AWS Developer Tools Blog

AWS CLI v2 now available for Linux ARM
With the release of 2.0.15 of the AWS CLI v2, we are excited to announce the availability of aarch64 builds of the AWS CLI v2. This launch includes a new Linux ARM installer to add to the current AWS CLI v2 installation mechanisms: Linux x86 installer MacOS PKG installer Windows MSI installer Docker image The […]
Announcing end of support for .NET Standard 1.3 in AWS SDK for .NET
Microsoft announced the end of support for .NET Core 1.0 and 1.1 platforms on June 27th, 2019. Given that the .NET Standard 1.3 target of the AWS SDK for .NET is only used for .NET Core 1.0 and 1.1 platforms, we will be removing the .NET Standard 1.3 target in AWS SDK for .NET, and […]
Provision AWS infrastructure using Terraform (By HashiCorp): an example of web application logging customer data
Many web and mobile applications can make use of AWS services and infrastructure to log or ingest data from customer actions and behaviors on the websites or mobile apps, to provide recommendations for better user experience. There are several ‘infrastructure as code’ frameworks available today, to help customers define their infrastructure, such as the AWS […]
Orchestrating an application process with AWS Batch using AWS CDK
In many real work applications, you can use custom Docker images with AWS Batch and AWS Cloud Development Kit(CDK) to execute complex jobs efficiently. AWS CDK is an open source software development framework to model and provision your cloud application resources using familiar programming languages, including TypeScript, JavaScript, Python, C# and Java. For the solution […]
Introducing .NET Core Support for AWS Amplify Backend Functions
Earlier this month, the AWS Amplify team announced support for backend functions that use runtimes beyond the existing support for Node.js. With this new feature, customers can now write backend functions using Python, Java, Go, and .NET Core to handle requests from their REST or GraphQL APIs, triggers from services like Amazon DynamoDB and Amazon […]
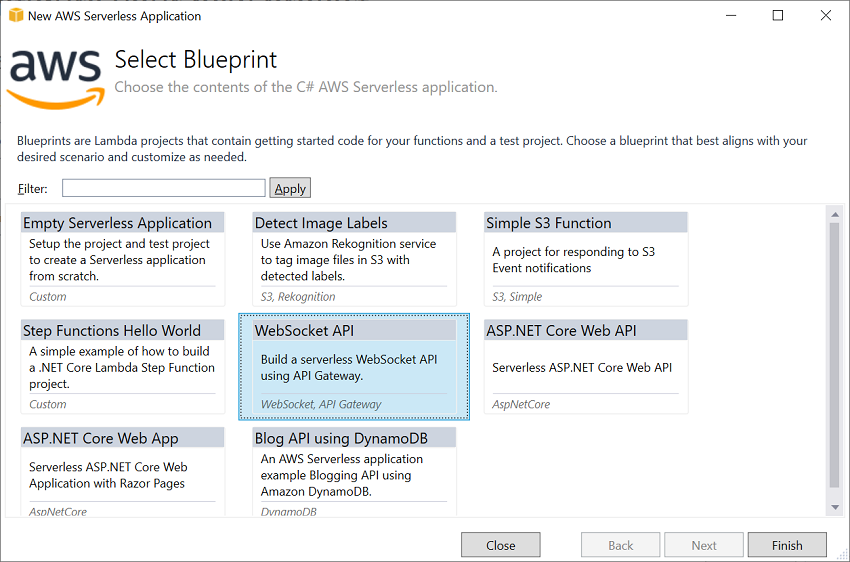
One Month Update to .NET Core 3.1 Lambda
One Month Update to .NET Core 3.1 Lambda About one month ago we released the .NET Core 3.1 Lambda runtime. Since then we have seen a lot excitement for creating new .NET Core 3.1 Lambda functions or porting existing Lambda functions to .NET Core 3.1. We have also received some great feedback and as a […]

AWS CodeBuild Test Reporting with .NET Core
At AWS re:Invent 2019, AWS CodeBuild announced a new test reporting feature which can help make diagnosing test failures in CodeBuild much easier. You can read more about it here. I wanted to use this feature for .NET and after a little research I was able to quickly add support for .NET tests to my […]
Introducing enhanced DynamoDB client in the AWS SDK for Java v2
We are pleased to announce the release of the enhanced DynamoDB client as a new module of the AWS SDK for Java 2.0. This enhanced DynamoDB module provides a more idiomatic code authoring experience. You can now integrate applications with Amazon DynamoDB using an adaptive API that allows you to execute database operations directly with […]

Introducing the AWS CDK public roadmap
We’ve published an AWS Cloud Development Kit (CDK) public roadmap on GitHub! As an open source project, we’re all about transparency and want to help you plan by making it easier to follow upcoming features and let us know what we should work on next. Checkout the CDK roadmap to see what we’re up to, […]
Bootstrapping a Java Lambda application with minimal AWS Java SDK startup time using Maven
We’re excited to share a new Maven Archetype for Java Lambda applications that we released recently and show you how to start building Java Lambda applications quickly, using this archetype. With the new archetype, customers can easily bootstrap a Java Lambda project configured with the AWS SDK for Java 2.x as a dependency and SAM […]