Artificial Intelligence
Part 3: How NatWest Group built auditable, reproducible, and explainable ML models with Amazon SageMaker
This is the third post of a four-part series detailing how NatWest Group, a major financial services institution, partnered with AWS Professional Services to build a new machine learning operations (MLOps) platform. This post is intended for data scientists, MLOps engineers, and data engineers who are interested in building ML pipeline templates with Amazon SageMaker. We explain how NatWest Group used SageMaker to create standardized end-to-end MLOps processes. This solution reduced the time-to-value for ML solutions from 12 months to less than 3 months, and reduced costs while maintaining NatWest Group’s high security and auditability requirements.
NatWest Group chose to collaborate with AWS Professional Services given their expertise in building secure and scalable technology platforms. The joint team worked to produce a sustainable long-term solution that supports NatWest’s purpose of helping families, people, and businesses thrive by offering the best financial products and services. We aim to do this while using AWS managed architectures to minimize compute and reduce carbon emissions.
Read the entire series:
|
SageMaker project templates
One of the exciting aspects of using ML to answer business challenges is that there are many ways to build a solution that include not only the ML code itself, but also connecting to data, preprocessing, postprocessing, performing data quality checks, and monitoring, to name a few. However, this flexibility can create its own challenges for enterprises aiming to scale the deployment of ML-based solutions. It can lead to a lack of consistency, standardization, and reusability that limits the time to create new business propositions. This is where the concept of a template for your ML code comes in. It allows you to define a standard way to develop an ML pipeline that you can reuse across multiple projects, teams, and use cases, while still allowing the flexibility needed for key components. This makes the solutions we build more consistent, robust, and easier to test. This also makes development go much faster.
Through a recent collaboration between NatWest Group and AWS, we developed a set of SageMaker project templates that embody all the standard processes and steps that form part of a robust ML pipeline. These are used within the data science platform built on infrastructure templates that were described in Part 2 of this series.
The following figure shows the architecture of our training pipeline template.
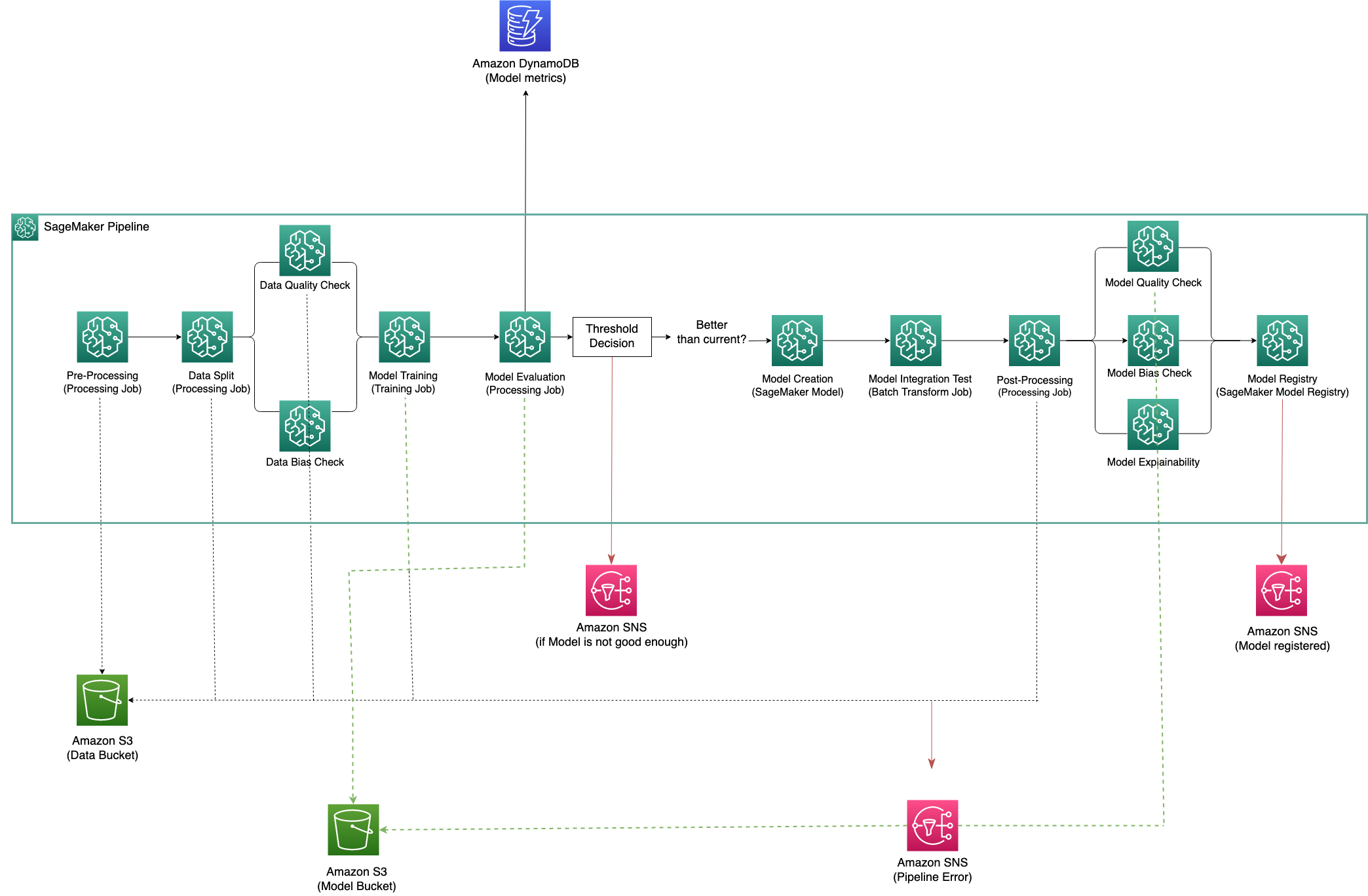
The following screenshot shows what is displayed in Amazon SageMaker Studio when this pipeline is successfully run.

All of this helps improve our ML development practices in multiple ways, which we discuss in the following sections.
Reusable
ML projects at NatWest often require cross-disciplinary teams of data scientists and engineers to collaborate on the same project. This means that shareability and reproducibility of code, models, and pipelines are two important features teams should be able to rely on.
