AWS Public Sector Blog
Navigating polymorphic data: A Pariveda guide to AWS Glue and Salesforce integration

Public sector organizations are increasingly seeking innovative software-as-service (SaaS) solutions that can transform their service delivery, improve constituent outcomes, and enhance operational efficiency through secure, scalable, and data-driven platforms. For example, a healthcare customer is going to market with a new SaaS product designed to improve patient outcomes, operational efficiency, and data-driven decision making across healthcare services for case managers and stakeholders. The product is backed by two main components: a data platform built on Amazon Web Services (AWS), with AWS services for ingesting, transforming, analyzing, and serving as much as 50 GB of data per month – and Salesforce for user engagement and case management. Built to meet the unique needs of the public health sector, the integration of the data platform and Salesforce empowers healthcare providers and agencies to securely manage, analyze, and act on critical health data.
Polymorphic referencing is a common pattern in database design and is used by both approaches because it gives developers the flexibility to create relationships between Salesforce objects. With this referencing pattern, a relationship field can be one of several different types of objects. The “Who” relationship field of a Task object could be a relation to either a Contact or a Lead object, for example. This flexibility is particularly useful when a developer wants to establish a relationship with different object types without having to create a separate lookup table or master-detail fields. With granular control over how data is transferred and the ability to upload records using the Salesforce connector or Bulk API, AWS Glue provides developers with the compute and integration framework they need for this use case.
This post shares lessons learned by Pariveda, a strategy and technology services firm, during the implementation of a scalable and flexible data integration pipeline for a customer. In this post, we review three approaches, all leveraging AWS Glue and Salesforce capabilities, to securely publish data to polymorphic objects and compounded fields. One approach uses the AWS Glue built-in Salesforce connector, where AWS manages the credentials and integration. The second approach uses Salesforce’s Bulk API to send large amounts of data by sending a series of Salesforce authenticated API requests. The third approach highlights the Salesforce and AWS Zero Copy Integration, which enables real-time, bi-directional data sharing between Salesforce Data Cloud and AWS services.
Overview of services
AWS Glue is a fully managed extract, transform, and load (ETL) service. Key highlights include its serverless nature and seamless ETL process. By eliminating the need for users to provision or manage infrastructure, AWS Glue streamlines the ETL process by autonomously handling tasks ranging from data schema discovery to ETL code generation. In addition, AWS Glue uses a centralized Data Catalog to provide a metadata repository for organizing and querying metadata about various data sources and targets. With the flexibility to write custom ETL scripts in Python or Scala to handle complex transformations or filters, you can extract, transform and push data to integrate with various services.
AWS offers a built-in AWS Glue connector for Salesforce that enables AWS Glue to extract data from Salesforce. It connects to Salesforce using OAuth 2.0 or JSON Web Token (JWT) and supports both standard and custom objects. This method retrieves data at the object level rather than executing queries, making it suitable for bulk data extraction and ETL workflows. The connector is configured within AWS Glue as a data source and can be used in AWS Glue ETL jobs to transform and load Salesforce data into AWS services such as Amazon Simple Storage Service (Amazon S3) or Amazon Redshift. It provides secure authentication, supports schema inference, and allows incremental data retrieval by filtering records based on system fields such as LastModifiedDate. However, because it doesn’t support Salesforce Object Query Language (SOQL), you can’t specify custom queries and must work with full object extractions. To push polymorphic fields to Salesforce, the connector between AWS Glue and Salesforce automatically handles relationship fields that can reference multiple object types. By promoting data integrity and monitoring API limits, you can efficiently manage polymorphic fields while integrating AWS Glue with Salesforce.
The following architecture diagram shows the integration of data using the AWS Glue connector for Salesforce:
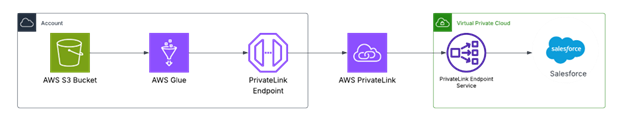
Figure 1: Integration of data using AWS Glue connector for Salesforce
JWT considerations
It is important that when using JWT authentication, always follow best practices for JSON Web Token (JWT) security. This includes validating token signatures, enforcing short token lifetimes, and avoiding exposure of tokens in URLs or client-side logs. Developers should also ensure proper audience and issuer checks to mitigate common JWT vulnerabilities such as replay or token substitution attacks.
