AWS DevOps & Developer Productivity Blog
Chaos engineering on Amazon EKS using AWS Fault Injection Simulator
In this post, we discuss how you can use AWS Fault Injection Simulator (AWS FIS), a fully managed fault injection service used for practicing chaos engineering. AWS FIS supports a range of AWS services, including Amazon Elastic Kubernetes Service (Amazon EKS), a managed service that helps you run Kubernetes on AWS without needing to install and operate your own Kubernetes control plane or worker nodes. In this post, we aim to show how you can simplify the process of setting up and running controlled fault injection experiments on Amazon EKS using pre-built templates as well as custom faults to find hidden weaknesses in your Amazon EKS workloads.
What is chaos engineering?
Chaos engineering is the process of stressing an application in testing or production environments by creating disruptive events, such as server outages or API throttling, observing how the system responds, and implementing improvements. Chaos engineering helps you create the real-world conditions needed to uncover the hidden issues and performance bottlenecks that are difficult to find in distributed systems. It starts with analyzing the steady-state behavior, building an experiment hypothesis (for example, stopping x number of instances will lead to x% more retries), running the experiment by injecting fault actions, monitoring rollback conditions, and addressing the weaknesses.
AWS FIS lets you easily run fault injection experiments that are used in chaos engineering, making it easier to improve an application’s performance, observability, and resiliency.
Solution overview
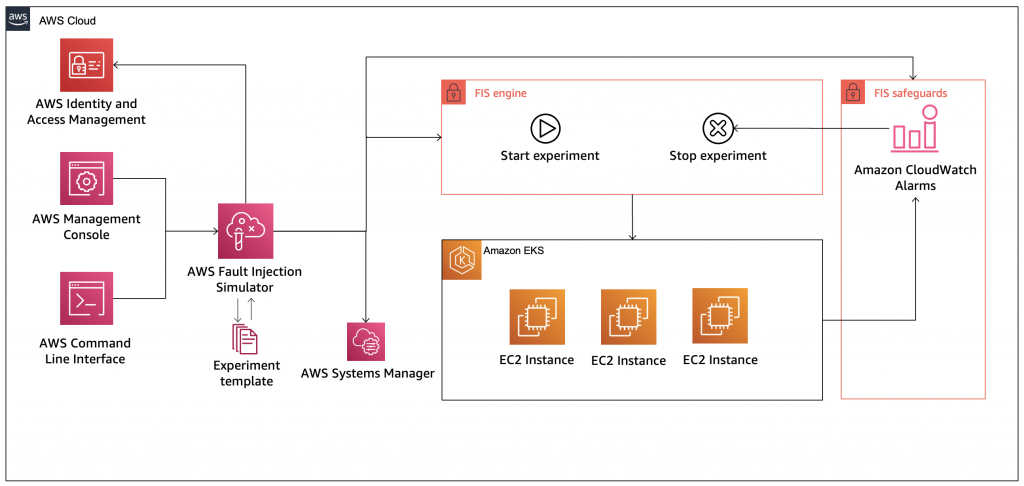
Figure 1: Solution Overview
The following diagram illustrates our solution architecture.
In this post, we demonstrate two different fault experiments targeting an Amazon EKS cluster. This post doesn’t go into details about the creation process of an Amazon EKS cluster; for more information, see Getting started with Amazon EKS – eksctl and eksctl – The official CLI for Amazon EKS.
Prerequisites
Before getting started, make sure you have the following prerequisites:
- Access to an AWS account
- kubectl locally installed to interact with the Amazon EKS cluster
- A running Amazon EKS cluster with Cluster Autoscaler and Container Insights
- Correct AWS Identity and Access Management (IAM) permissions to work with AWS FIS (see Set up permissions for IAM users and roles) and permissions for AWS FIS to run experiments on your behalf (see Set up the IAM role for the AWS FIS service)
We used the following configuration to create our cluster:
---
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: aws-fis-eks
region: eu-west-1
version: "1.19"
iam:
withOIDC: true
managedNodeGroups:
- name: nodegroup
desiredCapacity: 3
instanceType: t3.small
ssh:
enableSsm: true
tags:
Environment: DevOur cluster was created with the following features:
- Three Amazon Elastic Compute Cloud (Amazon EC2) t3.small instances spread across three different Availability Zones
- Enabled OIDC provider
- Enabled AWS Systems Manager Agent on the instances (which we use later)
- Tagged instances
We have deployed a simple Nginx deployment with three replicas, each running on different instances for high availability.
