AWS Database Blog
Protect sensitive data with dynamic data masking for Amazon Aurora PostgreSQL
Today, we are launching dynamic data masking feature for Amazon Aurora PostgreSQL-Compatible Edition. This addition to the Aurora security toolkit enables column-level protection, working in tandem with PostgreSQL’s native row-level security to deliver comprehensive, granular access control.
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database offering high performance and open-source flexibility. Organizations using Aurora need to protect sensitive data while providing different access levels to users based on their roles.
In this post we show how dynamic data masking can help you meet data privacy requirements. We discuss how this feature is implemented and demonstrate how it works with PostgreSQL role hierarchy. The feature is available for Aurora PostgreSQL version 16.10 and higher, and 17.6.
Data masking: Requirement and use cases
Enterprises in regulated industries such as banks, insurance providers, FinTech, and healthcare providers face complex challenges in managing access to sensitive customer data. Let’s consider a bank that needs to provide different levels of data access across multiple teams:
- Customer support representatives need to verify customer identities during service calls. They require partial access to account information – like the last few digits of account numbers – to authenticate customers without exposing complete account details.
- Industry analysts study customer financial behavior to develop new products and services. They need anonymized data to identify patterns while protecting individual customer privacy.
- Applications supporting end customer queries such as an internet banking application needs to show unmasked data for an authenticated user.
The challenge: Traditional data masking falls short
Organizations have long struggled to protect sensitive data while keeping it accessible for legitimate business needs. The traditional approaches each come with significant tradeoffs.
Separate sanitized datasets sound simple in theory – just create different copies of your production data for different teams. In practice, this becomes a maintenance nightmare. You’re constantly synchronizing data across multiple copies, paying for redundant storage, and as your organization grows, managing access across these datasets becomes exponentially more complex.
Database-level masked views seem like a cleaner solution, but they introduce serious security risks. Sophisticated users can gain unintended access through complex SQL expressions to peek at the underlying data protected by the view. Plus, they slow down your queries, impacting application performance when you need it most.
Application-level masking distributes the problem rather than solving it. Each application that touches your data needs its own masking logic, leading to inconsistent protection across your environment. Development teams spend valuable time reimplementing the same security controls, and every new application adds to your maintenance burden.
A better approach: Dynamic data masking
Amazon Aurora PostgreSQL-Compatible Edition now offers dynamic data masking – a solution that sidesteps these traditional limitations entirely.
Here’s what makes it different: you maintain just one copy of your data. No duplication, no synchronization headaches, and no storage bloat. The actual data in your database remains unmodified.
The magic happens through the pg_columnmask extension, which operates at the database level during query processing. This means you don’t need to modify your applications. Instead of scattering masking logic across multiple codebases, you define policy-based rules once, directly in the database.
These policies determine how sensitive data appears to different users based on their roles. An executive might see full credit card numbers, while a customer service representative sees only the last four digits—all from the same underlying data. And unlike masked views, this approach doesn’t introduce security vulnerabilities or performance penalties.
Dynamic data masking helps you:
- Protect sensitive information in real-time without data duplication
- Maintain data utility for users who need full access
- Meet compliance requirements for regulations like GDPR, HIPAA, and PCI DSS
- Implement role-based access controls efficiently and consistently
pg_columnmask extension
pg_columnmask extension uses two core PostgreSQL mechanisms:
- Policy-based Masking –
pg_columnmaskextends PostgreSQL’s row-level security (RLS) capabilities to create column-level masking policies. These policies use built-in or custom functions to:- Hide sensitive information
- Replace values with wildcards
- Use weights to determine which masking policy should be used when multiple policies apply to a column.
- Runtime Query Rewrite –
pg_columnmaskintegrates with PostgreSQL’s query processing pipeline to mask data during execution. This integration preserves query functionality while helping protect sensitive information.
A policy admin can create masking policies using standard SQL commands, incorporating PostgreSQL’s built-in functions or custom functions. These policies transform data based on user roles and access levels, enabling precise control over sensitive information.

Diagram 1 – Policy Administrators can create a policy using pgcolumnmask.create_masking_policy function
Policy admin will specify roles to which a masking policy is applied. An authorized user will be able to see unmasked data. When customers log into their banking application, the application connects to the database using an authorized user role. pg_columnmask recognizes this role and allows the application to read unmasked data. For example, when John Doe logs in to his internet banking account, and requests to see account information, the application uses database credentials to make a connection and run the query on behalf of John Doe.
