AWS Public Sector Blog
Integrating subject matter experts into generative AI evaluation with the AWS Generative AI Innovation Center

You’ve coded your generative AI proof of concept. The demo impresses stakeholders. Then a subject matter expert (SME) sits down with the output and spots a problem no automated metric would catch. The response was fluent, well-structured, and wrong in a way that only someone with deep domain knowledge could identify.
This moment plays out across industries as organizations move from prototype to production with generative AI. It’s the disconnect between what domain experts instinctively know is right and what they can express as measurable evaluation criteria.
Through our work in the Amazon Web Services (AWS) Generative AI Innovation Center, we’ve helped dozens of organizations develop evaluation strategies that bridge this “articulation gap.” The approach has four phases that act together as a flywheel. First, define what good looks like. Second, build ground truth alongside automated metrics. Third, shift from manual to automated evaluation as the system matures. Fourth, identify new evaluation needs.
The following graphic illustrates the flow through these phases. SME involvement evolves from hands-on scoring to periodic calibration as automated metrics mature.
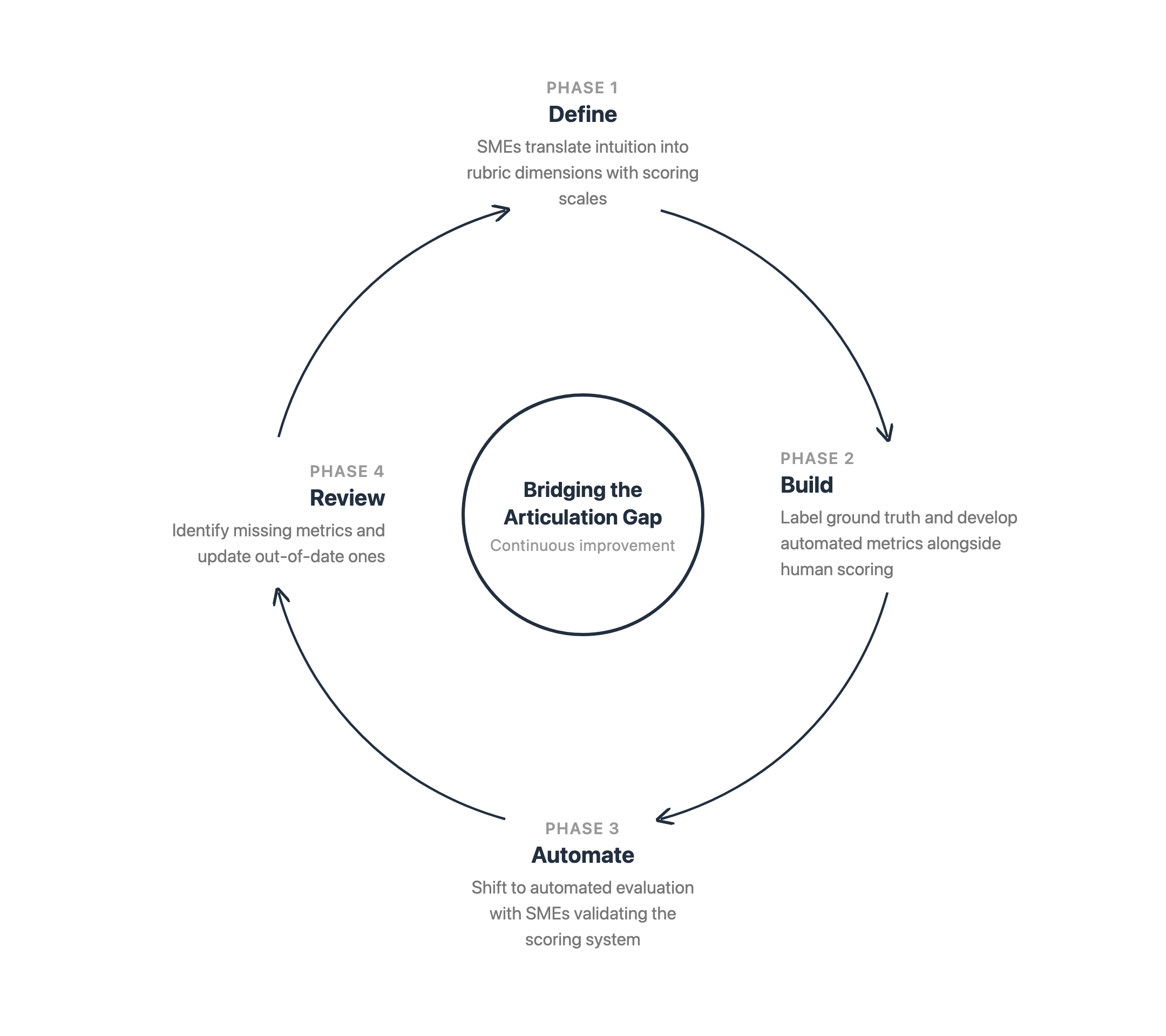
Figure 1: The evaluation flywheel
Phase 1. Define what good looks like
Before writing an evaluation script, the most important step is structured conversations with SMEs. The goal is to translate expert intuition into concrete, repeatable criteria. This can be harder than it sounds. Experts often struggle to articulate why one output feels right and another doesn’t, especially when both are factually correct.
