AWS Public Sector Blog
How Ride Data Helps Drive a Car Share Business
French text to follow
The British Columbia Automobile Association (BCAA) started the mobility revolution in B.C. over 100 years ago when a small group of British Columbians, passionate about cars and mobility, joined together to form an auto club. A century later, BCAA continues to help new generations get to where they need to go, and Evo is one way BCAA meets their changing mobility needs. Evo Car Share is Vancouver’s free-floating car sharing service offering a full fleet of 1,500 four-door, hybrid vehicles.
Improving Car Location to Maximize Customer Satisfaction
Convenience is the primary driver of free-floating car sharing, and Evo’s app-enabled service has grown to over 120,000 members in three years. High levels of vehicle utilization, along with high-density neighborhoods, ensures that a large portion of the fleet is continually “relocated” and available for the next member to use.
However, the challenge is how, when, and where to relocate the vehicles that are left away from peak areas of demand. With the high use of car sharing in Vancouver, the Evo team needs to maximize the likelihood that when a user opens the Evo app, they find an available vehicle nearby.
Each trip generates data that the Evo team analyzes to trend utilization, identify vehicles for servicing, plan investment timelines, and run the day-to-day business operations. Despite vast amounts of data, vehicle relocation has been done based on well-known hot spots and trip end points, rather than demand prediction.
Applying Machine Learning
Working directly with machine learning (ML) and Amazon Web Services (AWS), the Evo team broke down their core challenges into an ML problem – How can we define a prediction model to identify the vehicles most likely to be underutilized? To build this model, historical data was iterated on by applying different algorithms and models on over 5 million trips to identify the right algorithms to solve the problem.
The first step in model development relies on clean, consistent data. Cleaning the data involved defining what a “trip” was, determining the start and end point of a vehicle’s day, isolating Evo staff trips (for service or relocation purposes), and removing that data from consideration.
The data was then organized for the dashboard and the model. Both raw and prediction data were partitioned into daily folders under the root Amazon Simple Storage Service (Amazon S3) bucket. The data was organized geographically into bins that represent 50 m² areas of the city. These bins define the supply and demand area for vehicles based on how far a customer will walk to find a vehicle.
Multiple supervised learning algorithms (SARIMAX, polynomial regression, random forest regression) were implemented and tuned to predict the vehicles that would remain underutilized if not relocated.
Evo was concerned with the precision of the prediction. By combining the polynomial regression and random forest models, the team was able to obtain the most consistent results. Both models are trained by looking at the fleet distribution in each bin at the beginning and end of each day. The vehicles recommended for relocation are obtained by taking the intersection of recommendations coming from the two models.
AWS provided Evo with four ML formulations to predict the count or ratio of utilized or underutilized vehicles in each of the bins. Evo has the flexibility to compare these formulations and settle on the better performing one, accounting for metrics or criteria that weren’t specified or sufficiently identified at the onset of the project.
Architecture and Data Flow

Every trip generates data that is sent to and stored within the BCAA data center. On a nightly basis, an ETL process extracts relevant information from the on-premises system and uploads compressed files into Amazon S3. S3 buckets are organized into daily folders to store each day’s raw vehicle and ride data. Each upload triggers Amazon Simple Notification Service (SNS) to call multiple AWS Lambda functions to clean, organize, and analyze the raw data. The ML models developed in Python are packaged and pushed to AWS Batch to apply the location and prediction models against the current data. The resulting predictions are stored in partitioned folders within S3 for access and display in a custom web interface. Amazon Athena is used to query S3 data and display relevant results.
