AWS for Industries
BMW Group unlocks insights from petabytes of data with agentic search on AWS
The BMW Group, headquartered in Munich, Germany, employs 159,000 people across more than 30 production and assembly facilities in 15 countries. As an automotive innovation leader, BMW Group has been working to stay at the forefront of digital transformation by using data and artificial intelligence (AI). In 2020, BMW Group launched the Cloud Data Hub (CDH), which now operates as a Data Lakehouse – BMW Group’s central platform for managing company-wide data and data solutions in the cloud. It offers BMW Group employees across all corporate divisions a central starting point for implementing data-driven applications and generating data insights.
Today, CDH stores 20 PB of data and ingests an average of 110 TB data daily. Extracting insights from this vast data landscape can be a challenge, especially for users lacking technical and analytical expertise, as they need to identify relevant data sources, construct complex queries, and interpret tabular outputs.
In this blog post, we illustrate how BMW Group, in collaboration with AWS Professional Services, developed agentic search solution that combines the capabilities of Amazon S3 Vectors, Amazon Bedrock, and Amazon Bedrock AgentCore. This solution is designed to help BMW Group users, regardless of their technical skills, extract actionable data insights from massive datasets using natural language.
The challenge: Bridging the gap between data and insights
Traditional data analysis workflows are complex and time-consuming, creating barriers to quickly unlocking valuable insights from enterprise data. The process begins with discovery, requiring users to search through dozens, hundreds, or even thousands of data assets to find the right sources. Next, users must write and execute SQL queries, requiring schema knowledge for complex joins and aggregations. After generating query results, converting raw tabular output into actionable insights often requires specific domain expertise. These challenges, especially when combining structured and unstructured data, can severely limit an organization’s ability to leverage its data assets effectively.
Solution Overview
BMW Group’s agentic search solution addresses the challenge of extracting insights from massive datasets by combining three complementary search approaches within an AI agent framework. The solution enables users to query petabytes of structured and unstructured data using natural language, automatically selecting the optimal search strategy based on query characteristics.
In this blog post, we showcase the solution on a dataset from a product quality system which captures detailed records of issues reported across vehicle testing. Each record contains problem descriptions, categorizations, and technical details in both German and English, accumulated from production facilities and service centers worldwide. This dataset represents years of quality engineering knowledge, with semantically similar issues described using different terminology across teams and languages.
The architecture consists of three specialized tools, each designed for specific search patterns:
- Hybrid Search: Combines semantic similarity search with SQL filtering to efficiently retrieve conceptually similar data. This tool first performs vector-based semantic search to identify relevant records, then applies SQL filters for precise refinement. It’s ideal for queries like “find brake system feedback in specific vehicle models” where both conceptual understanding and structured filtering are required.
- Exhaustive Search: Uses AI-powered evaluation to comprehensively analyze all matching records when semantic search alone might miss relevant results due to terminology variations. This tool executes a SQL query to retrieve candidate records, then employs a large language model (LLM) to evaluate each result, determining relevance with detailed reasoning. It is particularly effective for questions like “How many brake-related issues occurred?” where complete coverage is essential.
- SQL Query: Provides direct structured query capabilities for precise data retrieval when no semantic analysis is needed. This tool handles pure analytical queries such as aggregations, counts, and statistical analysis over structured data fields.
An AI agent orchestrates these tools, analyzing each user query to determine the most appropriate search strategy. The agent automatically switches between semantic search for conceptual queries, exhaustive search for comprehensive analysis, and direct SQL for structured analytics—all through a single conversational interface. This intelligent routing allows users to receive relevant results without needing to understand the underlying technical complexity or manually select search methods.