In this post, we perform the following experiments:
- Terminate node group instances – In the first experiment, we will use the
aws:eks:terminate-nodegroup-instanceAWS FIS action that runs the Amazon EC2 API action TerminateInstances on the target node group. When the experiment starts, AWS FIS begins to terminate nodes, and we should be able to verify that our cluster replaces the terminated nodes with new ones as per our desired capacity configuration for the cluster. - Delete application pods – In the second experiment, we show how you can use AWS FIS to run custom faults against the cluster. Although AWS FIS plans to expand on supported faults for Amazon EKS in the future, in this example we demonstrate how you can run a custom fault injection, running kubectl commands to delete a random pod for our Kubernetes deployment. Using a Kubernetes deployment is a good practice to define the desired state for the number of replicas you want to run for your application, and therefore ensures high availability in case one of the nodes or pods is stopped.
Experiment 1: Terminate node group instances
We start by creating an experiment to terminate Amazon EKS nodes.
- On the AWS FIS console, choose Create experiment template.

Figure 2: AWS FIS Console
2. For Description, enter a description.
3. For IAM role, choose the IAM role you created.
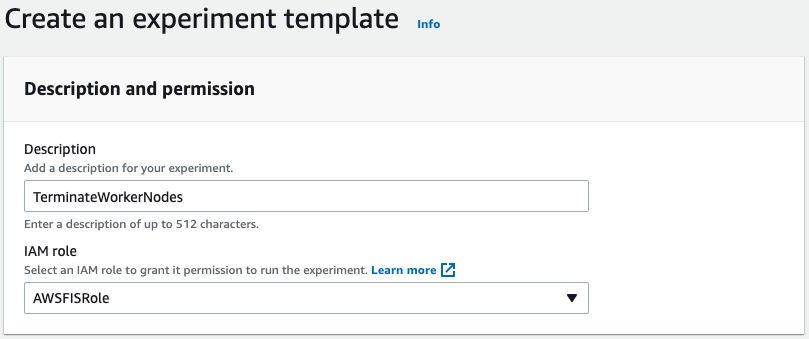
Figure 3: Create experiment template
4. Choose Add action.
For our action, we want aws:eks:terminate-nodegroup-instances to terminate worker nodes in our cluster.
5. For Name, enter TerminateWorkerNode.
6. For Description, enter Terminate worker node.
7. For Action type, choose aws:eks:terminate-nodegroup-instances.
8. For Target, choose Nodegroups-Target-1.
9. For instanceTerminationPercentage, enter 40 (the percentage of instances that are terminated per node group).
10. Choose Save.
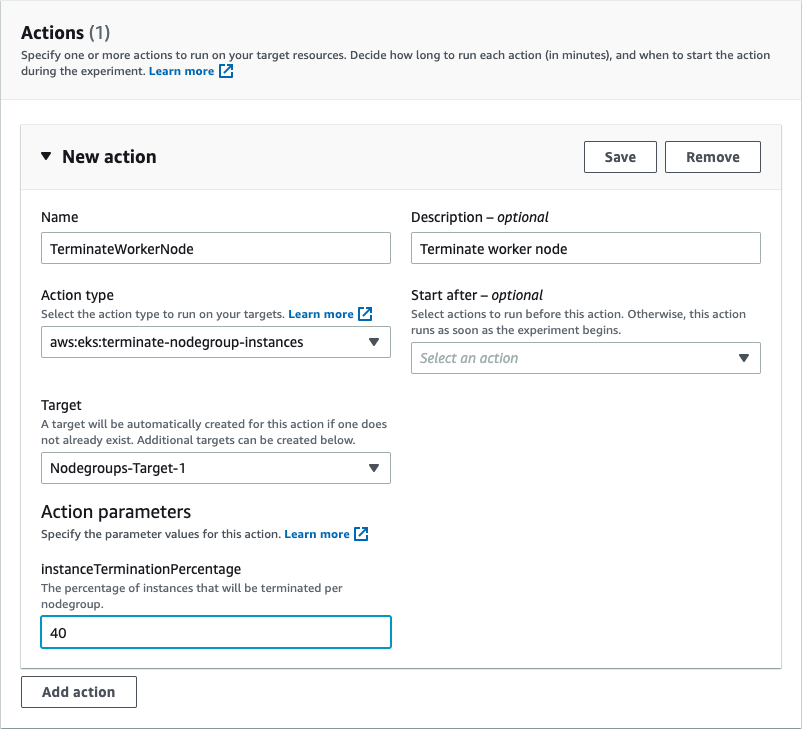
Figure 4: Select action type
After you add the correct action, you can modify your target, which in this case is Amazon EKS node group instances.
