亚马逊AWS官方博客
AWS DevOps Agent 实战:云网络故障自主调查与修复建议
摘要:混合云网络故障根因常散落在 CloudWatch、CloudTrail、VPC、TGW、DX、VIF 等多个控制面。本文在真实 Direct Connect 环境上用 6 个故障场景验证 AWS DevOps Agent:从告警 payload 自主解析上下文、关联多源证据、定位根因,并输出可接入 SRE 变更流程的 5 阶段 Mitigation Plan,把工程师从”跨控制台收集证据”解放出来。
目录
1. 引言
凌晨三点,值班工程师被一条业务投诉叫醒:某跨区域应用在两条 DX 路径上的流量出现了明显的不对称,eu-west-2 出口工作正常,eu-west-1 出口的 RTT 陡增、拥塞并导致部分流量丢失。工程师打开 AWS Management Console 排查:两条 AWS Direct Connect Connection 的 ConnectionState 均为 available,两个 vif 虚拟接口的 BGP status 均为 up;但 VirtualInterfaceBgpPrefixesAccepted 指标显示,eu-west-1 侧接收了 92 条明细路由,eu-west-2 侧只剩下 1 条默认路由。这是一种典型的 BGP 路由策略不对称故障 —— 基础连通性没有断,但流量被明细路由拉到了其中一条路径上。人工调查需要同时打开 Direct Connect 控制台、Amazon CloudWatch、AWS CloudTrail,并跨两个 Region 逐条对照 VIF 的指标与事件,耗时通常在 30 至 60 分钟之间。
另一类更隐蔽的故障发生在 AWS 控制平面。某次故障中,运维人员在 AWS Transit Gateway 路由表中添加了一条“指向远程机房”的静态路由,意在为某条内网网段指定专用出口。但这条路由的 next-hop attachment 其实连接到了一个对端 BGP 只通告 /32 管理地址的 Site-to-Site VPN,而非真正能到达远程机房的 Direct Connect Gateway。由于静态路由 /24 比 DXGW 传播的 0.0.0.0/0 更为明细,TGW 按最长前缀匹配将 VPC 发往远程机房的流量全部劫持到了这条 VPN,形成数据平面流量黑洞。VPC、TGW、attachment 的状态都健康,传统监控难以在分钟级定位根因。
AWS DevOps Agent 提供了一种基于 AI 的自动化事件调查机制。它通过 webhook 接收 CloudWatch 告警事件,使用一组只读的 AWS skill 自主调用 AWS API、Amazon CloudWatch、AWS CloudTrail 等服务,跨 Region 与跨服务收集相关数据,并生成包含时间线、证据链、根因假设与修复建议的 Investigation 报告。DevOps Agent 不对客户资源执行任何变更操作,修复动作由工程师评估后实施。
本文基于一套构建于真实 AWS Direct Connect 与 Transit Gateway 基础设施上的测试环境,通过 6 个 DX Connection、TGW 与 BGP 路由层面的故障场景观察 DevOps Agent 的调查过程。本文的重点不在于复现实验步骤,而在于展示 DevOps Agent 在以下几类能力上的实际表现:
- 从 CloudWatch 告警事件自主解析业务上下文,进入正确的调查方向
- 跨 Region、跨服务关联 CloudWatch 指标、CloudTrail 事件、以及 Direct Connect / TGW API 返回信息
- 基于历史基线与服务的 hard limit 给出前瞻性风险评估
- 在多个告警级联触发时识别共同根因,避免重复调查
- 针对数据缺失场景明确标注 Gap,而非生成猜测性结论
- 对控制平面误配置类故障(如 TGW 静态路由错配),除给出根因外还输出 runbook 级的 5 阶段修复方案,每步附带可直接执行的 AWS CLI 命令
本文还总结了 6 条可直接在生产环境落地的告警设计实践,并对齐 AWS Well-Architected Framework 的相关 Best Practice。
2. 测试环境
本文使用的测试环境构建于真实的 AWS Direct Connect 与 Transit Gateway 基础设施上,未使用模拟资源。原因是 Direct Connect 物理层的 BGP 协议行为、BFD 收敛时间、跨账号 VIF(账号 A 拥有物理 Connection,并在该 Connection 上创建 VIF 时将 owner 指定为账号 B,由账号 B 接受,即 hosted VIF 模型)下的 IAM 可见性边界、以及 TGW 路由表中静态路由覆盖 DXGW propagated 路由的最长前缀匹配行为,在模拟环境中无法完整复现。
测试环境分布在 AWS 的 3 个 Region。
欧洲部分(eu-west-1 / eu-west-2)用于 BGP 与 Connection 场景,关键组件包括:
- 2 台 on-premises router(Cisco,ASN 65000),通过 2 条 DX Connection 分别连接至 AWS 的 eu-west-1 与 eu-west-2
- 2 个 Transit VIF,分别位于 eu-west-1 与 eu-west-2,均配置 IPv4 BGP peer