The pg_columnmask extension recognize authorized user and will return unmasked data
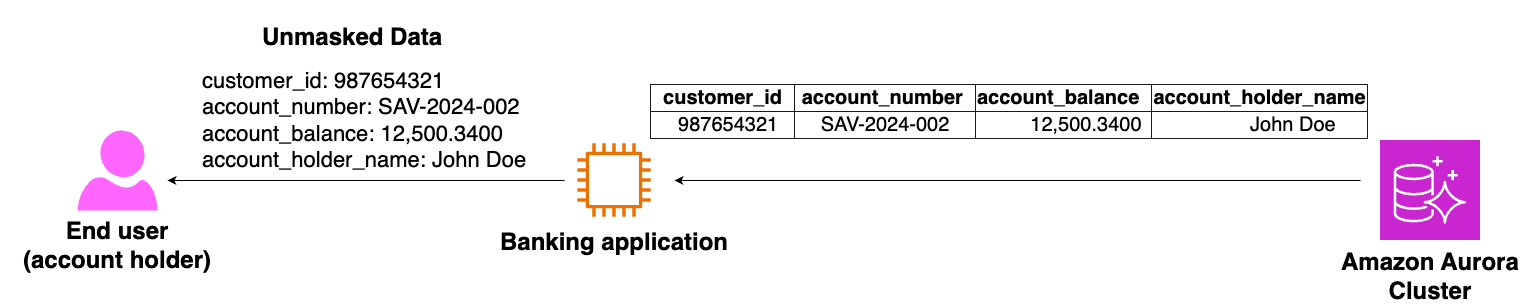
Diagram 2 – Authorized user can see unmasked data
When support staff assist customers like John Doe, they need to verify customer identity without accessing complete sensitive information. When the support staff access backend application, the application will make a database connection using a different role.
Through a specific masking policy, support staff can see partial details such as the last four digits of customer identifier or just the initials of the customer. The database engine will automatically apply these masking rules when the contact center application queries the accounts table, transforming sensitive data in real-time. For example, a support representative might see XXXX-XXX-321 instead of the complete customer identifier, providing just enough information for customer verification while helping protect sensitive data.
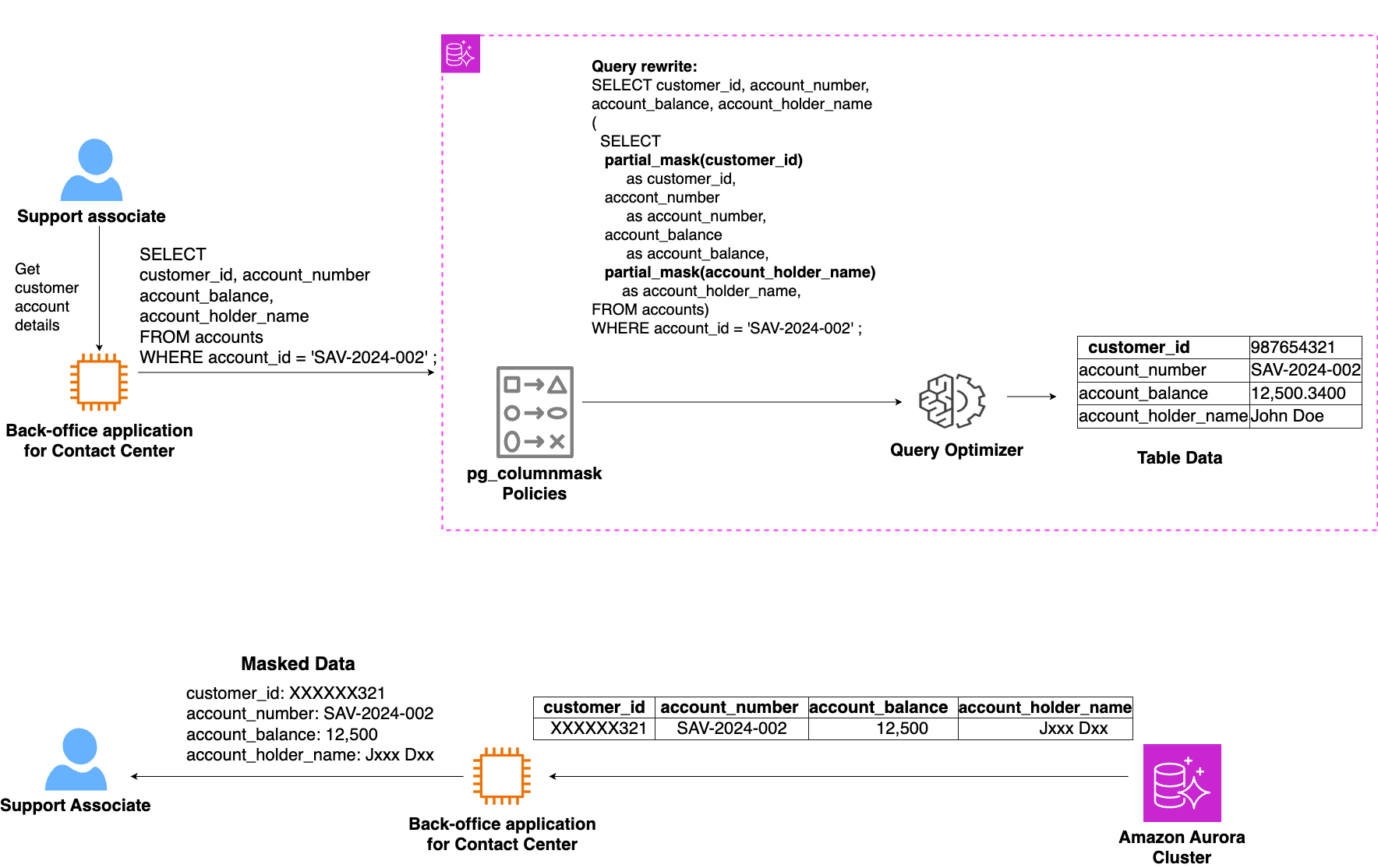
Diagram 3 – A Support Associate assisting a customer will see partial data, enough to validate and authenticate the customer
The following diagram shows how pg_columnmask handles data access for a user with analyst role. When Jane, an Analyst, queries customer financial data, she sees account balances rounded to the nearest thousand, while customer identifier and customer names appear masked. This masking approach enables industry research for new product offerings while helping protect customer identities. pg_columnmask extension applies these transformations automatically through role-based policies, making sure analysts can identify savings patterns without accessing sensitive customer information.
