AWS Database Blog
Stream changes from Amazon RDS for PostgreSQL using Amazon Kinesis Data Streams and AWS Lambda
In this post, I discuss how to integrate a central Amazon Relational Database Service (Amazon RDS) for PostgreSQL database with other systems by streaming its modifications into Amazon Kinesis Data Streams. An earlier post, Streaming Changes in a Database with Amazon Kinesis, described how to integrate a central RDS for MySQL database with other systems by streaming modifications through Kinesis. In this post, I take it a step further and explain how to use an AWS Lambda function to capture the changes in Amazon RDS for PostgreSQL and stream those changes to Kinesis Data Streams.
The following diagram shows a common architectural design in distributed systems. It includes a central storage, referred to as a single source of truth, and several derived “satellite” systems that consume this central storage.
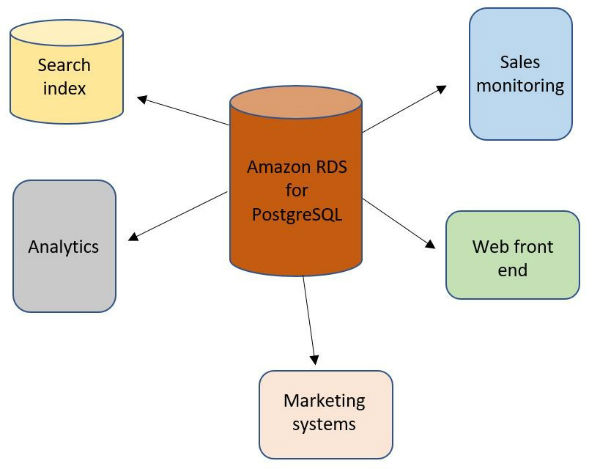
You can use this design architecture and have a relational database as the central data store, taking advantage of the transactional capabilities of this system for maintaining data integrity. A derived system in this context could be a full-text search system that observes this single source of truth for changes, transforms and filters those changes, and finally updates its internal indexes. Another example could be columnar storage that is more appropriate for OLAP queries. In general, any system that requires taking action when individual rows of the central relational system are modified is a good candidate to become a derived data store.
A naive implementation of these kinds of architectures has the derived systems issuing queries periodically to retrieve modified rows, essentially polling the central database with a SELECT-based query (often known as a batch processing system). On the other hand, a better implementation for this architecture is one that uses an asynchronous stream of updates.
Databases usually have a transaction log where all the changes in rows are stored. Therefore, if this stream of changes is exposed to external observer systems, those systems could attach to these streams and start processing and filtering row modifications. In this post, I show a basic implementation of this using PostgreSQL as the central database and Kinesis Data Streams as the message bus.
Normally, the PostgreSQL Write-Ahead Logging (WAL) file is exposed to read replicas that read all the changes on the master and then apply them locally. Instead of reading data from a read replica, I use logical decoding using the wal2json output plugin to decode the contents of the WAL directly. You can download the plugin from this GitHub repository. Logical decoding is the process of extracting all persistent changes to a database’s tables into a coherent, easy-to-understand format that can be interpreted without detailed knowledge of the database’s internal state.
To continuously read the changes from the RDS for PostgreSQL WAL logs and push the changes into Kinesis Data Streams, I use an AWS Lambda function. At a high level, this is what the end-to-end process looks like:
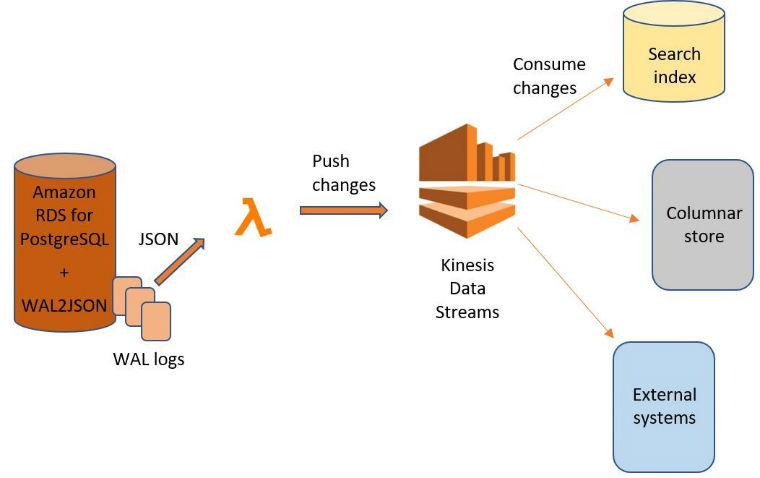
One important detail of this method is that the consumers won’t receive SQL queries. Those can be exposed too, but in general, observers aren’t very interested in SQL unless they maintain a SQL-compatible replica of the data themselves. Instead, they receive modified entities (rows) one by one.