- 一个 Direct Connect Gateway (DXGW),关联上述 2 个 Transit VIF 及测试账号内的 Transit Gateway
- 2 台 on-premises router 启用 Bidirectional Forwarding Detection(BFD),配置 interval 300 min_rx 300 multiplier 3,通过 BFD 可实现亚秒级的 BGP 故障检测
本测试采用 AWS Direct Connect 的跨账号 VIF 模型:物理 Connection 属于网络账号(账号 A),由账号 A 基于该 Connection 创建 VIF 并将 owner 指定为业务账号(账号 B),再由账号 B 在自己的账号中 accept。这也是企业生产环境中的常见部署形态 —— 物理端口通常由企业核心网络团队统一持有,VIF 最终归业务团队在自己的账号中管理与使用。
美国部分(us-east-1)用于 Transit Gateway 路由场景(T3),关键组件包括:
- 一个 production VPC(记为 VPC4),通过 TGW attachment 关联至 TGW-IAD
- TGW 路由表 TGW-IAD-Hybrid-RT,VPC4、Site-to-Site VPN 与 DXGW 的 attachment 均关联至此路由表
- DX Gateway attachment 向此路由表传播默认路由 0.0.0.0/0,用于访问远端机房 IDC
- Site-to-Site VPN attachment,对端 BGP 仅通告办公室(192.1.1.0/24)内的管理地址 192.1.1.1/32(不承载 IDC 网段)
- VPC4 内 1 台 EC2 探测实例(关联 EIP 以便通过 SSM 管理)以 systemd 服务常驻运行一个 ICMP 探测脚本,每 10 秒向 IDC 目标 192.168.58.10 发起一次探测,并将结果发布为 CloudWatch POC/Network::ICMPReachability 自定义指标
- 一条 Network-IDC-Unreachable-from-vpc4 CloudWatch 告警,评估 3 个连续 1 分钟窗口的 ICMPReachability < 1
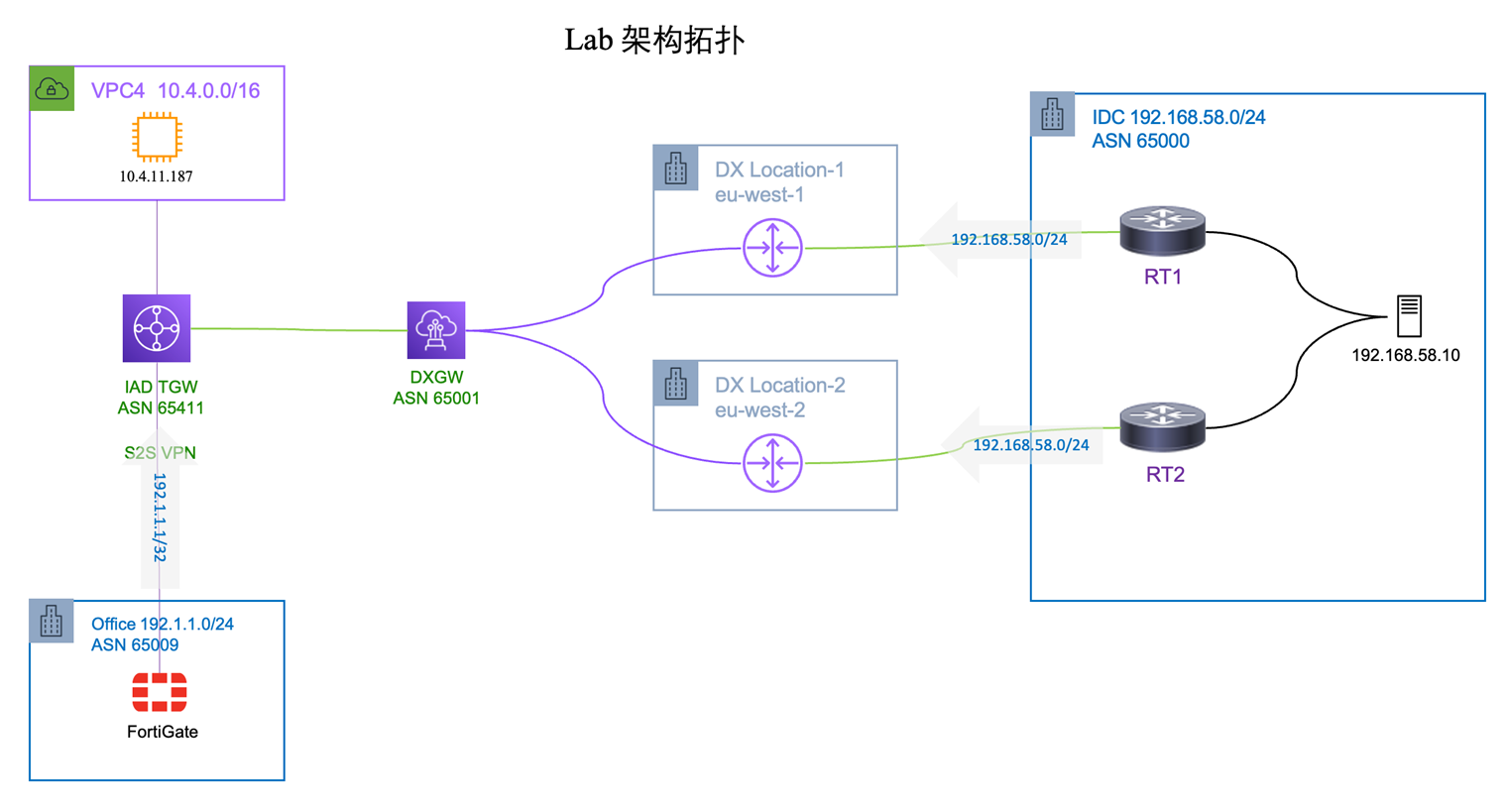
[图 1:Lab 架构拓扑] |
on-premises router(RT1 / RT2,ASN 65000)从 IDC 出发,通过 DX Location 1 / DX Location 2 接入 AWS 骨干网,2 条 Transit VIF 共同关联至 DXGW(ASN 65001),再连接到 us-east-1 的 IAD TGW(ASN 65411)与 VPC4(10.4.0.0/16);另有一条 Site-to-Site VPN 经 FortiGate Firewall 将办公室(Office 192.1.1.0/24,ASN 65009)接入 TGW。
整个测试环境包含 20 条 Amazon CloudWatch 告警(欧洲部分 19 条 DX/BGP 类告警 + 美国部分 1 条 TGW IDC 探测类告警)、4 个 AWS Lambda 函数、1 个 EC2 主动探测器、以及相应的 Amazon SNS topic 与 AWS Secrets Manager 资源。欧洲部分在 eu-west-1 与 eu-west-2 两个 Region 以相同架构部署,便于进行跨 Region 行为观察;美国部分独立部署于 us-east-1,验证 DevOps Agent 对 TGW 控制平面误配置类故障的调查能力。
3. CloudWatch 监控栈架构
监控栈分为两层:一层负责跨 Region 的 Prefix 对称性计算与账号级的全局配置;另一层为每个 Region 独立的告警、SNS topic、以及本地 Lambda,在 eu-west-1 与 eu-west-2 两个 Region 以相同架构部署。
下表按故障层级列出 11 个 CloudWatch 告警模板。每 Region 为每条 VIF 创建 5 条 BGP 告警、为每条 Connection 创建 4 条 Connection 告警,并在 DXGW 分组级别创建 1 条跨 Region 的 Prefix Asymmetry 告警;加上美国部分 1 条 Network 层面探测告警,本 Lab 一共创建了 20 条 CloudWatch 告警(欧洲部分 2 Region × 9 + 1 跨 Region Asymmetry = 19 条,美国部分 1 条)。
| 层级 | 告警名 | 触发条件 | 数据源命名空间 |
| BGP 层 | DX-BGP-Down-{vif}-ipv4 | Max < 1 持续 3 min | POC/DX |
| BGP 层 | DX-BGP-Flap-{vif}-ipv4 | Min < 1 出现 3/10 次 | POC/DX |
| BGP 层 | DX-BGP-Prefix-High-{vif}-ipv4 | ≥ 80 条 | AWS/DX |
| BGP 层 | DX-BGP-Prefix-Drop-Floor-{vif}-ipv4 | < 10 条持续 10 min | AWS/DX |
| BGP 层 | DX-BGP-Prefix-Drop-Partial-{vif}-ipv4 | < 50 条持续 10 min | AWS/DX |
