AWS for Industries
How Everllence Scaled P&ID Intelligence to Improve Plant Operations
When industrial equipment fails, engineers need fast access to the process knowledge locked in Piping and Instrumentations Diagrams (P&IDs), and AI agents can help. Unplanned downtime is a costly challenge in industrial operations. Much of the process knowledge needed to diagnose and resolve issues is encoded in P&IDs, which document equipment specifications, process flows, and safety system relationships. Yet P&IDs remain locked in static PDF formats that are difficult for AI systems to interpret and slow for engineers to navigate under pressure.
This blog post explores how Everllence, working with the AWS Generative AI Innovation Center, developed a solution that transforms P&IDs into intelligent knowledge graphs, enabling AI-powered troubleshooting that reduces the time engineers spend searching through P&ID documentation.
The Industrial P&ID Challenge
P&IDs document everything from equipment specifications to process flows and safety systems. The scale and complexity of these diagrams vary. A single component like an engine might require eight pages of P&IDs, while an entire plant may span up to 100 pages, with each page containing highly dense information that translates into thousands of interconnected components. For example, an eight-page engine P&ID can contain 2,000 nodes with 7,500 relationships. Engineers rely on these diagrams daily for troubleshooting, maintenance planning, and operational decisions. However, several challenges have limited their effectiveness in the age of AI.
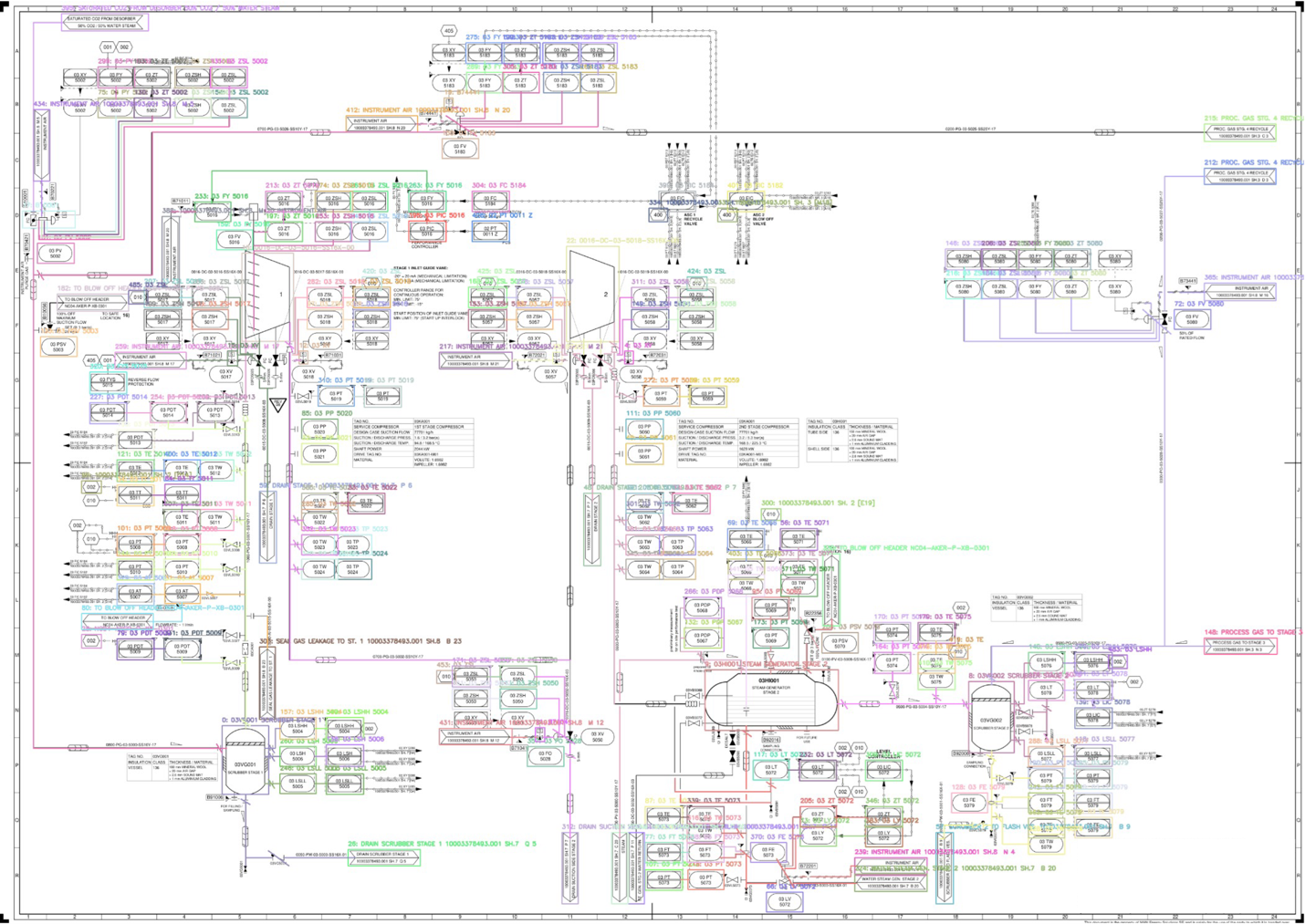
Figure 1: Example of an annotated Piping and Instrumentation Diagram (P&ID)
Different stakeholders have varying needs when consulting P&IDs. A maintenance engineer might need to trace a specific valve connection, while a process engineer seeks to understand flow patterns across multiple systems. Operations teams require quick answers during troubleshooting scenarios, where every hour of downtime carries significant cost.