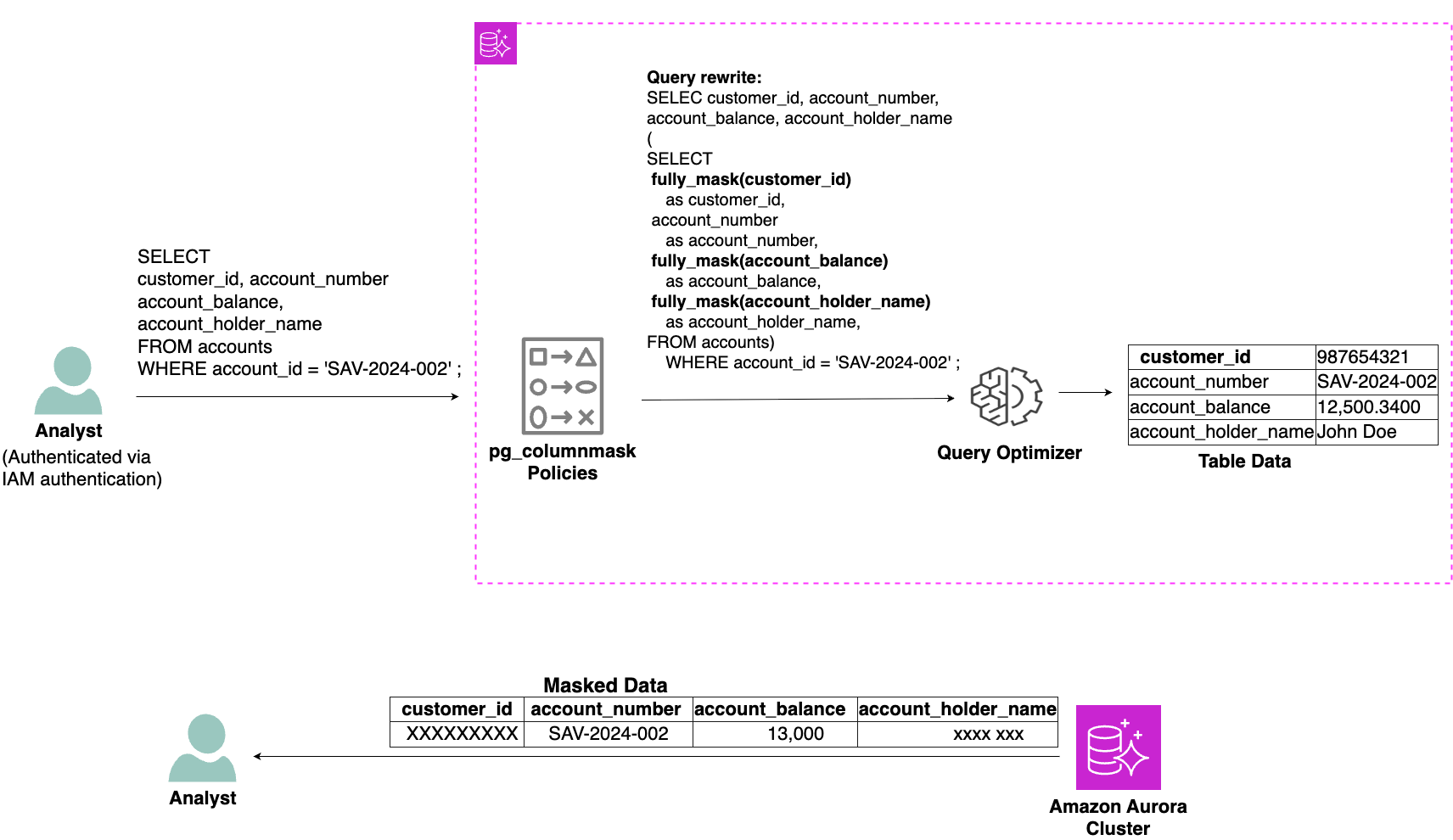
Diagram 4 – An analyst will not see PII data
pg_columnmask extension uses policy weights to determine precedence when multiple masking policies target the same column. The following diagram demonstrates how PostgreSQL’s role inheritance works with DDM policies. For example, as a Senior Analyst, Shirley needs more precise account balance data than Jane, who has the analyst role. In the database we will have a user shirley with senior_analyst role and inherits analyst role.
When multiple policies apply to the same data, pg_columnmask uses weights to determine which policy takes precedence. Consider these three policies applied to table account:
analystpolicy with weight 50 applies to ssn.senior_analystpolicy with weight 30 applies only to account balance. A user withsenior_analystrole to see account balance with a precision of up to nearest integer.analystpolicy with weight 20 applies to both account balance rounding off to nearest thousand, and customer name.
The following diagram shows weighted masking policies for hierarchical role structures:
| Policies | ||||
|
|
|||
Diagram 5 – Role-based data masking with weighted policy hierarchy
If a user who is member of analyst or senior_analyst role will access ssn information, both will see masked data due to policy applied to analyst. When shirey who is eligible for multiple policies, queries amount and name, the engine will apply senior_analyst masking rules to account balance (due to higher weight) and analyst rules to customer name. This weight-based approach allows organizations to implement role-specific masking rules while maintaining consistent data protection across different access levels.
