亚马逊AWS官方博客
基于 Amazon IoT Core 与 Kiro 构建可迁移的工业 IoT 数据管道
摘要:本文介绍了我们如何平滑地进行智慧工厂项目IoT系统的迁移,记录了我们如何把”手动步骤指南”演化成幂等的 boto3 编排脚本,再进一步用 Kiro 把它包装成一个 AI Agent 能直接调用的工作流。
目录
一、引言:一次跨账户的工业 IoT 链路重建
在智慧工厂场景里,一条工业 IoT 数据链路一旦上线,几乎不会有人愿意再触碰它——因为现场设备分布在工厂车间,停机意味着产线读数中断、能耗看板黑屏、BI 决策失真。但这一次,我们需要把一条已经稳定运行的链路从一个亚马逊云科技账户整体迁移到另一个账户,原因是客户在亚马逊云科技中国(北京 cn-north-1)区域启用了一套全新的多账户治理方案,要求所有生产工作负载落到新的“业务账户”,并与数据中台账户、安全审计账户解耦。
这条链路本身并不复杂——4 个 Advantech 网关通过 MQTT over TLS(X.509 双向认证)把现场能耗、温湿度数据推到 Amazon IoT Core,IoT Rule 把消息写入 Amazon Kinesis Data Streams,再由 Amazon Kinesis Data Firehose 缓冲落到 Amazon S3,最后客户的 BI 系统从 Amazon S3 拉数据回数仓做分析。但当它需要被“复制”到新账户、并且不允许更换设备端的证书与私钥时,迁移难点也随之出现。
朴素的做法是打开亚马逊云科技控制台,照着旧账户的资源一步步重建——这正是我们最初的“手动步骤指南”所做的事。它能跑通,但有三个问题:
- 不可重放:手动步骤一旦因人为误操作中断(比如忘记 attach 一个 inline policy),回滚和重做都依赖工程师的记忆。
- 不可演进:当客户从 1 个工厂扩展到 N 个工厂、需要批量铺设时,手册化流程是 O(N) 的人力成本。
- 不可被 AI 调度:在 Kiro、Amazon Bedrock Agent 这类 AI 驱动开发流行的当下,一份只有人能读懂的 Markdown 没法被 Agent 直接调用。
这篇文章记录我们如何把“手动步骤指南”演化成幂等的 boto3 编排脚本,再进一步用 Kiro 把它包装成一个 AI Agent 能直接调用的工作流 (本文配套源码与部署说明详见Github)。我们也会讨论一些容易被忽略的工程细节——比如为什么 IoT Policy 里的 IP 白名单是迁移过程中最容易踩到的关键约束,为什么 Amazon Kinesis Data Firehose 的 5 MiB / 5 min buffer 在工业场景里是一个值得权衡的默认值,以及为什么我们最终选择 Amazon Kinesis Data Streams 而不是直接 IoT Rule → Firehose。
二、架构总览
2.1 数据链路
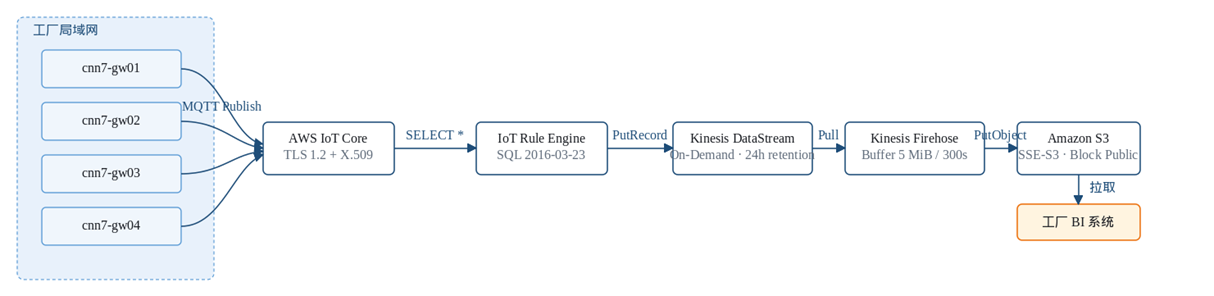
[图1] |
IoT 数据链路:4 个工厂网关通过 MQTT 推送到 Amazon IoT Core,再经 IoT Rule Engine → Amazon Kinesis Data Streams → Amazon Kinesis Data Firehose 落到 Amazon S3,最后由工厂 BI 系统拉取
设备端(4 个 Advantech 网关 cnn7-gw01..04)通过 MQTT over TLS(8883 端口、X.509 双向认证)把消息发到 Amazon IoT Core(亚马逊云科技中国 cn-north-1 区域);IoT Rule(SQL 版本 2016-03-23)以 SELECT * FROM ‘prd-factory-energy-mgt-iot-cnn1/#’ 把消息 PutRecord 到 Amazon Kinesis Data Streams(On-Demand、24 h retention);Amazon Kinesis Data Firehose 以 5 MiB / 300 s buffer 拉取并 PutObject 写入 Amazon S3(SSE-S3、Block Public Access);最终工厂 BI 系统从 Amazon S3 拉取数据进数仓。
2.2 各层设计意图
| 层级 | 选择 | 关键原因 |
