AWS Database Blog
Parallel vacuuming in Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL
PostgreSQL is a powerful open-source object-relational database system with over 30 years of active development that has earned it a strong reputation for reliability, feature robustness, and performance. AWS offers Amazon Relational Database Service (Amazon RDS) and Amazon Aurora as fully managed relational database services. Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL-compatible edition makes it easy to set up, operate, and scale PostgreSQL deployments in the cloud.
In this post, we talk about how parallel vacuuming works in Amazon RDS for PostgreSQL, which is a feature that was introduced in PostgreSQL 13. We also cover the parallel VACUUM parameters and demonstrate running parallel VACUUM in Amazon RDS for PostgreSQL.
In a PostgreSQL database, an important feature for reclaiming the storage occupied by dead tuples (a version of a row of a table) and indexes is called VACUUM. In a normal PostgreSQL operation, tuples that are deleted or obsoleted by an update aren’t physically removed from their table; they remain present until a VACUUM is performed. Frequent UPDATE and DELETE operations can leave a lot of unused space in the table or index files on the disk. The expired rows that UPDATE and DELETE cause are dead rows, which create more dead tuples or a bloated table. Therefore, you need to run a maintenance task like VACUUM periodically to minimize table bloat.
VACUUM phases:
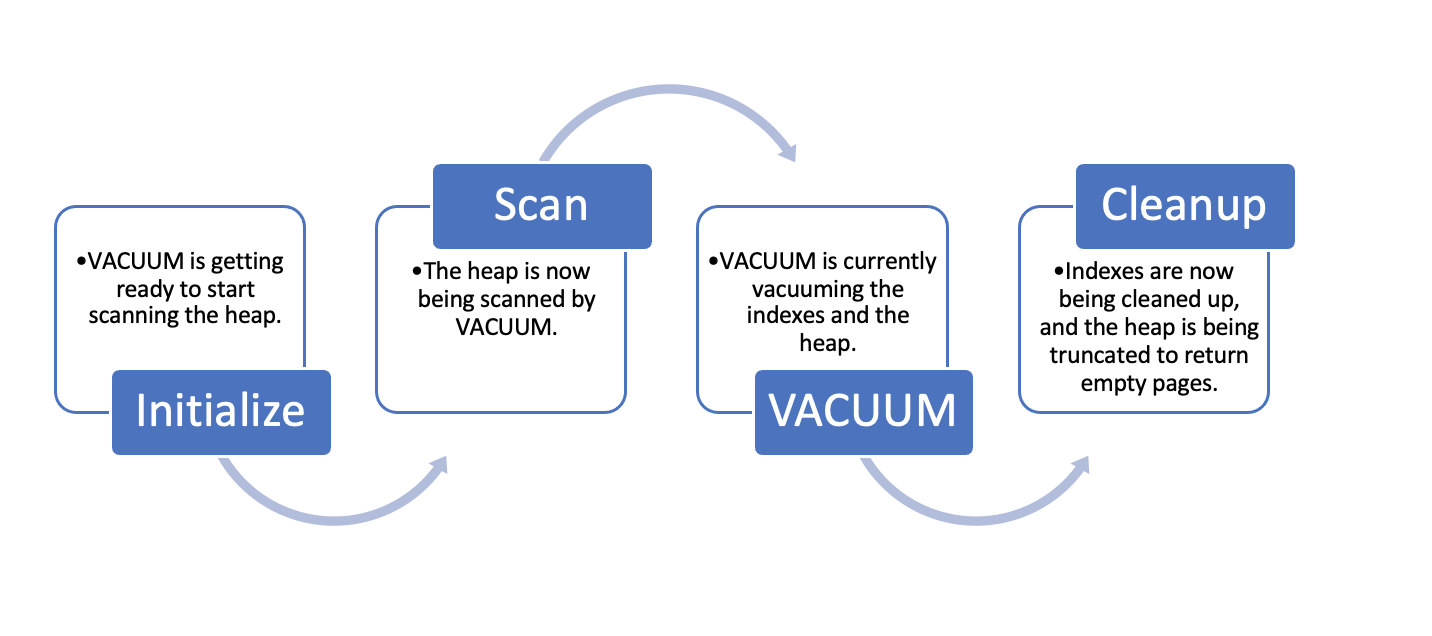
While autovacuum does take care of automating the VACUUM process, running VACUUM periodically is particularly efficient for frequently updated tables to minimize table bloat. This is because only when a certain number of dead rows have accumulated in the table are the cleanup steps taken by the VACUUM process. However, as datasets get larger, vacuuming takes longer to complete, which would lead to tables and indexes growing larger than ideal. VACUUM is always performed by a single process and one index at a time, which is why the runtime is longer for large tables.
