AWS Public Sector Blog
Smarter K12 lesson and assessment mapping in education on AWS

In the field of K12 education technology (EdTech), delivering personalized and standards-aligned learning experiences depends on deeply understanding the relationships between assessments, lessons, academic standards, and each student’s learning journey. However, most systems today manage these elements as traditional one-to-many relationships and in disconnected silos in which assessments live in one system, lesson content in another, standards in static documents or spreadsheets, and student performance in isolated gradebooks or learning management system (LMS) platforms.
This causes critical student assessment problems in several areas. Without linked lessons, standards, students, skills and assessment, educators can’t identify why a student excels in algebra but struggles with geometry. Most assessment platforms give families a score or grade, but not enough context to act on it. Families often don’t know which skills their child is struggling with or what lessons could help them improve—making it hard for them to support learning at home.
Current assessment systems can’t dynamically recommend the next best learning activity based on a student’s complete academic profile. If a student masters fractions but struggles with decimals, the system should automatically suggest targeted decimal lessons while reinforcing fraction concepts—but fragmented data can’t support connections like this. Educators need to answer complex questions such as, “Which students in my class are ready for advanced topics?” or “What prerequisite skills do struggling students need to develop?” Current assessment platforms provide data but not the relationship intelligence needed for informed instructional decisions.
These challenges and fragmented setups make it extremely difficult to build a system that connects a student’s progress with the lessons they’ve completed, the standards those lessons cover, and the assessments that measure understanding. It also fails to present a single unified view that ties it all together for teachers or families. These challenges prevent EdTech platforms from building a dynamic and responsive learning system, a structure where every lesson, assessment, standard, and student is a connected node, enabling intelligent analytics, content recommendation, and mastery tracking. Until these connections are made explicit and queryable, providers continue to face high operational costs, delayed instructional improvements, and limited ability to deliver the personalized learning experiences that modern education demands.
In this post, we explore how a graph-based student assessment system powered by Amazon Web Services (AWS)—including services such as Amazon Neptune and Amazon Bedrock—can address these challenges. By using a graph-enhanced Retrieval Augmented Generation (GraphRAG) architecture, we model the relationships among students, standards, lessons, and topics to bring automation, accuracy, and adaptability to the standards-alignment process. With this modern approach, EdTech platforms can deliver scalable, standards-compliant, and personalized learning experiences across K12 learning environments.
Why GraphRAG and not traditional RAG? The case for a relationship-first model
Before we demonstrate how a GraphRAG system might look, we need to address why we use GraphRAG and not RAG.
In educational systems where data is inherently relational—students, courses, assessments, standards, and learning outcomes—traditional RAG models fall short. Built to work with unstructured documents and keyword-based vector search, traditional RAG lacks the depth needed to reason over structured academic relationships.
How traditional RAG works
Traditional RAG systems follow a straightforward pipeline:
- Document chunking – Break documents into smaller pieces
- Vector embedding – Convert text chunks into numerical representations
- Similarity search – Find relevant chunks based on query similarity
- Context assembly – Combine retrieved chunks for AI processing
- Response generation – Generate answers from assembled context
Flow
Documents/Data → Chunking → Embeddings → Vector DB → Similarity Search → LLM → Response
Traditional RAG limitations
Traditional RAG systems work effectively with unstructured text such as research papers, manuals, and articles. However, educational data presents unique challenges because it consists of structured and relational information. When relational data gets forced into document chunks, the system loses the relationships that make the data valuable. In K12 assessment systems, a student’s algebra performance connects directly to their mastery of specific math standards, completion of prerequisite geometry lessons, and their teacher’s instructional approach. Traditional RAG would process each assessment score as isolated text, failing to recognize the connections between student achievement, curriculum standards, and learning pathways.
Vector similarity search identifies semantically similar content but when the related facts spread across chunks and documents, it cannot capture logical relationships. Education requires understanding how a student’s performance in prerequisite courses determines their readiness for advanced topics. These logical relationships extend beyond what vector similarity can detect. When a K12 teacher queries which students are ready for advanced calculus, the system must trace through prerequisite math courses from Algebra I through Algebra II to Precalculus while verifying mastery levels. This requires logical reasoning rather than finding students with similar course names or grades.