The benefits of this approach are that consumers don’t need to understand SQL, and the single source of truth does not need to know who will consume its changes. That means that different teams can work without coordinating among themselves on the required data format. Even better, given the capabilities of Kinesis Data Streams clients to read from a specific point in time, each consumer processes messages at its own pace. This is why a message bus is one of the less coupled ways to integrate your systems.
In the example used in this post, the rows fetcher is a regular Python process that attaches to the central database, simulating a read replica. The database can be either Amazon RDS or any installation of PostgreSQL. In the case of Amazon RDS, the fetcher process must be installed on a different host (for example, Amazon EC2 or a Lambda function) because you can’t install custom software on RDS instance hosts. For external installations, you can install the fetcher process on the same host as the database.
Preparing the master PostgreSQL instance
You must configure the PostgreSQL master (the single source of truth) as if it were a master for regular replication. WAL logs must be enabled—that is, for RDS for PostgreSQL, you simply need to enable the backup. Also, PostgreSQL logical replication on Amazon RDS is enabled by a new parameter, a new replication connection type, and a new security role. The client for the replication can be any client that is capable of establishing a replication connection to a database on a PostgreSQL DB instance. For more information, see Logical Replication for PostgreSQL on Amazon RDS.
The logical replication slot knows nothing about the receiver of the stream. So, if you set up a logical replication slot and don’t read from the slot, data can be written to your DB instance’s storage, and the storage can fill up quickly. The most common clients for PostgreSQL logical replication are AWS Database Migration Service (AWS DMS) or a custom-managed host on an Amazon EC2 instance. If, for example, you configure an AWS DMS task and don’t actively consume the changes, you might end up filling up your storage on the DB server.
To enable logical replication for an Amazon RDS PostgreSQL DB instance, you must do the following:
- Ensure that the AWS user account that initiates the logical replication for the PostgreSQL database on Amazon RDS has the
rds_superuserand therds_replication.Therds_replicationrole grants permissions to manage logical slots and to stream data using logical slots. - Set the
rds.logical_replicationparameter to 1. It is a static parameter that requires a reboot to take effect. As part of applying this parameter, set thewal_level,max_wal_senders,max_replication_slots, andmax_connectionsparameters. These parameter changes can increase WAL generation, so you should set therds.logical_replicationparameter only when you are using logical slots. Note:
Note:
- The default
wal_levelis REPLICA. - After you set
rds.logical_replicationto 1, thewal_levelis set to LOGICAL.
- The default
- Create a logical replication slot and choose a decoding plugin. In this example, I use the
wal2jsonI create the replication slot using Python, as shown in the next few steps.
Modifying the DB instance
After you modify the instance to use a new parameter group, the instance shows pending reboot and must be rebooted for the new parameter group to take effect. After rebooting the instance, you should be able to verify the new parameters, as follows:
For details on modifying an RDS DB instance, see Modifying a DB Instance Running the PostgreSQL Database Engine.
Adding permissions to the database user
If you are using the default master user that is created by Amazon RDS, you might already have the required permissions. If not, you must create a user with REPLICATION permissions, as in the following example:
Creating a Kinesis data stream
You need a Kinesis data stream and boto3 client credentials. For information about client credentials, see the Boto 3 documentation. You can create a data stream by using either the AWS CLI or the Amazon Kinesis console.