Architecture deep dive
The following architecture diagram illustrates how these components interact to deliver the agentic search experience:
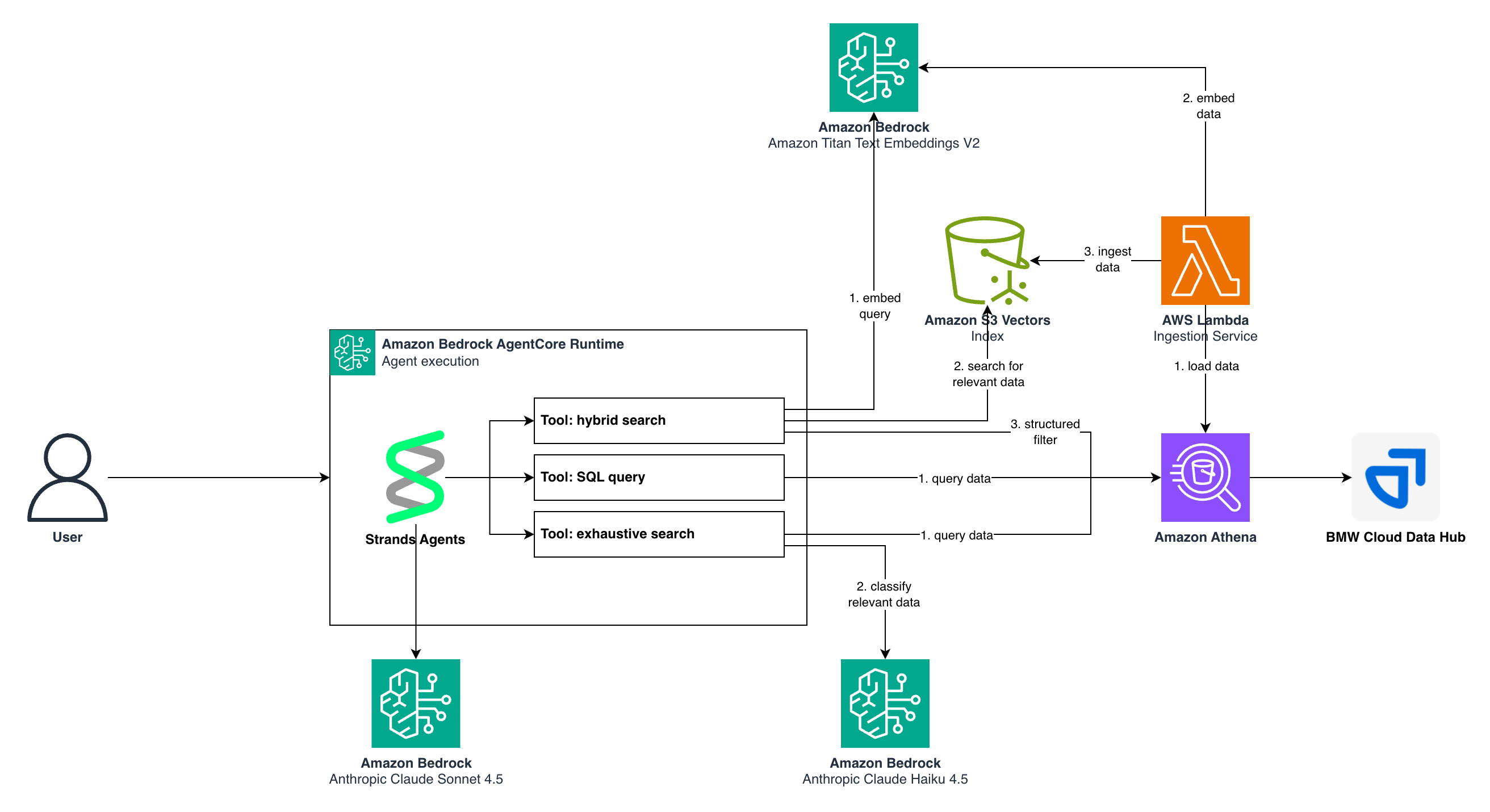
Figure 1. Agentic search solution architecture
Core components
Data storage and vector search
Amazon S3 Vectors (S3 Vectors) enables semantic similarity search on vector embeddings, supporting efficient nearest-neighbor queries across millions of data points without requiring dedicated vector database infrastructure. For structured data in S3 Vectors, Amazon Athena (Athena) provides serverless SQL query execution, enabling ad-hoc analytics and structured filtering on the original source data.