How dynamic data masking works: Under the hood
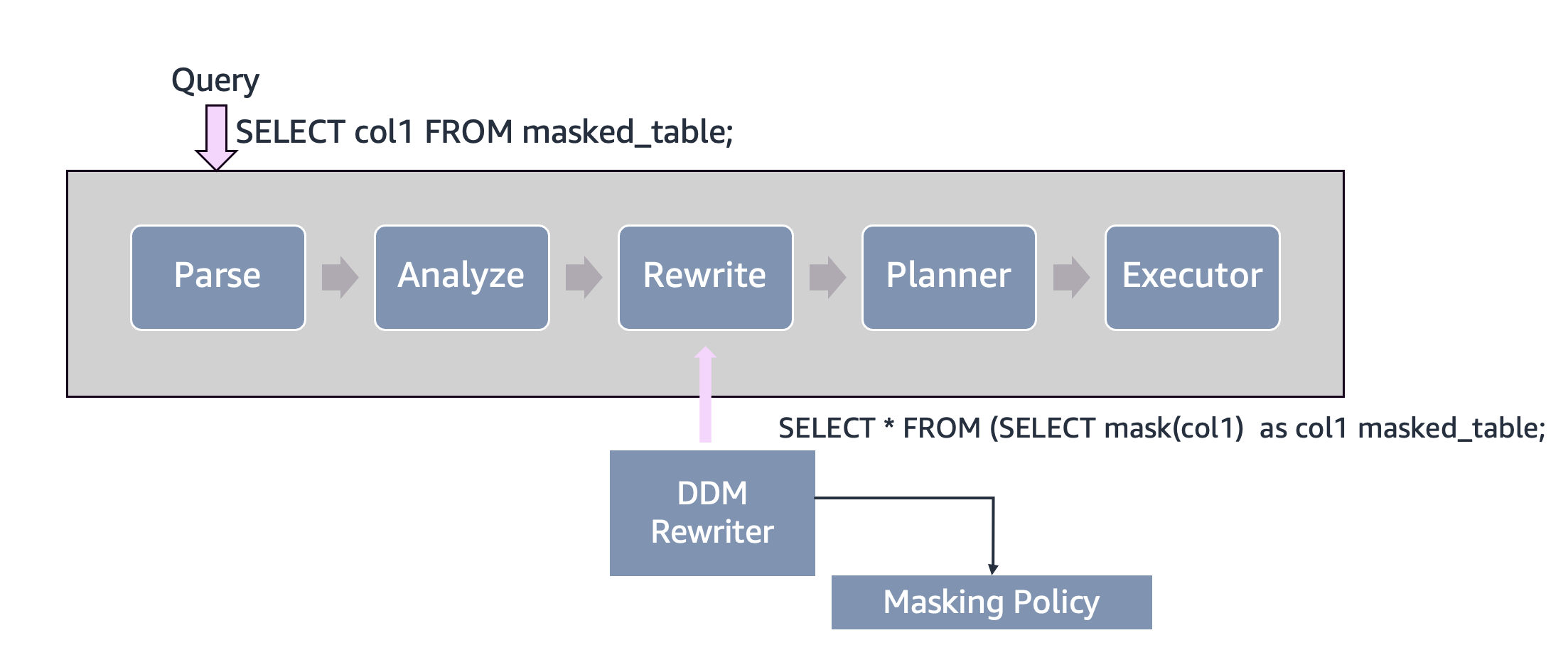
Before we walk through how to implement dynamic data masking using pg_columnmask extension, let’s review PostgreSQL’s query processing. The following diagram illustrates five subsystems of PostgreSQL query processing. For this post, we focus on the rewrite stage, which DDM uses.
To understand how dynamic data masking helps protect your data, it helps to know how PostgreSQL processes queries.
When you execute a SQL query, PostgreSQL runs it through several stages:

- Parsing: Checking the grammar
The parser reads your SQL query and builds a basic structure (called a parse tree). Think of it like a grammar checker—it only cares whether your SQL syntax is correct. At this stage, PostgreSQL doesn’t verify whether the tables or columns you’re querying actually exist. - Analysis: Validating the details
The analyzer takes that parse tree and does the real validation. It checks whether the tables, columns, and data types you’re referencing are legitimate. If you’re querying a table that doesn’t exist, this is where PostgreSQL catches it. - Rewriting: Applying transformations
Here’s where things get interesting. The rewrite stage modifies your query before it gets executed. PostgreSQL uses this stage for various transformations—and this is exactly where dynamic data masking does its work. - Planning and execution