| 设备接入 | Amazon IoT Core(MQTT 8883 + mTLS) | 工厂网关原生支持 MQTT;Amazon IoT Core 提供证书生命周期、规则引擎和按设备粒度的鉴权,相比自建 EMQX 运维负担更轻 |
| 路由 | IoT Rule + SQL SELECT * FROM ‘topic/#’ | 通配符 topic 让网关之间无需协调;如未来需要字段过滤可直接在 IoT 内做 SQL 投影 |
| 缓冲 | Amazon Kinesis Data Streams(On-Demand) | 解耦下游消费节奏;On-Demand 自动扩缩 shard,避免现场流量波动时丢数据 |
| 落盘 | Amazon Kinesis Data Firehose → Amazon S3 | 不需要自己写 AWS Lambda / Amazon EC2 batch;天然按时间分区写 Amazon S3 |
| 存储 | Amazon S3(SSE-S3、Block Public Access) | 成本低,可被任意下游(BI、Amazon Athena、AWS Glue、Spark)消费 |
2.2.1 为什么不直接 IoT Rule → Amazon Kinesis Data Firehose
这是这条链路的第一个工程取舍。理论上 IoT Rule 可以直接 action 到 Amazon Kinesis Data Firehose,少一跳、少一份费用。我们最终保留 Amazon Kinesis Data Streams 中间层,理由有三个:
- 可重放。Amazon Kinesis Data Streams 默认 24 h retention(可扩展到 365 天),Amazon Kinesis Data Firehose 没有 retention。一旦 Amazon S3 写入失败或下游 BI 入仓任务暂停,Streams 这一段还能提供最长 24 小时的回放窗口;Firehose 一旦投递失败只能落 error prefix。
- 多消费者。后续客户希望增加一条实时告警链路(AWS Lambda 消费 Streams 触发 Amazon SNS),还可能加一条 AWS Glue Streaming ETL。Streams 是天然的 fan-out 支点;Firehose 不是。
- 顺序与分区可控。Streams 让我们决定 partition key——目前固定为 “1” 表示所有消息进同一个 shard,等流量起来后改成 ${topic()} 即可,无需重建管道。
代价是多了一个 On-Demand Streams 的费用(按 GB 写入 + GB 读取计费)。我们认为这是合理的“可观测性 + 可扩展性”溢价。
2.2.2 为什么是 On-Demand 模式
Provisioned 模式单价更低,但需要根据流量预估 shard 数量。智慧工厂这种场景流量不算大(4 网关 × 每秒约 1 条消息 × 平均几 KB),但具有突发性——产线启动、批量上报、网络恢复后的补发都会在几秒内堆出十几倍峰值。On-Demand 在这个量级下的成本差异在可接受范围内(参见后文成本分析),且免去了手工调 shard 的运维负担。
2.2.3 Amazon Kinesis Data Firehose 的 5 MiB / 300 s buffer 是一项权衡
Amazon Kinesis Data Firehose 的 buffer 触发条件是“先到先触发”:要么累计 5 MiB,要么等满 300 秒。在我们的流量下几乎永远是 300 秒先到——也就是说,Amazon S3 上的一个 object 平均代表 5 分钟的消息批次。这意味着:
- BI 侧的入仓时延 = 设备产生时间 + 最长 5 分钟 Firehose buffer + Amazon S3 list/拉取间隔。对小时级看板足够,但不要期望它做秒级实时。
- 单个 Amazon S3 object 通常较小(几十 KB 至几百 KB)。这会让 Amazon S3 出现较多小文件,下游若用 Amazon Athena/Spark 直接扫会受 small files 影响。我们建议下游入仓时做 compaction(例如 AWS Glue Job 每小时合并一次到 Parquet)。
如果业务需要更短的入仓时延,可以把 buffer interval 降到 60 秒,但会进一步加剧小文件问题,并使每次 PUT 都计入 Amazon S3 PUT 请求费用。这是一个典型的“时延 vs 成本 vs 文件数量”三角,需要根据业务取舍。