Parallelism in PostgreSQL
Today, PostgreSQL can already devise query plans that can use multiple CPUs to answer queries faster, which is parallelism of a SQL query. VACUUM being one of the most important and critical maintenance operations to help DBAs control bloat, the introduction of parallel vacuuming helps speed up the process.
When we run VACUUM without the FULL option, it first scans the table from the top and collects garbage tuples in memory. If the table has more than one index, VACUUM runs for all of them one by one. Once the table is vacuumed it is followed by cleanup for indexes and truncating empty pages. To learn more about VACUUM and its various options and limitations, refer to the PostgreSQL documentation.
As VACUUM process runs in phases, in the heap scan phase, VACUUM can bypass the pages that don’t have dead tuples by using a visibility map. This map provides information on which table blocks are known to only have tuples that are visible to all transactions, but the index VACUUM and index cleanup phases demand a complete scan. With parallel vacuuming enabled, when you run VACUUM on a table, any indexes are processed in parallel, thereby making the VACUUM operation run faster and reduce the bloat as early as possible. It also allows you to use multiple CPUs to process indexes because VACUUM can perform the index VACUUM phase and index cleanup phase with parallel workers.
Parallel VACUUM parameters in RDS for PostgreSQL
The PARALLEL option was introduced in PostgreSQL 13 and is disabled by default. When we run VACUUM with the PARALLEL option, parallel workers are used for the index VACUUM and index cleanup phase. The number of parallel workers (degree of parallelism) is decided based on the number of indexes in the table or as specified by the user. If you’re running parallel VACUUM without an integer argument, it calculates the degree of parallelism based on the number of indexes in the table.
The following are important parameters for parallel vacuuming in RDS for PostgreSQL and Aurora PostgreSQL:
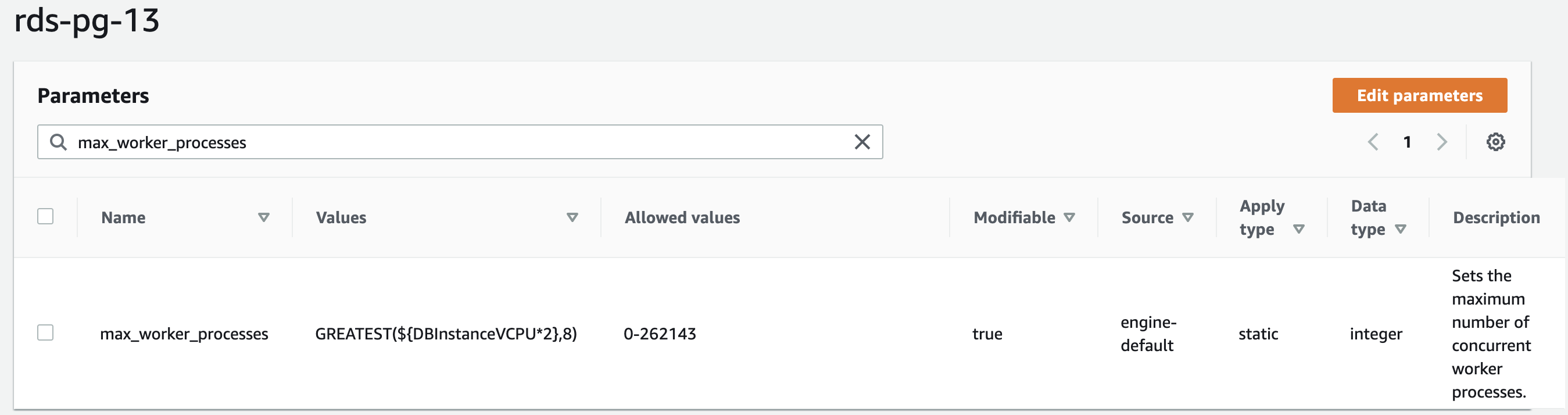
- max_worker_processes – Sets the maximum number of concurrent worker processes
- min_parallel_index_scan_size – The minimum amount of index data that must be scanned in order for a parallel scan to be considered
- max_parallel_maintenance_workers – The maximum number of parallel workers that can be started by a single utility command
You can add these parameter settings in RDS for PostgreSQL using DB parameter groups. In our case, we modify an existing DB parameter group called rds-pg-13, as shown in the following screenshots. For instructions, refer to Modifying parameters in a DB parameter group.