LLMs and agent implementation
Amazon Bedrock (Bedrock) powers the solution with multiple LLMs: Amazon Titan Text Embeddings V2 (Titan Text Embeddings) for generating vector embeddings, Anthropic’s Claude Sonnet 4.5 as the primary reasoning model for agent orchestration, and Anthropic’s Claude Haiku 4.5 for cost-effective classification tasks in exhaustive search. Strands Agents, AWS’s open-source framework, orchestrates the AI agent by managing tool selection, conversation flow, and model interactions while maintaining production-grade reliability.
Data ingestion and vector index creation
Before the agentic search solution can answer queries, the source data must be processed and indexed for semantic search. Here, we implemented a serverless ingestion pipeline using AWS Lambda (Lambda) to transform structured database records including free-form text attributes like titles or descriptions, into searchable vector embeddings.
The ingestion process follows these steps:
- Data extraction: Lambda functions query the source database tables in Amazon Athena, retrieving product quality records including problem descriptions, titles, and categorizations in both German and English.
- Text preparation: For each record, the pipeline concatenates semantically relevant fields (cluster names, problem titles, and descriptions) into a unified text representation suitable for embedding generation.
- Embedding generation: The prepared text is sent to Titan Text Embeddings, which generates 1,024-dimensional vector embeddings that capture the semantic meaning of each record.
- Vector storage: The embeddings are stored in Amazon S3 using the S3 Vectors index format, with each vector tagged with its corresponding record ID for retrieval during search operations.
- Metadata persistence: The original structured data remains in S3, that can be queried via Athena, enabling the agentic search tools to combine semantic similarity with SQL-based filtering.
This ingestion architecture processes data incrementally, enabling the BMW Group to continuously update the vector index as new product quality issues are reported without reprocessing the entire dataset.
Hybrid Search
The hybrid search tool combines semantic similarity with SQL filtering, enabling users to find conceptually related records while applying precise business constraints. For example, a query like “find brake system feedback in F09 vehicles from the last quarter” requires both semantic understanding (what counts as a “brake system feedback”) and structured filtering (specific vehicle model and time range).
How it works: When a user submits a query, the agent invokes the hybrid search tool with three parameters: 1) a semantic query describing the concept to search for (e.g., “brake system feedback”, 2) a top_k value specifying how many similar records to retrieve (e.g., 100) , and 3) a SQL query template containing the placeholder {semantic_ids} for filtering. The tool then executes a multi-step process to deliver relevant results.
Step 1 – Semantic Search Phase: The tool first sends the semantic query to Titan Text Embeddings to generate a query vector. This vector is then used to search the S3 Vectors index for the top_k most similar product quality records based on cosine similarity. The S3 Vectors API returns a list of IDs ranked by semantic relevance to the query.
Example input: “brake system feedback”
Example output: IDs ranked by similarity: [12847, 9203, 15634, 8821, …] (top 100 records about brake pad wear, brake fluid checks, brake performance, etc.)
Step 2 – SQL Filtering Phase: The semantic IDs are injected into the SQL query template. Athena then executes this SQL query, which can include additional WHERE clauses, JOINs, aggregations, or any valid SQL operations to further refine the results based on structured data attributes like dates, severity levels, or vehicle models.
Example input SQL template:
SELECT * FROM quality_records
WHERE record_id IN ({semantic_ids})
AND vehicle_model = ‘F09’
AND report_date >= DATE ‘2025-10-01’
Example executed query:
SELECT * FROM quality_records
WHERE record_id IN (12847, 9203, 15634, 8821, …)
AND vehicle_model = ‘F09’
AND report_date >= DATE ‘2025-10-01’
Example output:
7 records matching both semantic similarity AND structured filters
Step 3 – Result Synthesis: The filtered results are returned to the agent, which uses Anthropic’s Claude Sonnet 4.5 to synthesize a natural language response, to present the findings in a user-friendly format with relevant details and insights.
Example output to user:
“Found 7 brake-related records in F09 vehicles from Q4 2024. Most common: brake pad inspections (3 cases), brake fluid service (2 cases), brake performance checks (2 cases).”