| BGP 层 | DX-BGP-Prefix-Asymmetry-{dxgw}-ipv4 | ratio ≥ 10 持续 3 min | POC/DX |
| Connection 层 | DX-Conn-Down-{conn} | Max < 1 持续 1 min | AWS/DX |
| Connection 层 | DX-Conn-Flap-{conn} | Min < 1 出现 2/10 次 | AWS/DX |
| Connection 层 | DX-Conn-Errors-{conn} | Sum > 100 持续 5 min | AWS/DX |
| Connection 层 | DX-LightRx-Low-{conn} | Avg < -14 dBm 持续 15 min | AWS/DX |
| Network 层面 | Network-IDC-Unreachable-from-vpc4 | 连续 3 个 1-min 窗口 ICMPReachability < 1 | POC/Network |
Network 层面的告警并不来自 AWS 原生服务指标,而是来自 VPC 内部一台 EC2 实例主动发出的 ICMP 探测。这一设计可以覆盖 AWS 指标盲区:当 TGW 路由表、DX Connection 状态、BGP session 均显示健康,但数据平面因路由决策异常导致业务流量被丢弃时,只有端到端的主动探测才能感知到故障。关于这一设计的权衡参考 AWS Well-Architected REL11-BP01(在所有层级部署故障检测)。
每条告警的 AlarmDescription 字段包含结构化的业务上下文,DevOps Agent 在接收 webhook 时会优先解析此字段以确定事件与故障的调查范围。以 Prefix Asymmetry 告警为例,其配置如下:
4. AWS DevOps Agent 的集成方式
AWS DevOps Agent 通过 Agent Space 控制台以 webhook 形式与外部告警系统集成。在本测试环境中,CloudWatch 告警经由 Amazon SNS 触发一个 Lambda 桥接函数,该函数对告警 payload 执行 HMAC-SHA256 签名后调用 Agent webhook 启动 Investigation。整条链路从告警触发至 Investigation 开启的延迟低于 5 秒钟。
AWS DevOps Agent 使用的所有 skill 均为只读操作。修复建议以结构化文本形式呈现在 Investigation 报告中,不会对客户资源执行任何新增、更新或删除等写操作。
信任边界:AWS DevOps Agent 的输出形态是一份调查报告,不是一个可执行的修复动作。报告包含根因假设、证据链、以及推荐的修复命令,但 Agent 本身不会执行 aws ec2 authorize-security-group-ingress、aws directconnect update-virtual-interface-attributes 等修改类 API。在生产环境引入自动化工具时,建议保留这一设计原则。
5. 告警管道:从故障到 Investigation
从故障发生到 DevOps Agent 产出 Investigation 报告,完整链路如图 2 所示:
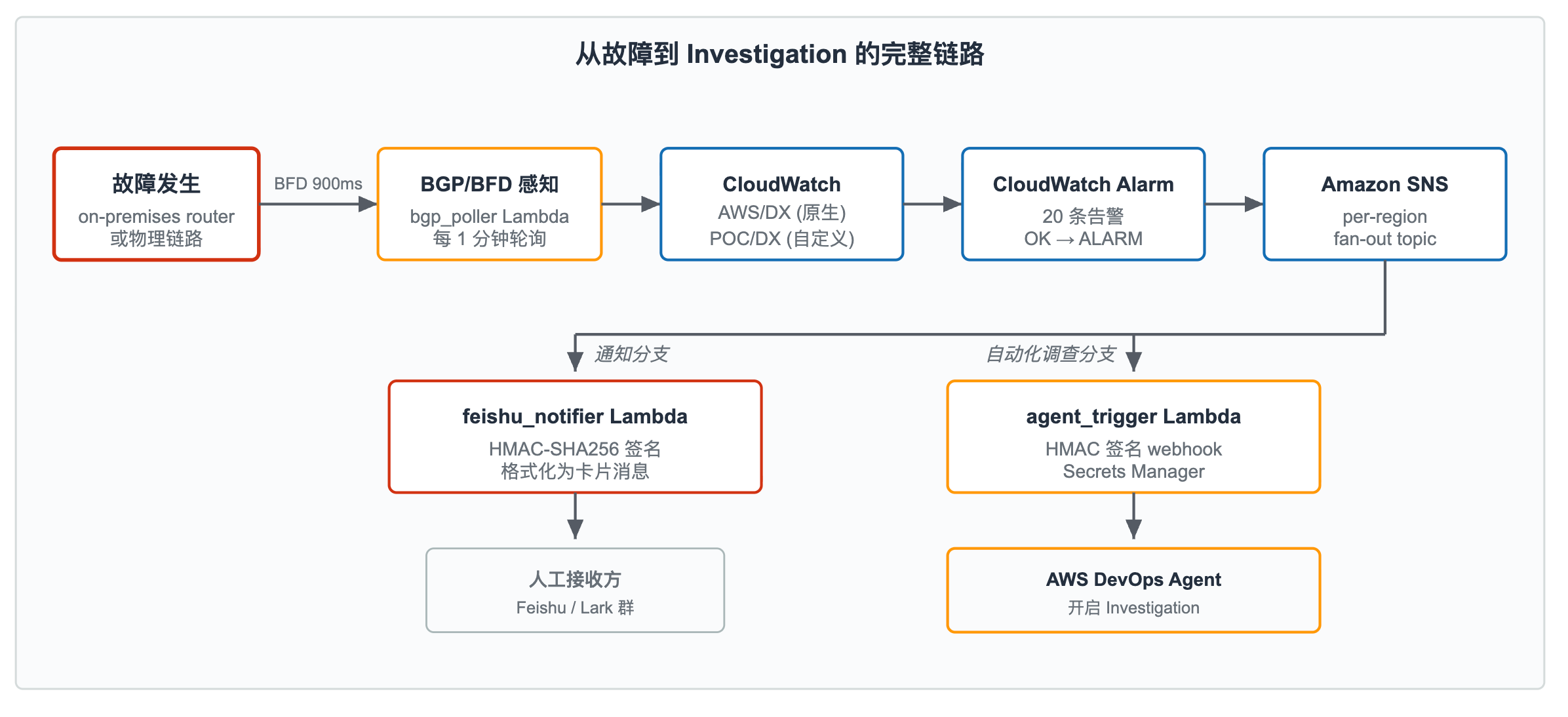
[图 2:告警管道] |
故障经 BFD / BGP 感知触发指标采集,由 Amazon CloudWatch 评估告警后经 Amazon SNS 分发至两个 AWS Lambda:一个推送通知至 Feishu,另一个调用 AWS DevOps Agent webhook 启动 Investigation。
链路中的一个关键技术点是 BGP 状态指标的采集粒度。AWS 原生命名空间 AWS/DX 下的 VirtualInterfaceBgpStatus 指标以 5 分钟为周期发布,这一粒度对于需要秒级响应的故障场景偏慢。为此,本 Lab 在每个 Region 部署一个 bgp_poller.py Lambda,以 1 分钟为周期调用 DescribeVirtualInterfaces API,解析 BGP peer 状态后发布至自定义命名空间 POC/DX。
为什么是 1 分钟,而不是亚秒级轮询:虽然客户侧 BFD 已经可以在 ≈900ms 内感知到 BGP session 终止,但 DescribeVirtualInterfaces 返回的是 AWS 侧观测到的 peer 状态,客户侧的 BFD 事件到 AWS 控制平面更新 bgpStatus 字段之间存在秒级到十几秒的内部同步延迟。轮询频率超过“AWS 内部状态更新频率”后,多出来的调用只是在读取同一个值,并不会加速指标变化。再加上本 Lab 用 EventBridge rule(rate(1 minute))触发 bgp_poller Lambda、EventBridge 最小调度粒度为 1 分钟、CloudWatch 标准分辨率指标为 1 分钟、Direct Connect API 共享的 throttle 限制等现实约束,1 分钟在本 Lab 中是成本与精度的平衡点。如需进一步压缩延迟,更有效的方向是将告警评估周期从 3 个缩短到 1-2 个,或在客户侧将 BGP state change 事件以 syslog 形式直接推送至 CloudWatch Logs,而不是盲目提高轮询频率。
核心采集逻辑示意如下(仅展示主流程,省略错误处理与权限配置):
