亚马逊AWS官方博客
Amazon Forecast – 现已正式发布
使用历史数据获得准确的时间序列预测并非易事。去年在 re:Invent 上,我们推出了 Amazon Forecast,这是一项完全托管的服务,无需机器学习经验即可提供高度准确的预测。 我很高兴地宣布 Amazon Forecast 于今天正式发布!
Amazon Forecast 不需要预置服务器。 您只需要提供历史数据,以及您认为可能对预测有影响的任何其他元数据。例如,您需要或生产的特定产品的需求可能会随着天气、一年中的时间以及产品使用位置的变化而变化。
Amazon Forecast 基于亚马逊的技术构建,融入了我们以易于使用的方式构建和运行高度准确的可扩展预测技术的多年经验;因为它使用深度学习方式从多个数据集中学习并自动尝试不同的算法,所以适合诸多不同的用例,例如预估产品需求、预估云计算使用量、财务规划、供应链管理系统中的资源规划等。
使用 Amazon Forecast
本篇博文中,我需要一些示例数据。为获得一个有趣的用例,我从 UCI 机器学习库中找到了个人家庭用电数据集。为简明起见,我使用的是一个数据每小时汇总的 CSV 文件格式的版本。开头的几行中您可以看到时间戳、耗电量以及客户 ID:
2014-01-01 01:00:00,38.34991708126038,client_12 2014-01-01 02:00:00,33.5820895522388,client_12 2014-01-01 03:00:00,34.41127694859037,client_12 2014-01-01 04:00:00,39.800995024875625,client_12 2014-01-01 05:00:00,41.044776119402975,client_12
让我们看看使用 Amazon Forecast 控制台构建预测工具并执行预测是多么简单。对于更高阶的用户,另一个选择是使用 Jupyter 笔记本和适用于 Python 的 AWS 开发工具包。您可以在此 GitHub 存储库中找到一些示例笔记本。
