AWS Database Blog
Supercharge your Amazon RDS for MySQL deployment with ProxySQL and Percona Monitoring and Management
This is a guest blog post by Michael Benshoof from Percona. In their own words, “With more than 3000 global customers, Percona reduces risk and operational costs by providing unbiased, best-of-breed enterprise-class support, consulting, managed services, training and software for open source databases in on-premises and cloud environments that eliminates lock-in, increases agility and enables business growth.”
“
So your organization is looking to deploy an application to the cloud, and you plan to use Amazon RDS for MySQL for the data tier… great! Let’s look at some of the best practices to ensure that you get the most out of your architecture.
What is Amazon RDS for MySQL?
RDS for MySQL is a managed database as a service (DBaaS) within the Amazon Web Services (AWS) stack. With RDS for MySQL, the majority of the operational details are handled for you, including:
- Backups
- Point-in-time recovery
- Automated minor-version upgrades
- Adding new replicas
- Automated failover (when running Multi-AZ)
As such, RDS for MySQL is a great option for a data tier that runs in the cloud. Many common failover scenarios are covered with the standard Multi-AZ deployment, but you can also do things to boost the resilience and usability of RDS. These practices allow your deployment and infrastructure to scale more seamlessly as your workload increases.
Standard best practices
By default, when you’re designing any architecture (in the cloud or in a physical data center), the most important thing is to plan for failure. Setting up your infrastructure expecting things to fail is key to designing a fault-tolerant environment. As such, you should do the following at a minimum for a production deployment (or any deployment that needs to be highly available):
Specify Multi-AZ for the primary instance
- DNS is then used to route application connections to the active instance.
- The passive instance is kept in sync using synchronous storage block-level replication, and is promoted in the event of a primary failure.
- No traffic can be sent to the passive instance.
Ensure that replicas are spread across multiple Availability Zones
- This practice increases availability in the event of multiple failures within an AWS Region.
- For additional redundancy in case of loss of an entire Region, you can add a cross-region replica.
- This practice also provides options for geographic load balancing.
Enable automated backups
- To use replicas, you must enable backups.
- Backups are taken from the passive instance in Multi-AZ mode.
- Test your backups periodically by running a restore to ensure their viability.
- We recommend a longer backup retention period (the current maximum is 35 days).
Use application retry logic
- The application should be able to handle failure and retry statements and transactions as needed.
Monitor with Percona Monitoring and Management
- Having insight into the instance metrics and query traffic is critical for troubleshooting and planning.
- PMM is a freely available Amazon Machine Image (AMI) and is easy to connect to a running RDS instance.
In this architecture, your application should send all writes to the DNS endpoint for the master. (Remember, if the primary instance dies, DNS automatically shifts to the passive node.) If you have the ability within the application to split reads and writes, you can direct read queries to replica nodes. EACH replica must be defined in the application because RDS doesn’t provide a “replica endpoint” with all the active replicas.
Percona Monitoring and Management
The final piece of the enhanced RDS deployment puzzle is setting up a Percona Monitoring and Management (PMM) instance. Although Amazon CloudWatch can give you some raw metrics from the instance, PMM provides a wealth of additional MySQL metrics. PMM provides thorough time-based analysis for MySQL and MongoDB servers to ensure that your data works as efficiently as possible.
PMM Query Analytics helps you optimize database performance by making sure that MySQL and MongoDB queries are executed as expected and within the shortest time possible. In case of problems, you can see which queries might be the cause and get detailed metrics for them. The Metrics Monitor tool provides a historical view of metrics that are critical to a database server. Time-based graphs are separated into dashboards by themes: Some are related to MySQL or MongoDB, and others provide general system metrics.
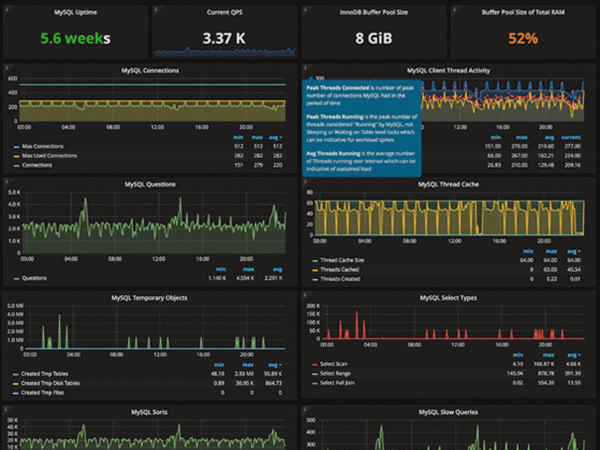
You can zoom in on a particular metric to get more details.
