AWS for Industries
Building an End-to-End Physical AI Data Pipeline for Autonomous Vehicle 3.0 on AWS with NVIDIA
Autonomous Vehicles (AV) development has been maturing and is advancing through clear architectural changes:
- AV 1.0: classical modular stacks (perception → prediction → planning → control) with hand-engineered interfaces
- AV 2.0: multi-modal LLM end-to-end (E2E) learned stacks that reduce modularity and improve scaling with data
- AV 3.0: end-to-end reasoning VLA (Vision–Language–Action) systems that perceive, reason, and act as a unified policy — grounded in real-world driving data and validated in closed-loop simulation
These new VLA models require vast quantities of real-world and synthetic sensor data — camera feeds, LiDAR point clouds, radar returns, and vehicle telemetry captured during actual driving. Collecting, curating, and validating this data is expensive, time-consuming, and safety critical.
In this post, we present a reference architecture for building an AV 3.0 data pipeline on AWS together with NVIDIA. It spans raw fleet sensor ingestion through AI-powered video curation, neural 3D scene reconstruction, reasoning VLA model training, and closed-loop simulation validation. The architecture uses a combination of open-source and commercial NVIDIA software: NVIDIA Cosmos foundation models, Cosmos Curator, Cosmos Dataset Search, Omniverse NuRec (Neural Reconstruction), and Alpamayo. These are running on managed AWS infrastructure, enabling customers to scale globally and focus engineering resources on innovation rather than infrastructure management.
Whether a customer is considering building a next-generation AV 3.0 data platform from scratch, or modernizing existing infrastructure, this architecture helps provide a reference for each stage of the development lifecycle — with a focus on what modern approaches need most: scalable and AI-enhanced data ingestion, retrieval-driven dataset assembly, and fast closed-loop validation.
Architecture overview
Developing AV 3.0 spans eight stages organized into four phases: Ingest, Data Processing, Train, and Validate.
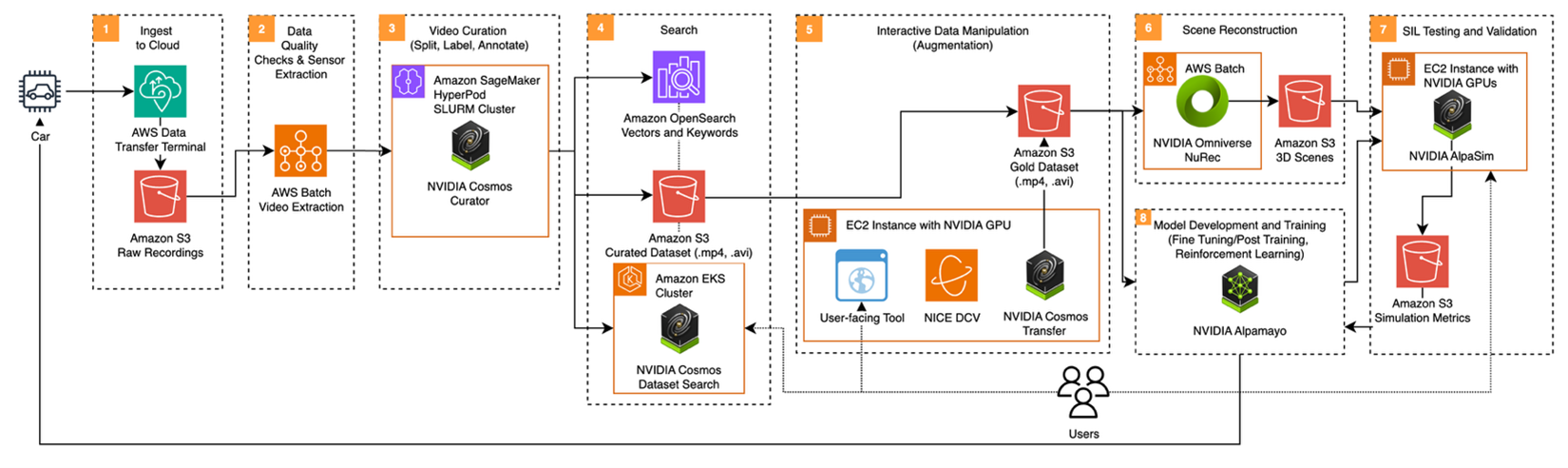 Figure 1: End-to-end Physical AI pipeline for AV 3.0 development on AWS with NVIDIA technologies.