How parallel VACUUM works
When we enable or request parallel VACUUM using the PARALLEL option, it’s not always certain that the number of parallel workers specified in the PARALLEL option will be used during the process. For parallel VACUUM to work, the table must have more than one index, and the index size must be greater than min_parallel_index_scan_size. Therefore, there also may be cases where we notice that VACUUM runs with fewer workers than specified in the PARALLEL option, or even with no workers at all.
Because we can use one worker per index, parallel workers are launched only when a table has at least two indexes. It’s also worth noting that this option can’t be used with the VACUUM FULL option.
Run parallel VACUUM in PostgreSQL
We now look at an example to see how to run parallel VACUUM in PostgreSQL:
- Connect to a running instance of PostgreSQL via psql and check the aforementioned settings:
In our configuration, we use two parallel workers for the indexes, which exceeds the size of 512 KB.
- Create the
parallel_vacuumdatabase for demonstration purposes and connect to the database: - Create a table
parallel_vacuumand populate it with test data:
Note: autovacuum has been turned off for demonstration purpose only, never do this in production. - Add three indexes to the table, one for each column and another for both columns together:
- List the index statistics using the following query. This query is available on the PostgreSQL wiki.
Now that we have the list of indexes with us, we can set the parallel workers accordingly. Next, we update the
parallel_vacuumtable to demonstrate the data being modified. - Update the
parallel_vacuumtable and set the maximum maintenance parallel workers to four, then run VACUUM with the PARALLEL 4 parameter:
In our example, we have three indexes in the table; therefore, the maximum number of vacuum workers can be two and a leader process. Here in the demonstration 3 processes worked on this command.
Now let’s examine the performance benefits of parallel VACUUM.
Observations of parallel VACUUM and its performance benefits
To verify the performance benefits of parallel VACUUM, let’s first turn on timing:
Now we update the parallel_vacuum table and run VACUUM with and without the PARALLEL option:
In this example, we’re able to visualize the parallel VACUUM process and how it uses multiple workers, thereby improving the runtime.
Conclusion
In this post, we showed how the VACUUM process’s ability to execute in parallel helped shorten its overall runtime. According to our analysis, running VACUUM with the PARALLEL option resulted in a performance improvement of 14 seconds (17%). Before using in production, you should thoroughly evaluate your settings, including the number of indexes as indicated in this blog post, as well as your tables. The performance improvement is influenced by the dataset being used and the parameter settings.
If you have any comments or questions about this post, submit them in the comments section.
About the Authors
 Kanchan Bhattacharyya is a Specialist Technical Account Manager – Databases with Enterprise Support, India. He joined AWS in 2021 and works with ES customers to provide consultative technical guidance, reviews, and recommendations on their databases running in the AWS Cloud. He also helps ES customers adopt best practices for their databases running in the AWS Cloud. Kanchan specializes in Amazon RDS for SQL Server, RDS for PostgreSQL, Amazon RDS for MySQL, and Amazon Aurora.
Kanchan Bhattacharyya is a Specialist Technical Account Manager – Databases with Enterprise Support, India. He joined AWS in 2021 and works with ES customers to provide consultative technical guidance, reviews, and recommendations on their databases running in the AWS Cloud. He also helps ES customers adopt best practices for their databases running in the AWS Cloud. Kanchan specializes in Amazon RDS for SQL Server, RDS for PostgreSQL, Amazon RDS for MySQL, and Amazon Aurora.
 Mohammed Asadulla Baig is a Technical Account Manager with Enterprise Support, India. He joined AWS in 2017 and helps customers plan and build highly scalable, resilient, and secure solutions. Along with his work as a TAM, he specializes in databases like Amazon Aurora and RDS for PostgreSQL. He has assisted multiple enterprise customers by enabling them with various AWS services and provided guidance on achieving operational excellence.
Mohammed Asadulla Baig is a Technical Account Manager with Enterprise Support, India. He joined AWS in 2017 and helps customers plan and build highly scalable, resilient, and secure solutions. Along with his work as a TAM, he specializes in databases like Amazon Aurora and RDS for PostgreSQL. He has assisted multiple enterprise customers by enabling them with various AWS services and provided guidance on achieving operational excellence.