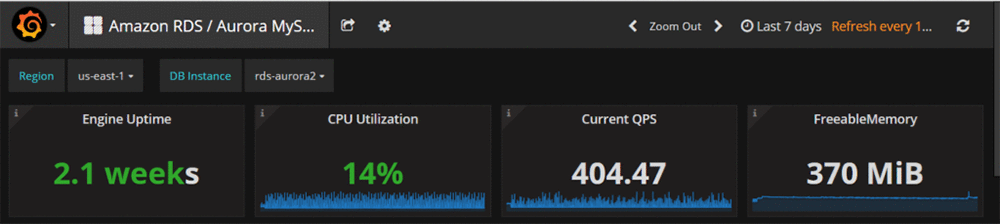
PMM Query Analytics lets you display more information about the data that is being monitored in each graph—for example, inbound and outbound network traffic, CPU use, or available memory over time.
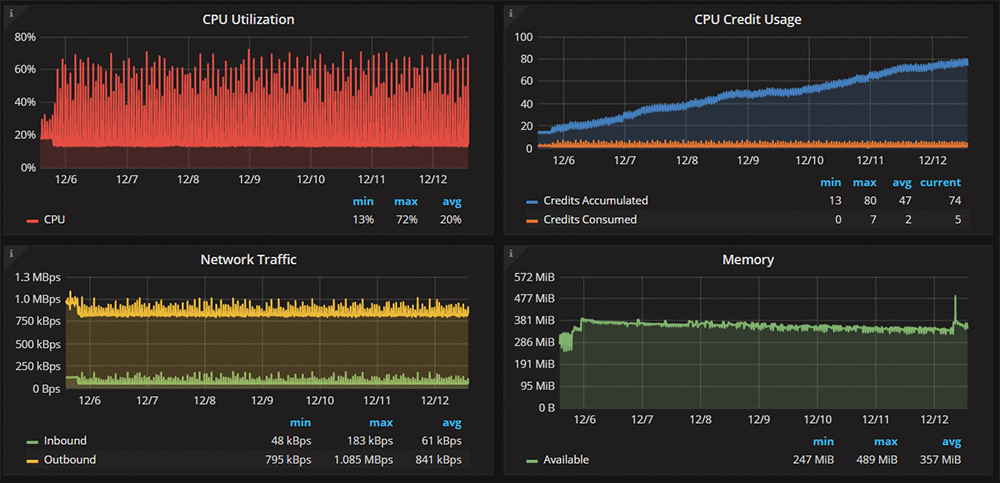
When you identify performance degradation, more often than not, a poorly performing query is the primary cause. With PMM, those queries quickly bubble up to the top of the list and can be quickly identified, even before they become a problem.
For more information, see the PMM documentation.
Enhanced architecture
Building on the preceding best practices, you can apply some additional enhancements that help you use resources more effectively while adding more transparent availability and visibility. The additional components include the following:
- ProxySQL
- Elastic Load Balancing (ELB)
The following sections break down these components and provide a brief explanation of how they add to the overall architecture, as shown in the following diagram.

ProxySQL
ProxySQL is a Layer 7 load balancer that acts as a SQL connection endpoint and proxy to the RDS instance behind it. You can use this tool to define pools of servers (for availability) in addition to transparent read/write splitting (better utilization). Its built-in health checks can determine when replicas are dead and transparently retry failed queries on other nodes (auto-commit or read queries).
You can also use ProxySQL for the primary instance. Although RDS automatically promotes the passive master to active, the DNS propagation can take some time, and the application will likely experience failures. With automatic retries, you can configure ProxySQL to retry until the RDS failover is complete and hide the promotion from the application entirely.
Finally, you can use ProxySQL to define a cluster endpoint for read traffic. If your application can already split reads/writes, then you can simply add the replicas to your cluster and send all reads through ProxySQL rather than manage replica endpoints in the application.
For more information, see the ProxySQL website.
Elastic Load Balancing
As stated earlier, you should design all architectures with component failure in mind. This is where adding Elastic Load Balancing (ELB) to the stack is important. Although ProxySQL can handle load balancing and node failures at the backend level, ELB provides redundancy for ProxySQL.
Setting up multiple ProxySQL instances and putting them behind ELB adds redundancy at the final level. In the event of a ProxySQL instance failing, ELB automatically routes all traffic to the healthy instances. You can also scale the ProxySQL layer as needed by adding new nodes.
Summary
Overall, Amazon RDS for MySQL is a great option for a data tier in AWS. Following some basic best practices can give your application enhanced availability. Adding in a few more layers can provide additional availability and visibility, to give you a production-ready solution with a drop-in replacement for your current MySQL deployment.
About the Author
 Michael Benshoof is a Technical Account Manager with Percona. Prior to joining Percona, Michael spent several years in a DevOps role in a company that developed and maintained a SaaS application specializing in social networking. His experiences include application development and scaling, systems administration, along with database administration and design. He enjoys designing extensible and flexible solutions to problems and has a strong background in HA systems.
Michael Benshoof is a Technical Account Manager with Percona. Prior to joining Percona, Michael spent several years in a DevOps role in a company that developed and maintained a SaaS application specializing in social networking. His experiences include application development and scaling, systems administration, along with database administration and design. He enjoys designing extensible and flexible solutions to problems and has a strong background in HA systems.