整条链路的延迟可按顺序拆解:on-premises router 启用 BFD (interval 300ms × multiplier 3) 后,BGP session 本地收敛时间 ≈ 900ms,属于亚秒级;bgp_poller Lambda 每 1 分钟触发一次,平均延迟 30s;CloudWatch 告警基于 VirtualInterfaceBgpStatus < 1 持续 3 个评估周期(为规避瞬时抖动)评估,需要 3 × 60s = 180s。三者相加,从 on-premises 侧 BGP Down 到告警触发的端到端延迟稳定在约 210-240 秒(即 3.5 至 4 分钟)。如果将告警评估周期缩短为 1 个周期,则端到端延迟可降至 90-120 秒;但实际部署中不建议这样做,容易被 BGP 正常收敛过程中的瞬时抖动误触发。
6. 6 个测试场景概览
本次测试覆盖 BGP、Connection 与 Transit Gateway 三层的 6 个典型故障场景。每个场景通过在 on-premises router 或 AWS 控制平面注入真实故障来触发告警,并完整执行 CloudWatch Alarm → Lambda → DevOps Agent → Investigation 的端到端链路。
| ID | 场景 | 故障注入方法 | 告警触发延迟 | 本文深度展开 |
| T1 | BGP Prefix High | on-premises router 新增 90 条 network 通告 | 5 分钟 | ✓ 深度场景一 |
| T2 | BGP Prefix Asymmetry(跨 Region) | route-map 使一侧 VIF 仅通告默认路由 | 4 分钟 | ✓ 深度场景二 |
| T3 | TGW 静态路由错配 → IDC 黑洞 | TGW 路由表为 IDC CIDR 增加一条指向 S2S VPN attachment 的静态路由 | 3-4 分钟 | ✓ 深度场景三 |
| T4 | BGP Down | on-premises router neighbor X shutdown | 3-4 分钟 | — |
| T5 | BGP Prefix Drop | 撤销 outbound route-map | 10 分钟 | — |
| T6 | Connection Down | on-premises router int Gi0/0/2 shutdown | 2-3 分钟 | — |
本文深度展开其中三个场景:
- 深度场景一(T1 – BGP Prefix High)展示 DevOps Agent 对 BGP 路由策略异常的识别与主动风险预测能力。
- 深度场景二(T2 – BGP Prefix Asymmetry)展示 DevOps Agent 跨 Region 与跨服务的数据关联分析能力。
- 深度场景三(T3 – TGW 静态路由错配导致 IDC 流量黑洞)展示 DevOps Agent 对控制平面误配置类故障的根因定位与 runbook 级 5 阶段修复建议能力。
其余场景(T4、T5、T6)的测试结论与上述深度场景趋势一致,因篇幅所限不单独展开。
7. 深度场景一:BGP Prefix 数量异常上涨(T1)
在 BGP 路由策略异常的场景中,接收前缀数量异常上涨是一种典型的高风险信号。AWS Direct Connect 的 Private 与 Transit VIF 对单一 BGP peer 接收的 IPv4 前缀数量存在 100 条的硬限制(Public VIF 为 1000 条)。若接收数量超过上限,AWS 将强制 reset BGP session,导致整条 VIF 的业务流量中断。在实际运维中,这一故障通常由 on-premises 侧的 route-map 配置错误、redistribute 策略调整、或跨网段扩展过程中未经评审的通告触发。及时检测并干预是避免业务中断的关键。
7.1 故障注入
在 on-premises router 上增加 90 条 IPv4 明细路由通告。为了简化演示,Lab 使用 172.18.1.0/24 至 172.18.90.0/24 的连续网段:
配置生效后,eu-west-1 VIF 的 VirtualInterfaceBgpPrefixesAccepted 指标从基线 2 条快速上涨至 92 条,BGP session 保持 up,Connection 保持 available。整条 VIF 的 Bps 指标仅有轻微上升(新增前缀不产生实际流量)。
7.2 指标曲线与告警阈值
告警 DX-BGP-Prefix-High-{vif}-ipv4 在接收前缀数达到 80 条时触发(eu-west-1 侧 VIF 实例化)。80 这一阈值距离 100 条硬限制留有约 20 条的预警余量,可为运维团队提供足够的处置时间。图 3 展示了本场景从故障注入到告警触发的指标曲线。
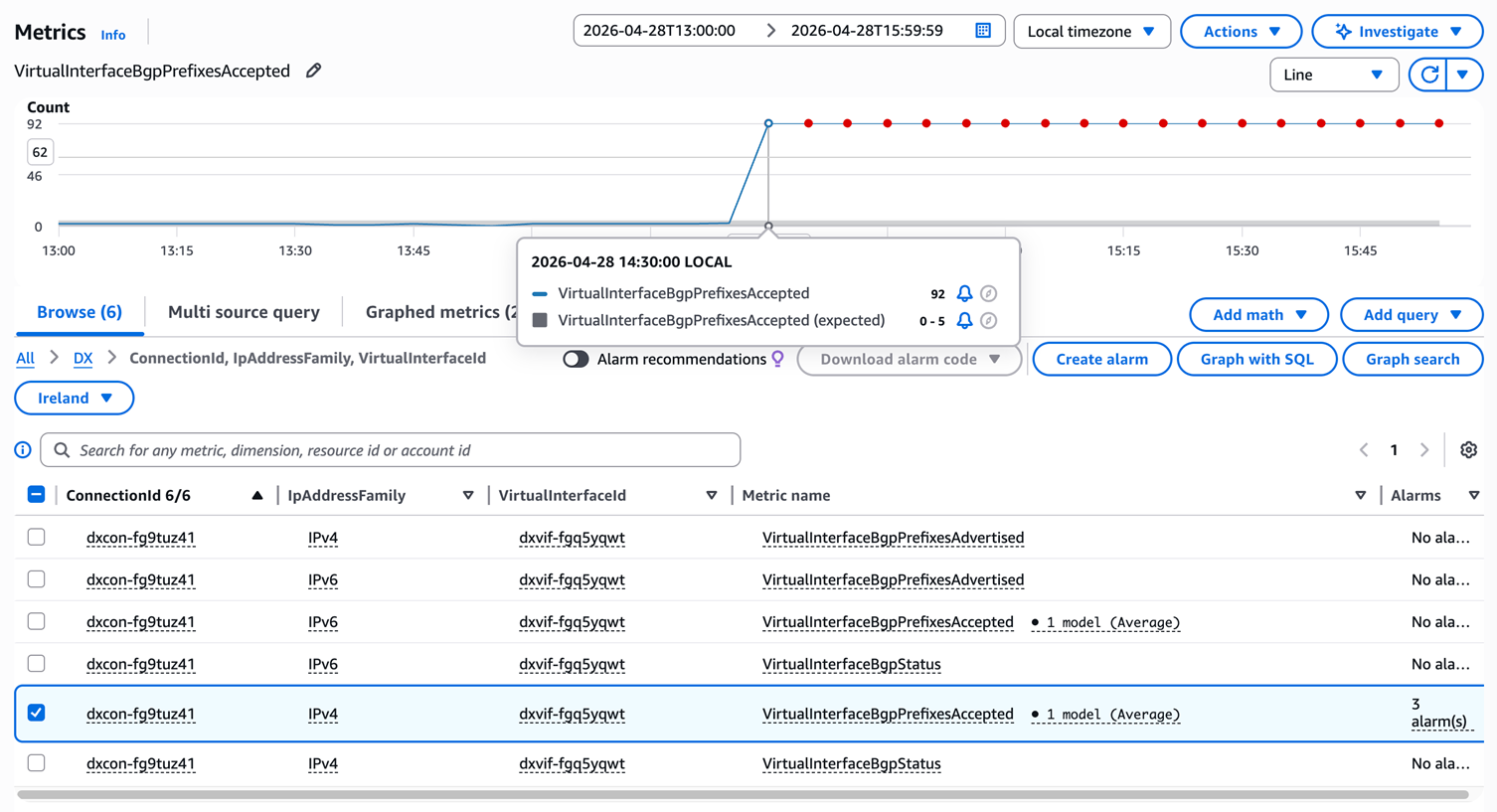
[图 3:BGP Prefix 数量异常上涨场景的 CloudWatch 指标曲线截图] |
PrefixesAccepted(on-premises 推送给 AWS 的前缀数)阶跃式上涨至 92 条后,距离 100 条硬限制仅 8 条余量。
7.3 DevOps Agent Investigation 过程