The documents that hold the answers remain difficult for both humans and machines to search efficiently. Making this technical knowledge accessible to Large Language Models (LLMs) is a natural next step but comes with its own challenges. While the context window of LLMs have expanded significantly, research shows that performance degrades as context length increases, particularly when relevant information is embedded within large documents (Liu et al., 2024). More critically, LLMs lack inherent understanding of industrial processes and equipment relationships. The challenge was clear: how do we equip AI agents with the ability to retrieve process knowledge to meaningfully support engineers in their daily work?
Solution Overview
Everllence developed CEON TechBot, a specialized AI engine for technical troubleshooting powered by engine documentation and machine telemetry. The solution enabled faster access to answers across many technical documents and connected site data. As the solution evolved, it became clear that incorporating digitized P&IDs would further enhance the system’s capabilities, enabling more comprehensive troubleshooting for complex industrial processes. This led to the exploratory project to transform static diagrams into knowledge graphs, enabling AI agents to effectively query and reason about equipment relationships and process flows.
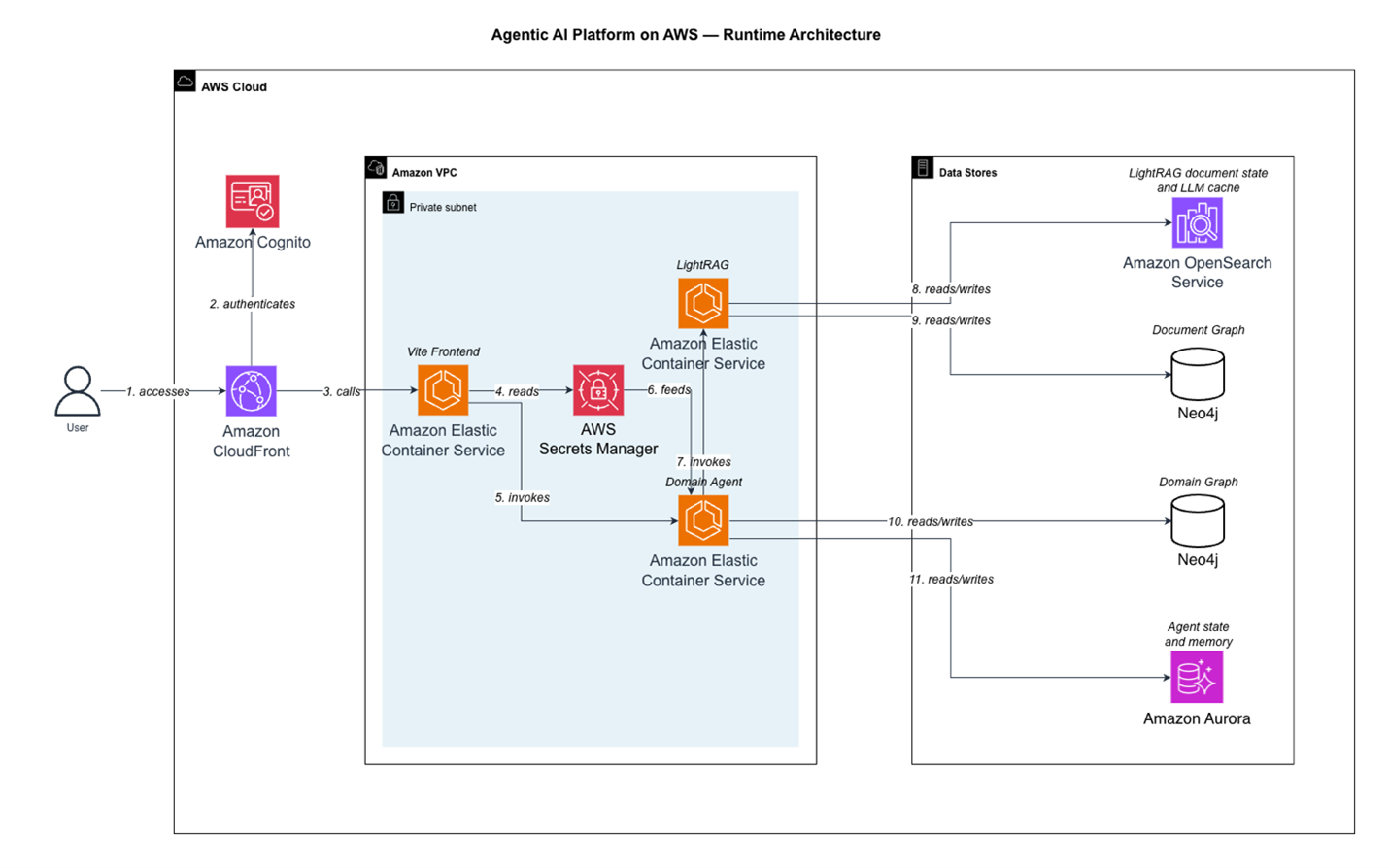
Figure 2: High-level Agentic AI platform on AWS runtime architecture
The frontend is deployed on Amazon CloudFront with Amazon Cognito authentication, providing secure access to the system. All P&ID data is encrypted at rest and in transit, with role-based access controls ensuring users only see authorized facility information. The processing layer uses Amazon Elastic Container Service (ECS) with separate containers for the front-end, domain agent, and LightRAG components. At