This hybrid approach makes sure results are both semantically relevant (understands “brake system feedback” includes brake pad wear, brake fluid service, etc.) and precisely filtered (only F09, only recent quarter). The approach is also designed to provide users with results that are both semantically relevant and precisely filtered according to business requirements, combining the flexibility of natural language understanding with the precision of structured queries. The following sequence diagram illustrates the complete workflow:
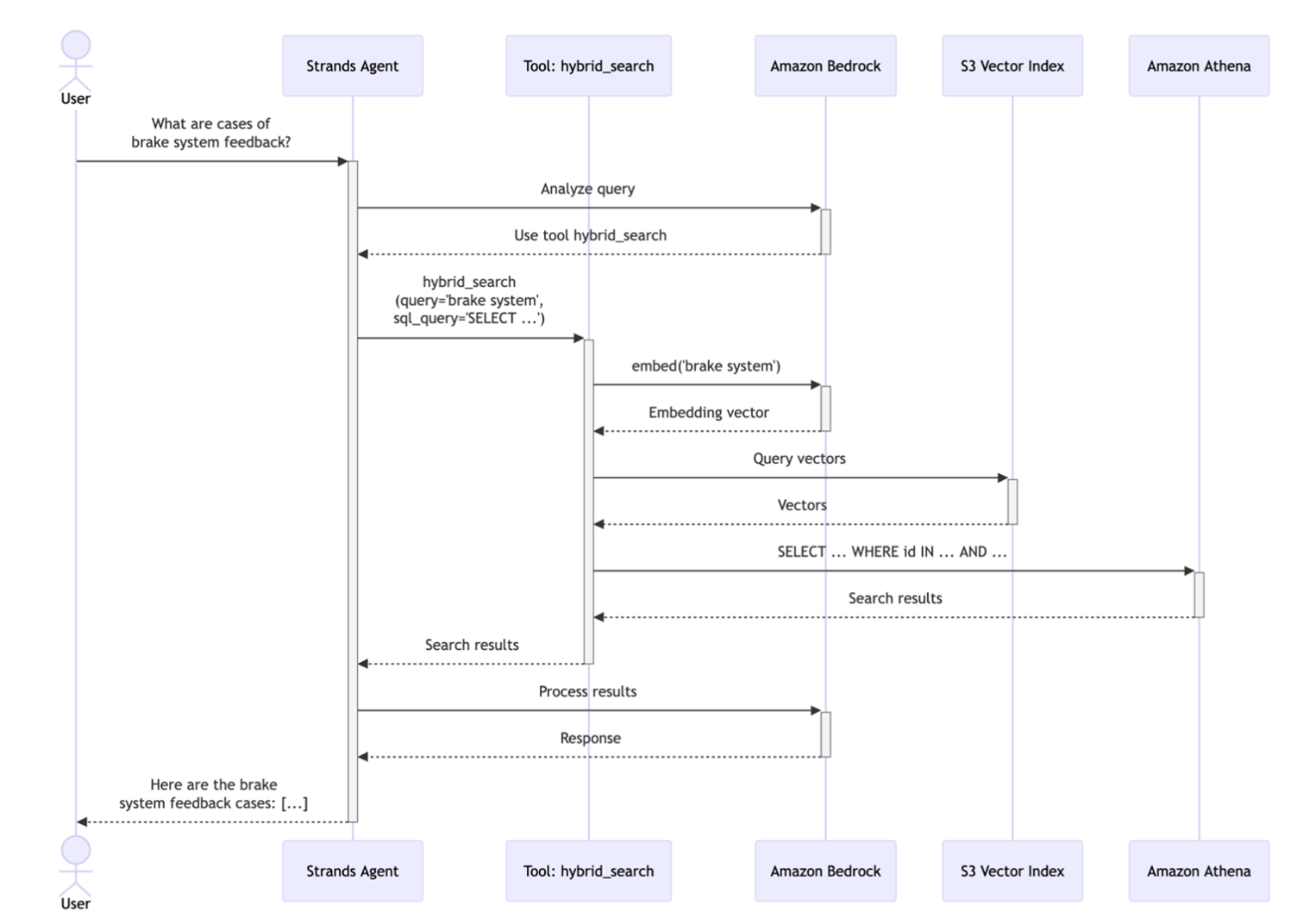
Figure 2. Hybrid search sequence diagram
Exhaustive search for comprehensive analysis
While hybrid search excels at finding semantically similar records, some queries require comprehensive analysis of all matching records to ensure complete coverage. Questions like “How many brake-related issues occurred on the F00 model?” demand exhaustive evaluation because terminology variations (e.g., “brake,” “braking system,” “brake pad,” “ABS“) might cause semantic search to miss relevant cases. The exhaustive search tool addresses this challenge by combining SQL-based candidate retrieval with AI-powered relevance classification.