告警触发后约 5 秒,DevOps Agent 开启 Investigation,整个调查过程约 4 分钟完成。DevOps Agent Space 控制台为每次 Investigation 提供 Timeline、Root cause、Mitigation plan 三个 tab。下面依次截取三个 tab 中最能体现 Agent 能力的片段。

[图 4:Investigation Timeline] |
Agent 自主分解调查步骤,按顺序调用 CloudWatch、Direct Connect API 与 CloudTrail,逐步收敛证据。读者能看到 Agent 并行拉取 PrefixesAccepted 与 PrefixesAdvertised 两条指标做来源判定(AWS 侧 vs. on-premises 侧),以及单独针对故障时间点前后 30 分钟执行了精确收敛的 CloudTrail 查询,用于排除 AWS 侧配置变更。
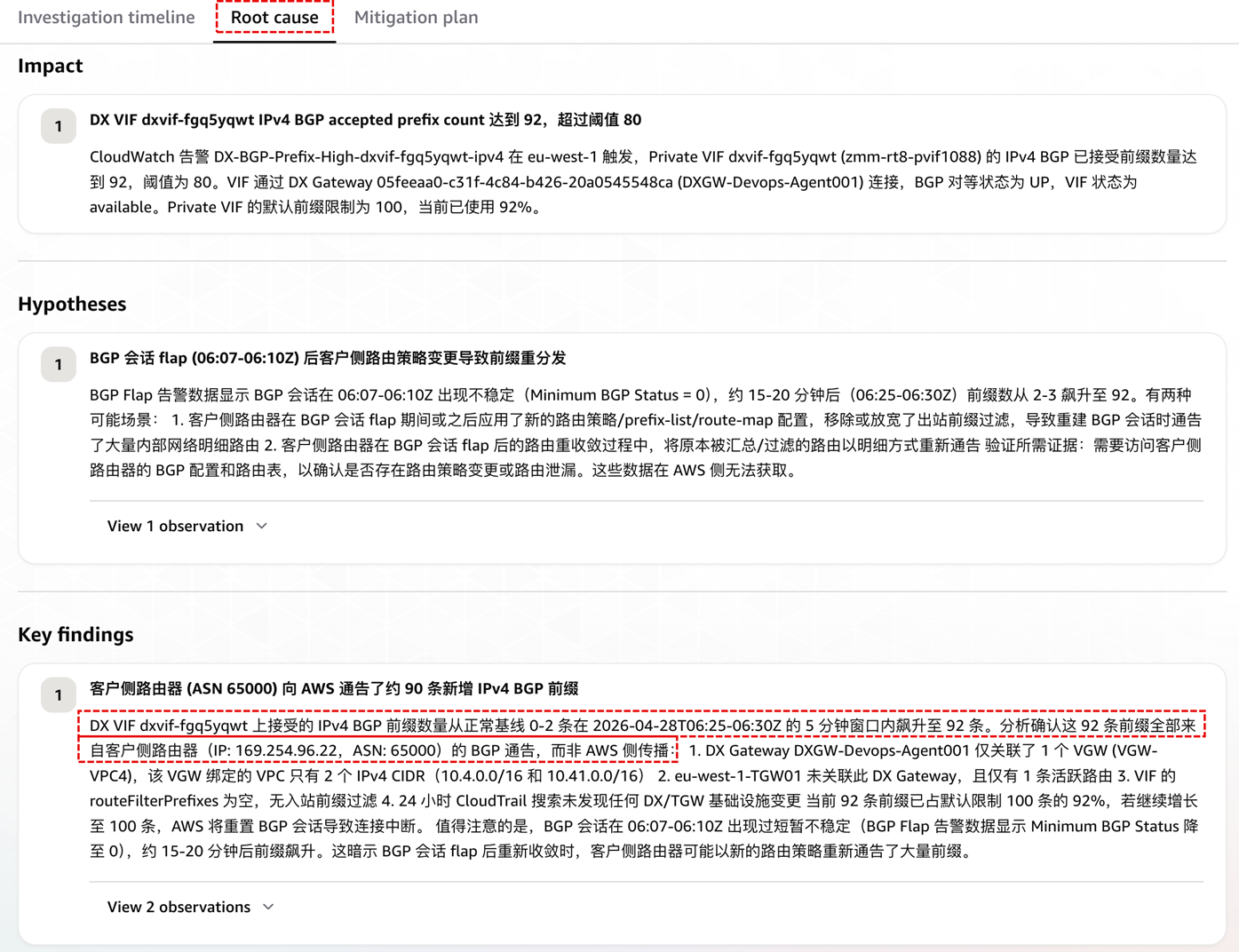
[图 5:Root cause 报告] |
Agent 把结论归属到 on-premises 侧 BGP 出站策略变更,并同时给出了一段前瞻性风险量化:“当前 92 条 / 距硬限制 8 条 / 若趋势不变将在 5 分钟内触发 BGP reset”。这一能力是传统告警工具不具备的 —— 后者只能回答“发生了什么”,Agent 进一步回答“如果不处理会变成什么”,这是决定事件严重度(P1 vs. P3)的关键输入。

[图 6:Mitigation plan] |
Agent 给出的不是一条命令,而是一组带判断条件的动作分支:先联系 on-premises 侧确认是否为预期业务变更;如非预期,回滚 route-map;如为预期业务扩展,评估前缀聚合或使用多个 vif 以缓解风险。这种“条件 → 动作”的结构把工程师的工作从“按命令执行”提升到“按上下文做决策”。
从告警触发到 Investigation 报告生成(含 Mitigation plan),本场景的端到端延迟约为 5-7 分钟。工程师拿到报告后的工作从“跨多个控制台收集证据”转变为“评估 Agent 提出的假设并做出决策”,MTTR 压缩明显。
8. 深度场景二:跨 Region Prefix 不对称(T2)
在企业生产环境中,“同一个 Direct Connect Gateway 关联的多条 VIF 之间接收到的 BGP 前缀数量出现显著差异”是一种典型的路由策略异构故障。根因通常不在网络设备本身,而在 on-premises router 的 BGP 出站路由策略 —— 某次配置变更后,一侧 VIF 继续推送完整的明细路由,另一侧只剩默认路由或汇总路由。由于默认路由仍然存在,基础连通性不受影响,业务流量可以继续传输;但 BGP 的最优路径选择会出现异常,MTU 黑洞、非对称路由、以及跨 Region 流量调度失衡等长尾问题会逐步显现。
8.1 故障注入
在 on-premises router 上配置 route-map,使面向 eu-west-2 VIF 的 neighbor 仅通告默认路由,eu-west-1 VIF 的 neighbor 保持原 92 条明细路由不变:
配置生效后,eu-west-2 VIF 的 VirtualInterfaceBgpPrefixesAccepted 指标从 92 降至 1,eu-west-1 VIF 保持 92。两条 VIF 的 BGP session 状态均为 up,Connection 状态均为 available。
8.2 原生告警的覆盖限制
这一场景无法通过单一 Region 内的标准告警覆盖。原因在于 Amazon CloudWatch 的一个结构性约束:一条 CloudWatch Alarm 只能评估一个 Metric Math 表达式的结果,且表达式内所有 Metric 必须来自同一个 Region。eu-west-1 的 VirtualInterfaceBgpPrefixesAccepted 与 eu-west-2 的同名指标无法放入同一条告警的 metric query 中进行比值运算。
本测试环境的方案是通过一个专用 Lambda 函数,以 1 分钟为周期跨 Region 拉取两侧的最新指标,在本地计算 ratio,并将结果作为新的自定义指标发布至 POC/DX 命名空间。基于此自定义指标的告警即可使用标准单 Region 阈值告警实现。核心逻辑示意如下:
基于此自定义指标的告警配置为 ratio ≥ 10 持续 3 分钟,此阈值可过滤 BGP 正常收敛过程中的瞬时抖动,同时在真实不对称发生时稳定触发。
8.3 DevOps Agent Investigation 过程
故障注入约 4 分钟后,DX-BGP-Prefix-Asymmetry-poc-dxgw-ipv4 告警进入 ALARM 状态,触发 DevOps Agent Investigation。下面依次截取 Timeline、Root cause、Mitigation plan 三个 tab 中最能体现 Agent 能力的片段。
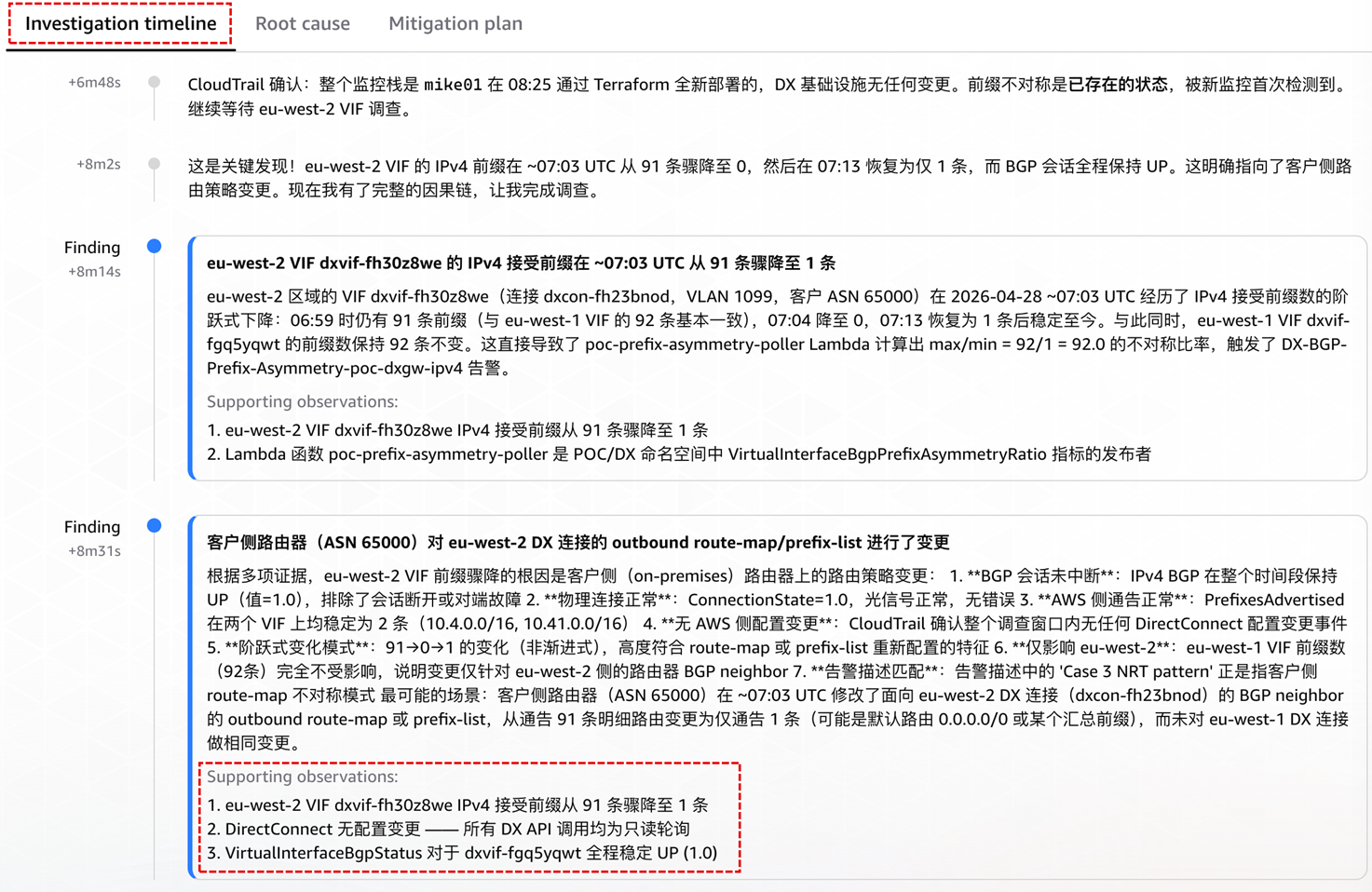
[图 7:Investigation Timeline ] |
本场景最能体现 Agent 的跨 Region 并行调查能力。Agent 同时对 eu-west-1 与 eu-west-2 两个 Region 发起 CloudWatch 查询,并将两侧历史基线回溯到 28 小时窗口对比,精确定位到 UTC 07:03 前后的阶跃下降时点(91 → 0 → 1,非线性衰减)。这种跨 Region 的横向关联在人工排查中需要在两个 Region 的控制台来回切换。
