IBM & Red Hat on AWS
Real-time data streaming for AI workloads with Confluent on AWS
AI models produce better results when they operate on current data. This is especially true for agentic AI systems, which are software components that plan, decide, and act on behalf of users. When the underlying data is stale or incomplete, model outputs degrade and downstream actions become unreliable.
With IBM‘s recent completion of its acquisition of Confluent, Amazon Web Services (AWS) customers now have a more direct path from live operational data to model inference. Confluent, built on Apache Kafka and Apache Flink, provides data streaming capabilities that organizations use to move operational data in real time. As part of IBM, Confluent connects IBM’s data and integration portfolio with AWS services such as Amazon Simple Storage Service (Amazon S3), AWS Lambda, and Amazon Bedrock.
In this post, we cover how organizations use Confluent Cloud on AWS across industries, how Confluent Intelligence provides real-time context for AI workloads, and how to get started from AWS Marketplace.
Why real-time data matters for AI
Batch-oriented data pipelines introduce latency between when an event occurs and when a model can act on it. For use cases such as fraud detection, supply chain optimization, and dynamic pricing, that delay directly affects outcomes.
With Confluent Intelligence on AWS, you can run Streaming Agents that respond to live events for timely and accurate actions. These agents consume continuously updated data streams rather than static snapshots, so decisions reflect current conditions.
Real-time data also requires governance. Stream Governance on Confluent Cloud is built upon three key pillars: Stream Lineage, Stream Catalog, and Stream Quality, spanning stream capture, stream processing, and context serving. The Confluent Real-Time Context Engine unifies the serving layer for both real-time and historical data into a single managed service, delivering fresh, trustworthy context to AI agents and applications. Together, these capabilities help ensure that the real-time context reaching Amazon Bedrock is high-quality and compliant end to end, reducing the risk of unreliable model outputs caused by ungoverned data flows.
How customers use Confluent Cloud on AWS
Customers across industries leverage Confluent Cloud on AWS to move and process data in real time, unlocking new levels of operational agility. In manufacturing, for instance, customers use Confluent to manage inventory across global supply chains, reducing costs while maintaining total visibility into stock levels. Similarly, retail leaders stream product updates across internal and third-party systems to pivot quickly as demand shifts, while automotive companies stream IoT data to bridge the gap between factory floor systems and cloud applications.
These patterns share a common thread. Operational data flows continuously from source systems into Confluent Cloud on AWS, where downstream applications and AI models can consume it.
To illustrate how these patterns apply to AI workloads, consider fraud detection in financial services. Transaction events stream into Confluent Cloud on AWS. Apache Flink enriches each transaction with customer context from Amazon Relational Database Service (Amazon RDS) and runs vector search against Amazon S3 Vectors for similar historical patterns. Multivariate anomaly detection then analyzes transaction amount, location, device fingerprint, and velocity as a combined signal. Streaming Agents call Amazon Bedrock models with that enriched context to make decisions. Results flow back to customers’ operational and response systems (native on AWS or third-party) for further actions through Confluent connectors. The following diagram shows this architecture.
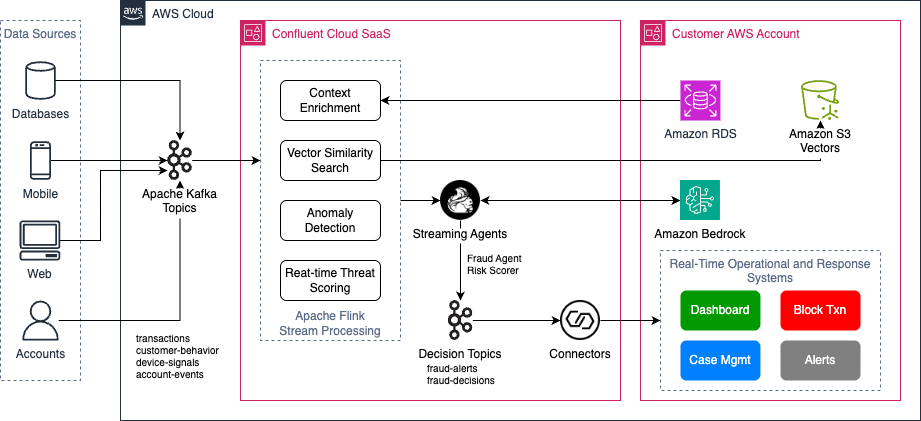
Figure 1. Real-time Fraud Detection with Confluent Cloud on AWS.
How IBM, Confluent, and AWS work together
The acquisition brings integrations across IBM’s portfolio that complement AWS services in three areas.
Confluent streams live operational events into IBM watsonx.data so that AI models and agents run on continuously updated data. You can pair this with Amazon Bedrock and other AWS AI services to build complete workflows from data ingestion through model inference.