The exhaustive search workflow begins when the agent determines that a query requires comprehensive coverage rather than similarity-based retrieval. The tool accepts two parameters: a SQL SELECT query that retrieves candidate records from the database, and a search problem description that defines what constitutes a relevant result.
Candidate retrieval: The agent generates a SQL query using only structured filter – not semantic concepts – to avoid terminology mismatches. For example, instead of filtering by semantic terms like “brake-related issues,” the query uses exact column values:
SELECT * FROM quality_records
WHERE vehicle_model = ‘F00’
This retrieves all records matching the structured criteria (potentially thousands of candidates) without relying on the LLM to guess correct terminology from the dataset. The tool includes a retry mechanism: if Athena returns an error (invalid column names, syntax errors, or other SQL failures), the error message is returned to the agent, which can regenerate a corrected query. This helps to prevent hallucinated SQL from silently failing and supports the agent can self-correct based on actual schema information.
Batched LLM classification: Rather than processing all candidates at once, the tool divides them into batches of 20 records for efficient processing. Each batch is formatted as a markdown table and sent to a smaller LLM (Anthropic’s Claude Haiku 4.5) via Bedrock. The model evaluates each record against the search problem, determining whether it’s relevant and providing a concise justification for its decision. We found 20 to be a good tradeoff between number of model invocations and context rot (as the number of tokens in the context window increases, the model’s ability to accurately recall information from that context decreases). The batches are processed in parallel, significantly reducing total processing time. This parallelization enables the tool to evaluate thousands of records in seconds while maintaining cost efficiency using a smaller, faster model for classification tasks.
Result aggregation: After all batches complete, the tool aggregates the relevant results, enriching each record with a _reason_for_match field containing the LLM’s justification. This transparency helps users understand why specific records were included and builds trust in the LLM-powered filtering.