Finally, the query planner receives a query tree from the rewriter and generates a cost-based query plan tree that can be processed by the executor.
Where masking happens
The pg_columnmask extension plugs directly into the rewrite stage. As your query passes through, the dynamic data masking (DDM) rewriter automatically injects masking logic based on the policies you’ve defined.
The masking happens transparently within PostgreSQL’s normal query flow. Your application sends a standard query, and depending on who’s asking, the rewriter transforms it to mask sensitive columns—all before the query reaches the execution stage.
For example, if you’ve set a policy to mask email addresses for junior analysts, their queries are automatically rewritten to return masked values. Senior analysts with different permissions see the real data. Same query, same table, different results — all handled by the rewrite stage.
The following diagram shows how the DDM rewriter fits into this pipeline:
Your applications don’t need to know masking is happening. The database handles it all, helping enforce your security policies consistently across every query, every application, every time.
In the following sections, we demonstrate how to create a sample database, users, and roles, and configure dynamic data masking and masking policies.
Prerequisites
Create an Amazon Elastic Compute Cloud (Amazon EC2) instance, and then create an Aurora PostgreSQL database using version 16.10 Or 17.6. Once the Aurora PostgreSQL cluster is in available state, connect to the EC2 instance and install required client tools (psql), and test connectivity to the database.