the heart of the solution is Neo4j, which stores the P&ID knowledge graph and enables traversal of equipment relationships and process flows. Amazon Aurora Serverless PostgreSQL handles structured metadata such as user sessions, query logs, and system configuration, while Amazon OpenSearch Serverless powers full-text search across technical documentation and supports the LightRAG retrieval layer.
AWS Solution Architecture
Throughout the P&ID digitization and query process, the system leverages multiple AWS services to ensure scalability, reliability, and performance. The architecture follows principles of full separation between storage and compute, enabling independent scaling and improved reliability. Least privilege access control is implemented between all components, ensuring security at every layer.
Let’s examine the data flow through the system:
P&ID Ingestion and Processing: The process begins when industrial P&ID documents are uploaded to the system. The hybrid digitization approach uses template matching for symbol detection, achieving high precision by sliding templates over the diagram and computing similarity scores. Text and line extraction occurs directly from native PDF files, preserving accuracy and detail.
Graph Construction: Extracted content is transformed into a graph representation, with nodes created for equipment, instruments, and connections. For a typical industrial site, this process generates thousands of nodes and relationships, one implementation created 1,909 nodes and 7,525 relationships from a single site in 1 hour.
Graph Enrichment: The raw graph undergoes enrichment through multiple processes. Naming conventions are unified using regex patterns, metadata from instrumentation lists is integrated, and a hierarchical service assignment structure is implemented. This three-level hierarchy organizes information from high-level systems, such as compression and auxiliary systems, down to detailed component descriptions.