Figure 1: End-to-end Physical AI pipeline for AV 3.0 development on AWS with NVIDIA technologies.
| Phase | Stages | What happens |
| Ingest | 1-2 | Raw sensor data moves from vehicles to the cloud and is quality-checked |
| Data Processing | 3-4-5 | Driving data is then curated, indexed, and augmented |
| Train | 5-6-8 | 3D scenes are reconstructed and the reasoning VLA model is trained |
| Validate | 6-7-8 | The AV Stack is validated using Neural Simulation |
The following sections walk through each stage.
Stage 1: Ingest to cloud
Recording units on each vehicle capture continuous sensor streams — cameras, LiDAR, radar, Inertial Measurement Unit (IMU), and Global Navigation Satellite System (GNSS) data — packaged into industry-standard container formats: ROS bags (.bag), MCAP (.mcap), or ASAM MDF4 (.mf4). Physical media is shipped to AWS Data Transfer Terminal, an AWS-managed facility with purpose-built hardware for the kind of sustained, high-volume transfer that fleet-scale AV development demands.
Raw recordings land in Amazon Simple Storage Service (Amazon S3), which is designed to provide the durability, scalability, and cost-effective storage needed for petabyte-scale sensor data. Amazon S3 Intelligent-Tiering, when configured, automatically moves older recordings to lower-cost storage classes as they age past the active extraction window.
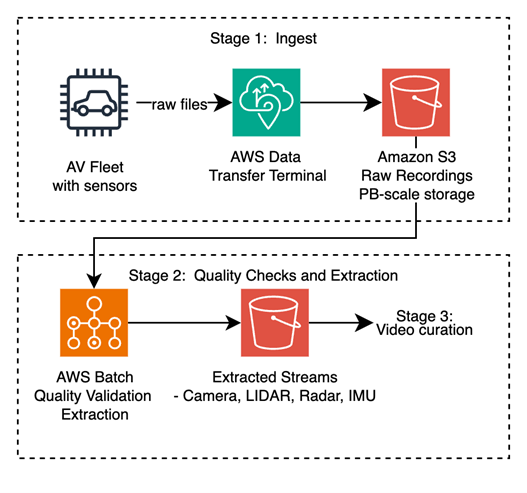 Figure 2: Vehicle sensor data ingestion flow — from fleet to Amazon S3.
Figure 2: Vehicle sensor data ingestion flow — from fleet to Amazon S3.
Stage 2: Data quality and sensor extraction
Before any AI processing can begin, raw recordings must pass a quality gate and be unpacked into individual sensor streams.
Quality validation: Each recording is an independent unit of work, making this stage well-suited to AWS Batch, orchestrating parallelized validation jobs. Customer-defined checks scan for missing sensor channels, timestamp desynchronization between sensor modalities (for example a radar recording at 10.2Hz versus a camera recording at 30.1Hz), or file corruption. Recordings that fail are quarantined with diagnostic metadata; valid recordings advance.
Sensor extraction: Validated drive log containers are decoded into individual modality streams to be further processed:
- Video (.mp4, .avi) — multiple camera perspectives per vehicle
- LiDAR point clouds (.laz) — 3D spatial measurements of the driving environment
- Radar returns (.pcd) — velocity-enriched detections, increasingly important with 4D imaging radar
- Telemetry (.csv, .parquet, .json) — Controller Area Network (CAN) bus signals, IMU measurements, GNSS positions, and calibrated ego poses
The extracted streams are stored in Amazon S3, ready for the data processing stages that follow.
Stage 3: Data curation
Raw driving video is continuous, unlabeled, and usually ordinary (highway cruising). AV 3.0 training demands scenario-dense, semantically indexed clips that can be discovered and reassembled into targeted datasets. This stage transforms raw footage into a curated, semantically enriched dataset using NVIDIA Cosmos foundation models.
