AWS HPC Blog
A Technical Deep Dive into Amazon EC2 Hpc8a Performance for Engineering and Scientific Workloads
High performance computing (HPC) workloads continue to grow in scale and complexity. Whether simulating airflow over an aircraft wing, modeling structural behavior under load, or performing crash simulation and multi-physics analysis, these workloads demand sustained compute throughput, high memory bandwidth, and efficient scaling across large clusters. Improvements in any one of these dimensions can reduce runtime, but meaningful reductions in time-to-solution require advances across the entire system architecture.
Amazon Elastic Compute Cloud (Amazon EC2) Hpc8a instances were designed to address these evolving requirements. Powered by 5th Generation AMD EPYC processors and integrated with Elastic Fabric Adapter (EFA) networking, Hpc8a delivers improvements in compute throughput, memory bandwidth, and scaling efficiency compared to previous generations. You can complete simulations faster, improve cluster utilization, and reduce overall infrastructure cost per simulation without requiring changes to application code.
In this post, we examine the architectural foundation of Hpc8a instances and present benchmark results demonstrating performance improvements across representative engineering and scientific workloads.
Instance architecture designed for tightly coupled HPC workloads
Each Hpc8a instance provides 192 physical cores across two processor sockets, powered by AMD EPYC processors with 96 cores per socket, and 768 GiB of system memory, enabling high compute density within a single node. Hpc8a instances are configured with Simultaneous Multithreading (SMT) disabled so that each vCPU corresponds directly to a physical core. This provides consistent and predictable performance characteristics that tightly coupled HPC workloads depend on, particularly those using Message Passing Interface (MPI).
Hpc8a instances are powered by 5th Generation AMD EPYC processors, which introduce architectural improvements in instruction throughput, cache hierarchy efficiency, and sustained performance under load. These improvements directly benefit floating-point intensive workloads such as computational fluid dynamics (CFD), finite element analysis (FEA), structural simulation, and electronic design automation.
In addition to processor improvements, Hpc8a instances are tuned specifically for HPC workloads. The Non-Uniform Memory Access (NUMA) topology is configured to improve memory locality, helping ensure that compute cores can efficiently access local memory. These optimizations enable higher sustained performance during long-running simulations and improve overall workload efficiency.
Hpc8a instances are built on the AWS Nitro System v6, which offloads virtualization, storage, and networking functions to dedicated hardware. Compared to earlier Nitro generations used in previous Hpc instances, Nitro v6 improves packet processing performance (packets per second) and reduces network latency. This architecture delivers near bare-metal performance while maintaining the flexibility, security, and scalability of cloud infrastructure.
Improving memory subsystem performance for memory-intensive workloads
Many HPC applications are constrained not only by compute capability but also by memory bandwidth. Workloads such as CFD, structural simulation, and weather modeling continuously move large datasets between memory and compute cores. When memory bandwidth is insufficient, compute cores spend time waiting for data rather than performing useful computation.
Hpc8a provides significantly higher effective memory bandwidth compared to previous generations, enabling improved performance for memory-intensive workloads. To quantify these improvements, we measured sustained memory bandwidth using the STREAM Triad benchmark. The results demonstrate higher aggregate memory bandwidth per node and improved bandwidth efficiency per core compared to Hpc7a, allowing memory-bound workloads to better utilize available compute resources.
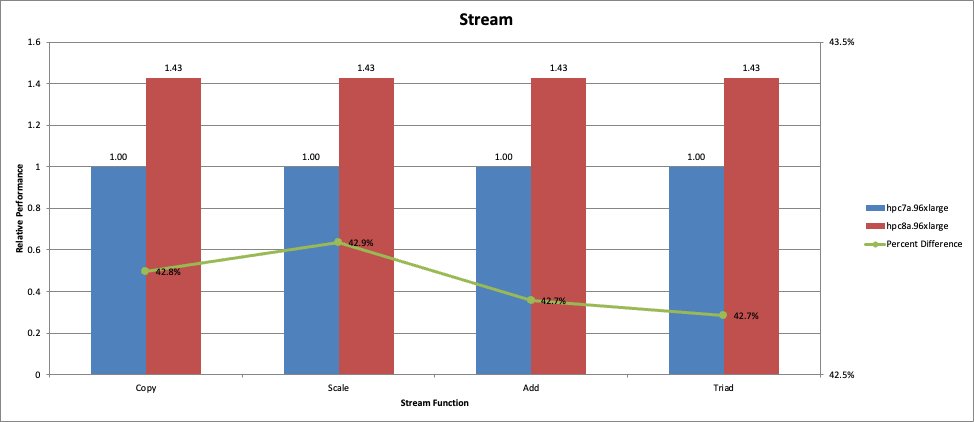
Figure 1: STREAM Triad memory bandwidth comparison between Hpc8a and Hpc7a instances.