The remainder of this post focuses on the two other approaches: Salesforce Bulk API and Zero Copy ETL. Also, it provides a technical walkthrough so that developers can use either approach. More information and a detailed walkthrough of using the AWS Glue Salesforce connector can be found at Accelerate data integration with Salesforce and AWS using AWS Glue in the AWS Big Data Blog.
Salesforce Bulk API solution
Using the Salesforce Bulk API 2.0, large amounts of data can be extracted and loaded into Salesforce efficiently. Developers can use AWS Glue to extract, transform, and load data into Salesforce by first extracting data from various sources such as an S3 bucket, transforming it into a format compatible with Salesforce, and then using Salesforce APIs to upload the prepared data into the target Salesforce object. This automated processing of the data along with the integration with Salesforce ensures consistency and accuracy. The process follows these steps:
- Source bucket – Specify an S3 bucket where you want to read the data from and have the sample data available for extraction as a .csv file.
- Field mapping and transformation – Configure the data to be in the format that Salesforce expects for bulk uploads. Refer to Prepare a CSV file for an Import or Update in Salesforce for more information on formatting the CSV.
- Destination bucket – Specify an S3 bucket as the destination for your data.
- Salesforce bulk upload – Use AWS Glue to point to the Salesforce APIs to upload the prepared data into Salesforce objects. Refer to Salesforce Bulk API for more information on using the Salesforce Bulk upload methods.
- Query – Query results of the ETL to obtain the records that successfully uploaded, failed to upload, or didn’t process.
The following diagram shows this flow.

Figure 2: Integration of data using Salesforce bulk API
Salesforce and AWS Zero Copy Integration
With the introduction of Salesforce and AWS Zero Copy Integration, organizations can seamlessly share data between Salesforce Data Cloud and AWS services like Amazon Redshift, Amazon S3, and AWS Glue without needing to move or copy data. In this approach, Salesforce Data Cloud establishes a bi-directional connection with AWS through Zero ETL pipelines. Data residing in AWS can be queried directly from Salesforce for AI-driven insights, while customer data in Salesforce can be analyzed in AWS analytics environments such as Redshift and SageMaker. This eliminates the traditional ETL overhead and latency, enabling real-time insights and unified data access.
Key highlights include:
- Zero Copy Data Access: No data duplication or physical movement between platforms.
- Security and Governance: Data remains governed under the original cloud’s compliance and IAM controls.
- Real-Time Analytics: Data is available for Salesforce AI and AWS analytics workloads simultaneously.
When compared to the AWS Glue Salesforce Connector and Salesforce Bulk API methods, Zero Copy Integration offers a third option focused on low-latency interoperability rather than data transfer. It is best suited for enterprises that require unified analytics or AI insights across both clouds without adding ETL complexity.
Comparison of Salesforce Integrations
The built-in AWS Glue connector provides integration that allows seamless ETL operations within AWS services, enabling direct data transformations and loading into Salesforce without requiring additional API management. It is well-suited for structured batch processing and simplifies authentication and connection handling. In contrast, the Salesforce Bulk API is optimized for high-volume data loads and asynchronous processing, making it ideal for large-scale insert, update, upsert, and delete operations. It provides more granular control over job batching, error handling, and performance tuning but requires direct API interactions, authentication management, and monitoring of job execution.
Recently, Salesforce and AWS introduced a third approach, Zero Copy ETL, which eliminates the need for traditional ETL or bulk upload processes altogether. This approach enables Salesforce Data Cloud and AWS storage services such as S3 to share and access the same datasets. While the AWS Glue connector offers ease of use within AWS Glue ETL pipelines and the Bulk API offers flexibility for developers managing high-volume data operations, the Zero Copy Integration focuses on seamless data access between platforms. The choice depends on the specific use case: AWS Glue is preferable for AWS based workflows, Bulk API is better for large-scale, independent Salesforce data operations, and Zero Copy Integration for real-time cross-cloud analytics and AI enablement. These factors are listed in the following tables.