To meet this requirement, the team set up Amazon SageMaker Pipelines templates for training and inference as dual starting points for new ML projects. The templates are deployed by the data science team via a single click into new development accounts via AWS Service Catalog as SageMaker projects. These AWS Service Catalog products are managed and developed by a central platform team so that best practice updates are propagated across all business units, but consuming teams can contribute their own developments to the common codebase.
To achieve easy replication of templates, NatWest utilized AWS Systems Manager Parameter Store. The parameters were referenced in the generic templates, where we followed a naming convention in which each project’s set of parameters uses the same prefix. This means templates can be started up quickly and still access all necessary platform resources, without users needing to spend time configuring them. This works because AWS Service Catalog replaces any parameters in the use case accounts with the correct value.
Not only do these templates enable a much quicker startup of new projects, but they also provide more standardized model development practices in teams aligned to different business areas. This means that model developers across the organization can more easily understand code written by other teams, facilitating collaboration, knowledge sharing, and easier auditing.
Efficient
The template approach encouraged model developers to write modular and decoupled pipelines, allowing them to take advantage of the flexibility of SageMaker managed instances. Decoupled steps in an ML pipeline mean that smaller instances can be used where possible to save costs, so larger instances are only used when needed (for example, for larger data preprocessing workloads).
SageMaker Pipelines also offers a step-caching capability. Caching means that steps that were already successfully run aren’t rerun in case of a failed pipeline—the pipeline skips those, reuses their cached outputs, and starts only from the failed step. This approach means that the organization is only charged for the higher-cost instances for a minimal amount of time, which also aligns ML workloads with NatWest’s climate goal to reduce carbon emissions.
Finally, we used SageMaker integration with Amazon EventBridge and Amazon Simple Notification Service (Amazon SNS) for custom email notifications on key pipeline updates to ensure that data scientists and engineers are kept up to date with the status of their development.
Auditable
The template ML pipelines contain steps that generate artifacts, including source code, serialized model objects, scalers used to transform data during preprocessing, and transformed data. We use the Amazon Simple Storage service (Amazon S3) versioning feature to securely keep multiple variants of objects like these in the same bucket. This means objects that are deleted or overwritten can be restored. All versions are available, so we can keep track of all the objects generated in each run of the pipeline. When an object is deleted, instead of removing it permanently, Amazon S3 inserts a delete marker, which becomes the current object version. If an object is overwritten, it results in a new object version in the bucket. If necessary, it can be restored to the previous version. The versioning feature provides a transparent view for any governance process, so the artifacts generated are always auditable.