11. Choose Edit target.
12. For Resource type, choose aws:eks:nodegroup.
13. For Target method, select Resource IDs.
14. For Resource IDs, enter your resource ID.
15. Choose Save.
With selection mode in AWS FIS, you can select your Amazon EKS cluster node group.
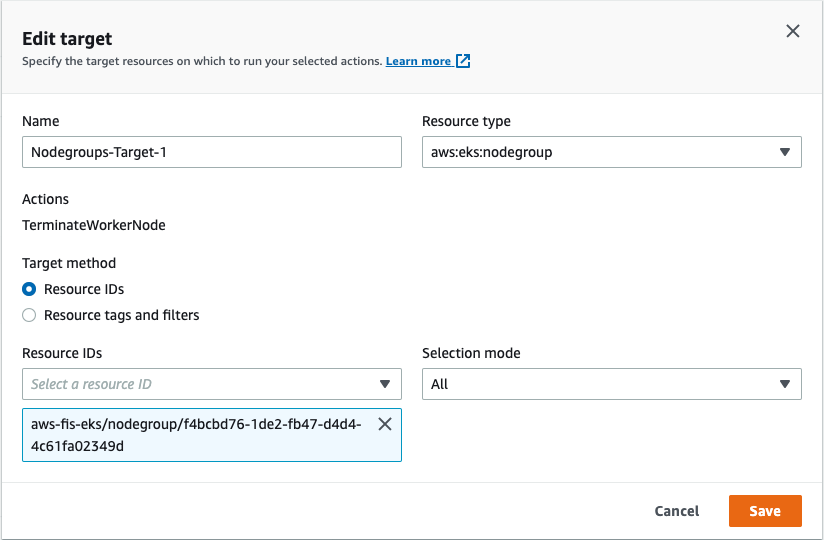
Figure 5: Specify target resource
Finally, we add a stop condition. Even though this is optional, it’s highly recommended, because it makes sure we run experiments with the appropriate guardrails in place. The stop condition is a mechanism to stop an experiment if an Amazon CloudWatch alarm reaches a threshold that you define. If a stop condition is triggered during an experiment, AWS FIS stops the experiment, and the experiment enters the stopping state.
Because we have Container Insights configured for the cluster, we can monitor the number of nodes running in the cluster.
16. Through Container Insights, create a CloudWatch alarm to stop our experiment if the number of nodes is less than two.
