AWS Database Blog
How to perform ordered data replication between applications by using Amazon DynamoDB Streams
AWS customers use Amazon DynamoDB to store mission-critical data. These customers’ applications make millions of requests per second to individual DynamoDB tables that contain hundreds of terabytes of items. They count on DynamoDB to return results in single-digit milliseconds.
In many cases, these applications have requirements to notify other systems and users about specific transactions, audit or archive transactions, and replicate data to other data stores in near-real time. The applications can meet these requirements by maintaining the order in which changes were made to items in DynamoDB. Building such capabilities requires that changes to items in DynamoDB be processed in parallel to achieve near-real-time performance.
You can integrate Amazon DynamoDB Streams with other AWS services to build ordered, near-real-time data processing capabilities. DynamoDB Streams captures a time-ordered sequence of item-level modifications in a DynamoDB table and durably stores the information for up to 24 hours. Applications can access a series of stream records from a DynamoDB stream in near-real time.
This post evaluates multiple patterns for processing DynamoDB streams by using several AWS services that are part of AWS serverless computing. It also dives into the details about the most reliable and scalable pattern to perform near-real-time processing of DynamoDB streams to notify other systems and users, archive transactions, and replicate data to other data stores while ensuring ordered processing.
Process DynamoDB streams using AWS Lambda
AWS Lambda is a service that lets you run code without provisioning or managing servers. For example, Lambda can execute your code based on a DynamoDB Streams event (such as inserting, updating, or deleting an item). Lambda polls a DynamoDB stream and, when it detects new records, invokes your Lambda function and passes in one or more events.
To understand how Lambda processes DynamoDB streams, you have to understand how DynamoDB streams work. DynamoDB stores data in partitions, which are based on either a partition key only or both a partition key and a sort key. When you enable a stream on a DynamoDB table, DynamoDB creates at least one shard per partition.
Shards in DynamoDB streams are collections of stream records. Each stream record represents a single data modification in the DynamoDB table to which the stream belongs.
The following diagram shows the relationship between a stream, shards in the stream, and stream records in the shards. For more information about shards, see Capturing Table Activity with DynamoDB Streams.

The following diagram shows a DynamoDB table with three partitions. With streams enabled for this table, DynamoDB creates a minimum of three shards, one per partition. DynamoDB relays changes (inserts, updates, and deletes) that are performed on each item within a partition to the corresponding shard by maintaining the order of the changes made. This process ensures that a given key is present in at most one shard and its order is maintained.
When a Lambda function is configured to process DynamoDB streams, one instance of the Lambda function is invoked per shard. Because the following illustrated DynamoDB stream has three shards, three Lambda functions are invoked concurrently whenever there is a change to an item or items within each partition.

Configure multiple Lambda functions with DynamoDB Streams
When you use DynamoDB to configure multiple Lambda functions with a stream to enable parallel processing of data, each function is concurrently invoked per shard. The following diagram shows an example of two Lambda functions that are configured with a DynamoDB stream and with each of these functions being concurrently invoked.

Though DynamoDB lets you configure multiple Lambda functions with a stream, configuring more than two Lambda functions per stream increases the possibility of failed requests. The number of Lambda functions or processes that are allowed to read from a DynamoDB stream might increase in the future. To reliably process data in real time within a stream, you need to ensure that the Lambda function requests succeed. To enable parallel, ordered processing of stream data and have successful Lambda function requests, implement a fan-out pattern.
Use fan-out patterns to process DynamoDB streams
There are several fan-out patterns for processing DynamoDB streams:
- Lambda fan-out pattern
- Amazon SNS fan-out pattern to Amazon SQS
- Kinesis Data Streams fan-out pattern
Lambda fan-out pattern
In a Lambda fan-out pattern, you configure a single Lambda function to process the DynamoDB stream. Lambda polls a DynamoDB stream and, when it detects new records, invokes this Lambda function by passing in one or more events. The Lambda function processes each item and invokes downstream services or APIs.
The following example shows a Lambda function processing a DynamoDB stream. It invokes another Lambda function to notify users, updates a DynamoDB table, and writes to an Amazon Kinesis data stream. The throughput of this function is dependent on its ability to perform bulk operations on the downstream services or APIs.