Traditional RAG systems also face limitations from the AI model’s context window when handling complex educational questions that require pulling together information from many connected lessons, standards, and assessments. These queries often become truncated or oversimplified, producing incomplete insights. Answering a question about which intervention strategies work for students struggling with reading comprehension in social studies requires connecting student reading assessment to comprehension skill gaps, then to social studies curriculum standards, proven intervention methods, and teacher implementation success rates. This multi-hop analysis exceeds traditional RAG capabilities. RAG treats each query independently and misses course dependencies and student progression patterns. This prevents dynamic relationship exploration that could reveal patterns across the educational ecosystem. Understanding why certain K12 students excel in science while struggling in math requires examining their learning history, teaching methods across subjects, family engagement patterns, and peer group dynamics. Traditional RAG cannot dynamically explore or correlate these interconnected factors that shape student outcomes.
How GraphRAG works
GraphRAG fundamentally reimagines how we approach data retrieval by treating relationships as the primary organizing principle rather than an afterthought.
Flow
Structured Data → Graph Modeling → Relationship Storage → Graph Queries → Context Assembly → LLM → Response
GraphRAG offers a shift from document-centric retrieval to a relationship-aware model, which is essential for the complex, interconnected world of K12 education. Unlike traditional RAG, which focuses on finding documents based on keyword or vector similarity, GraphRAG helps with rich, contextual queries across structured relationships. For example, instead of merely retrieving documents about student performance, GraphRAG can answer questions such as, “Which students taking advanced mathematics are also excelling in computer science?”
This relationship-first approach enables multi-hop reasoning, where insights can be drawn across linked data paths, such as tracing a student’s performance through courses, their prerequisites, and related assessments. For example, you can ask a multi-hop query, such as “Identify students who struggled with algebra but excelled in geometry, and recommend their optimal path to calculus.”
This is considered multi-hop because it requires traversing:
- Student → Algebra performance (hop 1)
- Student → Geometry performance (hop 2)
- Geometry → Calculus prerequisites (hop 3)
- Prerequisites → Recommended learning path (hop 4)
View
Student(Alice) --[TAKES]→ Lesson(Algebra) --[BELONGS_TO]→ Subject(Mathematics)
| |
| v
+—[SCORED]-----------> Assessment(85%)
It also brings deeper contextual understanding to retrieval, by incorporating the structural links between teachers, standards, lessons, and assessments. This means queries are no longer only about matching terms but about navigating meaningful educational connections.
Moreover, GraphRAG supports scalable analytics by enabling dynamic exploration of a constantly evolving academic graph. This is valuable for aligning content to shifting standards, monitoring student cohorts, or identifying knowledge gaps—all in real time. The result is a smarter, more adaptable foundation for personalized learning and instructional design.
Reference architecture
The reference architecture presents a GraphRAG solution using AWS services to support K12 student assessment and lesson mapping. The architecture is designed to extract, transform, and load educational data (students, lessons, standards, and grades) from a relational database into a graph database and enable natural language queries through a large language model (LLM), extended with an API endpoint capability.
At the heart of the architecture lies an Amazon Relational Database Service (Amazon RDS) for MySQL instance, serving as the primary data source. This database can house core entities of educational data, including students, lessons, standards, and grades information. It might also include other relational relationships such as student-to-standards, student-to-lessons achieved and learning-lessons-grade standards.