Results
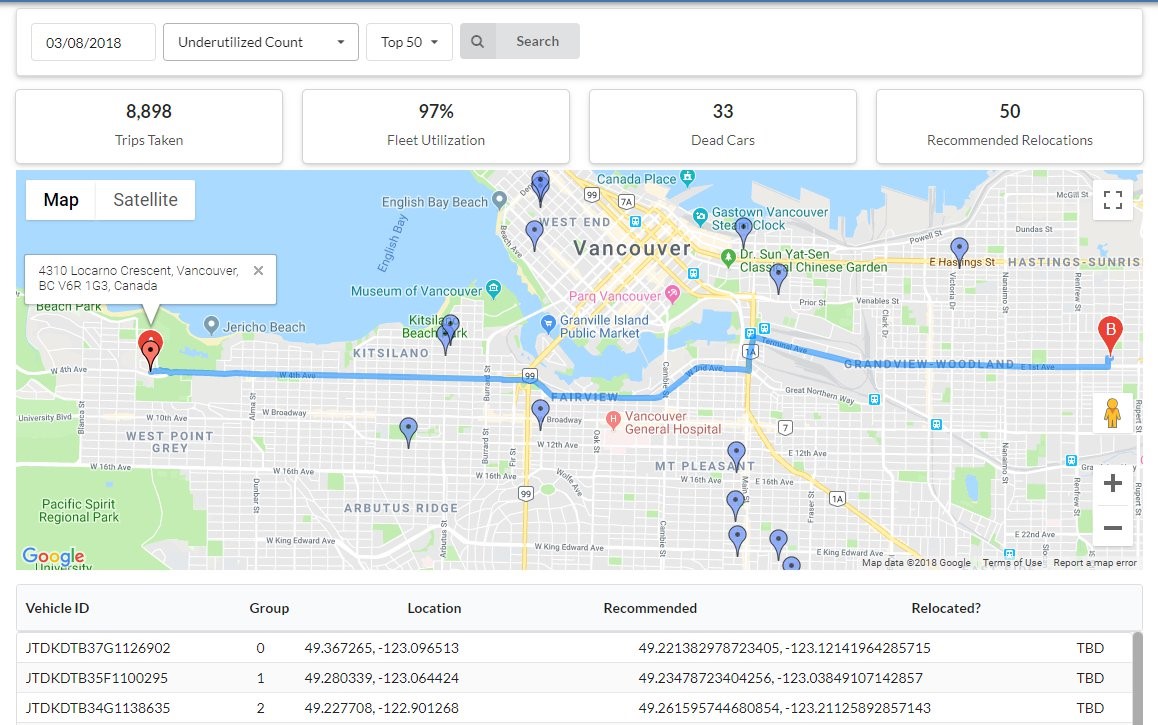
The system provides an automated, serverless dashboard for the team to make data-driven predictions on where and when they need to relocate vehicles. The initial dashboard includes daily reports on vehicle utilization, underutilized vehicles, and which vehicles, based on the output of the ML model, are the best options to relocate.
Evo’s success and continued growth is because our members can rely on us to be right there when they need a convenient way to get around. We’re great at achieving that, but we’re always looking at new ways to stay ahead. That’s why it’s important for us to innovate and invest in solutions like the latest machine learning expertise to ensure we always optimize our fleet operations and minimize the risk of not being in the right place at the right time for our members.
A post by Tai Silvey, Director, BCAA, and Ryan Jancaitis, EE, Amazon Web Services
Comment les données de trajet contribuent à guider une entreprise de covoiturage
Il y a plus de 100 ans, la British Columbia Automobile Association (BCAA) a révolutionné le monde de la mobilité en Colombie-Britannique lorsque quelques Britanno-Colombiens passionnés par les voitures et la mobilité se sont réunis pour former un club automobile. Un siècle plus tard, la BCAA continue d’aider les nouvelles générations à se déplacer, et Evo est l’une des solutions de la BCAA pour répondre à leurs besoins de mobilité changeants. Evo Car Share est un service d’autopartage en libre-service doté d’une flotte de 1 500 véhicules hybrides quatre portes.
Améliorer la location de voitures pour maximiser la satisfaction des clients
La facilité d’utilisation est l’avantage principal d’un service d’autopartage en libre-service. D’ailleurs, l’application d’Evo a attiré plus de 120 000 membres en trois ans. En raison d’un fort taux d’utilisation des véhicules et des quartiers densément peuplés, une grande partie de la flotte est constamment relocalisée et disponible pour le prochain utilisateur.
Le défi reste donc de savoir comment, quand et où relocaliser les véhicules qui se retrouvent en dehors des principales zones d’achalandage. Comme l’autopartage est très populaire à Vancouver, Evo doit maximiser les chances qu’un utilisateur puisse trouver un véhicule à proximité lorsqu’il ouvre l’application.
Chaque trajet génère des données et Evo analyse ces dernières pour déceler les tendances d’utilisation des véhicules, repérer les véhicules disponibles, planifier les investissements et assurer la gestion de l’entreprise au quotidien. Et malgré l’accès à une immense quantité de données, la relocalisation des véhicules se faisait toujours en fonction des lieux populaires et destinations bien connues, plutôt qu’en prévoyant la demande.
Mettre en application l’apprentissage machine
En travaillant directement avec l’apprentissage machine et Amazon Web Services (AWS), Evo a pu mettre le doigt sur son défi principal, qui était en fait un problème d’apprentissage machine – comment pouvons-nous définir un modèle de prédiction pour identifier les véhicules risquant d’être sous-utilisés? Pour créer ce modèle, les données historiques ont été réitérées en appliquant différents algorithmes et modèles sur plus de cinq millions de trajets afin de trouver les algorithmes appropriés pour résoudre le problème.
La première étape de la création d’un modèle est d’obtenir des données nettes et fiables. Pour obtenir celles-ci, il a fallu définir la notion de « trajet », déterminer les points de départ et d’arrivée d’un véhicule lors d’une journée, isoler les trajets réalisés par le personnel d’Evo (pour le travail ou la relocalisation du véhicule) et retirer ces données des calculs.