The exhaustive search approach provides complete coverage for critical queries where missing relevant cases could impact business decisions. By combining SQL’s structured filtering with the semantic understanding of LLMs, the tool achieves both precision and recall that neither approach could deliver independently. The following sequence diagram illustrates the complete workflow:
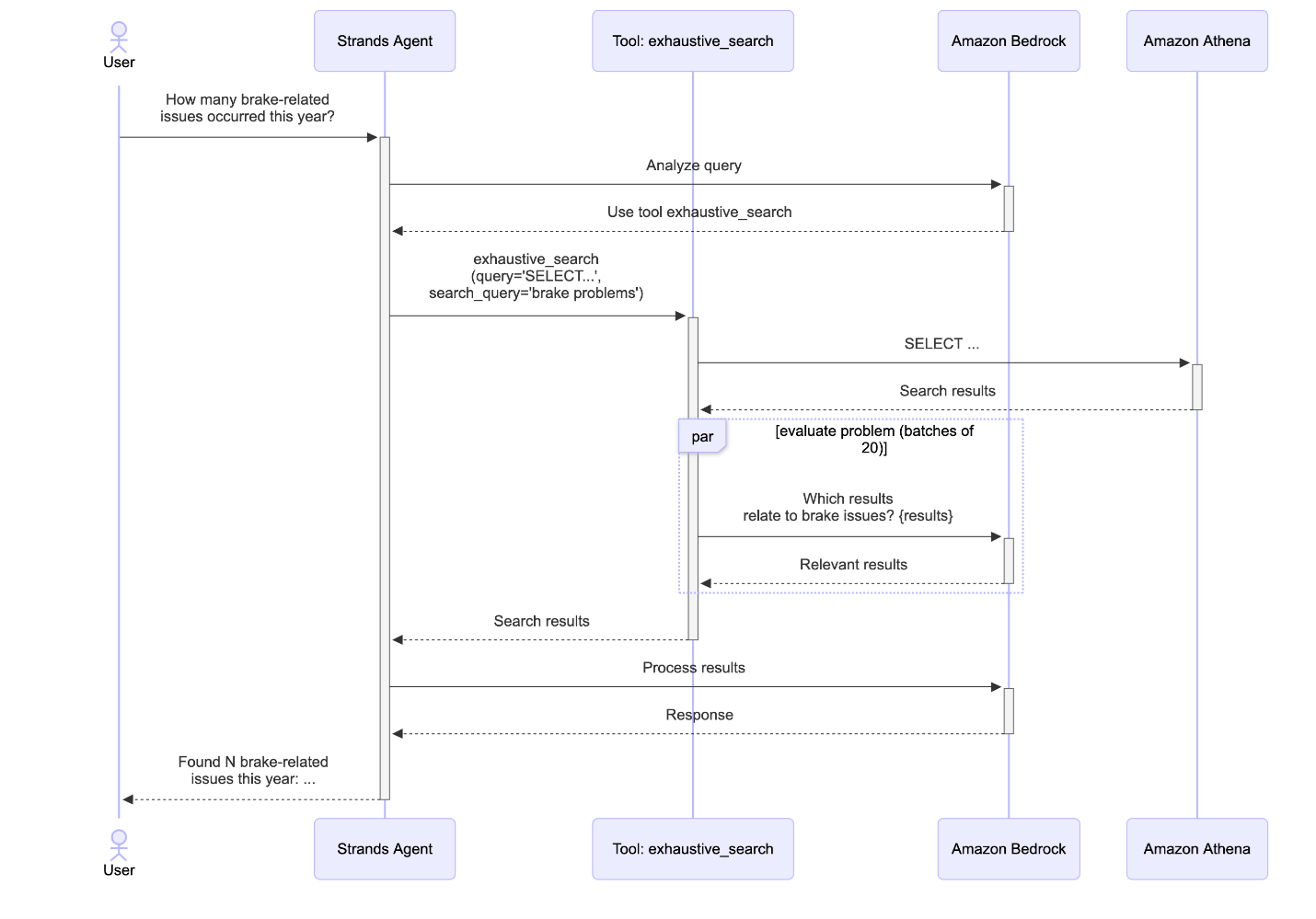
Figure 3. Exhaustive search sequence diagram
Key benefits and outcomes
Unified approach to structured and unstructured data
The combination of hybrid search, exhaustive search, and SQL query enables the solution to seamlessly handle both structured and unstructured data within a single conversational interface. Users can ask questions that require conceptual understanding (“find similar brake system feedback“), precise filtering (“count brake problems from last quarter“), or comprehensive analysis (“evaluate all safety-related incidents“) without switching tools or reformulating queries. The agent’s intelligent tool selection helps ensure that each query type is handled by the most appropriate method, delivering accurate results while maintaining a consistent, natural language user experience.
Cost-effective serverless architecture
Built entirely on serverless AWS services, the solution components scale to zero when not in use, compute resources are allocated on-demand, and you pay only for actual usage. Serverless architecture enables development of sophisticated AI-powered data analytics platforms without the operational overhead and fixed costs of traditional infrastructure.
Conclusion
This agentic search solution demonstrates how AWS’s generative AI Services can transform the way users interact with their data. By helping reduce traditional barriers between users and insights, this approach enables all users to generate data insights while maintaining the precision and scale required for enterprise applications. As organizations continue to generate increasing volumes of data, solutions like this become essential for unlocking the full value of enterprise data assets.
To learn more about building AI-powered data solutions on AWS, explore our generative AI resources.