Artificial Intelligence

Author: Aman Shanbhag
Aman Shanbhag is an Associate Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services, where he helps customers and partners with deploying ML Training and Inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in Computer Science, Mathematics, and Entrepreneurship.
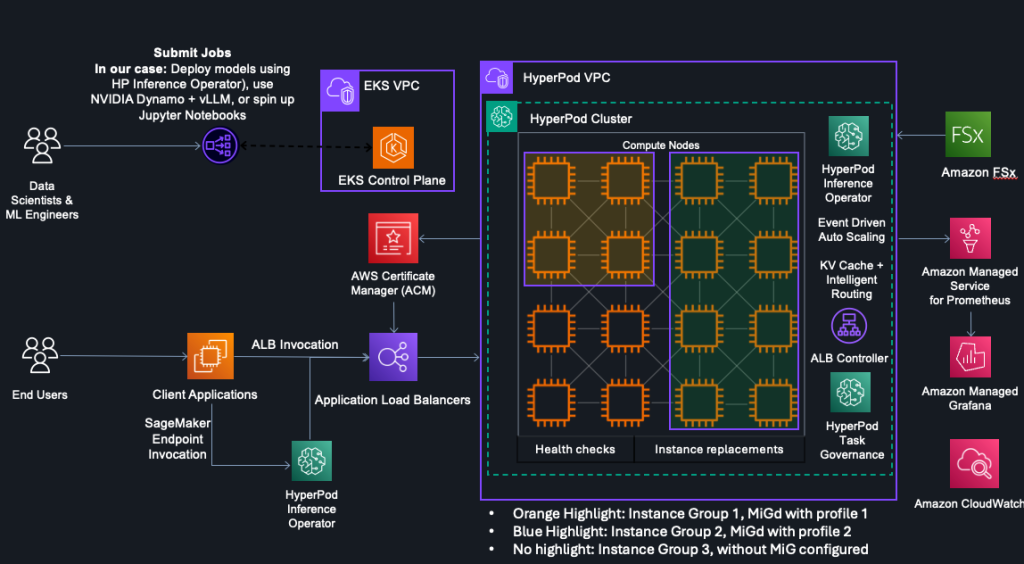
HyperPod now supports Multi-Instance GPU to maximize GPU utilization for generative AI tasks
In this post, we explore how Amazon SageMaker HyperPod now supports NVIDIA Multi-Instance GPU (MIG) technology, enabling you to partition powerful GPUs into multiple isolated instances for running concurrent workloads like inference, research, and interactive development. By maximizing GPU utilization and reducing wasted resources, MIG helps organizations optimize costs while maintaining performance isolation and predictable quality of service across diverse machine learning tasks.

From fridge to table: Use Amazon Rekognition and Amazon Bedrock to generate recipes and combat food waste
In this post, we walk through how to build the FoodSavr solution (fictitious name used for the purposes of this post) using Amazon Rekognition Custom Labels to detect the ingredients and generate personalized recipes using Anthropic’s Claude 3.0 on Amazon Bedrock. We demonstrate an end-to-end architecture where a user can upload an image of their fridge, and using the ingredients found there (detected by Amazon Rekognition), the solution will give them a list of recipes (generated by Amazon Bedrock). The architecture also recognizes missing ingredients and provides the user with a list of nearby grocery stores.

Speed up your cluster procurement time with Amazon SageMaker HyperPod training plans
In this post, we explore how Amazon SageMaker HyperPod training plans accelerate compute resource procurement for machine learning workloads. We guide you through a step-by-step implementation on how you can use the AWS CLI or the AWS Management Console to find, review, and create optimal training plans for your specific compute and timeline needs. We further guide you through using the training plan to submit SageMaker training jobs or create SageMaker HyperPod clusters.

Accelerating Mixtral MoE fine-tuning on Amazon SageMaker with QLoRA
In this post, we demonstrate how you can address the challenges of model customization being complex, time-consuming, and often expensive by using fully managed environment with Amazon SageMaker Training jobs to fine-tune the Mixtral 8x7B model using PyTorch Fully Sharded Data Parallel (FSDP) and Quantized Low Rank Adaptation (QLoRA).