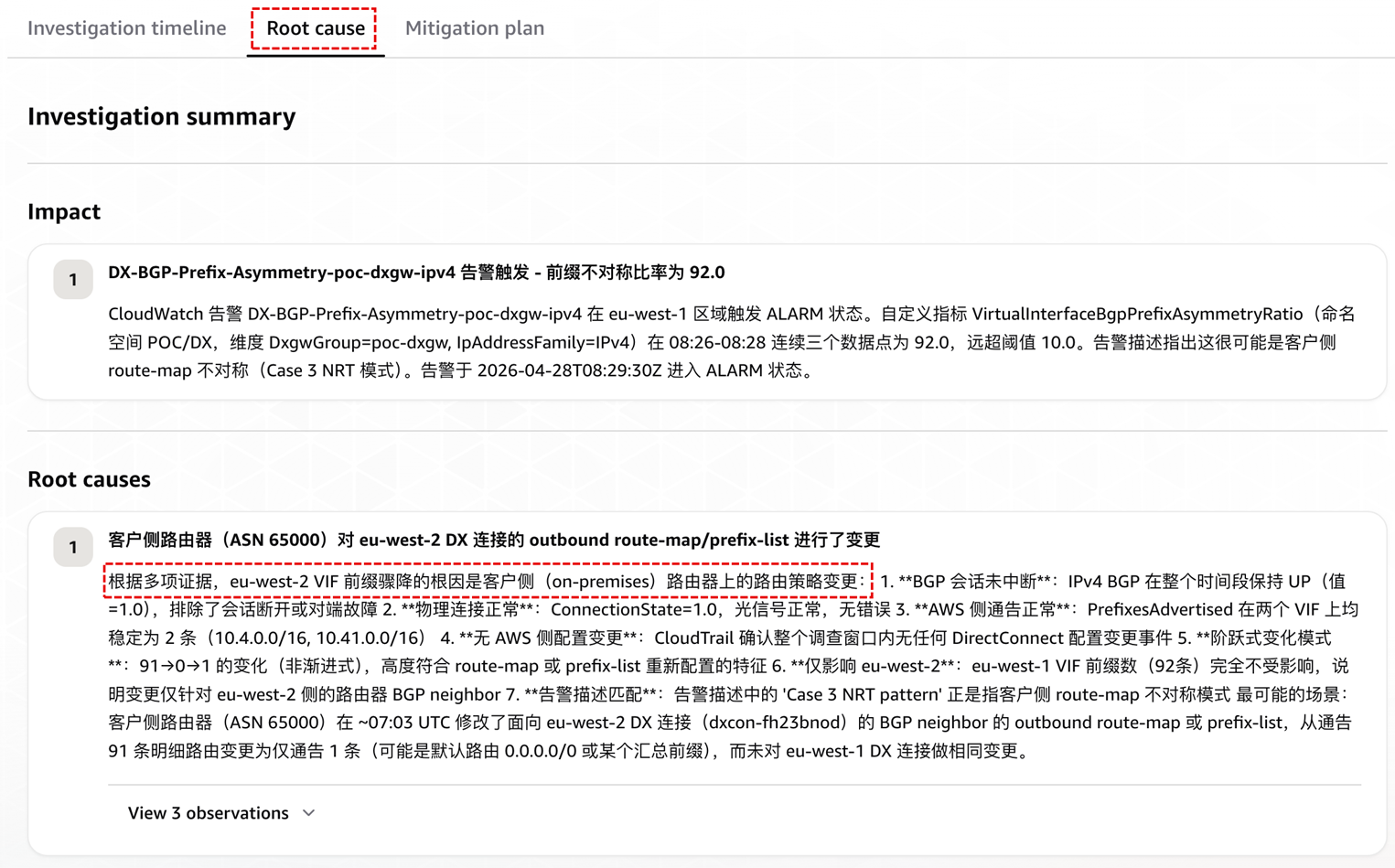
[图 8:Root cause 报告] |
Agent 得出的结论“eu-west-2 对端于 UTC 07:03 前后修改了 BGP 出站策略”由 4 条独立证据支持:两条 VIF 的 bgpStatus 全时段保持 up、Connection 状态正常、PrefixesAdvertised 在 AWS 侧稳定无变化、CloudTrail 在故障时点前后 30 分钟窗口内返回 0 条 mutative 事件。每一条证据都明确标注了数据来源与查询窗口,读者可以直接复核。

[图 9:Mitigation plan] |
由于根因明确在 on-premises 侧,AWS 侧无可执行动作,Agent 给出的建议聚焦在“如何与 on-premises 侧网络团队协同”:确认 eu-west-2 的策略变更是否为预期、如果意外则回滚 route-map、并建议在 DXGW 分组维度建立前缀对称性的例行巡检。
值得注意的是:Agent 在排除证据的环节并未使用宽泛的 LookupEvents,而是将 CloudTrail 查询窗口精确收敛至 UTC 07:03 前后 30 分钟,并过滤 directconnect.amazonaws.com 与 ec2:ModifyTransitGateway* 等相关事件源。这种查询收敛策略可以避免被 CloudTrail 中大量只读操作记录淹没,也为后续类似调查提供了可复用的模板。
从告警触发到 Investigation 报告生成(含 Mitigation plan),本场景的端到端延迟为 8 分 45 秒。
9. 深度场景三:TGW 静态路由错配导致 IDC 流量黑洞(T3)
前两个深度场景展示的是数据可观测性完整的故障形态:BGP 指标直接暴露异常信号,Agent 从指标出发即可快速收敛到根因。现实中还存在另一类更隐蔽的故障:控制平面配置错误导致数据平面流量黑洞,而所有 AWS 资源的状态指标均显示健康。本场景即属此类。
在 AWS Transit Gateway 中,路由表可以同时包含通过 DX Gateway 传播(propagated)的动态路由与运维人员手动创建的静态路由。当两者的目标 CIDR 存在覆盖时,TGW 按“前缀长度优先,长度相同时静态路由优先于动态路由”的规则选路。这意味着:一条无意中配置错误的 /24 静态路由,足以覆盖一整张由 0.0.0.0/0 传播的默认路由表,且不触发任何 AWS 服务级告警。
9.1 故障注入
测试场景设计如下:VPC4 通过 TGW-IAD 的 hybrid 路由表访问一台位于远端机房 IDC 的主机 192.168.58.10。该路由表从 DX Gateway attachment 接收 0.0.0.0/0 传播路由,VPC4 发出的流量按默认路由经 DXGW → DX 物理链路 → IDC。
通过以下单条 AWS CLI 命令注入故障:
这条命令在 VPC4 关联的 TGW 路由表中创建了一条静态路由 192.168.58.0/24 → Site-to-Site VPN attachment。由于 /24 比 DXGW 传播的 0.0.0.0/0 更为明细,按最长前缀匹配原则,VPC4 发往 IDC 的流量不再走 DX,而是被劫持至 VPN attachment。而 VPN 对端 BGP 只通告 192.1.1.1/32(供 VPN 建立与管理用,并不承载 IDC 网段),流量经 VPN 隧道到达 FortiGate 后因无匹配路由被丢弃,形成数据平面流量黑洞。

[图 10:TGW 最长前缀匹配覆盖 DXGW 传播路由] |
TGW 最长前缀匹配覆盖 DXGW 传播路由,导致 VPC4 去往 IDC 的流量被劫持至 VPN attachment 后丢弃。
9.2 为什么传统监控难以发现此类故障
故障注入后,观察 AWS 原生服务指标与资源状态:
- VPC4、DX Gateway 与 VPN Connection attachment 的 State 均为 available
- DX 侧 BGP session 保持 up,VirtualInterfaceBgpPrefixesAccepted 与基线一致
- VPN 侧 BGP session 保持 up,传播的 192.1.1.1/32 未变
- TGW BytesIn/Out 等流量指标呈正常波动,不足以单独作为报警信号
所有 AWS 服务级健康指标都通过检查。唯一能感知这类故障的方式,是在 VPC 内部署端到端主动探测:从 VPC4 的 EC2 实例每 10 秒向 IDC 192.168.58.10 发起 ICMP 探测,将结果作为 POC/Network::ICMPReachability 自定义指标发布。故障注入后,探测结果立即从 1.0 变为 0.0,3 个连续 1 分钟窗口后触发 Network-IDC-Unreachable-from-vpc4 告警。
设计原则:控制平面指标正常不等于数据平面流量可达。AWS 服务的状态指标、BGP session、路由表条目等都属于控制平面信号,它们只能回答“服务自身是否正常”,不能回答“服务之间的流量是否真正到达对端”。当路由决策错误、策略配置不一致、或发生 gray failure(部分链路质量下降但仍报告 healthy)时,控制平面可以全部健康、而数据平面已经丢包甚至黑洞。对关键业务路径必须在两端之间部署端到端的主动探测作为独立信号源,与控制平面指标交叉验证。