LightRAG Integration: To complement the structured graph data, the system integrates LightRAG, a retrieval framework that combines low-level and high-level retrieval to pull precise answers from unstructured documentation when the knowledge graph alone does not contain enough context.
ReAct Agent System: When users submit queries, a specialized ReAct (Reasoning and Acting) agent processes the request. The agent uses LangGraph for orchestration and has access to multiple tools: predefined graph query tools for common patterns, a “Swiss Army knife” tool for executing custom Cypher queries with guardrails, and the LightRAG document retrieval tool.
For each query, the ReAct agent follows a systematic reasoning process:
- Analyze Query: Understand what the user is asking about the P&ID
- Plan Approach: Determine which tools and queries are needed:
- Can the question be answered based solely on documentation?
- If not, which components of equipment would yield information? E.g. compressor stage 1
- Find the right component and navigate the knowledge graph from there
- Execute Tools: Call Neo4j graph queries in sequence
- Observe Results: Process the returned data
- Reason Further: Decide if additional information is needed
- Synthesize Answer: Combine results into a comprehensive response
This agent-driven approach ensures that queries are answered with both precision and context, drawing from the structured knowledge graph and supporting documentation.
Key Learnings
The CEON TechBot solution evolved through careful experimentation and refinement. Four factors emerged as critical for success.
Hybrid Approach to P&ID Digitization
In industrial operations, P&IDs serve as the single source of truth for process plants, meaning anything less than 100% digitization accuracy is unacceptable. Image-only processing approaches cannot guarantee this level of precision. By combining direct text and line extraction from native PDFs with template matching for symbol detection, the system captures most diagram content automatically. Everllence closes the remaining gap through a specialized review tool that enables human experts to validate, correct, and complete the digitized output, ensuring the knowledge graph faithfully represents the original P&ID documentation.
Systematic Graph Engineering
Extracting components from P&IDs is only the starting point. The graph must be enriched with metadata, unified naming conventions, and hierarchical organization. A three-level service assignment hierarchy allows queries to operate at different levels of abstraction depending on user needs, while cross-page connectivity restoration links systems that span multiple diagram sheets.
Specialized Agent Architecture
Rather than relying on general-purpose AI assistants, the ReAct agent is equipped with domain-specific tools and guardrails. A flexible Cypher query tool handles ad hoc graph queries with built-in validation, while the combination of graph queries and document retrieval ensures answers draw from both structured and unstructured knowledge.
Scalable AWS Infrastructure
The architecture separates storage and compute for independent scaling. Amazon ECS handles container orchestration, Amazon Aurora Serverless adjusts database capacity on demand, and Amazon CloudFront ensures fast global content delivery. Amazon CloudWatch provides real-time monitoring and automated alerts across all components. The solution deploys across multiple Availability Zones with automated failover, enabling growth from pilot implementations to enterprise-wide deployments.
Future Direction
The transformation of P&IDs into AI-accessible knowledge graphs has moved from concept to working prototype, with engineers now able to ask natural language questions about complex systems and receive contextualized answers significantly faster than through manual diagram searches. The system handles queries ranging from simple equipment lookups to complex process flow analysis and has generated interest across the process industry.
Looking ahead, the near-term roadmap focuses on expanding P&ID coverage to additional plant sections, onboarding more engineering teams, and refining the AI agent’s query accuracy based on real-world usage feedback. As the solution matures, Everllence and AWS will evaluate opportunities to integrate additional data sources that complement the existing knowledge graph.
Conclusion
The CEON TechBot solution demonstrates how AI agents and knowledge graphs can make the critical process knowledge locked in P&IDs searchable, queryable, and actionable. By leveraging AWS services, Everllence built a scalable platform that significantly reduces the time engineers spend searching P&ID documentation. As the solution moves from prototype to production, Everllence will continue measuring and reporting on concrete operational impact. The combination of hybrid P&ID digitization, systematic graph engineering, specialized agent architecture, and cloud-native infrastructure provides a replicable foundation for the process industry.
If your organization relies on P&IDs for daily operations and wants to make that documentation accessible to AI-powered troubleshooting, this approach can serve as a practical starting point. Reach out to your AWS account representative to explore how knowledge graph technology can transform your P&ID documentation into a queryable, intelligent asset.