An AWS Glue job that acts as the extract, transform, and load (ETL) pipeline to extract the preceding education relationship data. You can use the capabilities of visual ETL to create a source, transform and target job, or you can use a transformation script. The ETL pipeline will:
- Connect to the RDS database using the provided Java Database Connectivity (JDBC) connection
- Read data from Amazon RDS using JDBC
- Generate Neptune compatible node IDs, graph-based node dataframes, and combine all nodes (vertices)
- Generate edge dataframes from foreign key relationships, combine all edges (relationships)
- Write node and edge data to Amazon Simple Storage Service (Amazon S3) in Neptune CSV bulk loader format (importable using Neptune bulk loader API)
- Generate a manifest file describing the location and type of each file (nodes or edges) under the Amazon S3 output path
After the AWS Glue job script has successfully transformed the relational data and saved it to Amazon S3 as nodes and edges, we need to load this data into Amazon Neptune database. Neptune provides a bulk loader API that can import data directly from Amazon S3.
The bulk loader requires:
- The S3 path containing the transformed data
- The format of the data (CSV in our example)
- An AWS Identity and Access Management (IAM) Amazon Resource Name (ARN) role that Neptune can assume to access the S3 bucket of the output path
- The AWS Region where the S3 bucket is located
The bulk load API returns a load ID that can be used to check the status of the load operation. (Note: For an example of curl command to initiate the load process from the Amazon S3 CSV output into Amazon Neptune, visit Loading Data into a Neptune DB Instance in the Amazon Neptune User Guide.)
To enable natural language interaction, a GraphRAG function running on AWS Lambda serves as the bridge between natural language questions and graph queries. At a bare minimum, it should perform the following actions:
- Get the user’s question as event context
- Initialize core modules of connections
- The Neptune Gremlin endpoint
- The Amazon Bedrock client for LLM-based response generation
- Translate the question into a graph search (for example, through a Gremlin query) that knows what to look for in the educational data
- Extract searched results returned from the above query, create context
- Format the prompt using the question and retrieved context and convert to string context for prompting the LLM
- Invoke Amazon Bedrock for answer generation, including the constructed prompt
- Return the answer along with the question as a JSON response as Lambda output
To provide public-facing interface for the GraphRAG educational analytics system, a managed Amazon API Gateway REST API endpoint is included in the reference architecture that can accept POST requests with JSON payloads. This enables client applications to submit natural language queries about student data through HTTP requests—allowing the solution to be accessible for educational applications, dashboards, or direct testing. The API uses AWS_PROXY integration to seamlessly forward incoming requests to the GraphRAG Lambda function.
The following diagram illustrates the reference architecture.
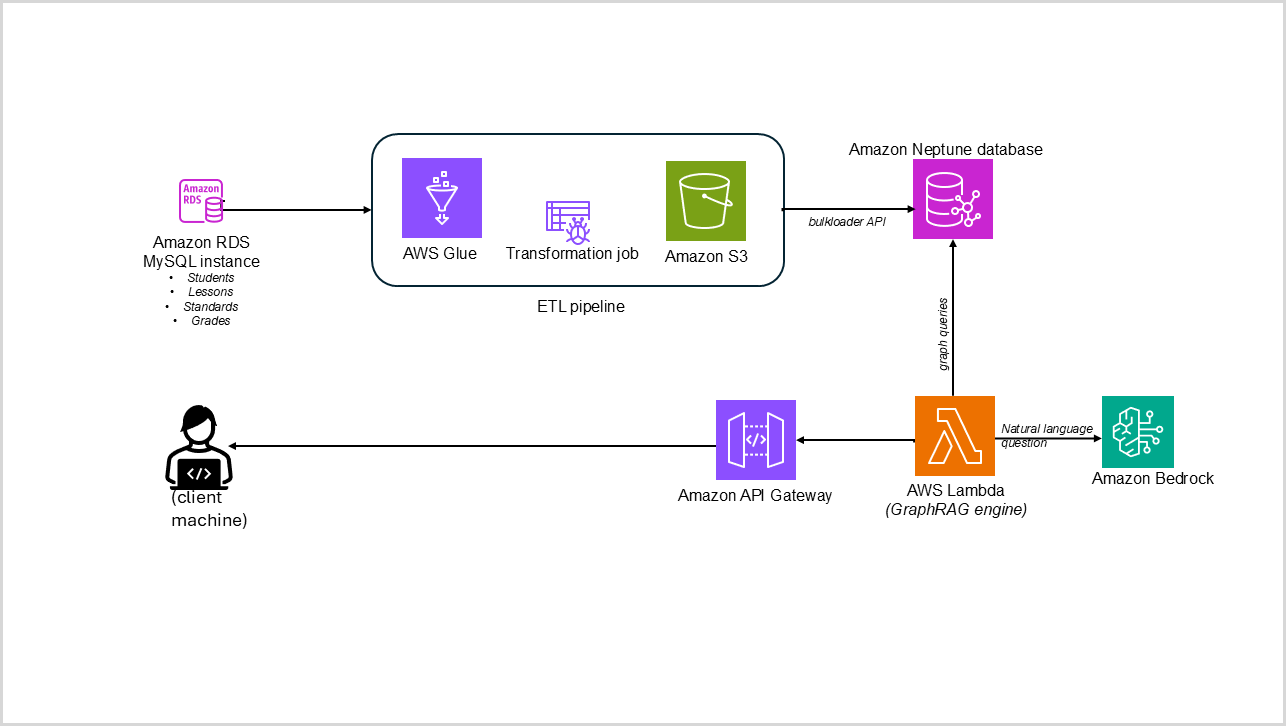
Figure 1: Reference architecture