9.3 DevOps Agent Investigation 过程
告警在故障注入后约 4 分钟进入 ALARM 状态,触发 DevOps Agent 开始调查。整个 Investigation 耗时 3 分 34 秒(两次独立测试结果一致)。下面依次截取 Timeline、Root cause、Mitigation plan 三个 tab 中最能体现 Agent 能力的片段。

[图 11:Investigation Timeline] |
与前两个场景不同,T3 的根因不在指标里,而在控制平面变更中。Agent 的调查路径因此转为跨服务纵向关联:并行对 CloudTrail(查 CreateTransitGatewayRoute 变更事件)、TGW 路由表 API(查当前路由条目与 attachment 指向)、以及 VPN BGP 状态(验证对端仅通告 192.1.1.1/32)三条独立数据链路发起查询,并在多源之间交叉验证同一结论。
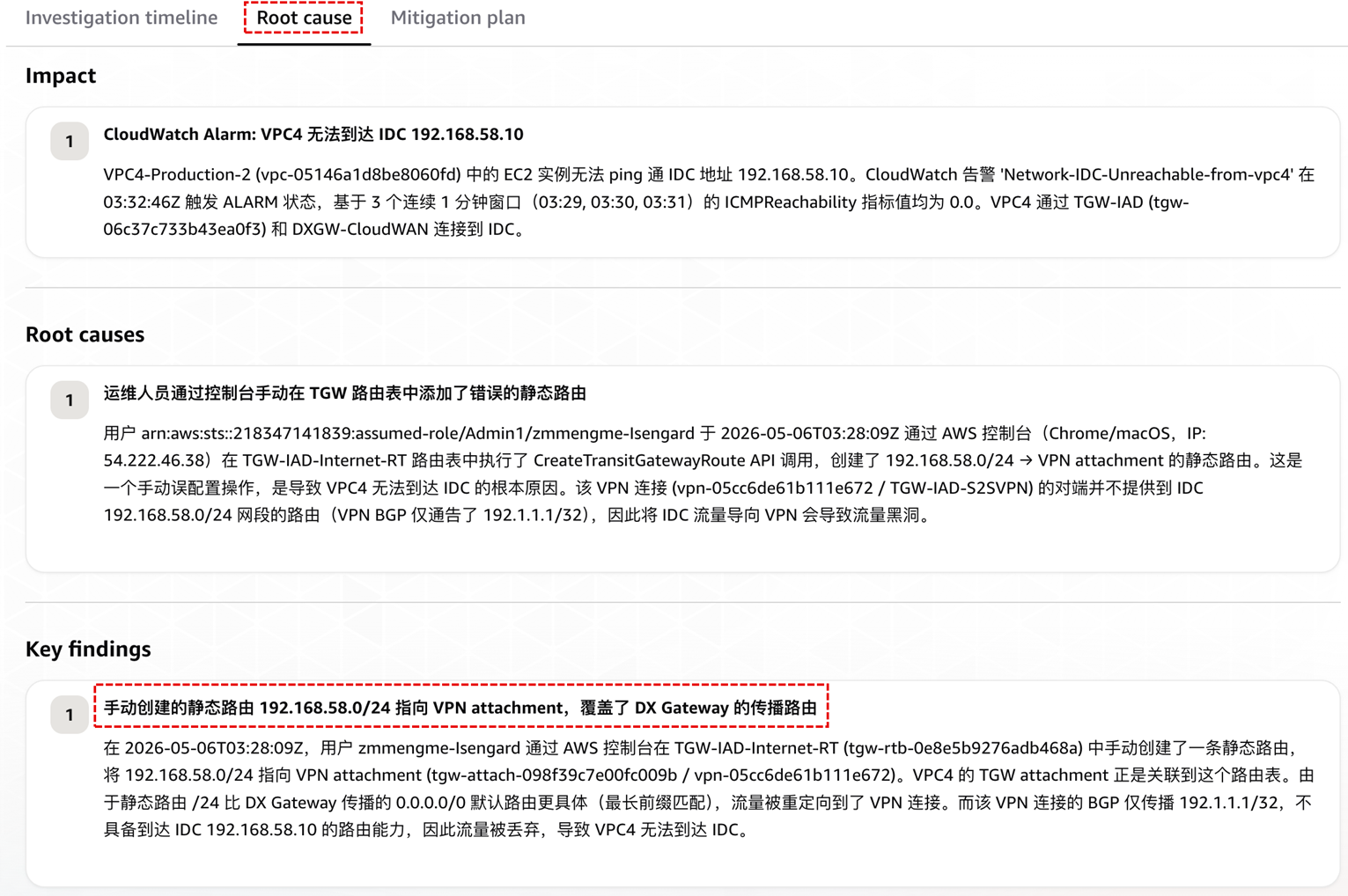
[图 12:Root cause 报告] |
本场景最能体现 Agent 完整操作者画像的能力。CloudTrail 返回的字段被 Agent 直接整合到结论中:谁在什么时间(03:28:09Z)、用哪个 IAM assumed-role、从哪个 IP、通过哪个浏览器、执行了哪个 API 调用。更关键的是 Agent 还主动解释了“为什么”:最长前缀匹配让 /24 覆盖了 DXGW 传播的 /0,而 VPN 对端只通告 /32 不承载 IDC 网段 —— 这段协议行为推理让工程师直接理解机理,而非只接受一个结论。

[图 13:Mitigation plan] |
T3 场景最突出的差异:Agent 给出了一份完整的 5 阶段 runbook(Prepare / Pre-validate / Apply / Post-validate / Rollback),每个阶段都有明确的运维语义与可直接执行的 AWS CLI 命令。这不是“列一条命令”,而是一份“变更可回滚、可观测、可审计”的结构化变更方案,可直接接入 SRE 团队的变更管理流程。
9.4 T3 的独特价值
与前两个深度场景相比,T3 在三个维度上突出了 Agent 的新能力:
- 跨服务纵向关联(vs T2 的跨 Region 横向对比):T2 展示 Agent 并行比对两个 Region 相同服务的指标;T3 则要求 Agent 同时从 CloudTrail、TGW 路由表、VPN BGP 三个不同服务收集证据,在多源之间交叉验证同一结论
- 最完整的 runbook 结构:本 Lab 六个场景的 Agent 都给出了带操作步骤的修复建议,而 T3 因故障类型本身就适合按“准备→前置校验→执行→后置验证→回滚”推进,Agent 输出的 5 阶段 runbook 结构最完整,覆盖了“每一步具体的命令、每一步如何验证、出错时如何回滚”。这种成熟度直接决定了 Agent 在运维场景中的角色 —— 从“辅助工具”变为“可授权执行的自动化参考方案”
- 控制平面变更的审计链路闭环:精确的 IAM 角色、源 IP、浏览器元数据,使根因不仅指向“错误的资源配置”,还指向“做出错误决策的工程师与其操作上下文”。这为组织级的变更管理流程(如 OPS04-BP01、AWS Service Catalog 等治理工具)提供了可执行的闭环入口
从告警触发到 Investigation 报告生成(含 5 阶段 Mitigation Plan),本场景的端到端延迟为 8 分 43 秒。两次独立测试结果完全一致,证明 Agent 输出在此类场景下具备稳定性。
10. 可落地的告警设计实践
基于本 Lab 的 6 个测试场景,以下 6 条告警设计实践可直接应用于生产环境。每条实践头部的彩色徽标标注了对应的 AWS Well-Architected Framework 支柱,便于读者将本文实践与组织内部架构评审流程对齐。
1. 将 AlarmDescription 作为 Agent 的上下文输入 Operational Excellence
CloudWatch 告警的 AlarmDescription 字段应包含结构化的业务上下文:故障类别、涉及资源的完整 ID、业务分组、以及可能的根因方向。DevOps Agent 在接收 webhook 时优先解析此字段以确定 Investigation 范围。若字段内容仅为阈值描述,Agent 需从 dimension 反推语义,调查效率下降;若字段包含完整上下文,Agent 可在接收事件的瞬间进入正确调查路径。
2. 对单一指标使用双阈值分层覆盖 Reliability
单一阈值难以同时覆盖灾难级与渐进级两种严重度。对 BGP Prefix Drop 等关键指标,建议部署两条告警:< 10 条(Floor,捕获全量撤回)与 < 50 条(Partial,捕获部分撤回)。两条告警按时序依次触发时,Investigation 的 triage 层将识别为“同一事件严重度升级”,形成自然的告警序列。
3. 原生慢指标辅以自建快指标 Performance Efficiency Reliability
AWS 原生 Direct Connect 指标的采集粒度为 5 分钟。对于 Connection Down、BGP Down 等需要快速响应的故障,此粒度偏慢。一个以 1 分钟为周期调用 DescribeVirtualInterfaces 并发布至自定义命名空间的轮询 Lambda 可将告警延迟从约 15 分钟降至 3-4 分钟。类似思路亦适用于跨 Region 或跨资源对比的场景,如本文的 Prefix Asymmetry Lambda。