Increased memory bandwidth allows compute cores to remain fully utilized, improving overall application throughput.
These improvements benefit applications that perform stencil operations, sparse matrix computations, and particle-based simulations. In these workloads, improved memory subsystem performance translates directly into faster simulation completion.
Enabling efficient distributed scaling with Elastic Fabric Adapter
As HPC workloads scale beyond a single instance, network performance becomes increasingly important. Many applications rely on frequent communication between nodes to exchange boundary conditions and synchronize computation phases. Network latency and bandwidth directly impact scaling efficiency and overall application performance.
Hpc8a instances support Elastic Fabric Adapter networking with up to 300 Gbps of bandwidth. While the peak network bandwidth is similar to previous Hpc generations, Hpc8a is built on AWS Nitro System v6, which improves packet processing performance (packets per second) and reduces network latency compared to earlier Nitro generations. These enhancements improve small-message performance and MPI communication efficiency, which are critical for tightly coupled workloads. EFA enables low-latency communication using OS-bypass capabilities, allowing MPI-based applications to communicate efficiently between nodes.
These improvements help MPI-based applications scale efficiently across large clusters. Reduced communication overhead supports larger simulations and improve overall cluster efficiency.
Flexible core configuration using Optimize CPU settings
Hpc8a is delivered as a single full-node 192-core configuration. In tightly coupled HPC environments, consistent node architecture across the cluster simplifies deployment and tuning. Uniform core counts, NUMA layout, memory capacity, and network characteristics across nodes help reduce configuration complexity and support predictable scaling behavior for MPI-based workloads.
Hpc8a instances support Optimize CPU settings, allowing customers to configure the number of active cores per instance. This provides flexibility for applications that are licensed per core or tuned for specific memory bandwidth per core ratios. Optimize CPU is well suited when a fixed core configuration is desired for the lifetime of the instance. In environments where multiple workloads with different CPU requirements share the same node, core allocation can also be managed at the workload scheduler or operating system level without modifying the underlying instance configuration. Additional implementation guidance will be available in the AWS HPC Applications GitHub repository.
CFD workload performance using ANSYS Fluent
Computational fluid dynamics workloads are highly sensitive to both compute throughput and memory bandwidth. These workloads involve continuous updates to large numerical grids and frequent communication between nodes.
To evaluate performance improvements, we ran the ANSYS Fluent v251 f1_racecar_140M benchmark across multiple instance counts.
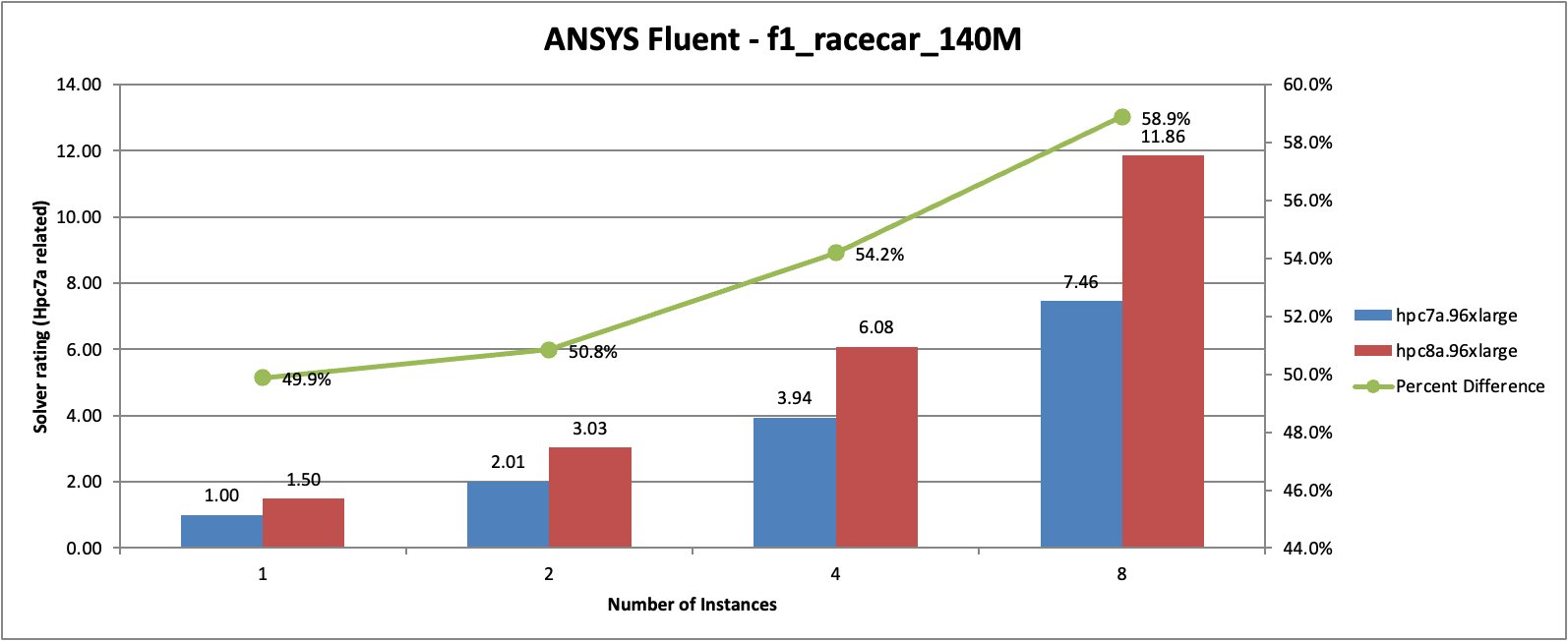