Education scholars can use the architecture we’ve presented to unify fragmented content and assessment data, enabling personalized learning, real-time performance analysis, and standards alignment. The system can be extended with additional entities (such as teachers, schools, and districts) and relationships (such as prerequisites, recommendations, and peer interactions) to create even richer educational insights.
It’s important to note that detailed implementation instruction is outside the scope of this post. Detailed deployment varies significantly across EdTech organizations due to unique institutional requirements and constraints. Each school district or educational institution operates with different student information systems (SIS) and state education standards like TEKS and California Common Core State Standards, requiring custom data extraction and transformation approaches. Security and compliance requirements differ based on state regulations, with some districts mandating on-premises deployments whereas others embrace cloud-first strategies. Budget constraints, technical expertise levels, and procurement processes also influence deployment strategies, making standardized implementation guidance impractical for real-world EdTech scenarios where customization is essential for successful adoption. Refer to the resources section at the end of the post, which includes a workshop, GraphRAG toolkits, and further guidelines that can help you with implementations.
Conclusion
The guidance in this post provides a foundation for educational analytics, enabling natural language queries over student-course-assessment relationships. The graph-based approach offers advantages over RAG for structured, relational data scenarios.
While traditional RAG finds documents about student performance, GraphRAG goes further by answering which students taking mathematics are excelling in computer science. Similarly, traditional RAG has limitations with document similarity, whereas GraphRAG traces paths from students through courses to prerequisites to performance patterns. This difference extends to retrieval methods: Traditional RAG relies on keyword-based retrieval, but GraphRAG understands relationships between students, teachers, courses, and assessments. Furthermore, traditional RAG analyzes documents without modification, in contrast to GraphRAG, which explores relationships across the educational graph as data changes.
EdTech teams can use the reference architecture in this post as a starting point for exploring GraphRAG approaches that bring structured educational data to life through conversational interfaces. Building on this foundation, educators and EdTech professionals should evaluate their data infrastructure, identify areas where fragmented systems hinder personalized learning experiences, and take action towards implementing a GraphRAG solution for their K12 assessment and lesson mapping needs.
To learn more, explore the following resources. For guidance on best practices and implementation specifics tailored to K12 use cases, connect with AWS education specialists.
Resources
- Workshop – Transforming K-12 Education Assessment with GraphRAG on AWS
- Introducing the GraphRAG Toolkit
- Using knowledge graphs to build GraphRAG applications with Amazon Bedrock and Amazon Neptune
- Build a knowledge base with graphs from Amazon Neptune Analytics
- Amazon Bedrock Knowledge Bases supports GraphRAG now generally available
- Build GraphRAG applications using Amazon Bedrock Knowledge Bases