三、跨账户迁移的真正难点
如果只是创建一组新资源,故事到这里就结束了。但这是一次带流量的迁移,难点不在创建,而在以下几个隐藏约束:
3.1 约束 1:证书不能换
设备端的私钥保存在网关里,远程升级路径有限,且每次更换都要现场出工。客户的硬性要求是:新账户必须复用旧账户已签发的 4 张设备证书。
Amazon IoT Core 支持把同一张证书注册到多个账户(注册时使用 register-certificate-without-ca + SNI_ONLY 模式),这给了我们一个非常优雅的迁移路径:
- 从旧账户导出 4 张证书的 PEM(只导公钥部分,私钥不需要也不允许传输)。
- 在新账户调用 register-certificate-without-ca 注册同一张证书,得到的 certificateId 与旧账户完全相同。
- 在新账户给证书绑定新的 IoT Policy 与 Thing。
- 设备端只更换 IoT Endpoint 域名,证书、私钥保持不动。
- 验证通过后,再去旧账户 deactivate 证书。
这个方案的好处是设备端改动最小(只改一行 endpoint 配置),且整个迁移过程证书在两个账户同时有效,给了我们安全的回滚窗口。
3.2 约束 2:IoT Policy 的 IP 白名单是一个关键约束点
旧账户的 IoT Policy 用 aws:SourceIp 把允许连接的 IP 限制在工厂出口 IP(示例:203.0.113.82)。这个 Condition 是 IoT Policy 评估的一部分,任何 IP 不匹配的连接都会被 Amazon IoT Core 拒绝且日志极简——表现就是 UNEXPECTED_HANGUP,工程师容易误以为是证书或 endpoint 问题。
迁移过程中我们遇到过一次这种情况:实验室里用一台 Amazon EC2 验证 MQTT 连接,初期验证过程中曾因 IP 白名单限制导致连接失败。后来形成一条规范:任何手工 MQTT 验证必须先把测试机的当前公网 IP 加进一个独立的“测试 Policy”,验证完立刻 detach 并删除。这条规则后来直接固化到了自动化脚本里(测试 Policy 命名为 prd-factory-energy-mgt-iot-pl-test)。
3.3 约束 3:Amazon S3 Bucket 名称全局唯一(注意点)
Amazon S3 Bucket 名称全局唯一,跨账户迁移时新账户不能复用旧账户的 bucket 名,否则会冲突。我们的命名约定是:
把 12 位账户 ID 当后缀,这样在 N 个账户里铺设同一套架构时永远不会冲突。下游 BI 的拉取任务需要相应改 bucket 名——这是迁移割接窗口里需要协调的最后一步。
3.4 约束 4:cn-north-1 与 cn-northwest-1 使用 aws-cn ARN partition(注意点)
亚马逊云科技中国(北京 cn-north-1)区域与亚马逊云科技中国(宁夏 cn-northwest-1)区域的 ARN partition 是 aws-cn,不是 aws。所有 AWS IAM Policy、IoT Rule、Amazon Kinesis Data Firehose 配置里的 ARN 都必须写成 arn:aws-cn:…。这一点在脚本里我们做了硬编码,文档中也作为注意点显式强调。
四、部署演进:从手册到 boto3,再到 Kiro
迁移这条链路的“创建顺序”本身已经被设计指南讲清楚了:
按数据链路从下游到上游创建,能保证每一步依赖的资源都已经就绪。下面分别讲手动、自动化、AI 化三种部署形态。
4.1 形态一:手动步骤指南(人工部署)
最初版本是一份近 800 行的 Markdown,把每一步控制台路径、字段值、JSON 内容都列出来。它的优势是透明——任何工程师拿到文档都能在 30 分钟内手动跑出一套环境,且能看到每一步的状态。劣势我们前面提到了:不可重放、不可批量、不可被 AI 调用。
我们没有抛弃它。在客户的运维 SOP 里,这份文档仍然是“最后的人工应急路径”——当自动化脚本因为权限、网络问题跑不起来时,工程师可以用它做兜底。这是一个被低估的工程实践:自动化不是消灭手动,而是给手动找到一个明确的位置。
4.2 形态二:boto3 幂等脚本(CI/CD 集成)
setup_all.py 是手册的“代码化”版本。它有三个关键设计:
1. 幂等。 每个资源先 describe/get/head 一次,存在就跳过,不存在才创建。这样脚本可以反复跑,不会因为“已存在”报错而中断。例如 Amazon S3 Bucket:
