亚马逊AWS官方博客
AWS Clean Rooms 推出用于机器学习模型训练的隐私增强型合成数据集生成功能
今日,我们宣布 AWS Clean Rooms 推出隐私增强型合成数据集生成功能。这是一项新功能,组织及其合作伙伴可以使用该功能,通过其集合数据生成隐私增强型合成数据集,用于训练回归和分类类型的机器学习(ML)模型。您可以使用此功能生成的合成训练数据集,以保留原始数据的统计模式,同时让模型无法访问原始记录,这为以往因隐私顾虑而难以实现的模型训练开辟了新的机会。
在构建机器学习模型时,数据科学家和分析师往往会面临数据可用性与隐私保护之间的根本矛盾。访问高质量、细粒度的数据是训练可以识别趋势、实现个性化体验并推动业务成果的准确模型的关键。但是,使用来自多方的细粒度数据(如用户级事件数据)会引发严重的隐私担忧和合规挑战。组织想要回答诸如“哪些特征能预示高概率的客户转化?”之类的问题,但基于个体级信号进行训练往往会与隐私政策和监管要求相冲突。
为自定义 ML 生成隐私增强型合成数据集
为应对这一挑战,我们在 AWS Clean Rooms ML 中引入了隐私增强型合成数据集生成功能,组织可以通过该功能创建敏感数据集的合成版本,可以更安全地用于 ML 模型训练。此功能采用先进的 ML 技术,以生成保留原始数据统计特性、同时对原始数据来源中的主体进行去标识化处理的新数据集。