Figure 2: ANSYS Fluent f1_racecar_140M benchmark performance comparison between Hpc8a and Hpc7a instances across multiple instance counts.
In this benchmark, Hpc8a delivered approximately 50 percent higher performance compared to Hpc7a at a single instance. As the workload scaled across additional instances, performance improvements increased further, reaching approximately 59 percent higher performance at eight instances.
The gains come from both higher per-core performance and improved scaling efficiency. Faster communication between nodes and improved memory subsystem performance allow the simulation to progress more efficiently at scale.
CFD workload performance using Siemens StarCCM+
To evaluate performance across another representative CFD workload, we ran the StarCCM+ 19.06.008 with LeMans Car benchmark across multiple node counts.
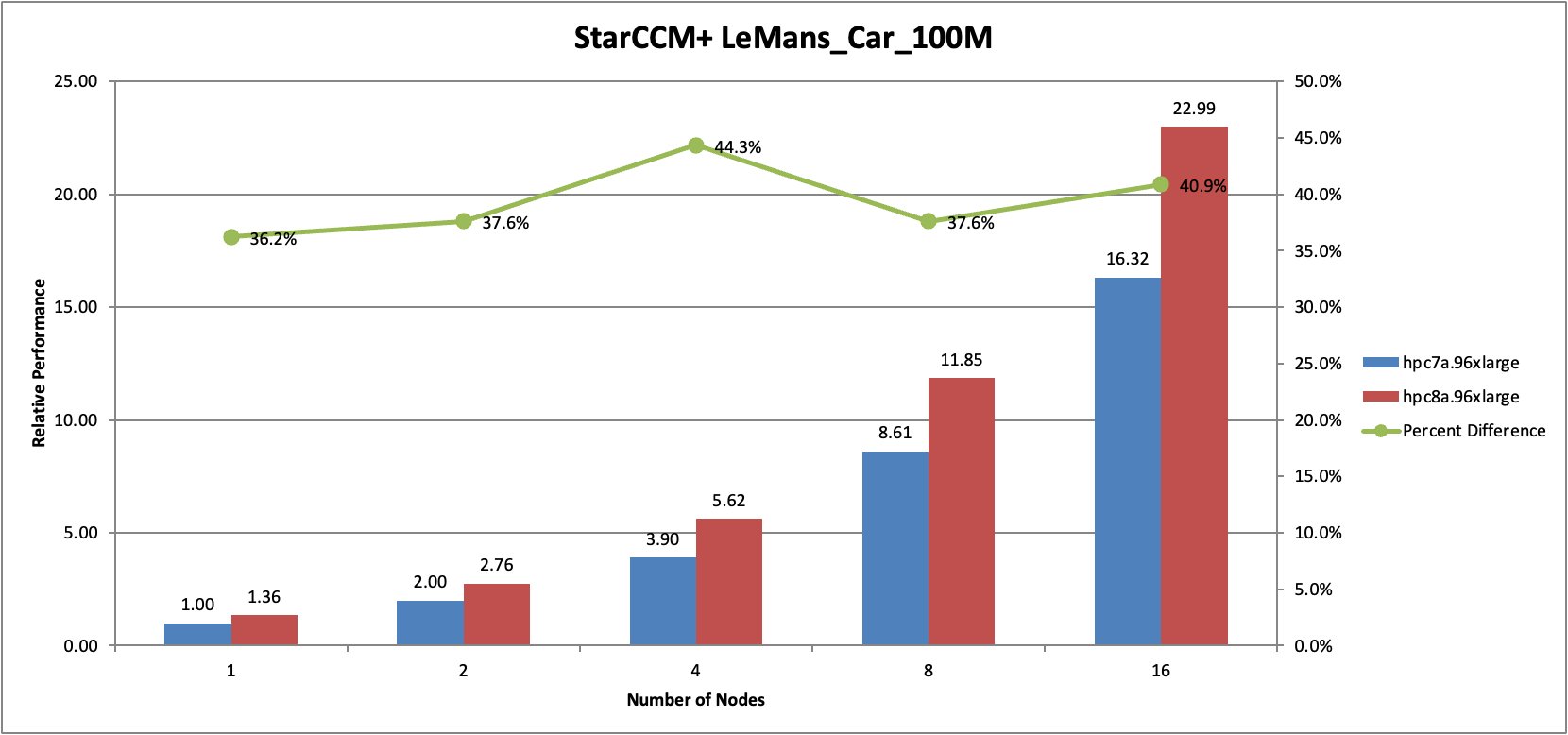
Figure 3: Siemens StarCCM+ LeMans Car benchmark performance comparison between Hpc8a and Hpc7a instances across multiple node counts.
In this benchmark, Hpc8a delivered between approximately 36 percent and 44 percent higher performance compared to Hpc7a across all tested node counts. Performance improvements remained consistent as the simulation scaled across increasing numbers of nodes.
These results demonstrate that Hpc8a improves both single-node performance and distributed scaling efficiency, enabling customers to complete CFD simulations faster.
Structural simulation performance using ANSYS Mechanical
Finite element analysis workloads are commonly used across aerospace, automotive, and industrial engineering applications. These workloads rely on both compute throughput and memory subsystem performance.