在 Amazon Forecast 控制台中,首先要创建一个数据集组。数据集组充当相关数据集的容器。
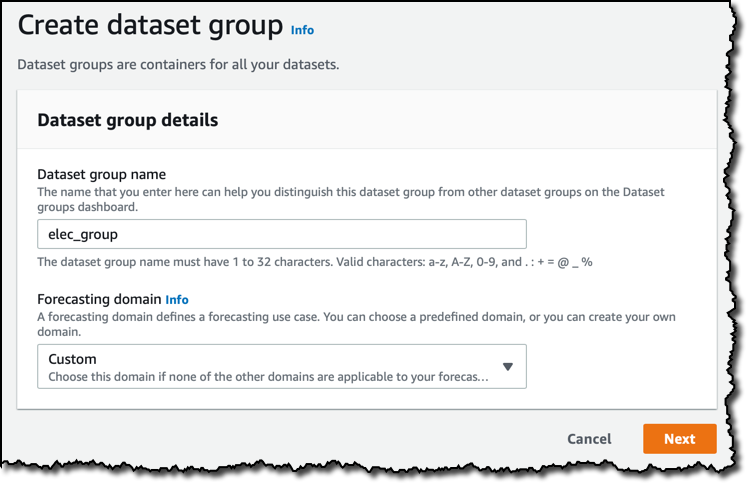
我可以为我的数据集组选择一个预测域。每个域都涵盖一个特定的用例,例如零售、库存计划或网络流量,并根据用于训练的数据类型提供自己的数据集类型。目前,我使用涵盖不属于其他类别的所有用例的自定义域。
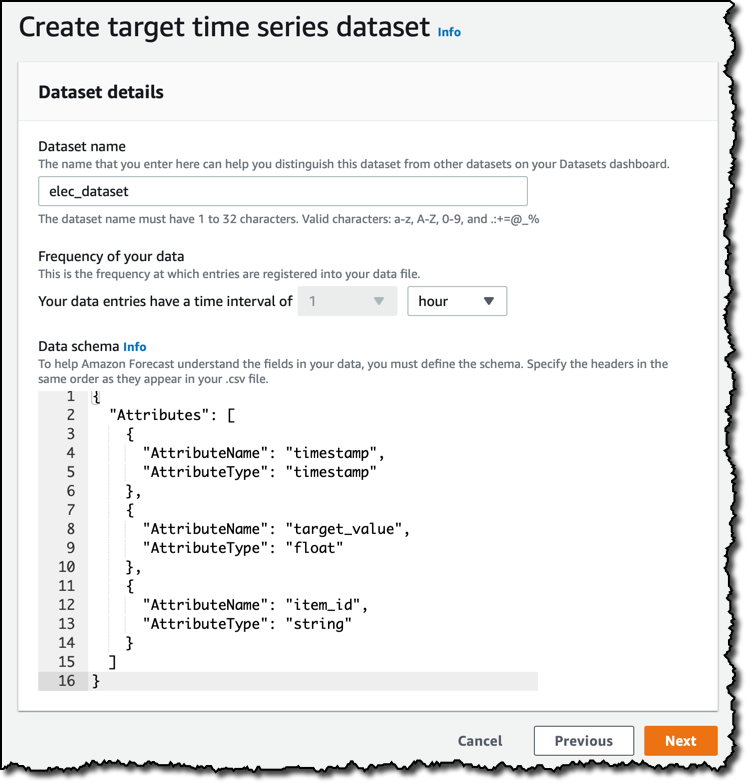
下一步,我要创建一个数据集。我要上传的数据按小时汇总,因此我的数据频率为 1 小时。默认数据架构取决于我之前选择的预测域。 我在这里使用自定义域,并将数据架构更改为具有一个 timestamp、一个 target_value 和一个 item_id,与您在本文开头看到的数行示例数据的结构相同。
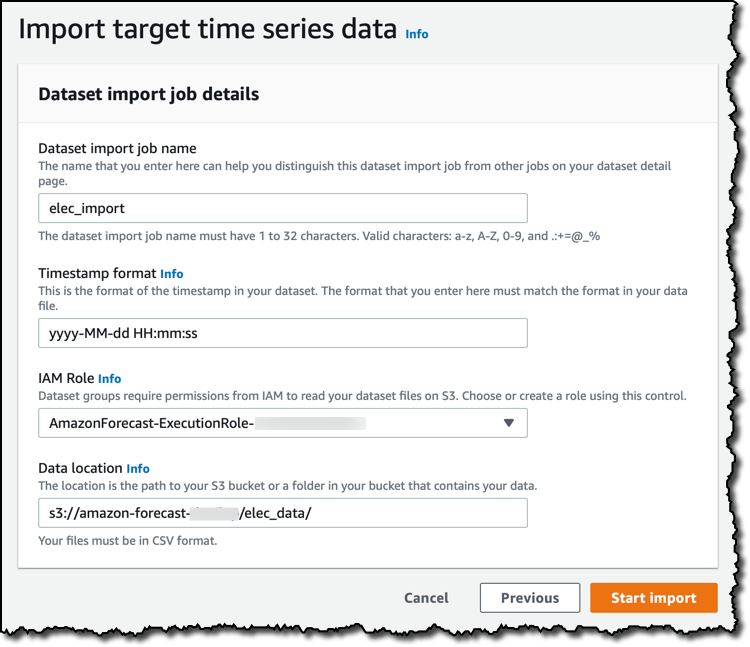
现在是时候将我的时间序列数据从 Amazon Simple Storage Service (S3) 上传到我的数据集了。我在数据中就使用默认时间戳格式,所以不需要更改。我需要一个 AWS Identity and Access Management (IAM) 角色来赋予 Amazon Forecast 对于 S3 存储桶的访问权限。我可以在这里选择一个,或者为此用例创建一个新的。一如以往,避免创建过于宽松的 IAM 角色并应用最低权限方法将权限限制为此活动所需的最低程度。在告诉 Amazon Forecast 要在哪个 S3 存储桶和文件夹中查找我的历史数据后,我启动了导入作业。
数据集组仪表板给出了该过程的概览。我的目标时间序列数据正在导入,我可以选择添加:
- 关于我想要预测的项目的项目元数据信息;例如零售场景中项目的颜色,或者这种以电力为中心的用例的家庭类型(是公寓还是独立式住宅?)。
- 可以帮助改进我的模型的,但不包含我想要预测的目标变量的相关时间序列数据;例如电子商务公司提供的价格和促销可能与实际销售有关。

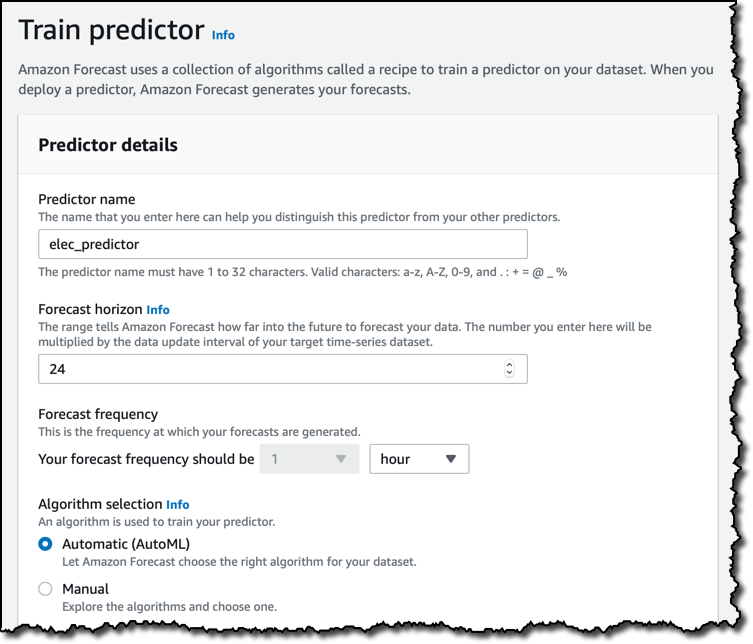