Pros of using a Lambda fan-out pattern include the following:
- On Lambda function processing failure, Lambda retries the entire batch of records until it succeeds or the data expires from the stream. This retry mechanism helps ensure that all events are processed in order. For more information about how AWS Lambda handles failures, see Understanding Retry Behavior.
Cons of using this pattern include the following:
- The handling of partial failures results in Lambda retries, which make the system not quite real time.
- Guaranteeing message write ordering is a challenge when dealing with partial failures when writing to downstream services.
- Lambda functions must be redeployed to send data to new downstream services.
- Upon Lambda processing failures, the entire batch of records is reprocessed. This may lead to duplication of records within Kinesis Data Streams or DynamoDB.
- Throughput of the Lambda function is reduced as and when new downstream data stores or applications are introduced.
Amazon SNS fan-out pattern to Amazon SQS
Amazon Simple Notification Service (Amazon SNS) is a flexible, fully managed publish/subscribe messaging and mobile notifications service for coordinating the delivery of messages to subscribing endpoints and clients. Amazon Simple Queue Service (Amazon SQS) is a fully managed message queuing service that makes it easy to decouple and scale microservices, distributed systems, and serverless applications.
In an Amazon SNS fan-out pattern to Amazon SQS, you configure a single Lambda function to process a DynamoDB stream. Lambda polls a DynamoDB stream and, when it detects a new record, invokes this Lambda function by passing in one or more events. The Lambda function processes each item and writes it to an SNS topic using the Publish API.
When you create SQS queues that subscribe to an SNS topic, each queue receives identical notifications every time a message is pushed to the topic. Services attached to these SQS queues can then process these messages asynchronously and in parallel.
In the following example, a Lambda function that is processing the DynamoDB stream writes a message to an SNS topic. SNS delivers the message to each SQS queue that is subscribed to the topic. Lambda functions that are scheduled by using Amazon CloudWatch Events are used to further process these messages and communicate with downstream services or APIs.
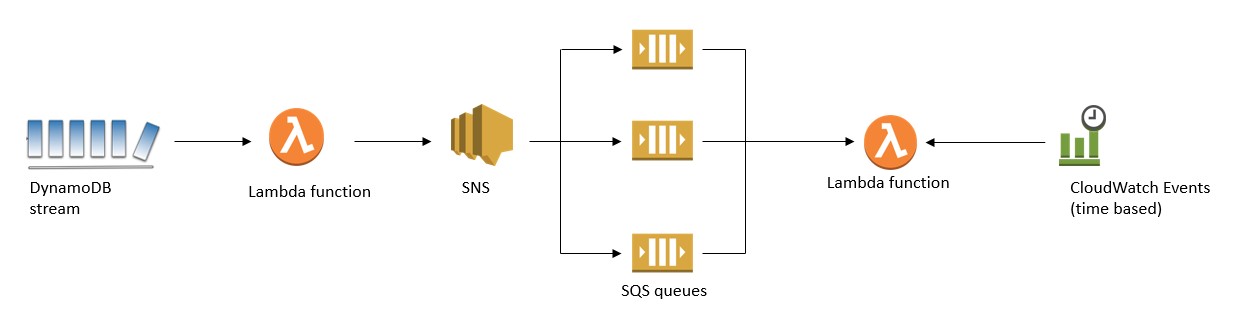
Pros of using this pattern include the following:
- Provides an extensible subscription mechanism because many AWS services can be subscribed to an SNS topic.
- On Lambda function processing failure, Lambda retries the entire batch of records until it succeeds or the data expires from the stream. This retry mechanism ensures that all events are processed in order. For more information about how AWS Lambda handles failures, see Understanding Retry Behavior.
Cons of this pattern include the following:
- Amazon SNS limits message size to 256 KB, so the DynamoDB item size should be within this limit.
- Message write ordering is not possible during partial failures when SNS writes to SQS queues.
- Failure handling results in retries, which make the system not quite real time.
- Messages in Amazon SQS are processed by Lambda functions that are scheduled using CloudWatch Events, making the system not quite real time.
- Upon Lambda processing failures, the entire batch of records is reprocessed. This can lead to the duplication of records within SQS.
Kinesis Data Streams fan-out pattern
You can use Kinesis Data Streams to build custom applications that process or analyze streaming data. Kinesis Data Streams can continuously capture and store terabytes of data per hour from hundreds of thousands of sources.
In the Kinesis Data Streams fan-out pattern, you configure a single Lambda function to process the DynamoDB stream. Lambda polls a DynamoDB stream behind the scenes. When it detects a new record, it invokes your Lambda function by passing in one or more events. The Lambda function processes each item and writes to a Kinesis data stream by using the PutRecord API. You can process Kinesis data streams by using Lambda or Kinesis applications that are built using the Kinesis Client Library (KCL).
The following example illustrates this fan-out pattern.