Create the users, database, and test data
Connect to the cluster endpoint using a role with rds_superuser permissions:
Create users who will be the owner of user tables, policy administrator, and members of analyst and senior analyst roles:
Create a new database called test_ddm, and grant necessary privileges to dbowner:
Connect to test_ddm using dbowner:
and create test tables called accounts and ledger:
Insert some sample data in both tables:
Configure policy admin
Create a new DB cluster parameter group using the same engine version that you used for the Amazon Aurora cluster. Modify the DB cluster parameter group, to set parameter pgcolumnmask.policy_admin_rolname to policy_admin. Modify the Amazon Aurora cluster to use newly created DB cluster parameter group. It is a dynamic parameter, and if you are using a non-default DB cluster parameter group, you can modify the parameter setting without a restart. The pgcolumnmask.policy_admin_rolname sets the role which can create data masking policies for user tables. Table owners, and members of rds_superuser role can also associate masking policy with a table.
Set up dynamic data masking
To use the masking feature, connect to the Aurora cluster endpoint using a user with rds_superuser role:
Create the pg_columnmask extension:
After you set up the extension, a new function pgcolumnmask.create_masking_policy is created to define the masking policy. You can use the built-in masking functions installed by pg_columnmask extension.
Create a masking policy
Login to the database using user with policy admin role (policy_admin).
Create a masking policy using the function create_masking_policy:
The command creates a new masking policy named ‘fully_mask_account_data’ that is applied to the ‘public.accounts’ table. The JSONB column defines the following masking rules:
account_holder_namewill be masked usingmask_textfunction provided bypg_columnmaskextension, which will replace all the characters in a string with “X”.customer_idwill also be masked usingmask_textfunction.account_balancewill be masked using PostgreSQL’s build-in functionround, to round off the amount to nearest thousand.account_contact_emailwill be masked usingmask_emailfunction provided bypg_columnmask, which works similar tomask_textbut masks a string in email address format.
Then, the ARRAY object includes all the roles that are subject to this policy and we set the weight for all those rules to 50.
Create a masking policy to mask transaction details from the analysts
In these policies we are using built-in functions which are provided by pg_columnmask extension, but you can use built-in functions of PostgreSQL and even define custom SQL or pl/pgsql functions to mask data. The return type of the function used should be the same as the data type used by column being masked.
Note that we don’t assign access to actual data to the policy administrator role. The users with policy_admin role (samkumar) can’t see the data in account and ledger, but they can define masking policy for sensitive data:
Create separate policy for a senior_analyst to allow them to view accurate amount and details of transaction:
You can see the policies when you describe a table:
You can also get the details of masking policy defined on a table using get_masking_policy_info.
Validate data masking
After you have defined the masking policies, the users under role analyst will only see masked data. To test, connect using the user jane and run a query:
As an analyst jane has access to ledger table and she can perform a JOIN between accountsand ledger, but she will only be seeing masked data:
When shirley , who is member of senior_analyst role connects to the database test_ddm, she will be able to JOIN accounts with ledger, and see partially masked data:
Here, shirley is seeing masked data as an effect of policies defined for both analyst and senior_analyst. First the masking rules are applied based on the higher weight masking policies – partially_mask_ledger_data and partially_mask_account_data. That’s why shirley can see transaction_merchant_code, transaction_amt, and account_balance. Then for rest of the columns lower weight policies – fully_mask_ledger_data and fully_mask_account_data, are applied. Hence, shirley can’t see account_holder_name or account_contact_email.
dbowner will be able to see the data:
Clean up
To clean up the resources used in this post, follow these steps:
- Delete the instances in the Aurora PostgreSQL cluster that you created as part of the pre-requisite steps.
- If needed, change the deletion protection setting for the Aurora PostgreSQL cluster.
- Delete the Aurora PostgreSQL cluster.
- Terminating the Amazon EC2 instance used as client for connection to Aurora PostgreSQL cluster.
- If needed delete the Amazon Elastic Block Store (Amazon EBS) volume that was attached to Amazon EC2 instance.
Conclusion
Aurora dynamic data masking represents a significant advancement in database security, helping provide granular control over sensitive data access without compromising operational efficiency. Aurora already supports out-of-the-box encryption in transit and encryption at rest, and you can implement access control using PostgreSQL RLS policies and granular access control at the object and column level. You can also protect access to the database with AWS Identity and Access Management (AWS IAM) database authentication and Kerberos authentication, and by managing user credentials using AWS Secrets Manager.
Aurora DDM enables real-time data transformation based on user roles, so teams can work with necessary data structures while helping protect sensitive information through flexible masking approaches. The feature integrates with the auditing capabilities of Aurora, including Database Activity Streams and pgAudit, providing visibility into data access patterns. By implementing Aurora DDM, you can confidently support diverse business functions and help maintain compliance posture while preserving data utility. The feature’s integration with the Aurora security infrastructure delivers enterprise-grade data protection that balances operational efficiency with robust data security.