Create a Kinesis data stream by using the following AWS CLI command:
Or, open the Amazon Kinesis console, and choose Data Streams in the navigation pane. Then choose Create Kinesis stream: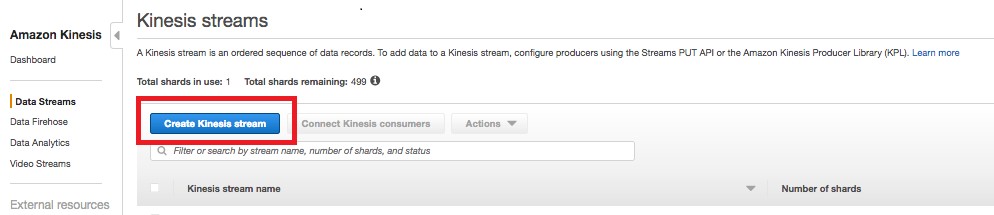
Type a name for your stream and the number of shards. In this example, there is a single shard.
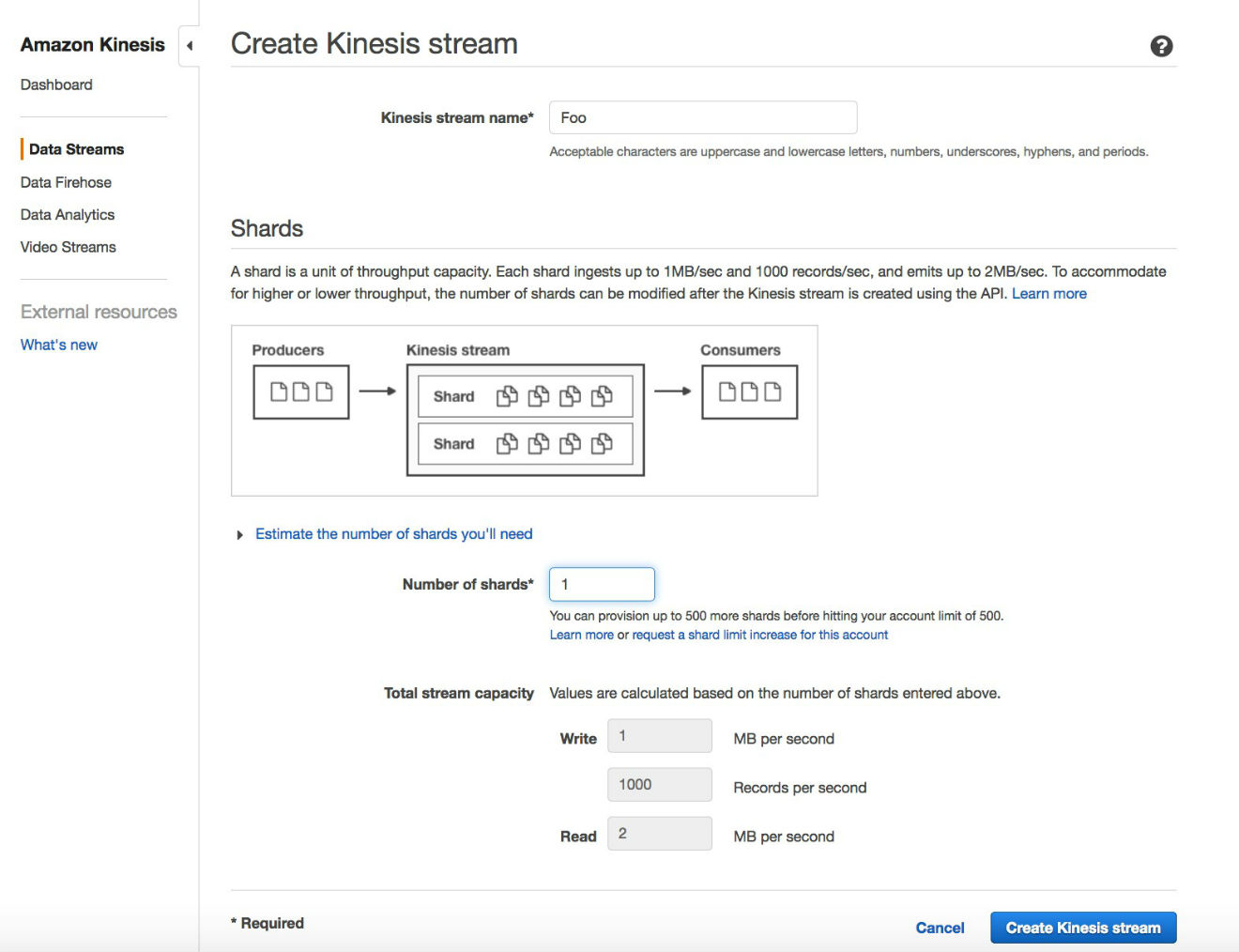