IBM MQ and IBM webMethods Hybrid Integration work with Confluent’s event streaming capabilities. Applications, APIs, and AI agents can sense and respond to business events in real time, whether they run on AWS, on premises, or across hybrid environments.
For organizations running workloads on IBM Z, Confluent can stream transactional data directly to AWS for analytics, automation, and AI workflows.
Confluent Intelligence on AWS
Confluent Intelligence is a fully managed capability within Confluent Cloud that helps you build AI systems with real-time context. It provides built-in connectivity with AWS services and supports secure connectivity between Amazon Virtual Private Cloud (Amazon VPC) environments through AWS PrivateLink to keep AI traffic off the public internet.
On the AI side, Confluent Intelligence includes support for the Agent2Agent (A2A) protocol for orchestrating multi-agent workflows. It also provides built-in ML functions such as multivariate anomaly detection and vector search for Amazon S3 Vectors and other vector stores that support retrieval-augmented generation (RAG) workflows. Apache Flink handles enrichment by combining streaming data with external context. The following diagram shows how these capabilities work together.
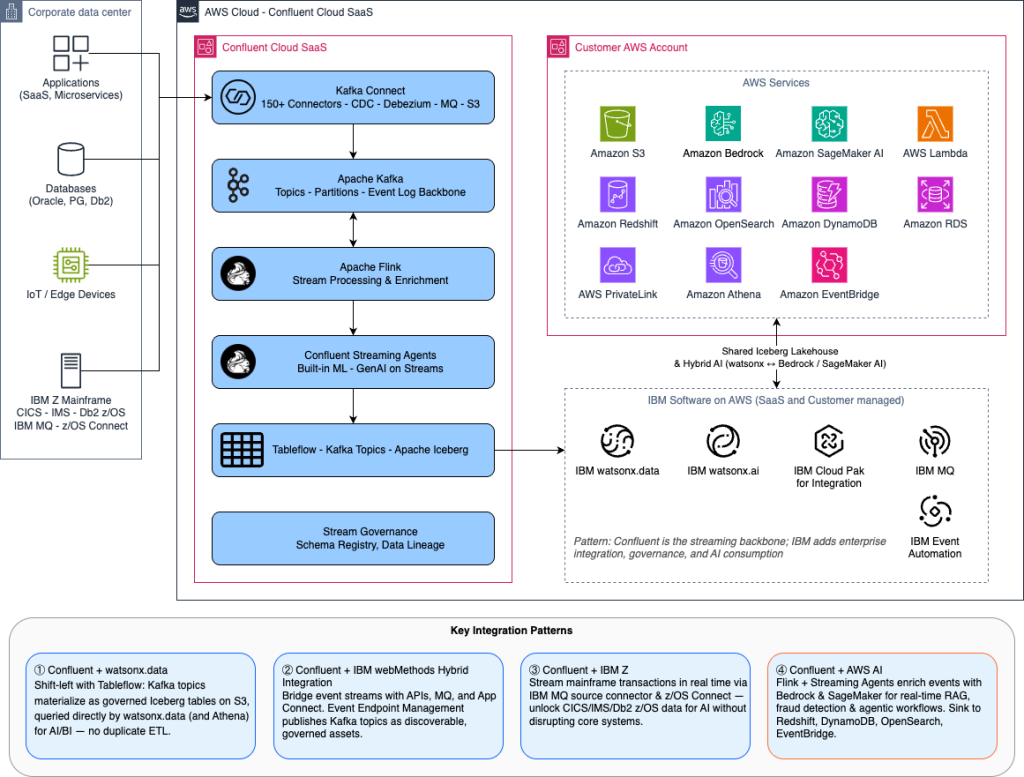
Figure 2: IBM, Confluent, and AWS AI and Data Integration Reference Architecture.
Getting started
To build AI systems with Confluent Cloud on AWS:
- Deploy Confluent Cloud from AWS Marketplace for consolidated procurement and billing.
- Connect your AWS services using the built-in integrations.
- Build Streaming Agents and AI workflows with Confluent Intelligence.
Conclusion
In this post, we covered how IBM’s acquisition of Confluent brings data streaming capabilities to AWS customers building AI workloads. We walked through use cases across manufacturing, retail, automotive, and financial services, and showed how Confluent Intelligence integrates with AWS services to provide context for AI models and agents.
IBM and Confluent on AWS Marketplace:
- Apache Kafka & Apache Flink on Confluent Cloud
- Confluent MCP Server
- IBM webMethods Hybrid Integration (iPaaS)
- IBM MQ and IBM MQ Advanced (software)
- IBM watsonx.data PayGo