17. Add the alarm as a stop condition.
18. Choose Create experiment template.
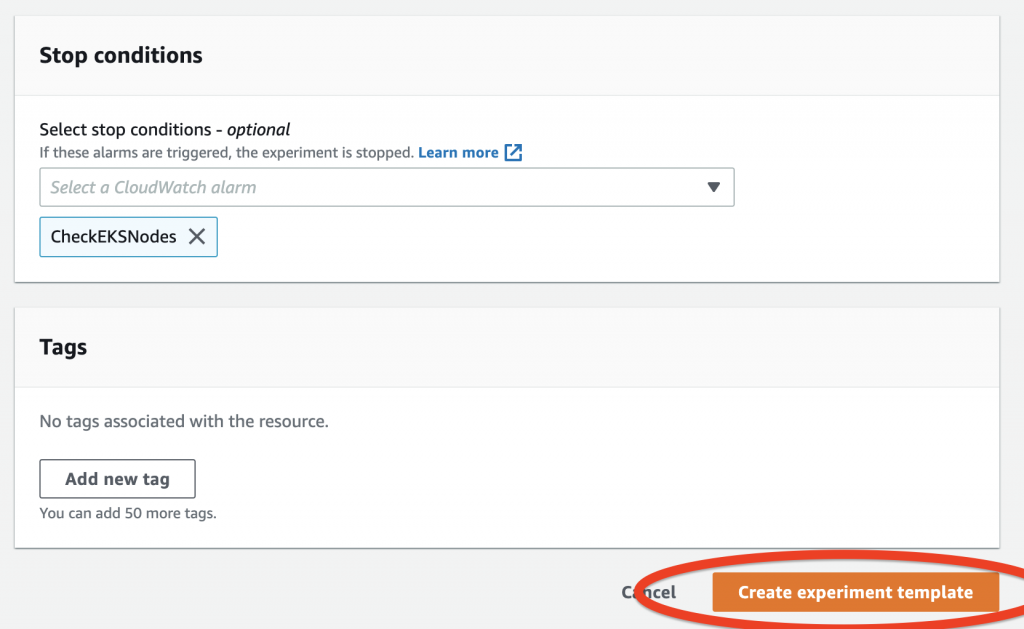
Figure 6: Create experiment template

Figure 7: Check cluster nodes
Before we run our first experiment, let’s check our Amazon EKS cluster nodes. In our case, we have three nodes up and running.
19. On the AWS FIS console, navigate to the details page for the experiment we created.
20. On the Actions menu, choose Start.
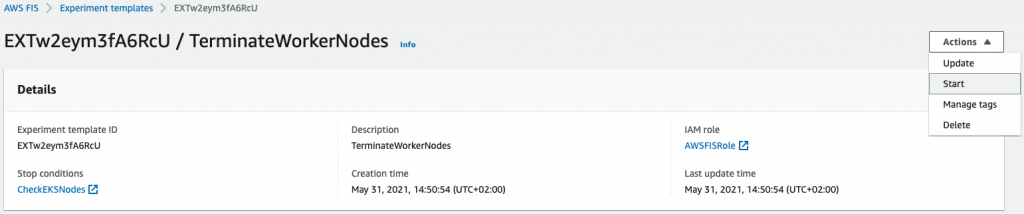
Figure 8: Start experiment
Before we run our experiment, AWS FIS will ask you to confirm if you want to start the experiment. This is another example of safeguards to make sure you’re ready to run an experiment against your resources.
21. Enter start in the field.
22. Choose Start experiment.
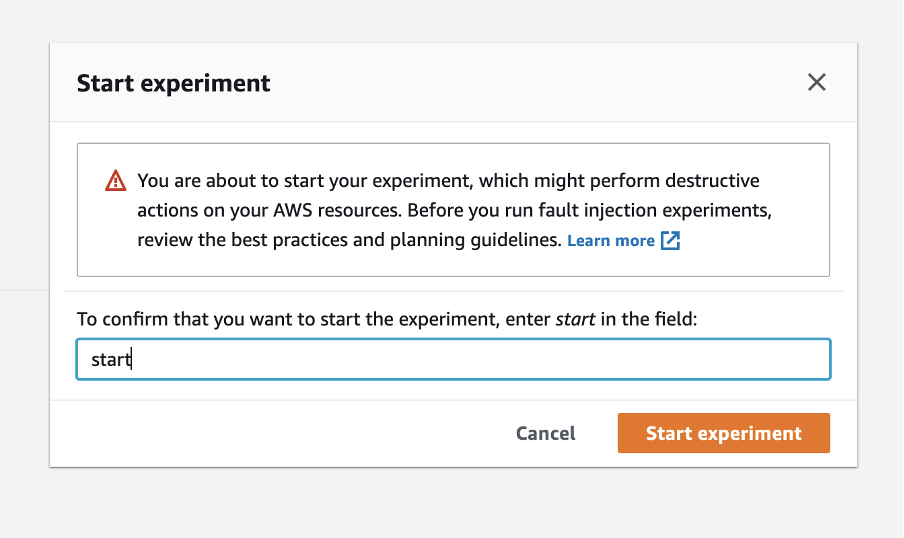
Figure 9: Confirm to start experiment
After you start the experiment, you can see the experiment ID with its current state. You can also see the action the experiment is running.
