AWS Database Blog
Failover with Amazon Aurora PostgreSQL
Replication, failover, resilience, disaster recovery, and backups—it can be challenging to achieve any or all of these in a traditional or non-cloud-based architecture. In addition, they sometimes require a considerable re-engineering effort. Due to the high implementation and infrastructure costs that are involved, some businesses are compelled to tier their applications so that only the most critical ones are well protected.
You can help mitigate these concerns by moving to Amazon Aurora for PostgreSQL. AWS provides a wide selection of relational database engines, including (but not limited to) Oracle, MySQL, PostgreSQL, and Aurora. For PostgreSQL, AWS supports multiple flavors, including PostgreSQL on an Amazon EC2 instance, Amazon RDS for PostgreSQL, and Amazon Aurora with PostgreSQL compatibility. Among the many barometers for selecting the right PostgreSQL version, the following are a few important ones:
- High availability (HA)
- Performance
- Ease of management
Let’s delve into how Amazon Aurora PostgreSQL meets these criteria out of the box.
High availability: HA is built into the architecture of Aurora PostgreSQL, with six copies of data maintained across three Availability Zones. That is two copies in each Availability Zone, boosting availability with minor disruption even if an entire Availability Zone is down. In addition, the database is continuously backed up to Amazon S3, so you can take advantage of the high durability of S3 (99.999999999) for your backups. Aurora PostgreSQL also supports point-in-time recovery.
Performance: Amazon Aurora PostgreSQL delivers up to three times better performance compared to PostgreSQL on Amazon EC2. For more details about the benchmark tests, download the Amazon Aurora PostgreSQL-compatible Edition Benchmarking Guide. In addition, database analysis and troubleshooting are made easier with Performance Insights.
Manageability: Amazon Aurora PostgreSQL simplifies administration by handling routine database tasks such as provisioning, patching, backup, recovery, failure detection, and repair. Aurora storage scales automatically, growing and rebalancing I/O across the fleet to provide consistent performance.
In this post, I provide an overview of Amazon Aurora clusters and endpoints, and how they can help you achieve failover and load balancing for reads with minimal changes to your configuration. I walk you through an example showing how failover works in an Aurora cluster, and I describe how you can make failover transparent. This post mainly discusses Amazon Aurora PostgreSQL, but you can also apply most of the concepts to Amazon Aurora MySQL.
Introduction to Aurora clusters
Unlike PostgreSQL on Amazon EC2 or Amazon RDS for PostgreSQL, when you create an Aurora PostgreSQL DB instance, you are actually creating a database cluster. In Aurora PostgreSQL, a DB cluster is collection of one read/write instance and up to 15 read instances, along with data storage (cluster volume) that spans multiple Availability Zones. Each Availability Zone maintains two copies of the DB cluster data.
Amazon Aurora Replicas share the same underlying storage as the source instance, lowering costs and avoiding the need to copy data to the replica nodes. An Amazon RDS for PostgreSQL Read Replica is a physical copy. It uses an asynchronous replication method to update the Read Replica whenever there is a change to the source database instance. Also with RDS for PostgreSQL, you are limited to five Read Replicas per database source instance, whereas Aurora clusters support one primary (master or read/write) instance along with up to 15 Read Replicas.
The following diagram illustrates the Aurora PostgreSQL architecture with a master and three Read Replicas:
For more information about the architecture of Aurora, see the AWS Database Blog post Introducing the Aurora Storage Engine.
Endpoints
Connections to Aurora PostgreSQL instances are made using endpoints. Endpoints are URLs that contain a host address and a port, separated by a colon. When you create an Aurora PostgreSQL instance, AWS creates endpoints at the cluster level and at the instance level. At the cluster level, two endpoints are created, one for read/write operations (referred to as the cluster endpoint) and the other for read-only operations (referred to as the reader endpoint). Failover is made possible via the cluster endpoint, whereas load balancing for read-only connections across multiple Read Replicas is achieved via the reader endpoint. Also, if the cluster has no Read Replica, the reader endpoint provides a connection to the primary instance.
At the instance level, one endpoint is created per instance. With the instance endpoint, you are connecting directly to the instance just like a traditional connection. Use of the instance endpoint only (without the cluster endpoint) is discouraged without a strong justification. You can use cluster endpoints along with instance endpoints for manual load balancing of read queries.