我不会为这个用例添加更多数据。数据集一旦导入,我就开始训练可以用来生成预测的预测工具。我给预测工具命名,然后选择预测范围(在我的示例中是 24 小时),以及生成预测的频率。
为了训练预测工具,我可以选择特定的机器学习算法,例如 ARIMA 或 DeepAR+,但我想更简单一点,所以使用 AutoML 让 Amazon Forecast 评估所有算法并选择对于我的数据集表现最佳的算法。
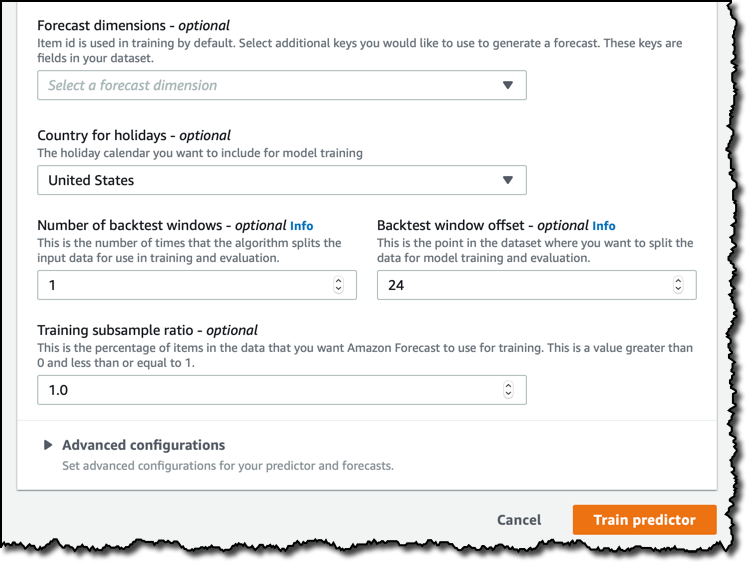
在我的数据集中,每个家庭都以一个变量 item_id 标识,但如果需要,您可以添加更多维度。然后,我可以选择国家/地区以确定节假日。这是可选的,但是如果您使用的数据可能受居民是否休假的影响,设置该项可以改进结果。我认为节假日的能源使用量会有变化,所以我选择美国,即我数据集的来源国。
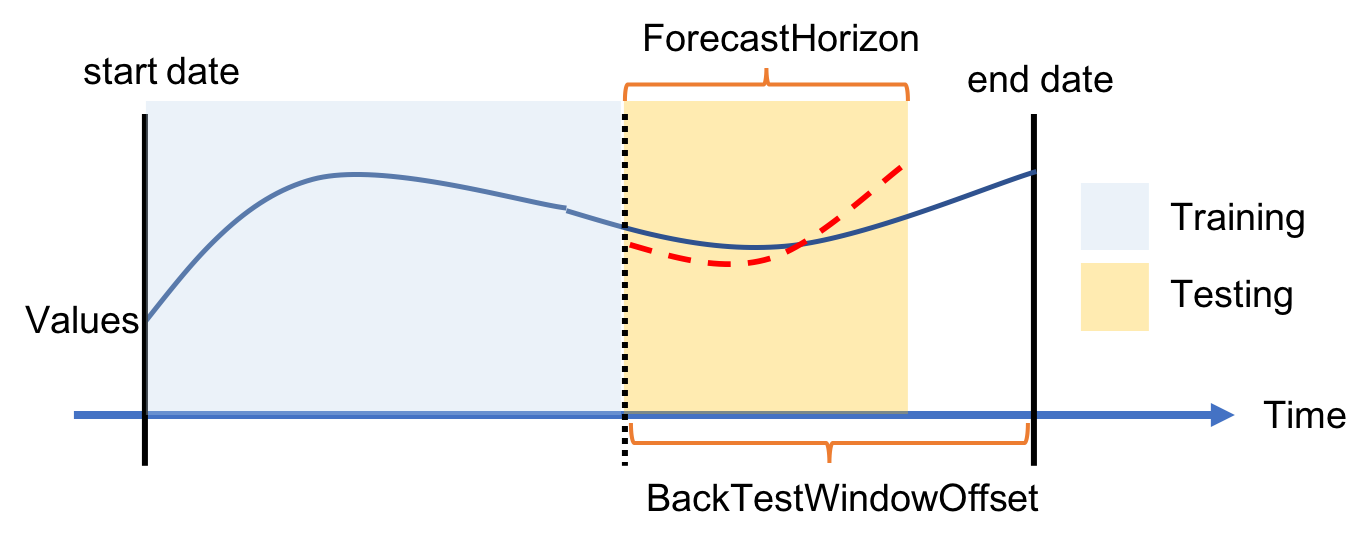
回测窗口的配置是一个更高阶的主题,如果您对于使用时间序列数据情况下评估机器学习模型的细节不感兴趣,可以跳过下一段。在本示例中,我将保留默认设置。
在训练机器学习模型时,您需要将数据集分为两部分:用于训练机器学习算法的训练数据集,以及用于评估训练后模型性能的评估数据集。对于时间序列,不能像往常那样随机创建这两个数据子集,因为数据点的顺序很重要。我们用于 Amazon Forecast 的方法是将时间序列分成一个或多个部分,每个部分称为一个回测窗口,保留数据的顺序。当您根据回测窗口评估模型时,应始终使用相同长度的评估数据集,否则将很难比较不同的结果。 回测窗口偏移量表明在要用于评估的分割点之前有多少数据点,此值应用于所有分割。例如,24(小时)表示我总是使用一天的数据来根据多窗口偏移评估我的模型。
在高级配置中,我可以选择为支持的算法启用超参数优化 (HPO),以及特性化,以开发使用数据计算得出的其他特征。我现在不修改这些设置。
几分钟后,预测工具进入活动状态。要了解预测工具的质量,我会查看一些自动计算的指标。