Technology: NVIDIA Cosmos Curator running on Amazon SageMaker HyperPod with SLURM (Simple Linux Utility for Resource Management) scheduling. Cosmos Curator is an integrated data curation pipeline that orchestrates the four sub-stages below across a persistent GPU cluster.
Decoding and Splitting. Decodes the video frames from the raw mp4 bytes and the video is segmented into discrete clips using fixed stride based splitting algorithm.
Transcoding. Encodes each of the clips into individual mp4 files under the same encoding, e.g., H264.
Captioning. NVIDIA Cosmos Reason Vision-Language Model (VLM) analyzes each clip and generates dense, AV-specific text descriptions. Unlike generic video captioning, Cosmos Reason identifies safety-critical events, traffic violations, pedestrian conflicts, lane dynamics, and adverse weather conditions with the specificity that AV engineering demands. Cosmos Reason is also available on the AWS Marketplace.
Embedding. NVIDIA Cosmos Embed generates joint video-text embeddings for each clip, encoding both visual semantics and temporal dynamics — scene composition, motion patterns, lighting conditions, and object relationships — into searchable vector representations suited for retrieval, deduplication, and zero-shot classification.
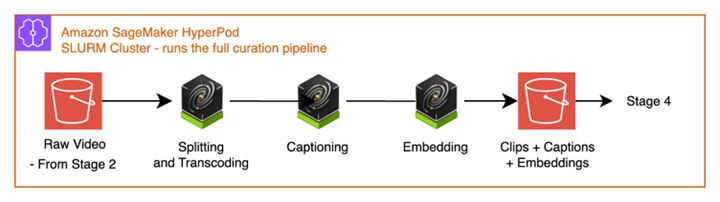
Figure 3: Cosmos Curator curation pipeline — split, caption, embed.
Output: A curated dataset in Amazon S3, with per-clip caption metadata (.json) and vector embeddings ready for indexing.
The vector embeddings generated by Cosmos Curator can be exported to external search indices (Stage 4), or consumed directly through NVIDIA Cosmos Dataset Search (CDS) — giving organizations flexibility to choose the integration path that fits their existing infrastructure.
Stage 4: Search and indexing
With thousands — or millions — of curated clips, engineers need to find specific driving scenarios quickly. AV 3.0 development is retrieval-driven: customers continuously mine, assemble, and refresh datasets that target the model’s observed weaknesses. This stage provides two complementary search paths.
Path A: Amazon OpenSearch Service with NVIDIA GPU acceleration
Embeddings and captions from Cosmos Curator are indexed into Amazon OpenSearch Service, accelerated by NVIDIA GPUs for high-throughput vector similarity search using NVIDIA cuVS. Amazon OpenSearch Service supports hybrid queries that combine natural-language text search (“Find all unprotected left turns in rain”) with vector similarity (“Find clips that look like this near-miss scenario”) — enabling the scenario-specific data mining that AV development requires.
This path suits organizations with existing search infrastructure, or teams who want to embed driving data discovery into broader data platforms and custom tooling.
Path B: NVIDIA Cosmos Dataset Search
NVIDIA Cosmos Dataset Search (CDS) runs on Amazon Elastic Kubernetes Service (Amazon EKS) and provides a production ready search experience built specifically for multi-modal driving data. It includes a visual User Interface (UI), embedding-aware search, dataset assembly workflows, and GPU-accelerated retrieval. It is an efficient path to scenario mining without building custom search infrastructure.
The vector embeddings as well as caption and metadata files generated by Cosmos Curator can be ingested directly into Cosmos Dataset Search. CDS uses metadata to enhance semantic search with both learned embeddings and high-quality ground-truth signals (captions, events, tags), enabling more accurate scenario mining.
This path suits teams who want a production-ready search experience with minimal integration effort, while retaining the freedom to only adopt the required components from CDS into their current search architecture rather than replacing it.