The following diagram illustrates how endpoints work.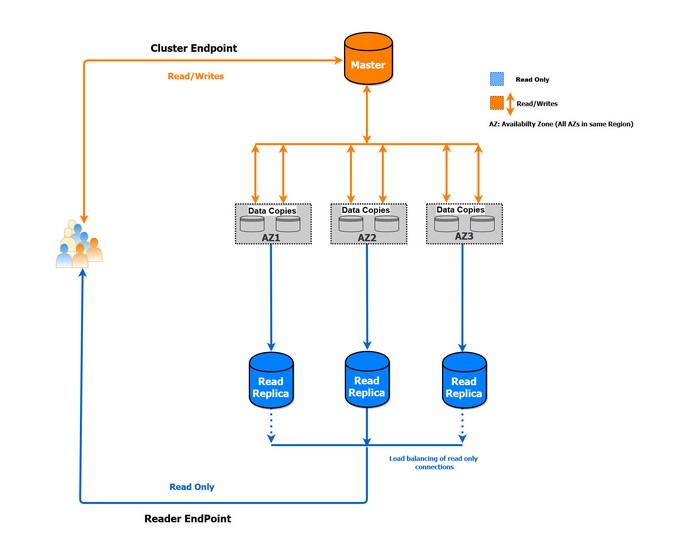
Note: Cluster and reader endpoints change if the DB cluster is renamed.
In the Amazon RDS console, you can find the cluster and reader endpoints by choosing Clusters in the navigation pane:

How does failover work?
If the primary instance in a DB cluster fails, Aurora automatically fails over in the following order:
- If Aurora Read Replicas are available, promote an existing Read Replica to the new primary instance.
- If no Read Replicas are available, then create a new primary instance.
If there are multiple Aurora Read Replicas, the criteria for promotion is based on the priority that is defined for Read Replicas. The priority number can vary from 0 to 15 and can be modified any time. Amazon Aurora PostgreSQL promotes the Aurora Replica with the highest priority to the new primary instance. For Read Replicas with same priority, Aurora PostgreSQL promotes the replica that is largest in size or in an arbitrary manner.
Applications experience minimal interruption of service if they connect using the cluster endpoint and implement connection retry logic. During the failover, AWS modifies the cluster endpoint to point to the newly created/promoted DB instance. Well-architected applications reconnect automatically. The downtime during failover depends on the existence of healthy Read Replicas. If no Read Replicas are configured, or if existing Read Replicas are not healthy, then you might notice increased downtime to create a new instance.
Aurora cluster failover example
Let’s walk through an example of failover of an Amazon Aurora cluster. The following table contains the details of a cluster with a master and two Read Replicas.
| Cluster name | pgcluster |
| Master instance | myinstance-us-east-2a |
| Read Replica | myinstance-us-east-2b (Priority 0) |
| Read Replica | myinstance-us-east-2c (Priority 1) |
| Cluster endpoint | pgcluster.cluster-xxxxxxxxxx.us-east-2.rds.amazonaws.com |
| Reader endpoint | pgcluster.cluster-ro-xxxxxxxxxx.us-east-2.rds.amazonaws.com |
This diagram represents the Aurora PostgreSQL cluster named pgcluster. Note that the cluster endpoint pgcluster.cluster-xxxxxxxxxx.us-east-2.rds.amazonaws.com is currently pointing to the instance myinstance-us-east-2a.
The following code Illustrates connecting to the database pgdb on port 5432 using the cluster endpoint. As part of this illustration, the example creates a table named failover and inserts one row into the table.
The following code shows the connection to a Read Replica instance using the reader endpoint along with a failed transaction. The failover table is accessed from the Read Replica via the reader endpoint to verify sync.
As expected, an error occurs because read-only replicas don’t support writable transactions.