To properly audit and trust our ML models, we need to keep a record of the experiments we ran during development. SageMaker allows for metrics to be automatically collected by a training job and displayed in SageMaker experiments and the model registry. This service is also integrated with the SageMaker Studio UI, providing a visual interface to browse active and past experiments, visually compare trials on key performance metrics, and identify the best performing models.
Secure
Due to the unique requirements of NatWest Group and the financial services industry, with an emphasis on security in a banking context, the ML templates we created required additional features compared to standard SageMaker pipeline templates. For example, container images used for processing and training jobs need to download approved packages from AWS CodeArtifact because they can’t do so from the internet directly. The templates need to work with a multi-account deployment model, which allows secure testing in a production-like environment.
SageMaker Model Monitor and SageMaker Clarify
A core part of NatWest’s vision is to help our customers thrive, which we can only do if we’re making decisions in a fair, equitable, and transparent manner. For ML models, this leads directly to the requirement for model explainability, bias reporting, and performance monitoring. This means that the business can track and understand how and why models make specific decisions.
Given the lack of standardization across teams, no consistent model monitoring capabilities were in place, leading to teams creating a lot of bespoke solutions. Two vital components of the new SageMaker project templates were bias detection on the training data and monitoring the trained model. Amazon SageMaker Model Monitor and Amazon SageMaker Clarify suit these purposes, and both operate in a scalable and repeatable manner.
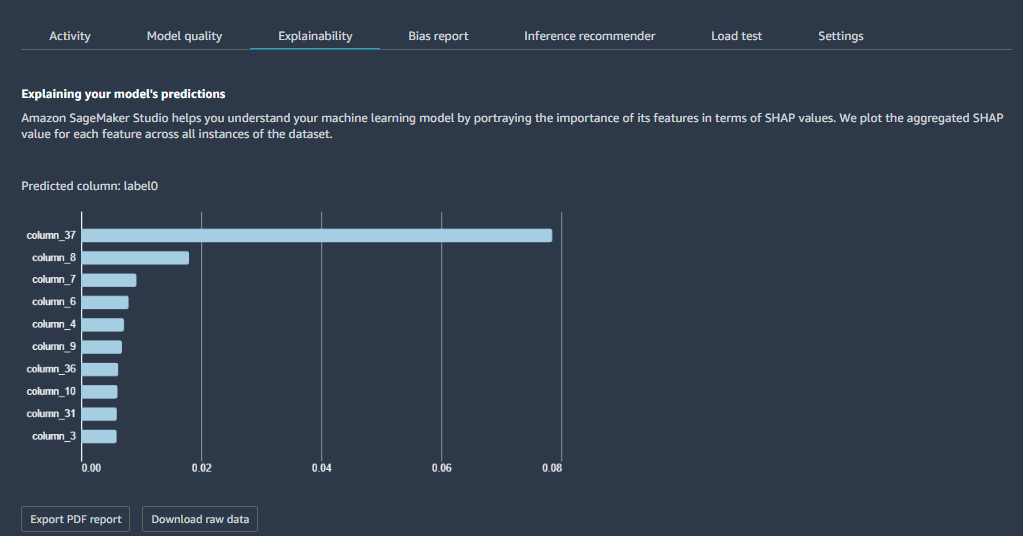
Model Monitor continuously monitors the quality of SageMaker ML models in production against predefined baseline metrics. Clarify offers bias checks on training data based on the Deequ open-source library. After the model is trained, Clarify offers model bias and explainability checks using various metrics, such as Shapley values. The following screenshot shows an explainability report viewed in SageMaker Studio and produced by Clarify.
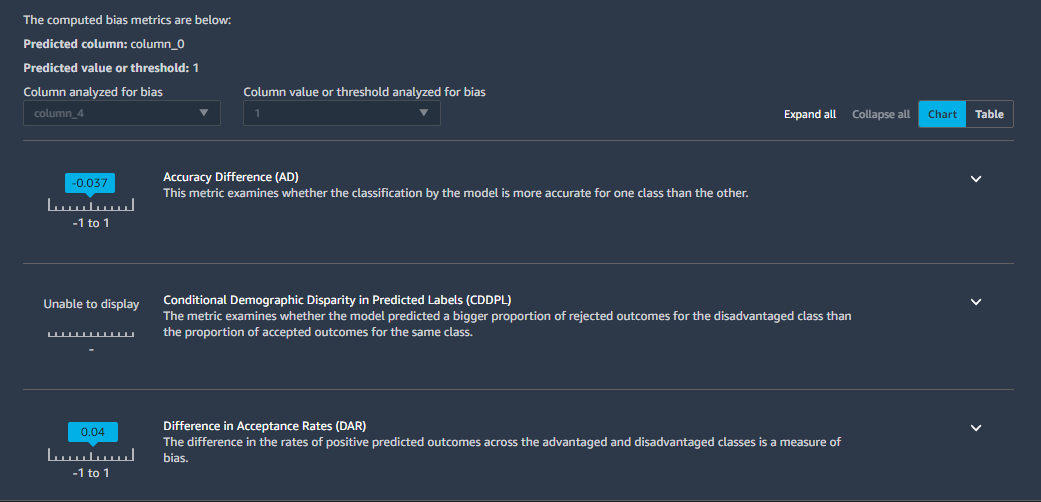
The following screenshot shows a similarly produced example model bias report.
