templates, which you can customize […]
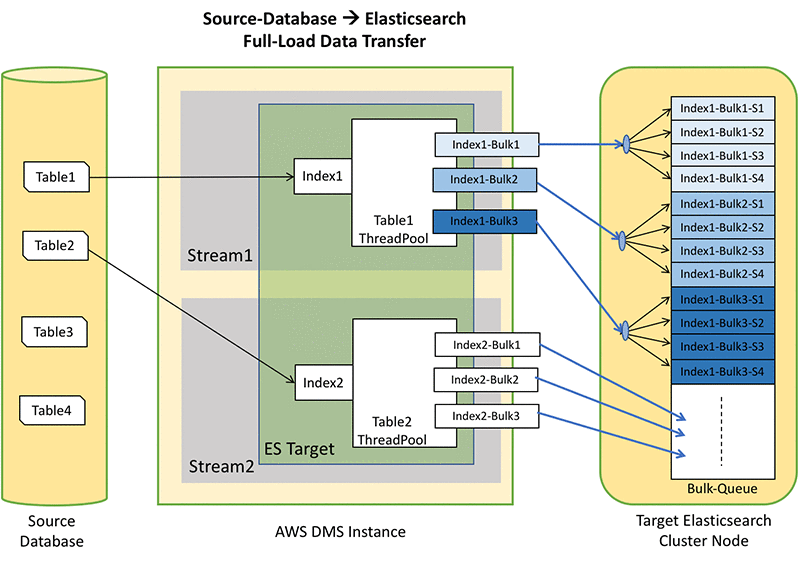
Scale Amazon OpenSearch Service for AWS Database Migration Service migrations
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. A common pattern for web application architecture includes a database for application data coupled with a search engine for searching that data. Many relational and even nonrelational databases offer rudimentary search capabilities. However, search engines add true, complex, natural-language search […]

Setting up for cross-account native backup and restore in Amazon RDS for Microsoft SQL Server
Reviewed and updated on June 2022. Amazon Relational Database Service (Amazon RDS) supports native backup and restore for Microsoft SQL Server databases. If you have multiple AWS accounts, you can perform native backup and restore across these accounts, provided that your Amazon RDS instance and the Amazon Simple Storage Service (Amazon S3) bucket are in […]

Recap of Amazon RDS features launched in 2018
Amazon Relational Database Service (Amazon RDS) makes it easy to set up, operate, and scale a relational database in the cloud. It provides cost-efficient and resizable capacity. At the same time, it automates time-consuming administration tasks such as hardware provisioning, database setup, patching, and backups. It frees you to focus on your applications so you […]

Upgrade Your End of Support Microsoft 2008 R2 Workloads in AWS with Ease
Many IT organizations have run the Microsoft Windows Server 2008 R2 operating system, SQL Server 2008 and SQL Server 2008 R2 database systems for over a decade. End-of-support (EOS) dates are fast approaching (July 2019 for SQL Server and January 2020 for Windows Server). Thus, it’s critical these systems get upgraded to a supported version […]

Run a petabyte scale cluster in Amazon Elasticsearch Service
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. When you use Amazon Elasticsearch Service (Amazon ES) for log data, you’re drinking from what usually becomes […]

Best practices for configuring parameters for Amazon RDS for MySQL, part 3: Parameters related to security, operational manageability, and connectivity timeout
August 2025: This post was reviewed for accuracy. In the previous blog post of this series, I discuss MySQL parameters used to optimize replication in Amazon Relational Database Service (Amazon RDS) for MySQL and best practices related to them. In today’s post, I discuss the most important and commonly used MySQL parameters for implementing various […]