Manual failover
The following screenshot shows the current primary myinstance-us-east-2a in the Amazon RDS console:
To do a manual failover, choose the primary instance name on the console, and choose Failover on the Instance actions menu.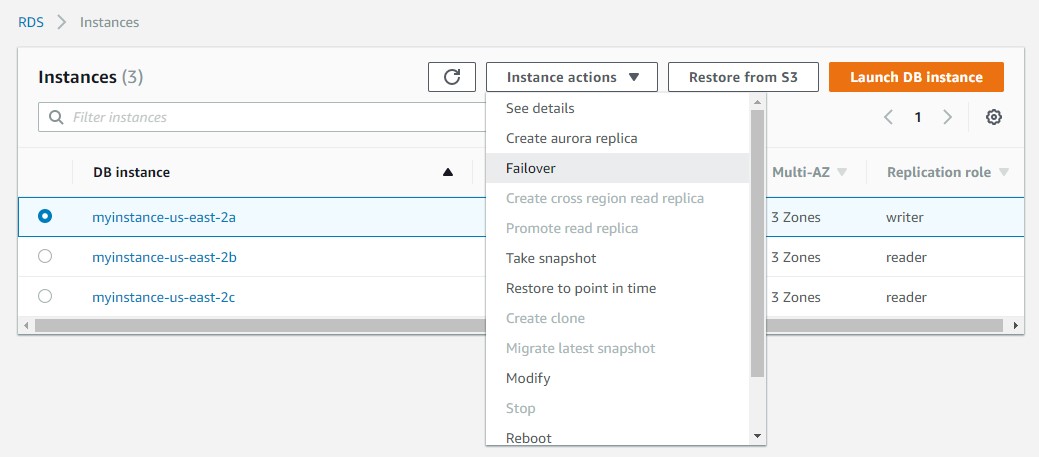
Then confirm it in the Failover window:
After manual failover is complete, the myinstance-us-east-2b instance is promoted as the new primary, and the myinstance-us-east-2a instance role is changed to a Read Replica. Also, the cluster endpoint now points to myinstance-us-east-2b, whereas myinstance-us-east-2a is available via the reader endpoint.
The following screenshot shows the Read Replica becoming the new primary in the RDS console: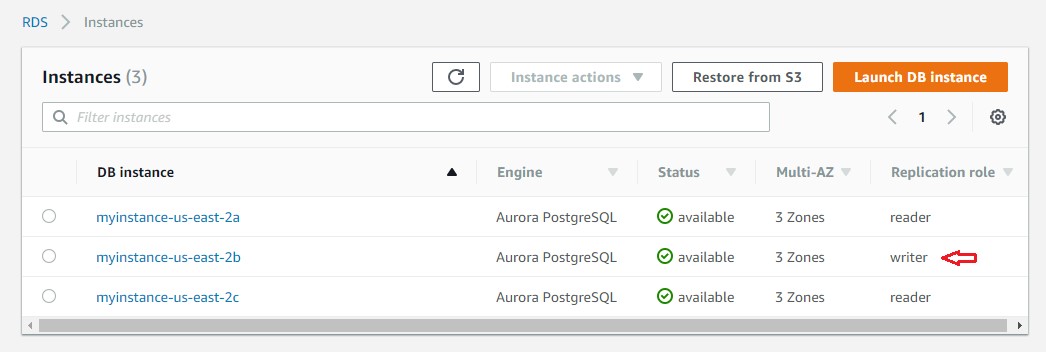
Reconnecting the instance
Now you can reconnect using the same cluster endpoint:
As the preceding code shows, the connection is successful without making any changes to the endpoint. You can make failover transparent by adding application connection retry logic.
Along with cluster endpoints, you can also respond to failover much faster by configuring aggressive TCP keepalive settings and JDBC connection settings or the PGConn class at the application level. For details, see Best Practices with Amazon Aurora PostgreSQL.
Conclusion
Handling unattended recovery is very important to achieve uptime service level agreements (SLA) for any organization. Aurora PostgreSQL, with its innovative failover architecture, not only supports increased availability and reliability but also provides enhanced performance via read scalability.
There are many ways your applications can respond to failover, but with cluster and reader endpoints, you can achieve failover and load balancing for reads with minimal configuration change. In addition, by using cluster endpoints along with following TCP keepalive and JDBC best practices, you can achieve fast failover and high availability. Use of the instance endpoint as the primary endpoint is discouraged. However, it can be used to support manual load balancing for reads. Moreover, you can make failovers transparent by adding automatic retry capability to the application.
About the Author
 Shan Nawaz is a big data consultant at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database & big data projects, helping them improve the value of their solutions when using AWS.
Shan Nawaz is a big data consultant at Amazon Web Services. He works with AWS customers to provide guidance and technical assistance on database & big data projects, helping them improve the value of their solutions when using AWS.