Conclusion
NatWest’s ML templates align our MLOps solution to our need for auditable, reusable, and explainable MLOps assets across the organization. With this blueprint for instantiating ML pipelines in a standardized manner using SageMaker features, data science and engineering teams at NatWest feel empowered to operate and collaborate with best practices, with the control and visibility needed to manage their ML workloads effectively.
In addition to the quick-start ML templates and account infrastructure, several existing NatWest ML use cases were developed using these capabilities. The development of these use cases informed the requirements and direction of the overall collaboration. This meant that the project templates we set up are highly relevant for the organization’s business needs.
This is the third post of a four-part series on the strategic collaboration between NatWest Group and AWS Professional Services. Check out the rest of the series for the following topics:
- Part 1 explains how NatWest Group partnered with AWS Professional Services to build a scalable, secure, and sustainable MLOps platform
- Part 2 describes how NatWest Group used AWS Service Catalog and SageMaker to deploy their compliant and self-service MLOps platform
- Part 4 details how NatWest data science teams migrate their existing models to SageMaker architectures
About the Authors
 Ariadna Blanca Romero is a Data Scientist/ML Engineer at NatWest with a background in computational material science. She is passionate about creating tools for automation that take advantage of the reproducibility of results from models and optimize the process to ensure prompt decision-making to deliver the best customer experience. Ariadna volunteers as a STEM virtual mentor for a non-profit organization helping the professional development of Latin-American students and young professionals, particularly for empowering women. She has a passion for practicing yoga, cooking, and playing her electric guitar.
Ariadna Blanca Romero is a Data Scientist/ML Engineer at NatWest with a background in computational material science. She is passionate about creating tools for automation that take advantage of the reproducibility of results from models and optimize the process to ensure prompt decision-making to deliver the best customer experience. Ariadna volunteers as a STEM virtual mentor for a non-profit organization helping the professional development of Latin-American students and young professionals, particularly for empowering women. She has a passion for practicing yoga, cooking, and playing her electric guitar.
 Lucy Thomas is a data engineer at NatWest Group, working in the Data Science and Innovation team on ML solutions used by data science teams across NatWest. Her background is in physics, with a master’s degree from Lancaster University. In her spare time, Lucy enjoys bouldering, board games, and spending time with family and friends.
Lucy Thomas is a data engineer at NatWest Group, working in the Data Science and Innovation team on ML solutions used by data science teams across NatWest. Her background is in physics, with a master’s degree from Lancaster University. In her spare time, Lucy enjoys bouldering, board games, and spending time with family and friends.
 Sarah Bourial is a Data Scientist at AWS Professional Services. She is passionate about MLOps and supports global customers in the financial services industry in building optimized AI/ML solutions to accelerate their cloud journey. Prior to AWS, Sarah worked as a Data Science consultant for various customers, always looking to achieve impactful business outcomes. Outside work, you will find her wandering around art galleries in exotic destinations.
Sarah Bourial is a Data Scientist at AWS Professional Services. She is passionate about MLOps and supports global customers in the financial services industry in building optimized AI/ML solutions to accelerate their cloud journey. Prior to AWS, Sarah worked as a Data Science consultant for various customers, always looking to achieve impactful business outcomes. Outside work, you will find her wandering around art galleries in exotic destinations.
 Pauline Ting is Data Scientist in the AWS Professional Services team. She supports financial, sports and media customers in achieving and accelerating their business outcome by developing AI/ML solutions. In her spare time, Pauline enjoys traveling, surfing, and trying new dessert places.
Pauline Ting is Data Scientist in the AWS Professional Services team. She supports financial, sports and media customers in achieving and accelerating their business outcome by developing AI/ML solutions. In her spare time, Pauline enjoys traveling, surfing, and trying new dessert places.