Artificial Intelligence
Category: Case Study

Part 3: How NatWest Group built auditable, reproducible, and explainable ML models with Amazon SageMaker
This is the third post of a four-part series detailing how NatWest Group, a major financial services institution, partnered with AWS Professional Services to build a new machine learning operations (MLOps) platform. This post is intended for data scientists, MLOps engineers, and data engineers who are interested in building ML pipeline templates with Amazon SageMaker. […]

Part 2: How NatWest Group built a secure, compliant, self-service MLOps platform using AWS Service Catalog and Amazon SageMaker
This is the second post of a four-part series detailing how NatWest Group, a major financial services institution, partnered with AWS Professional Services to build a new machine learning operations (MLOps) platform. In this post, we share how the NatWest Group utilized AWS to enable the self-service deployment of their standardized, secure, and compliant MLOps […]

Part 1: How NatWest Group built a scalable, secure, and sustainable MLOps platform
This is the first post of a four-part series detailing how NatWest Group, a major financial services institution, partnered with AWS to build a scalable, secure, and sustainable machine learning operations (MLOps) platform. This initial post provides an overview of the AWS and NatWest Group joint team implemented Amazon SageMaker Studio as the standard for […]

Predict residential real estate prices at ImmoScout24 with Amazon SageMaker
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]

Bundesliga Match Fact Set Piece Threat: Evaluating team performance in set pieces on AWS
The importance of set pieces in football (or soccer in the US) has been on the rise in recent years: now more than one quarter of all goals are scored via set pieces. Free kicks and corners generally create the most promising situations, and some professional teams have even hired specific coaches for those parts […]

Bundesliga Match Fact Skill: Quantifying football player qualities using machine learning on AWS
In football, as in many sports, discussions about individual players have always been part of the fun. “Who is the best scorer?” or “Who is the king of defenders?” are questions perennially debated by fans, and social media amplifies this debate. Just consider that Erling Haaland, Robert Lewandowski, and Thomas Müller alone have a combined […]

How Kustomer utilizes custom Docker images & Amazon SageMaker to build a text classification pipeline
This is a guest post by Kustomer’s Senior Software & Machine Learning Engineer, Ian Lantzy, and AWS team Umesh Kalaspurkar, Prasad Shetty, and Jonathan Greifenberger. In Kustomer’s own words, “Kustomer is the omnichannel SaaS CRM platform reimagining enterprise customer service to deliver standout experiences. Built with intelligent automation, we scale to meet the needs of […]
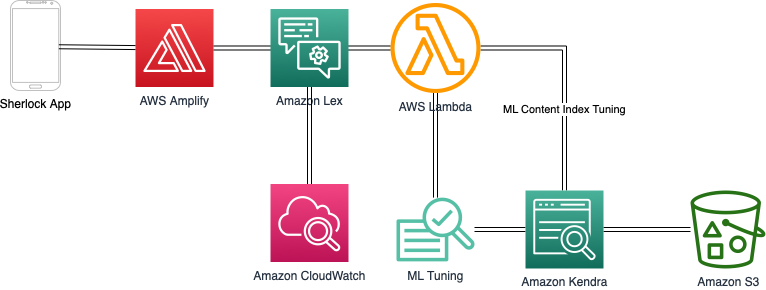
How InpharmD uses Amazon Kendra and Amazon Lex to drive evidence-based patient care
The intersection of DI and AI: Drug information refers to the discovery, use, and management of healthcare and medical information. Healthcare providers have many challenges associated with drug information discovery, such as intensive time involvement, lack of accessibility, and accuracy of reliable data. The average clinical query requires a literature search that takes an average of 18.5 hours. In addition, drug information often lies in disparate information silos, behind pay walls and design walls, and quickly becomes stale.

How SIGNAL IDUNA operationalizes machine learning projects on AWS
This post is co-authored with Jan Paul Assendorp, Thomas Lietzow, Christopher Masch, Alexander Meinert, Dr. Lars Palzer, Jan Schillemans of SIGNAL IDUNA. At SIGNAL IDUNA, a large German insurer, we are currently reinventing ourselves with our transformation program VISION2023 to become even more customer oriented. Two aspects are central to this transformation: the reorganization of […]

How Süddeutsche Zeitung optimized their audio narration process with Amazon Polly
This is a guest post by Jakob Kohl, a Software Developer at the Süddeutsche Zeitung. Süddeutsche Zeitung is one of the leading quality dailies in Germany when it comes to paid subscriptions and unique users. Its website, SZ.de, reaches more than 15 million monthly unique users as of October 2021. Thanks to smart speakers and […]