We evaluated performance using the ANSYS Mechanical benchmark.
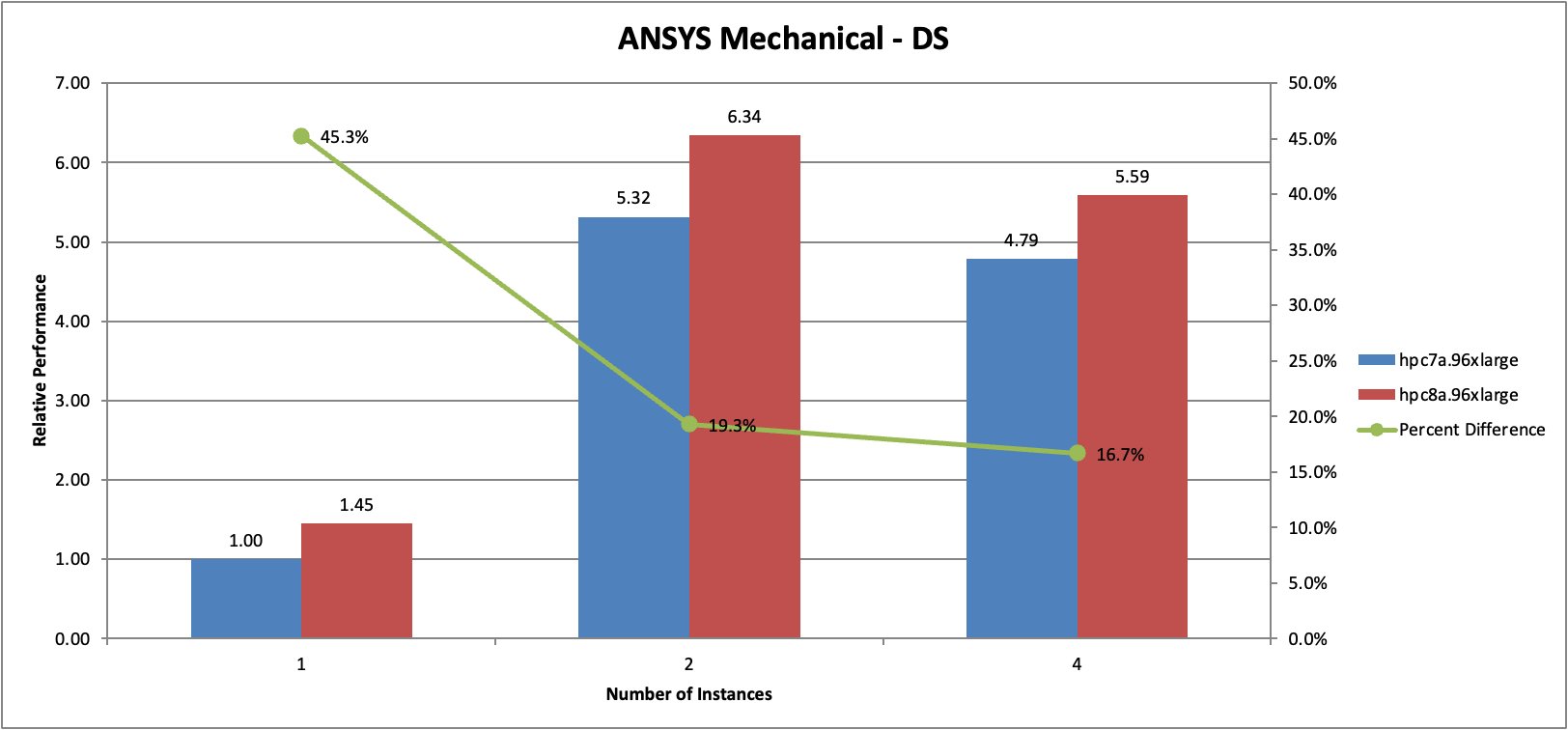
Figure 4: ANSYS Mechanical benchmark performance comparison between Hpc8a and Hpc7a instances at single-node and multi-node configurations.
In this benchmark, Hpc8a delivered approximately 45 percent higher performance compared to Hpc7a at a single instance. At single-instance scale, the workload operates in out-of-core mode, generating increased disk I/O as the working dataset exceeds available system memory. When scaling to two instances, the simulation runs in-core, significantly reducing I/O activity and improving overall execution efficiency. Multi-instance configurations also showed meaningful performance improvements, demonstrating improved efficiency across both compute and memory subsystems. Notably, Hpc8a demonstrates stronger performance gains than Hpc7a during out-of-core execution. This behavior reflects improved sustained compute throughput and higher effective memory bandwidth under memory pressure, allowing the workload to make forward progress more efficiently even when increased I/O activity is present.
These improvements allow customers to solve larger structural models and complete simulations more quickly.
Crash simulation performance using LS-DYNA
Explicit structural simulations such as crash analysis rely on sustained compute throughput and efficient communication between nodes.
We evaluated performance using the LS-DYNA Car2Car benchmark.