传统匿名化技术(如数据掩蔽)仍然存在数据集个体重识别风险,例如,仅通过邮政编码和出生日期等属性,结合人口普查数据即可识别出具体个人。隐私增强型合成数据集生成则通过完全不同的思路来应对这一风险。系统训练一个模型,该模型会学习原始数据集的核心统计模式,再通过从原始数据中采样值并利用模型预测目标值列来生成合成记录。该系统并非简单复制或干扰原始数据,而是采用模型容量缩减技术,降低模型记忆训练数据中个体信息的风险。生成的合成数据集具有与原始数据相同的架构和统计特征,适用于训练分类和回归模型。这种方法可以量化地降低重新识别的风险。
使用此功能的组织可以自主控制隐私参数,包括施加的噪声量、抵御成员推理攻击的防护等级(攻击者试图通过此类攻击判断特定个体的数据是否包含在训练集中)。生成合成数据集后,AWS Clean Rooms 会提供详细指标,以帮助客户及其合规团队从两个关键维度评估合成数据集质量:与原始数据的一致性(保真度)和隐私保护效果。其中,保真度分数通过 KL 散度衡量合成数据与原始数据的相似度,隐私分数则可以量化数据集抵御成员推理攻击的能力。
在 AWS Clean Rooms 中处理合成数据
隐私增强型合成数据集生成功能的使用遵循既定的 AWS Clean Rooms ML 自定义模型工作流程,其中包含指定隐私要求和审查质量指标的新步骤。组织先使用偏好的数据来源创建带分析规则的配置表,随后与合作伙伴建立协作(或加入现有协作),并将配置表与该协作关联。