Les données ont ensuite été organisées pour le tableau de bord et le modèle. Les données brutes et prédictives ont été réparties en dossiers quotidiens dans le compartiment Amazon Simple Storage Service (Amazon S3) principal. Les données ont été organisées géographiquement en zones de 50 m². Ces zones déterminent l’offre et la demande pour les véhicules en fonction de la distance qu’un client marchera pour trouver un véhicule.
De multiples algorithmes d’apprentissage supervisé (SARIMAX, régression polynomiale, régression aléatoire des forêts) ont été appliqués et perfectionnés pour prédire quels véhicules seraient sous-utilisés s’ils n’étaient pas relocalisés.
L’équipe d’Evo s’est également attardé à la précision de la prédiction. En combinant les modèles de régression polynomiale et de régression aléatoire des forêts d’arbres décisionnels, elle a pu obtenir des résultats plus uniformes. Les deux modèles sont formés en étudiant la distribution de la flotte dans chaque zone, au début et à la fin de chaque journée. La recommandation de relocaliser des véhicules se fait selon la mise en commun des résultats des deux modèles.
AWS a fourni à Evo quatre formules d’apprentissage machine pour prédire le nombre ou le ratio de véhicules utilisés ou sous-utilisés dans chaque zone. Evo peut ainsi comparer ces formules et retenir celle qui produit les meilleurs résultats, en tenant compte de mesures ou de critères qui n’ont pas été précisés ou correctement identifiés au début du projet.
Architecture et flux de données
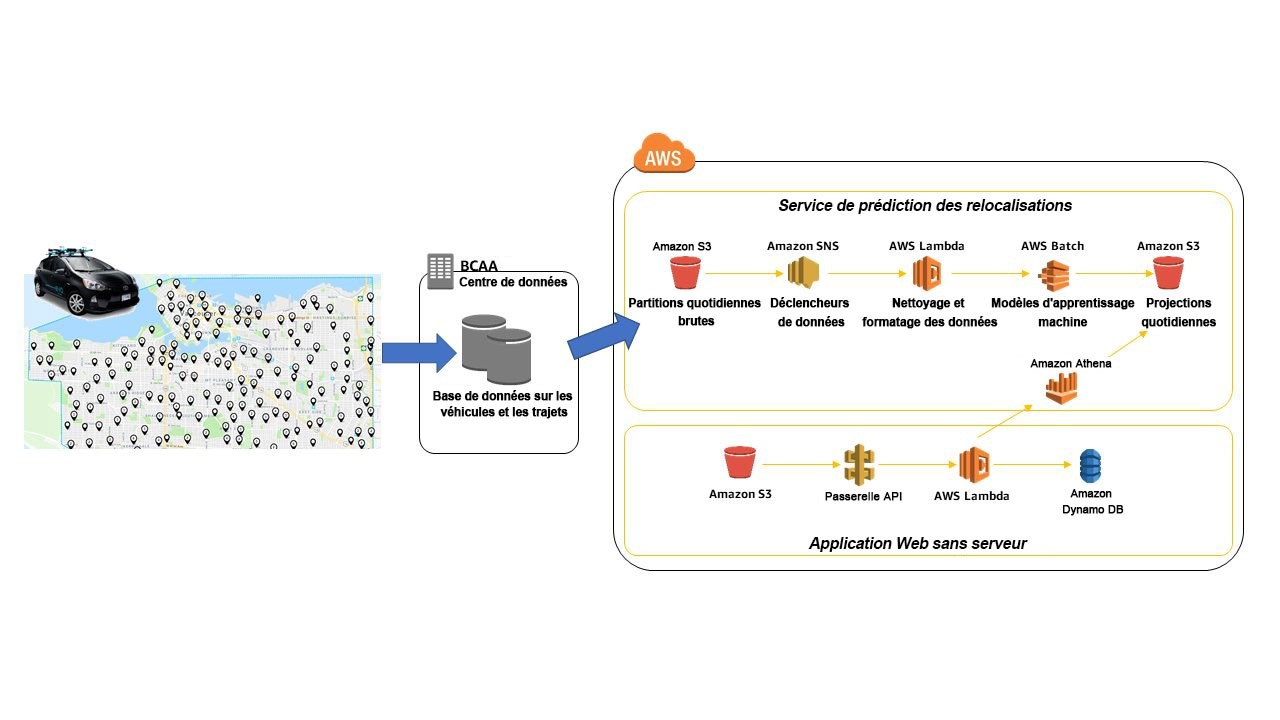
Chaque trajet génère des données qui sont envoyées et stockées dans le centre de données de la BCAA. Chaque soir, un processus ETL extrait l’information pertinente du système sur place et téléverse les fichiers compressés dans Amazon S3. Les compartiments S3 sont organisés en dossiers journaliers pour stocker les données brutes quotidiennes sur les véhicules et les trajets. Pour chaque téléversement, Amazon Simple Notification Service (SNS) s’appuie sur de multiples fonctions AWS Lambda pour nettoyer, organiser et analyser les données brutes. Les modèles d’apprentissage machine créés dans Python sont agencés et poussés vers AWS Batch pour appliquer les modèles de localisation et de prédiction aux données actuelles. Les prédictions obtenues sont stockées à l’intérieur de fichiers partitionnés dans les dossiers S3 pour pouvoir y accéder et les afficher dans une interface Web personnalisée. Amazon Athena est utilisé pour interroger les données S3 et afficher les résultats pertinents.