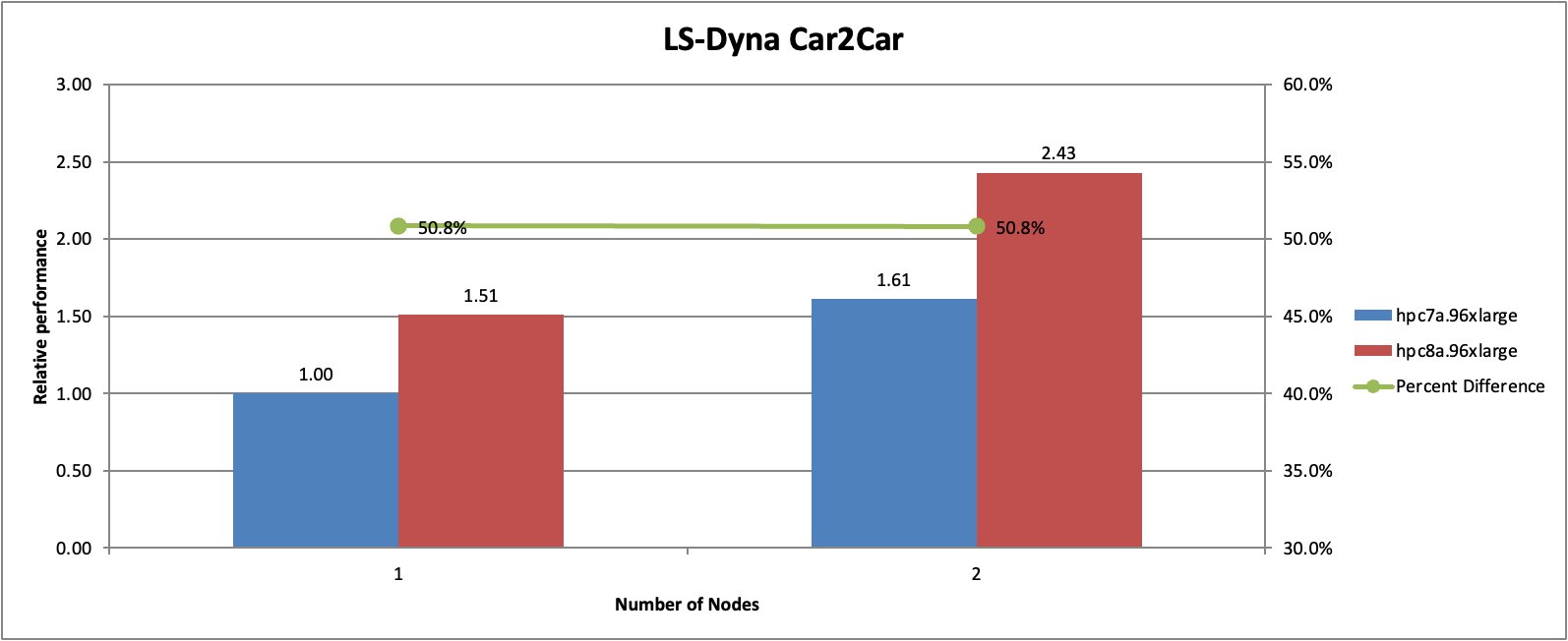
Figure 5: LS-DYNA Car2Car crash simulation benchmark performance comparison between Hpc8a and Hpc7a instances.
In this benchmark, Hpc8a delivered approximately 51 percent higher performance compared to Hpc7a. Performance improvements were consistent across both single-node and multi-node configurations.
These results demonstrate the ability of Hpc8a to accelerate explicit simulation workloads and improve overall engineering productivity.
Improving cluster efficiency and reducing time-to-solution
Across all evaluated workloads, Hpc8a demonstrated improved performance compared to previous generation instances. These improvements result from architectural advancements across multiple subsystems, including compute, memory, and networking.
Higher per-core performance enables each node to complete more work per unit time. Improved memory subsystem performance allows compute cores to remain fully utilized. Enhanced networking capabilities reduce communication overhead and improve distributed scaling efficiency.
Together, these improvements increase cluster throughput and reduce time-to-solution for engineering and scientific workloads.
Conclusion
Hpc8a instances provide improvements in compute performance, memory subsystem efficiency, and distributed scaling compared to previous generations. These improvements enable customers to accelerate engineering and scientific simulations across a wide range of workloads, including CFD, structural simulation, and crash analysis.
By combining next-generation processor architecture, high memory bandwidth, and high-performance networking, Hpc8a instances enable customers to run simulations faster, improve infrastructure efficiency, and accelerate innovation.
Get started with Hpc8a instances
You can launch Hpc8a instances from the Amazon EC2 console.
To learn more about Hpc8a specifications, supported regions, and configuration options, visit the Amazon EC2 Hpc8a instances page.
For pricing information, see Amazon EC2 Pricing page.
For application configuration guidance and reference examples, visit the AWS HPC Applications GitHub repository.