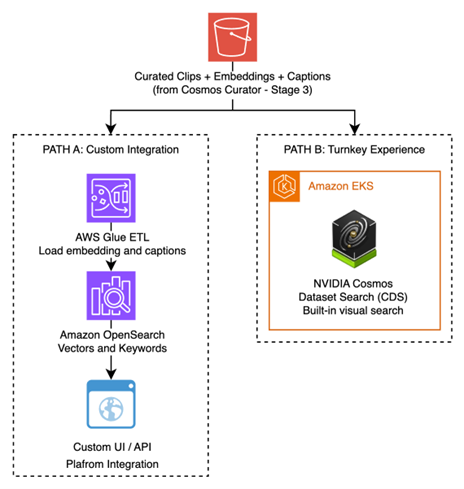
Figure 4: Two search paths — Amazon OpenSearch Service (custom integration) vs. NVIDIA Cosmos Dataset Search (turnkey).
Both paths serve the same downstream goal: enabling the engineering team to assemble targeted, high-quality datasets for reasoning VLA model training and simulation.
Stage 5: Data augmentation
First, engineers use a search tool to dig through data to find the driving scenarios that matter for their use-case (rainy weather, pedestrian crossings, unprotected left-turns). If the required scenes are too scarce, the engineers can create new test cases using Generative AI, leading to a high-quality, set of data. This customer-selected data can then be used for downstream machine learning workloads.
Technology: Amazon Elastic Compute Cloud (EC2) instances with NVIDIA GPUs, accessed through Amazon DCV for low-latency remote desktop streaming. To generate a new scene out of an existing hand-picked one, NVIDIA Cosmos Transfer requires approximately 65 GB of GPU memory — making Amazon EC2 G7e instances (powered by NVIDIA RTX PRO 6000 Blackwell Server Edition GPUs with 96 GB of GPU memory) a well-suited choice.
The workflow has three components:
Scenario discovery. Engineers access and query the search indices from Stage 4, browsing and filtering curated clips by scenario type, weather condition, traffic complexity, or visual similarity to assemble training candidates. This process can be carried out by using either the CDS UI or a UI specific to each customer, which incorporates pathways described in Stage 4.
Generative augmentation. Cosmos Transfer generates photorealistic synthetic variants of selected clips:
- Weather modification: sunny, rain, fog, snow, etc.
- Time-of-day transfer: sunrise, daytime, sunset, night, etc.
- Environmental changes: Urban, highway, desert, mountains, etc.
Cosmos Transfer preserves the geometric structure and semantic content of the original scene while producing physically plausible visual variations — generating realistic training data for conditions that are expensive or dangerous to capture on real roads.
Output: The Amazon S3 gold dataset — a curated and augmented collection of driving scenarios selected for training and validation. The augmented data will be directly used for model training (Stage 7), while the hand-picked data will feed both training and 3D scene reconstruction (Stage 6).
Stage 6: Neural Reconstruction
AV 3.0 depends heavily on camera inputs. That dependency makes high-fidelity sensor simulation essential: a synthetic environment that differs too much from reality will produce a distribution shift that breaks the model’s assumptions about the real world. Neural reconstruction closes that gap by converting real-world sensor recordings directly into photorealistic, drivable 3D scenes — environments the AV stack can test through.
Technology: AWS Batch running NVIDIA Omniverse NuRec (Neural Reconstruction) in GPU-accelerated containers.
Before reconstruction begins, multi-modal sensor input (calibrated multi-camera video, LiDAR point clouds, and ego-vehicle poses from the gold dataset) is processed into NCore, NVIDIA’s standard data ingestion format. NuRec takes this NCore data and reconstruct a Gaussian splat photorealistic 3D scene representation. The reconstruction captures static scene geometry (roads, buildings, vegetation, signage), scene appearance (lighting, textures, materials), and dynamic actors (vehicles, pedestrians) into independently controllable scene-graph elements. To handle these dynamic assets, NuRec relies on NVIDIA Asset Harvester. Asset Harvester is an AI model that recognizes and extracts specific objects directly from “in-the-wild” sensor recordings, leveraging generative AI to “fill in the blanks” for occluded or unseen portions to reconstruct them into 3D assets. NVIDIA Fixer, a single-step image diffusion model, can be used during the reconstruction loop to improve the output’s fidelity and the generalization of novel views.