4. 在 on-premises router 启用 BFD Reliability
on-premises router 若未启用 BFD,BGP holdtime 默认 180 秒。叠加 CloudWatch 指标评估周期后,实际告警延迟可能超过 4 分钟。启用 bfd interval 300 min_rx 300 multiplier 3 后,BGP 本地收敛时间从分钟级降至亚秒级,叠加 1 分钟轮询与 3 个评估周期后端到端告警延迟稳定在约 3.5-4 分钟。此为部署 Direct Connect 监控的基础前置配置。
5. 统一告警名前缀规范 Operational Excellence
告警名的前缀(如 DX-BGP-*、DX-Conn-*、DX-LightRx-*、Network-*)由 agent_trigger Lambda 映射至 DevOps Agent 的 severity 与 skill hint。前缀规范稳定后,新增告警遵循相同模式即可自动接入正确的 Investigation 调查路径,减少 Lambda 映射表维护成本。
6. 对关键路径部署端到端主动探测 Reliability
深度场景三(T3)证明了:当故障来自控制平面配置错误(如 TGW 静态路由覆盖 propagated 路由)时,AWS 所有服务级健康指标仍显示健康,只有端到端主动探测能感知数据平面黑洞。
对以下场景,建议在 VPC 内部署主动探测:
- VPC 通过 TGW + DX / VPN 访问远端 IDC 或其他 VPC 的关键路径
- 跨账号、跨 VPC 的非冗余链路
- SaaS 类业务依赖的第三方 endpoint(尤其是经由 PrivateLink / VPC endpoint)
实现形态可以很轻量 —— 本 Lab 使用一个运行 Python icmplib 脚本的 systemd 服务,EC2 t3.nano 实例即可承载,每 10 秒发起一次 ICMP 探测并发布 CloudWatch 自定义指标。替代方案包括 Amazon CloudWatch Synthetic monitors 等。
11. 结论
本文通过真实 AWS Direct Connect 与 Transit Gateway 基础设施上的 6 个故障场景测试了 AWS DevOps Agent 的自动化调查能力。深度场景一(T1 BGP Prefix High)展示了 DevOps Agent 基于产品硬限制的主动风险预测能力;深度场景二(T2 BGP Prefix Asymmetry)展示了其跨 Region 与跨服务的数据关联分析能力;深度场景三(T3 TGW 静态路由错配导致 IDC 流量黑洞)展示了其在控制平面误配置场景下的根因定位 + runbook 级 5 阶段修复建议的完整交付形态。
在这些测试场景中,AWS DevOps Agent 表现出若干与传统监控工具不同的能力特征:从告警 payload 中自主解析业务上下文、基于历史基线判断异常模式、用 CloudTrail 等多源证据主动排除假设、对 AWS 服务机理(如 TGW 最长前缀匹配选路)进行协议级推理、并对控制平面误配置类故障输出可直接接入 SRE 变更管理流程的 5 阶段 Mitigation Plan。AWS DevOps Agent 不对资源执行任何修改操作,其输出形态为一份结构化的 Investigation 报告与可选的 runbook。在运维流程中,工程师的工作由“跨多个控制台收集证据”转向“评估 Investigation 提出的假设并决定是否执行 Agent 给出的修复方案”。
本文聚焦 AWS 侧的自主调查能力,但在混合云环境里,BGP 路由异常的另一半证据往往在 on-premises 网络设备上。本系列第 2 篇:AWS DevOps Agent × MCP Server——打通混合云网络排障的最后一公里 在同一套 Direct Connect 环境上,用 MCP Server 把 Cisco IDC 路由器的只读 show 命令暴露给 Agent,用 Private Connection 把调用流量全程留在 AWS 骨干网;再用 EventBridge Scheduler + Lambda 把 Agent 的 mitigation plan 回推到飞书群,完成 ChatOps 闭环。在两个真实 BGP 场景里,MTTR 从 AWS 侧的约 8 分钟进一步压到约 2 分钟,根因从”相关性”升级为”因果性”(who / when / what)。
➡️ 下一步行动:
相关产品:
- Amazon DevOps Agent — 解决和预防事故的代理
- Amazon Connect — AI 客户体验解决方案
- Amazon CloudWatch — 可观测性工具
- Amazon VPC — 隔离云网络
- AWS Lambda — 无需服务器即可运行代码
相关文章:
- 基于 AWS DevOps Agent 构建 AI 驱动的运维分析系统
- 将 AWS DevOps Agent 智能运维能力延伸到中国区
- AWS DevOps Agent 与 GitHub 集成实践:如何实现从代码变更到故障调查的端到端闭环
- AWS Direct Connect 故障演练实战指南
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