Résultats
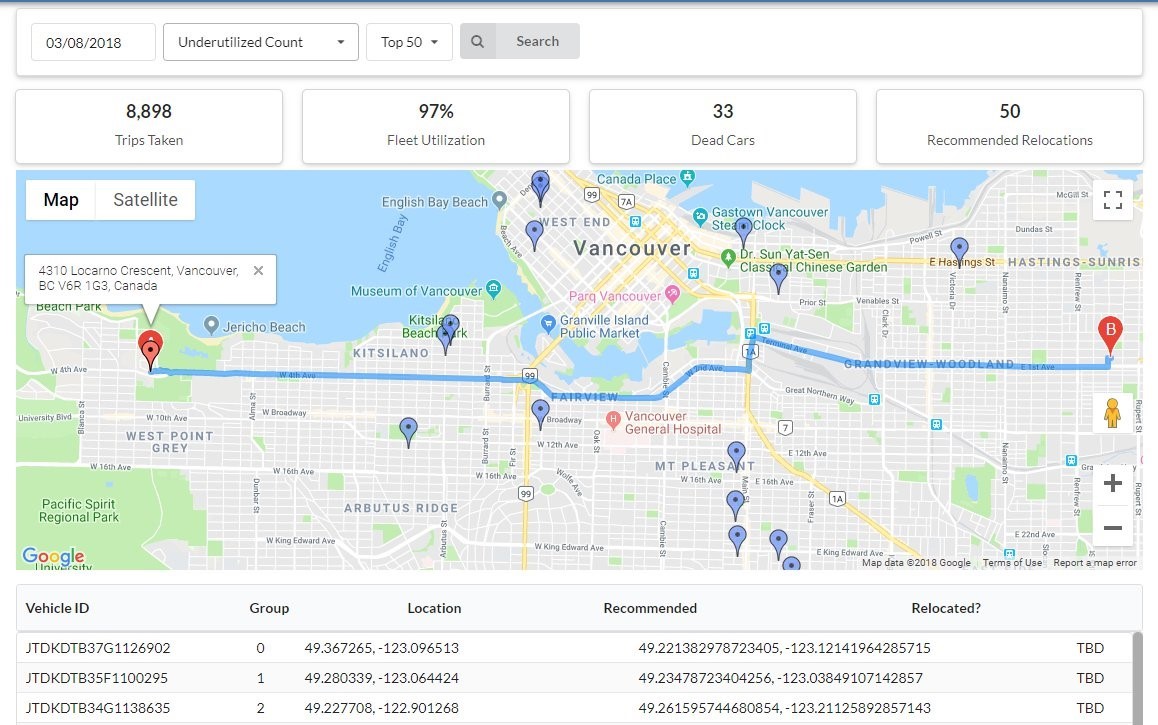
Grâce au tableau de bord sans serveur et automatisé, l’équipe est en mesure d’analyser les données et d’effectuer des prédictions concernant l’endroit et le moment idéal pour relocaliser les véhicules. Le tableau de bord initial comprend les rapports quotidiens sur le taux d’utilisation des véhicules, les véhicules sous-utilisés et les véhicules avantageux à relocaliser, selon les résultats du modèle d’apprentissage machine.
Le succès et la croissance continue d’Evo sont liés à sa fiabilité et sa facilité d’utilisation : ses membres savent qu’ils peuvent compter sur l’entreprise lorsqu’ils ont besoin de se déplacer sans tracas. Nous y parvenons avec brio, mais nous sommes constamment à la recherche de nouvelles façons de nous démarquer. C’est pourquoi nous trouvons important d’innover et d’investir dans des solutions comme l’expertise la plus récente en matière d’apprentissage machine pour optimiser les activités de notre flotte et minimiser le risque de ne pas être au bon endroit, au bon moment, pour nos membres.
Une publication de Tai Silvey, directeur, BCAA, et de Ryan Jancaitis, Ingénierie, Amazon Web Services