Start by gathering preliminary requirements. What does the system need to do? What are the highest-risk failure modes? Where would a wrong answer cause real harm? Then move to evaluation design. We find that showing SMEs real model outputs and asking, “What’s wrong with this?” is more productive than asking them to define quality in the abstract. Their reactions reveal implicit standards that would otherwise go unspoken.
Consider an education technology company building an AI tutoring assistant. An instructional designer reviewing outputs might flag that the AI gives correct answers but fails to establish the student’s prerequisite knowledge. A math tutor that jumps to derivatives without confirming the student understands limits is technically accurate but pedagogically harmful. That feedback can be used to develop a rubric dimension such as scaffolding appropriateness, scored on a 1–5 scale with a clear definition and anchor example(s) at each level. The rubric becomes the shared language between domain experts and engineers for the rest of the project. The following table shows an example rubric.
| Score | Label | Definition | Anchor example |
| 5 | Excellent | Builds on confirmed prior knowledge, introduces concepts in logical sequence, checks understanding before advancing | “Before we look at derivatives, let’s make sure you’re comfortable with limits. Can you tell me what happens to f(x) = 1/x as x approaches infinity?” |
| 4 | Good | Follows a logical sequence and references prerequisites, but doesn’t actively verify understanding | “Derivatives build on the concept of limits. Remember that a limit describes the value a function approaches. Now, a derivative measures…” |
| 3 | Adequate | Correct and organized but assumes prerequisite knowledge without acknowledging it | “The derivative of f(x) measures the rate of change. To find it, we use the limit definition…” |
| 2 | Poor | Skips prerequisites and uses jargon or notation the learner might not recognize | “Apply the power rule: d/dx[x^n] = nx^(n-1). So for f(x) = x³, f’(x) = 3x².” |
| 1 | Harmful | Introduces concepts out of order or gives answers that actively confuse the learner | “Use L’Hôpital’s rule here. Take the derivative of the numerator and denominator separately…” (student has not learned derivatives yet) |
Phase 2. Improve ground truth and build automated metrics
Then you can begin building your evaluation dataset. Amazon SageMaker Ground Truth provides managed labeling workflows where SMEs can score model outputs against your rubric at scale. These human-scored examples become the ground truth that all automated metrics are validated against. Try to cover the full range of quality levels and edge cases your system will encounter.
Simultaneously, develop automated evaluation pipelines based on SME feedback. You can use Amazon Bedrock Evaluations to run large language model (LLM)-as-judge assessments with custom metrics. Keep in mind automated metrics earn trust by agreeing with expert judgment, not the other way around. Measure the correlation between automated and human scores. When they diverge, investigate. Sometimes the automated metric needs refinement. Sometimes it reveals inconsistency in human scoring. Both outcomes improve the system.
Phase 3. Shift from manual to automated evaluation
As confidence in automated metrics grows, the SME role shifts from scoring every output to validating the scoring system itself. You can now automatically evaluate at production scale with limited human involvement. SMEs can first conduct periodic calibration checks between human and automated scores, then check cases the automated system flags as uncertain.
For the education company example, automated metrics might handle 90% of evaluation volume, covering factual accuracy, response format, and reading level. SMEs review a rotating sample of outputs during each sprint plus any outputs where the automated scorer’s confidence falls below a threshold, particularly for scaffolding and pedagogical quality. The SMEs are no longer bottlenecking every release but are calibrating the system that evaluates at scale.
The following graphic illustrates how SME effort evolves from one phase to the next. Total effort decreases, but the nature of the work shifts from defining criteria to calibrating automated systems.