分位数损失 (QL) 计算某个分位数的预测离实际需求的差距。其根据具体的分位数为低估和高估分配权重。例如,经校准的 P90 预测意味着 90% 的时间是真实需求低于预测值。因此,当需求高于预测时,损失将大于预测高于需求的情况。
当预测工具准备就绪,并且我对其指标感到满意时,我可以使用它来创建预测。

当预测处于活动状态时,我可以查询它以获得预测结果。我可以将整个预测导出为 CSV 文件,或查询特定查找。我们来试试查找。对于我使用的数据集,我可以预测一个家庭在特定的时间段内使用的电量。这里的日期是过去的,因为我使用了一个旧的数据集。您肯定会使用 Amazon Forecast 来一窥未来的。

对于预测中的每个时间戳,我得到一系列值。P10、P50 和 P90 预测分别有 10%、50% 和 90% 的概率满足实际需求。如何使用这三个值取决于您的用例及其受到高估或低估需求的影响方式。P50 预测是对需求的最可能估计。P10 和 P90 预测为期望结果提供了 80% 的置信区间。

现已推出
您可以使用控制台、AWS 命令行界面 (CLI) 和 AWS 开发工具包使用 Amazon Forecast。例如,您可以利用适用于 Python 的 AWS 开发工具包,使用 Jupyter 笔记本中的 Amazon Forecast 来创建新的预测工具,或者在浏览器中使用适用于 JavaScript 的 AWS 开发工具包从 Web 或移动应用程序获得预测,又或者使用适用于 Java 的 AWS 开发工具包或适用于 .NET 的 AWS 开发工具包向已有的企业应用程序添加预测功能。
下面就是 Amazon Forecast API 从创建数据集组到查询和获取预测的总体流程图:

此过程中我所使用的数据集以及其他示例皆可从此 GitHub 存储库获取:
Amazon Forecast 现已在美国东部(弗吉尼亚北部)、美国西部(俄勒冈)、美国东部(俄亥俄)、欧洲(爱尔兰)、亚太地区(新加坡)和亚太地区(东京)推出。
有关具体功能和定价的信息,请点击下方链接:
我期待了解这一工具在您手中能派上哪些用场,请务必与我分享您的使用结果!
– Danilo