新功能引入了增强的分析模板,数据所有者不仅可以在其中定义创建数据集的 SQL 查询,还可以指定结果数据集为合成类型。在模板中,组织可以对列进行分类,以指明 ML 模型的预测目标列、分类值列和数值型列。至关重要的是,该模板还包括隐私阈值,生成的合成数据必须达到这些阈值才能用于训练。其中包括指定合成数据中需包含的 epsilon 值(用于防范重识别)以及抵御成员推理攻击的最低防护分数。要适当设置这些阈值,需要结合组织具体的隐私合规要求,建议在此过程中咨询法律和合规团队。
在所有数据所有者审阅并批准分析模板后,协作成员会创建一个引用该模板的机器学习输入通道。然后,AWS Clean Rooms 将开始合成数据集生成流程,此流程通常可在几小时内完成,具体取决于数据集大小和复杂度。如果生成的合成数据集满足分析模板中定义的所需隐私阈值,则合成机器学习输入通道以及详细的质量指标便可用。数据科学家可以查看在模拟成员资格推断攻击中获得的实际保护分数。
对质量指标感到满意后,组织可以继续使用 AWS Clean Rooms 协作中的合成数据集来训练其 ML 模型。根据使用案例,他们可以导出经过训练的模型权重,也可以继续在协作环境本身运行推理作业。
操作演示
在创建新的 AWS Clean Rooms 协作时,我现在可以设置合成数据集生成的付款方。
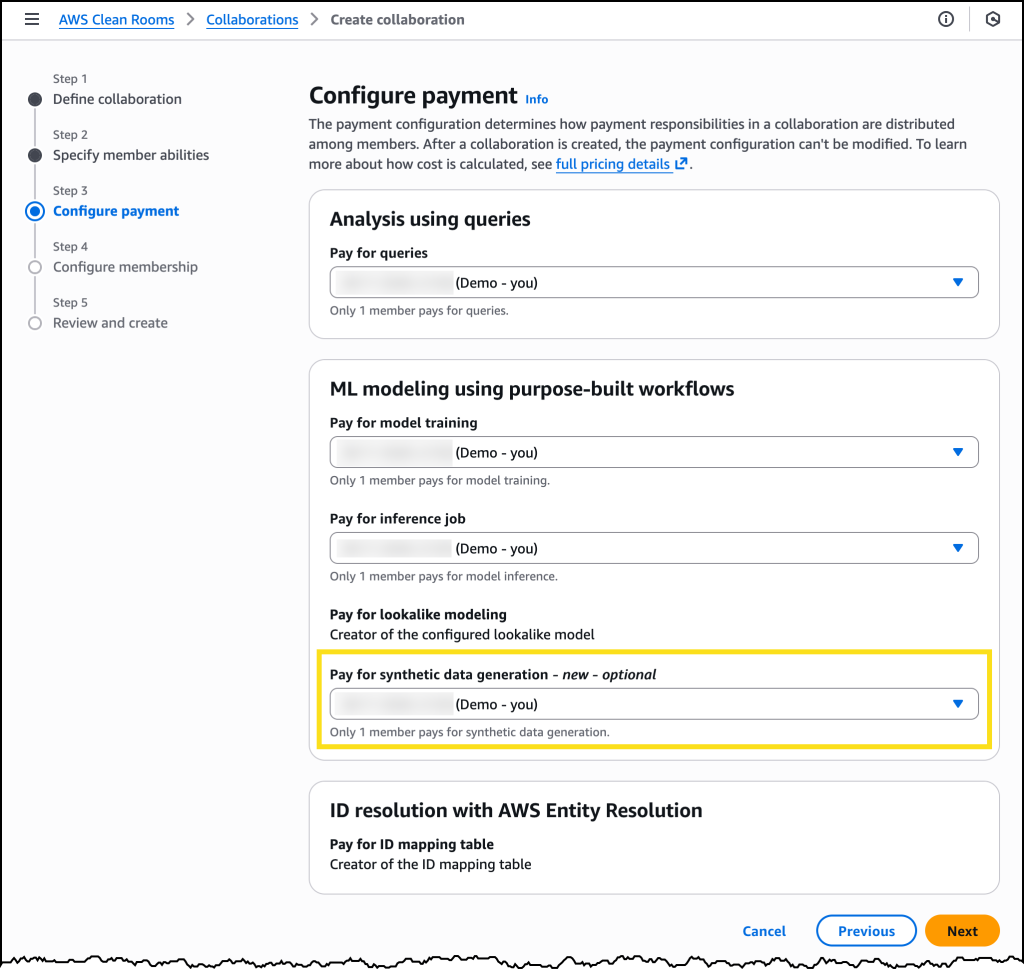
配置好协作后,我可以在创建新的分析模板时选择要求分析模板输出合成。