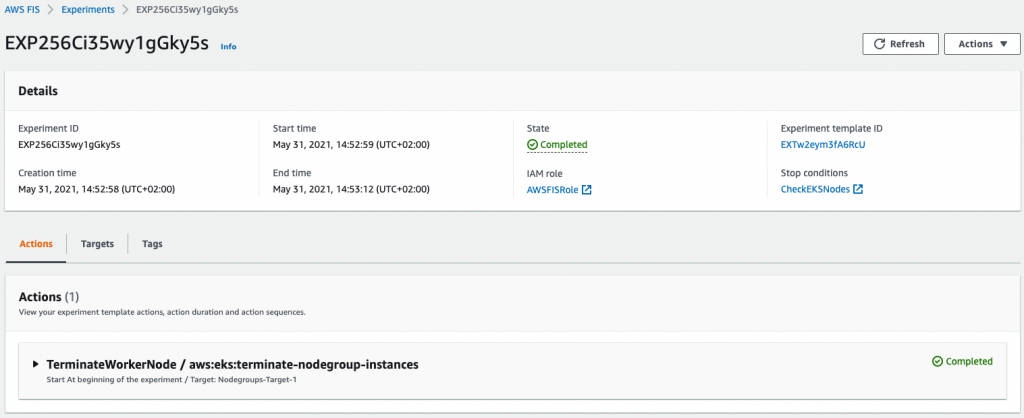
Figure 10: Check experiment state
Next, we can check the status of our cluster worker nodes. The process of adding a new node to the cluster takes a few minutes, but after a while we can see that Amazon EKS has launched new instances to replace the terminated ones.
The number of terminated instances should reflect the percentage that we provided as part of our action configuration. Because our experiment is complete, we can verify our hypothesis—our cluster eventually reached a steady state with a number of nodes equal to the desired capacity within a few minutes.

Figure 11: Check new worker node
Experiment 2: Delete application pods
Now, let’s create a custom fault injection, targeting a specific containerized application (pod) running on our Amazon EKS cluster.
As a prerequisite for this experiment, you need to update your Amazon EKS cluster configmap, adding the IAM role that is attached to your worker nodes. The reason for adding this role to the configmap is because the experiment uses kubectl, the Kubernetes command-line tool that allows us to run commands against our Kubernetes cluster. For instructions, see Managing users or IAM roles for your cluster.
- On the Systems Manager console, choose Documents.
- On the Create document menu, choose Command or Session.
-

Figure 12: Create AWS Systems Manager Document
3. For Name, enter a name (for example, Delete-Pods).
4. In the Content section, enter the following code:
---
description: |
### Document name - Delete Pod
## What does this document do?
Delete Pod in a specific namespace via kubectl
## Input Parameters
* Cluster: (Required)
* Namespace: (Required)
* InstallDependencies: If set to True, Systems Manager installs the required dependencies on the target instances. (default True)
## Output Parameters
None.
schemaVersion: '2.2'
parameters:
Cluster:
type: String
description: '(Required) Specify the cluster name'
Namespace:
type: String
description: '(Required) Specify the target Namespace'
InstallDependencies:
type: String
description: 'If set to True, Systems Manager installs the required dependencies on the target instances (default: True)'
default: 'True'
allowedValues:
- 'True'
- 'False'
mainSteps:
- action: aws:runShellScript
name: InstallDependencies
precondition:
StringEquals:
- platformType
- Linux
description: |
## Parameter: InstallDependencies
If set to True, this step installs the required dependecy via operating system's repository.