After a few minutes, your stream is ready to accept row modifications!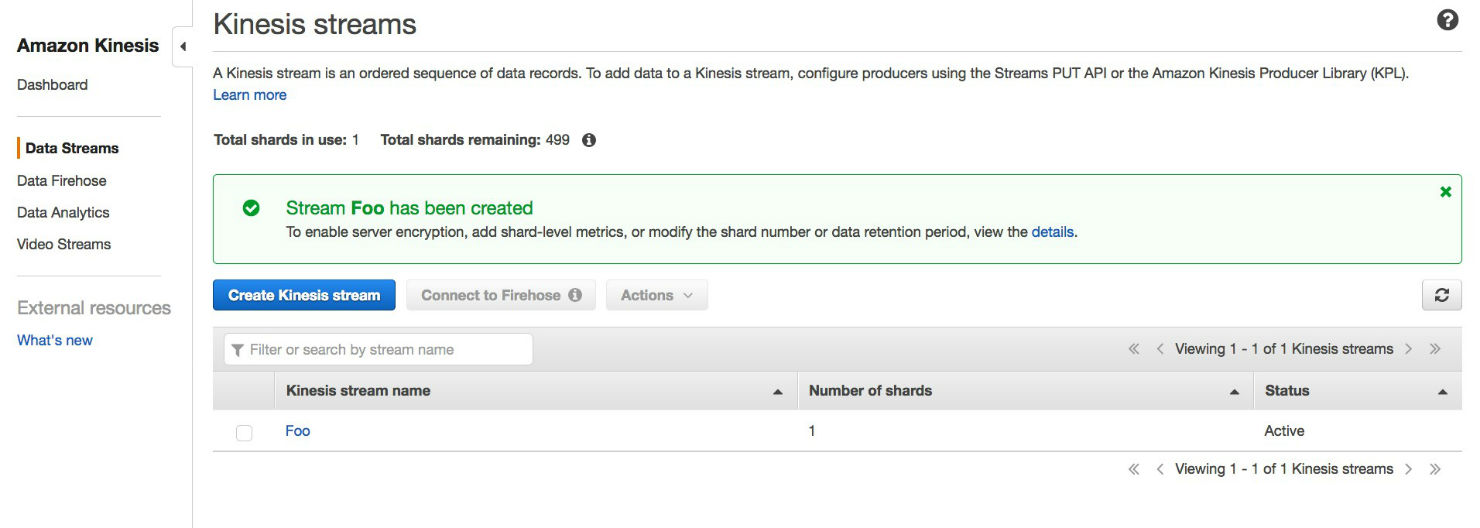
Assigning permissions to your AWS CLI user
You can use AWS Identity and Access Management (IAM) to grant permissions to the CLI user that will be accessing this stream.

In this example, that user is kinesis-rds-user. You can create a user or use an existing one, but you need to add permissions for writing to the Kinesis data stream.