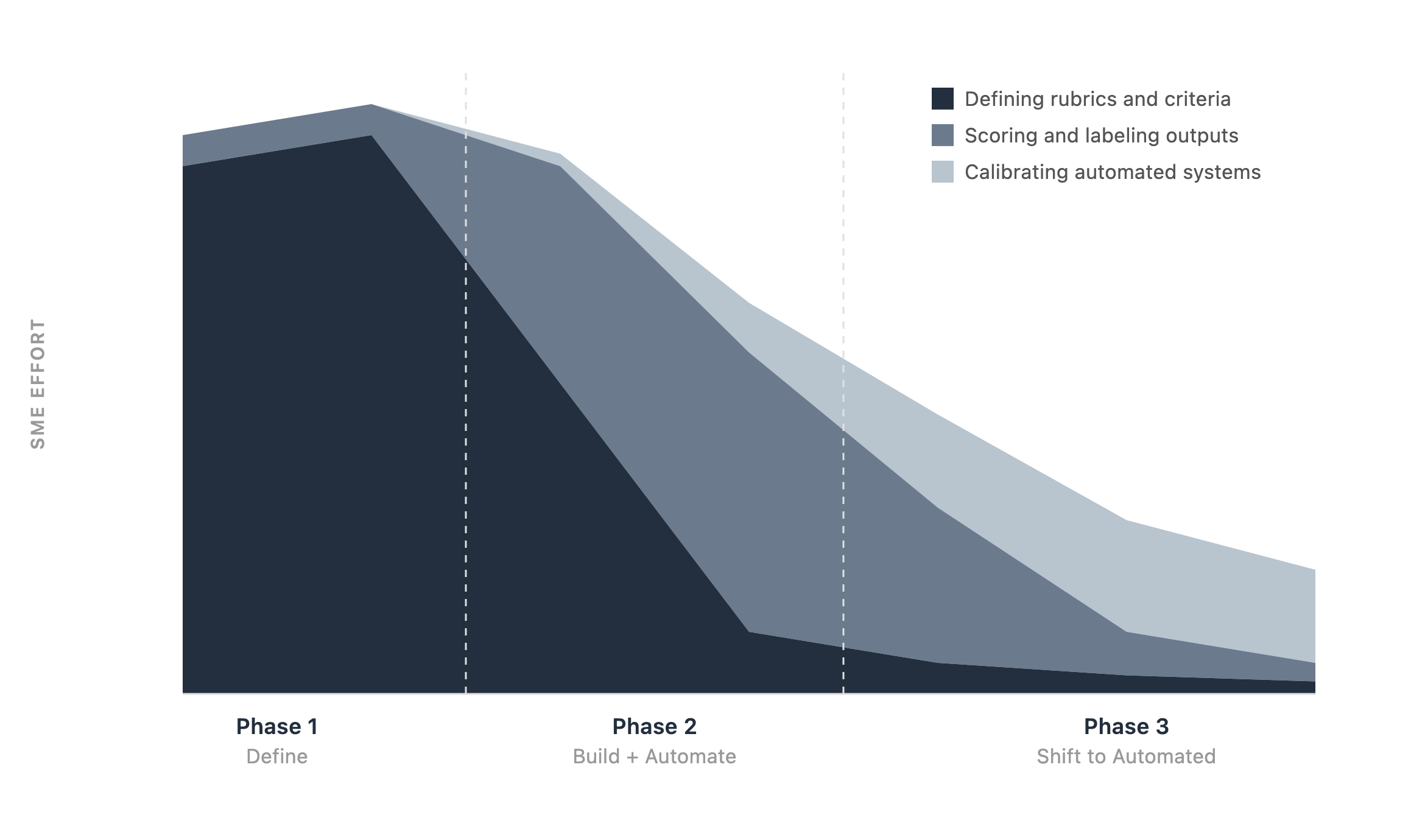
Figure 2: How SME effort evolves across phases
Phase 4. Review the metrics
As your product evolves, so should your evaluation framework. Phase 4 brings SMEs back to assess whether the rubric, ground truth, and automated metrics still reflect what “good” looks like today.
Start by having SMEs review the current rubric against recent model outputs. Are the dimensions still relevant? For the education company, if the tutoring assistant now supports multi-turn conversations, the original rubric might miss how well the assistant builds on prior exchanges.
SMEs should also flag where automated scores are diverging from expert judgment. Consistent disagreements from phase 3 calibration checks signal that metrics need updating.
After gaps and outdated criteria are identified, cycle back to phase 1 with fresh structured conversations, current outputs, and an updated rubric. Then add to the ground truth, revalidate automated metrics, and return to phase 4. This is the flywheel: teams that treat evaluation as a continuous loop maintain alignment with what “good” means as it changes over time.
Getting started
After working on hundreds of generative AI projects, we’ve consistently seen that teams who build effective feedback loops into their development process can evaluate at scale with confidence, ship faster, and clear the gap between prototype and production that stalls so many generative AI initiatives.
Are you ready to learn more or get started?