inputs:
runCommand:
- |
#!/bin/bash
if [[ "{{ InstallDependencies }}" == True ]] ; then
if [[ "$( which kubectl 2>/dev/null )" ]] ; then echo Dependency is already installed. ; exit ; fi
echo "Installing required dependencies"
sudo mkdir -p $HOME/bin && cd $HOME/bin
sudo curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.20.4/2021-04-12/bin/linux/amd64/kubectl
sudo chmod +x ./kubectl
export PATH=$PATH:$HOME/bin
fi
- action: aws:runShellScript
name: ExecuteKubectlDeletePod
precondition:
StringEquals:
- platformType
- Linux
description: |
## Parameters: Namespace, Cluster, Namespace
This step will terminate the random first pod based on namespace provided
inputs:
maxAttempts: 1
runCommand:
- |
if [ -z "{{ Cluster }}" ] ; then echo Cluster not specified && exit; fi
if [ -z "{{ Namespace }}" ] ; then echo Namespace not specified && exit; fi
pgrep kubectl && echo Another kubectl command is already running, exiting... && exit
EC2_REGION=$(curl -s http://169.254.169.254/latest/dynamic/instance-identity/document|grep region | awk -F\" '{print $4}')
aws eks --region $EC2_REGION update-kubeconfig --name {{ Cluster }} --kubeconfig /home/ssm-user/.kube/config
echo Running kubectl command...
TARGET_POD=$(kubectl --kubeconfig /home/ssm-user/.kube/config get pods -n {{ Namespace }} -o jsonpath={.items[0].metadata.name})
echo "TARGET_POD: $TARGET_POD"
kubectl --kubeconfig /home/ssm-user/.kube/config delete pod $TARGET_POD -n {{ Namespace }} --grace-period=0 --force
echo Finished kubectl delete pod command.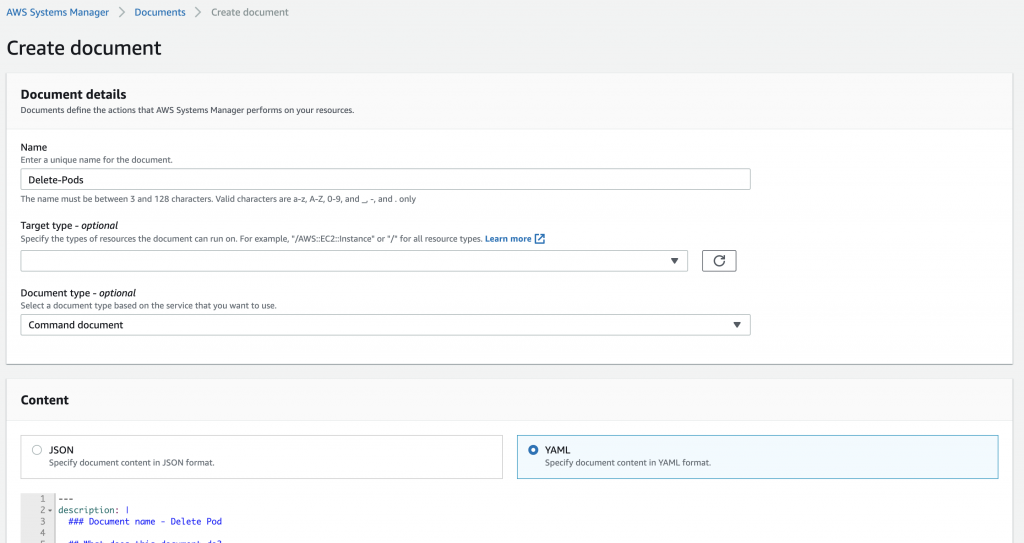
Figure 13: Add Document details
For this post, we create a Systems Manager command document that does the following:
- Installs kubectl on the target Amazon EKS cluster instances
- Uses two required parameters—the Amazon EKS cluster name and namespace where your application pods are running
- Runs kubectl delete, deleting one of our application pods from a specific namespace
5. Choose Create document.
6. Create a new experiment template on the AWS FIS console.
7. For Name, enter DeletePod.
8. For Action type, choose aws:ssm:send-command.
This runs the Systems Manager API action SendCommand to our target EC2 instances.
After choosing this action, we need to provide the ARN for the document we created earlier, and provide the appropriate values for the cluster and namespace. In our example, we named the document Delete-Pods, our cluster name is aws-fis-eks, and our namespace is nginx.