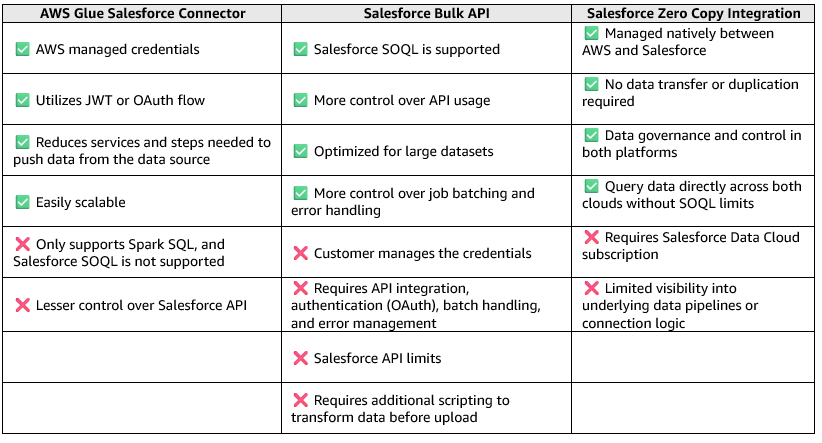
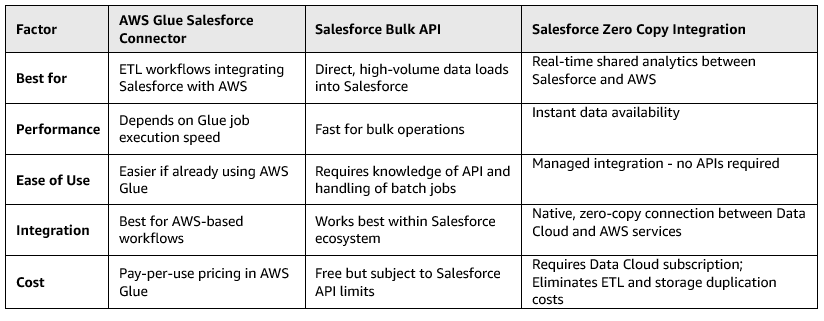
Based on this comparison, we concluded that if the task is to only upload data into Salesforce, the Salesforce Bulk API is the better choice. If there is a need to integrate Salesforce with AWS services or need data transformation, use the AWS Glue Salesforce connector. However, if the goal is to enable real-time, bi-directional data sharing, the Salesforce and AWS Zero Copy Integration provide the most efficient approach.
Security Considerations
To securely manage access across AWS Glue, Redshift, and S3, follow AWS IAM best practices. Define granular IAM policies based on the principle of least privilege, use IAM roles instead of long-term access keys, and validate permissions using IAM Access Analyzer. These practices help ensure the integration between AWS and Salesforce remains secure and auditable. To create and maintain your policies, reference these policies and permissions in AWS Identity and Access Management.
It is also important to ensure that all S3 buckets storing data for ETL processes are encrypted at rest using AWS KMS managed keys and apply AWS encryption best practices. Data in transit between services must be encrypted using TLS. Implement clear data classification policies to define how sensitive Salesforce or customer data is handled within the pipeline. For more information, refer to Encrypting data at rest and in transit.
When uploading to the Bulk API, establish strong API authentication, authorization, and communication protections for all Salesforce and AWS data flows. Set CloudWatch metrics and alarms to monitor Salesforce API usage, throttling errors, and bulk API request volumes. Also, use AWS CloudTrail for auditing API calls and detecting unusual patterns. While pushing data, require TLS 1.2 or later for all service communications between services. Deny non-TLS requests using IAM policies (“aws:SecureTransport”: “false” → Deny). When possible, use AWS PrivateLink or VPC endpoints to keep traffic on the AWS network and reduce public internet exposure.
Conclusion
AWS Glue is a powerful tool for ETL processes requiring complex transformations to upload data for Salesforce and other target applications. An in-depth comparison was made of the three methods used to extract and write data to Salesforce: the AWS Glue to Salesforce connector, Salesforce Bulk API, and Salesforce and AWS Zero Copy Integration. From the analysis, the AWS Glue to Salesforce connector is recommended for AWS based workflows. However, all methods can allow polymorphic data to land in Salesforce, which means users can perform more complex operations. Overall, these integrations increase flexibility on what a user can do with various types of data, providing significant benefits for data professionals and organizations seeking to use the storage and analytical capabilities of both platforms.