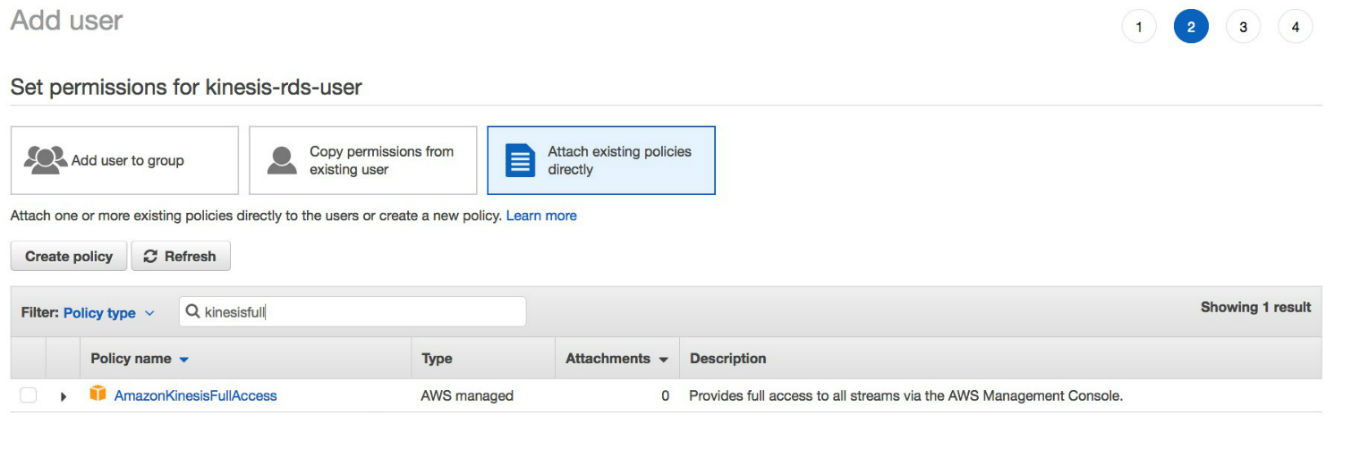
You can create a policy that is specific for your stream. This example uses a standard policy that gives complete access to Kinesis Data Streams.
Publishing the messages to a Kinesis data stream
To read changes from WAL logs and publish them to Amazon Kinesis, you can use one of the following:
- An Amazon EC2 machine with an access key ID and a secret access key
- A Lambda function with an IAM role
Here I show you both ways using a simple Python program. However, note that this example is test code and is not production ready.
Option 1: Using an Amazon EC2 machine
To use an EC2 machine with the kinesis-rds-user AWS access key ID and AWS secret access key that was created earlier in the post, set your credentials as shown following:
Use this Python code:
Note: I used an optional print(msg.payload), which shows the following output printed. For example, on RDS for PostgreSQL, I run this sample DML:
And the Python code shows the following:
Option 2. Using an AWS Lambda function
To use an AWS Lambda function, you can re-use the preceding Python code and package it in a deployment package. For more information, see Creating a Deployment Package (Python) in the AWS Lambda Developer Guide.
In this example, I used psycopg2, which is a popular PostgreSQL adapter for the Python programming language. The following shows what my package looks like:
With app.py, it looks like the following:
Creating an IAM role
Before you create the AWS Lambda function, you must ensure that there is an appropriate IAM role that has permission to access Kinesis and the Amazon RDS database. Also, you need to create the Lambda function in an appropriate virtual private cloud (VPC), with appropriate security groups attached so that it can access Amazon RDS and Kinesis Data Streams.
In the IAM console, you can create an IAM role to be assigned to the Lambda function, as shown following:

Creating an AWS Lambda function
Now, you can use the AWS CLI to create a Lambda function as follows:
Testing
After creating the Lambda function, you can launch and test it.
On a side note, in another session, you can also test whether the records are being published into your Kinesis data stream by using a shell script, as follows:
In this example, it shows that my records are being published into the Kinesis data stream:
Consuming the messages
Now you are ready to consume the modified records. Any consumer code would work. If you use the code in this post, you will get messages in JSON format as shown preceding.
Summary
In this post, I showed how to expose the changes stream to the records of a database using Amazon Kinesis Data Streams. Many data-oriented companies are using architectures similar to this. Although the example provided in this post is not ready for a real production environment, you can use it to experiment with this integration style and improve the scaling capabilities of your enterprise architecture. The most complex part is probably what is already solved behind the scenes by Amazon Kinesis Data Streams.
Additional resources
For more information, see the following resources:
JSON output plugin for changeset extraction (GitHub)
Replication connection and cursor classes (Psycopg 2.7.5 documentation)
Adding replication protocol (PDF file)
About the Author
 Jatin Singh is a partner solutions architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Jatin Singh is a partner solutions architect at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.