9. For documentARN, enter arn:aws:ssm:<region>:<accountId>:document/Delete-Pods.
10. For documentParameters, enter {"Cluster":"aws-fis-eks", "Namespace":"nginx", "InstallDependencies":"True"}.
11. Choose Save.
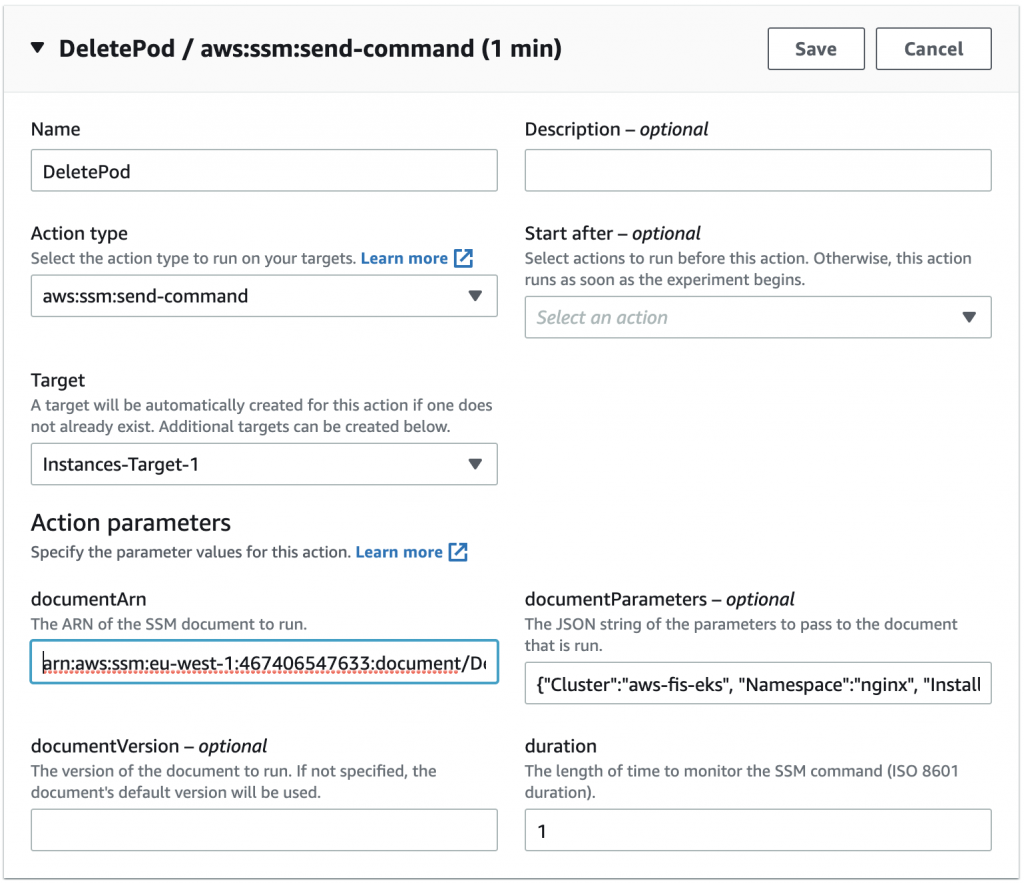
Figure 14: Select Action type
12. For our targets, we can either target our resources by resource IDs or resource tags. For this example we target one of our node instances by resource ID.