Output: Reconstructed 3D scenes in OpenUSD format, stored in Amazon S3 and ready for import into the simulation environment. These are not hand-modeled approximations — they are photorealistic digital replicas of real driving encounters, enabling testing in environments derived from what was recorded on real roads.
Stage 7: Model training
With a curated gold dataset and reconstructed 3D scenes, the pipeline turns to the core challenge: training an AV 3.0 end-to-end reasoning VLA model.
Technology: NVIDIA Alpamayo is a reasoning Vision-Language-Action (VLA) foundation model for autonomous driving — a single neural network that perceives the driving scene through sensor inputs, reasons about it through language-grounded understanding, and outputs trajectory prediction. This advances beyond AV 1.0 modular stack by learning a unified policy and beyond AV 2.0 by emphasizing reasoning-grounded action.
The training workflow covers three phases:
- Fine-tuning: Adapt the pre-trained Alpamayo model to the target Operational Design Domain (ODD) using the gold dataset from Stage 5.
- Reinforcement learning: Use world model rollouts to optimize the driving policy through reward-based learning at scale.
- Optimization: Distillation and quantization prepare the model for edge deployment, reducing inference latency without significant accuracy loss.
Model development is iterative, each training cycle produces a candidate model that is evaluated in simulation (Stage 8). The resulting insights inform the next round of targeted data curation and retraining.
Stage 8: Software-in-the-loop testing
The final stage closes the loop. Before a model candidate can advance toward deployment, it must be rigorously validated in a closed-loop simulation environment, using the already reconstructed real-world scenarios to quantify safety and performance metrics.
Technology: Amazon EC2 instances with NVIDIA GPUs running NVIDIA AlpaSim. It’s an open-source, configurable and modular AV simulation framework that provides realistic high-fidelity neural sensor rendering, enabling scalable closed-loop testing. For production-scale validation across hundreds or thousands of scenarios, AlpaSim can be orchestrated on AWS Batch with multi-container jobs. NVIDIA AlpaSim Renderer is using NVIDIA Omniverse NuRec to generate novel views.
A typical simulation loop is orchestrated as follow:
- Scene loading: Reconstructed 3D scenes from Stage 6 are loaded into AlpaSim, which synthesizes photorealistic sensor feeds from viewpoints, as if a real sensor suite were driving through the scene.
- Model execution: The trained Alpamayo model from Stage 7 is deployed as the ego-vehicle controller. It receives synthesized sensor inputs and outputs driving commands in real time.
- Physics simulation: AlpaSim runs full physics — the ego vehicle moves through the reconstructed world, traffic agents respond, and the simulation evolves based on the model’s decisions. This is not data replay; it is interactive, branching simulation where the model’s actions change the outcome.
- Metrics collection: Performance is measured across simulated vehicle behavior (collision rate, off-road etc…), reliability metrics (mean-time between incidents, etc…) and higher-level metrics (e.g. lane-keeping) that can be developed on top.
Output: Structured simulation metrics stored in Amazon S3. These insights flow directly back into Stage 5 — if the model struggles with nighttime urban intersections, the team knows to curate more nighttime data, reconstruct more nighttime scenes, and fine-tune on those scenarios.
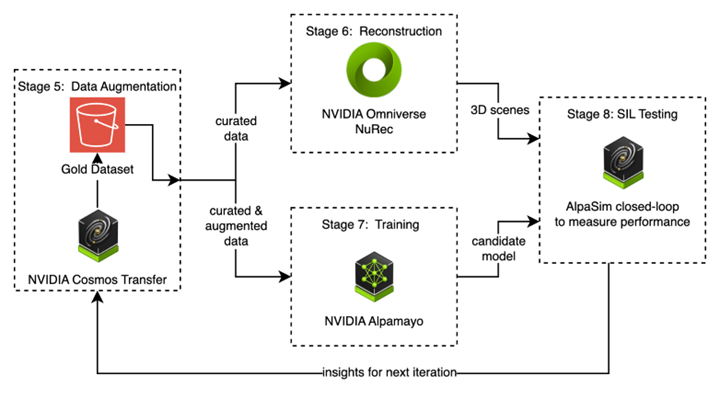
Figure 5: The data-driven iteration loop — curate → reconstruct → train → simulate → repeat.