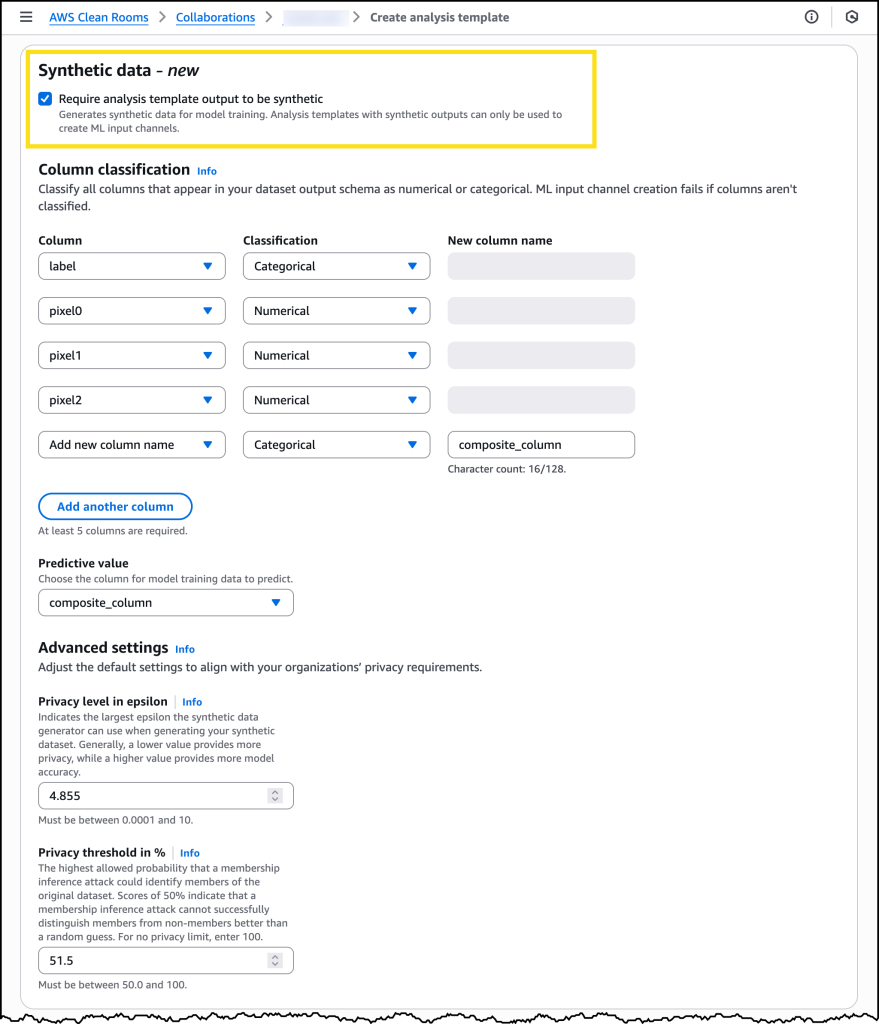
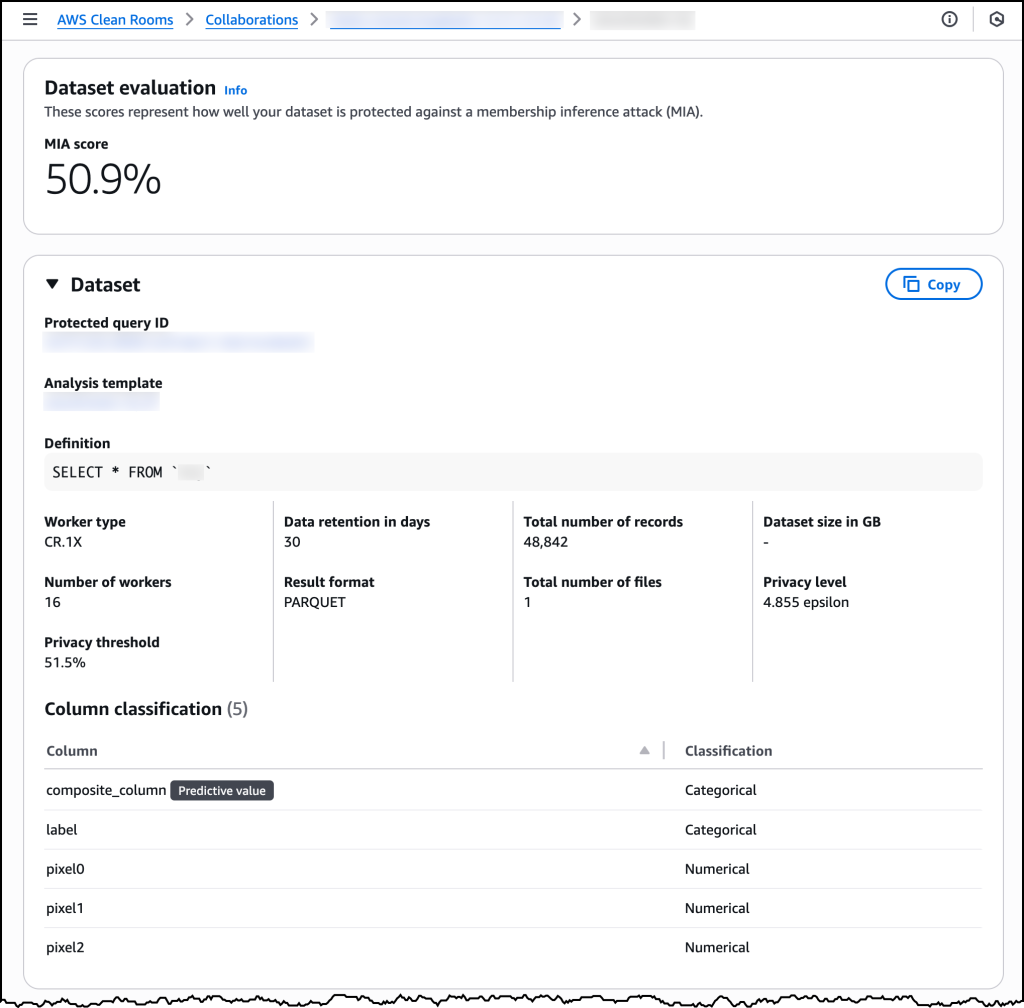
合成分析模板准备就绪后,我可以在运行受保护的查询时使用它并查看所有相关机器学习输入通道的详细信息。
现已推出
您可以立即开始通过 AWS Clean Rooms 生成隐私增强型合成数据集。该功能已在所有提供 AWS Clean Rooms 服务的商业 AWS 区域推出。有关更多信息,请参阅 AWS Clean Rooms 文档。
隐私增强型合成数据集生成功能按使用量单独计费。您只需生成合成数据集所消耗的计算资源付费,计费单位为合成数据生成单元(SDGU)。SDGU 数量取决于原始数据集的大小和复杂度。此费用可通过付费人设置配置 ,这意味着任何协作成员都可以同意支付该费用。有关定价的更多信息,请参阅 AWS Clean Rooms 定价页面。
初始版本支持基于表格数据训练分类和回归模型。合成数据集可与标准 ML 框架兼容,无需修改工作流即可集成到现有的模型开发管道中。
此功能代表了增强隐私的机器学习领域的重大进步。组织可以释放敏感用户级数据的模型训练价值,同时降低个人敏感信息泄露的风险。无论是优化广告活动、实现保险报价个性化,还是增强欺诈检测系统,隐私增强型合成数据集生成功能都能让您在尊重个体隐私的前提下,通过数据协作训练出更准确的模型。