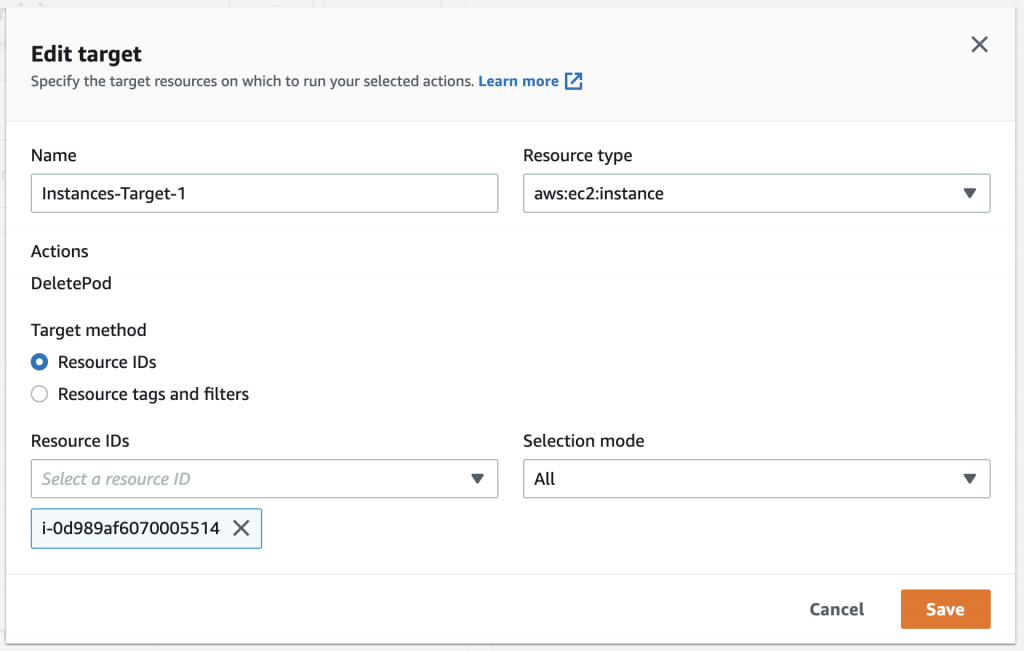
Figure 15: Specify target resource
13. After you create the template successfully, start the experiment.
When the experiment is complete, check your application pods. In our case, AWS FIS stopped one of our pod replicas and because we use a Kubernetes deployment, as we discussed before, a new pod replica was created.
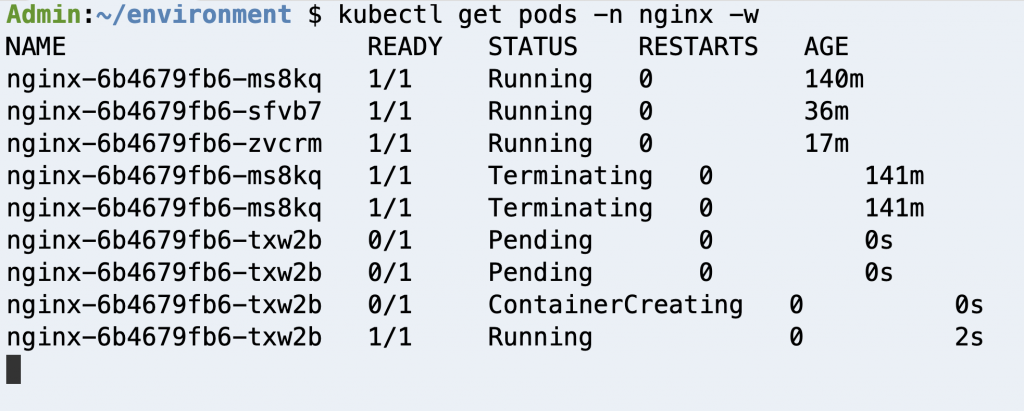
Figure 16: Check Deployment pods
Clean up
To avoid incurring future charges, follow the steps below to remove all resources that was created following along with this post.
- From the AWS FIS console, delete the following experiments, TerminateWorkerNodes & DeletePod.
- From the AWS EKS console, delete the test cluster created following this post, aws-fis-eks.
- From the AWS Identity and Access Management (IAM) console, delete the IAM role AWSFISRole.
- From the Amazon CloudWatch console, delete the CloudWatch alarm CheckEKSNodes.
- From the AWS Systems Manager console, delete the Owned by me document Delete-Pods.
Conclusion
In this post, we showed two ways you can run fault injection experiments on Amazon EKS using AWS FIS. First, we used a native action supported by AWS FIS to terminate instances from our Amazon EKS cluster. Then, we extended AWS FIS to inject custom faults on our containerized applications running on Amazon EKS.
For more information about AWS FIS, check out the AWS re:Invent 2020 session AWS Fault Injection Simulator: Fully managed chaos engineering service. If you want to know more about chaos engineering, check out the AWS re:Invent session Testing resiliency using chaos engineering and The Chaos Engineering Collection. Finally, check out the following GitHub repo for additional example experiments, and how you can work with AWS FIS using the AWS Cloud Development Kit (AWS CDK).
About the authors

Omar is a Professional Services consultant who helps customers adopt DevOps culture and best practices. He also works to simplify the adoption of AWS services by automating and implementing complex solutions.

Daniel Arenhage is a Solutions Architect at Amazon Web Services based in Gothenburg, Sweden.