Pros of using the Kinesis Data Streams fan-out pattern include the following:
- Kinesis Data Streams provides a way to write-order events that are generated by DynamoDB.
- On Lambda function processing failure, Lambda retries the entire batch of records until it succeeds or the data expires from the stream. This retry mechanism ensures that all events are processed in order. For more information about how AWS Lambda handles failures, see Understanding Retry Behavior.
- Allows further fan-out of Kinesis data streams by chaining together multiple data streams.
- Allows data archiving to Amazon S3, Amazon Redshift, and Amazon OpenSearch Service using Kinesis Data Firehose.
- Enables data aggregations using a partition key other than the partition key defined in the DynamoDB table.
Cons of this pattern include the following:
- Throughput is limited because this pattern encourages a serial invocation pattern of the PutRecord API to ensure write ordering.
- Upon Lambda processing failures, the entire batch of records is reprocessed. This can lead to duplication of records within Kinesis Data Streams and thereby in the downstream DynamoDB table and Kinesis data stream.
The following diagram shows the Kinesis Data Streams fan-out pattern that enables ordered, increased parallel processing of DynamoDB streams. It addresses the application requirements that are described at the beginning of this post.
 To explain the preceding architecture diagram in detail:
To explain the preceding architecture diagram in detail:
- DynamoDB relays item changes to a DynamoDB stream.
- Lambda polls the DynamoDB stream and invokes the configured Lambda function,
StreamForwarder, when it detects new items in the stream. - The
StreamForwarderfunction writes each item to a Kinesis data stream using thePutRecordAPI to ensure write ordering. - The Kinesis data stream is configured as a data source to Kinesis Data Firehose.
- The data that is streamed into Kinesis Data Firehose is archived in Amazon S3.
- Lambda polls the Kinesis data stream and invokes the configured Lambda functions concurrently.
- The Lambda function notifies SNS subscribers via email.
- The Lambda function aggregates and persists data into a DynamoDB table.
- The Lambda function transforms and inserts data into another Kinesis data stream.
- Lambda polls this Kinesis data stream and invokes the configured Lambda functions concurrently. This further increases the parallel processing of DynamoDB streams.
Enable write ordering with Kinesis Data Streams
Kinesis Data Streams lets you order records and read and replay records in the same order to many Kinesis Data Streams applications. To enable write ordering, Kinesis Data Streams expects you to call the PutRecord API to write serially to a shard while using the sequenceNumberForOrdering parameter. Setting this parameter guarantees strictly increasing sequence numbers for puts from the same client and to the same partition key.
The following Lambda function demonstrates an implementation that processes this stream. The function calls the PutRecord API to write data into the ProductCatalog Kinesis data stream. To maintain write ordering, the function sets the sequenceNumberForOrdering parameter with a value of the sequenceNumber obtained from the PutRecord API call made for the previous item.
Notice that the first call to the PutRecord API is made without setting the sequenceNumberForOrdering parameter because of the absence of any previous sequenceNumber. It still results in the item being write ordered. This is because Kinesis orders this item based on the arrival time and the fact that Lambda invokes this function with some time delay after the previous invocation.
Conclusion
In this post, I demonstrated how you can use Kinesis Data Streams to implement ordered, near-real-time processing of DynamoDB streams. You can use a number of fan-out patterns to process DynamoDB streams in parallel. However, with Kinesis Data Streams, you get the benefit of write ordering, read ordering, and a scalable ingestion pipeline. It also gives you the ability to process data from Kinesis data streams with applications written using the Kinesis Client Library or by using Lambda. However, the throughput delivered when you implement the fan-out pattern using Kinesis data streams is limited when compared to the parallel processing of DynamoDB streams using Lambda, if you can stay within the two-reader limit.
About the Author
 Aravind Kodandaramaiah is a solutions developer at Amazon Web Services.
Aravind Kodandaramaiah is a solutions developer at Amazon Web Services.