Putting it all together: The data-driven iteration loop
The eight stages above are not a one-shot linear pipeline. The architecture’s power comes from the iterative feedback loop between Stages 5 through 8 — the mechanism that makes AV 3.0 development scale:
- Curate (Stage 5): Engineers select and augment targeted scenarios based on known model weaknesses
- Reconstruct (Stage 6): Augmented sensor data is converted to 3D simulation environments
- Train (Stage 7): The driving model is fine-tuned on targeted data
- Validate (Stage 8): The model is evaluated through reconstructed scenarios and is scored on performance
- Repeat: Simulation insights reveal failure modes and guide the next curation cycle
This loop accelerates development by enabling rapid hypothesis testing — for example, “Will the model handle rain better if we augment training data with Cosmos Transfer and retrain?” — a question that can be answered in hours rather than weeks of real-world data collection.
This inner loop is part of a larger cycle: once the model is deployed to the vehicle fleet, it generates new real-world data — but at a much smaller volume. The most challenging long-tail scenarios encountered on the road feed back into Stage 1, triggering a new iteration with a far smaller and more targeted dataset than the original. Each deployment cycle requires less raw data while targeting increasingly rare failure modes.
Getting started
The AWS and NVIDIA technologies described in this architecture are available today:
| Component | Where to get it |
| NVIDIA Cosmos Curator | GitHub (open source) |
| NVIDIA Cosmos Reason NIM | AWS Marketplace |
| NVIDIA Cosmos Transfer | Hugging Face (NVIDIA Open Model) |
| NVIDIA Cosmos Dataset Search | NVIDIA AI Enterprise on AWS |
| NVIDIA NCore | GitHub (Apache 2.0) |
| NVIDIA Omniverse NuRec | NVIDIA NGC |
| NVIDIA AlpaSim | GitHub (Apache 2.0) |
| NVIDIA Alpamayo | GitHub (open source) |
| NVIDIA Fixer | Hugging Face (NVIDIA Open Model) |
| NVIDIA Asset Harvester | Hugging Face (NVIDIA Open Model) |
| Amazon SageMaker HyperPod | Amazon SageMaker HyperPod |
| Amazon OpenSearch Service | Amazon OpenSearch Service |
| Amazon EC2 G7e instances | Amazon EC2 G7e |
| AWS Batch | AWS Batch |
For a deeper look at deploying Cosmos foundation models on AWS, see Running NVIDIA Cosmos world foundation models on AWS.
Conclusion
AV 3.0 — end-to-end reasoning VLA — is fundamentally a data and iteration problem. A customer would generally need the ability to (1) ingest fleet-scale multi-modal sensor data, (2) curate and retrieve scenario-targeted datasets, (3) generate coverage through physically plausible augmentation, (4) reconstruct real scenes into drivable 3D environments, and (5) validate candidates in closed-loop simulation running on AWS — quickly, repeatedly, and at scale.
By using AWS managed services — Amazon S3 for storage, AWS Batch for extraction, Amazon SageMaker HyperPod for GPU-accelerated AI workloads, AWS Batch and Amazon EKS for containerized applications, Amazon OpenSearch Service for semantic search, and Amazon EC2 with Amazon DCV for interactive workflows — with NVIDIA’s AV technologies — Cosmos Curator, Cosmos Dataset Search, Omniverse NuRec, and Alpamayo — a customer could build an end-to-end pipeline from raw fleet data to a validated driving model.
The architecture is modular: each stage can be adopted independently and integrated with existing systems. Start with ingestion and curation to unlock the value in a customer’s existing driving data, then progressively add search, augmentation, reconstruction, and simulation as the customer built program matures.
To learn more about autonomous vehicle development on AWS, visit the AWS Automotive page. To explore NVIDIA’s physical AI platform, visit NVIDIA Alpamayo.