幂等是脚本能进 CI/CD 的前提——只有这样我们才能在 PR merge 时无脑触发 setup_all.py,不需要先判断“这是首次部署还是更新”。
2. 双证书模式(create / register)。 同一份脚本支持两种场景
- -cert-mode create:在新账户新建 4 张证书,用于早期链路验证(不绑定真实设备)。
- -cert-mode register –cert-dir ./oldcert:把旧账户导出的 PEM 注册到新账户,用于正式割接。
这个设计让“测试环境”和“生产迁移”共享同一份代码路径,避免了“测试用脚本 A、生产用脚本 B”的双轨问题。
3. 测试 Policy 自动跟随当前公网 IP。 脚本启动时调用 https://ifconfig.me 拿到机器的公网 IP,自动写入 prd-factory-energy-mgt-iot-pl-test:
这把前面提到的“IP 白名单约束”从经验教训变成了系统约束——只要用脚本部署,验证机一定能连上。验证完成后 detach 测试 Policy 即可,不影响生产 Policy。
verify_e2e.py 与 setup_all.py 配套,做端到端验证:
- 用 mqtt_connection_builder.mtls_from_path 通过证书连上 Amazon IoT Core。
- 向 prd-factory-energy-mgt-iot-cnn1/cnn7-gw01..04 发一条带唯一 test_id 的 JSON 消息。
- 立刻用 AT_TIMESTAMP shard iterator 去 Amazon Kinesis Data Streams 里搜,确认消息进了 Streams。
- 轮询 Amazon S3 最长 330 秒(覆盖一个完整的 Firehose buffer 周期),按 YYYY/MM/DD/HH/ 前缀找包含 test_id 的 object。
整个验证大约耗时 5–6 分钟,全程无需人工介入。
4.3 形态三:用 Kiro 包装成 AI 工作流
setup_all.py 已经能让人或 CI 工具调用,但如果希望把它接入一个对话式的运维入口——比如让现场工程师在 Kiro 里说一句“帮我把这条 IoT 链路在 1234567890 这个新账户里跑起来,测试 IP 是 xxx,证书在 s3://oldcert/”,让 AI Agent 自己去编排——还需要再封一层。
这就是 Kiro 介入的地方。Kiro 是亚马逊云科技推出的 AI 编程助手,支持把脚本、文档、规范包装成可被 LLM 调用的 specs。我们的演进路径是:
Step 1:把脚本拆成原子操作。 把 setup_all.py 的 9 个 step 拆成 9 个独立函数,每个函数只做一件事,输入输出都是结构化的 JSON。这样 Kiro 的 spec runner 可以按需调度。
Step 2:把“手动创建步骤指南.md”升级成 Kiro spec。 Kiro 的 spec 是一个 Markdown + YAML 混合体,包含意图(intent)、步骤(steps)、验收(acceptance criteria)。我们把 9 步改写成:
这一步看起来像在写 Terraform,但本质不同:Kiro spec 描述“任务的意图”,Terraform 描述“基础设施的状态”。前者天然适合被 LLM 推理,后者适合被工具应用。
Step 3:让 Agent 处理人类不愿意处理的边界情况。 这是 AI 驱动方案最有价值的部分。例子:
- 当 register_certs 因为 PEM 内容损坏失败时,Agent 自动回退到 –cert-mode create,并在结束时报告“已使用临时证书完成验证,请检查源 PEM 文件的换行符”。
- 当 verify_e2e 因为 IP 白名单失败时,Agent 自动调用 ifconfig.me 拿到当前 IP、对比测试 Policy 中的 IP,给出“测试 Policy 中的 IP 是 1.2.3.4,但当前机器是 5.6.7.8,是否更新?”的提示。
- 当某一步触发了 AWS IAM 权限传播延迟(典型场景:刚创建的 Role 立刻被 Amazon Kinesis Data Firehose 引用时报 not assumable),Agent 等 10 秒后自动重试,而不是把错误抛给用户。
这些边界情况在原始脚本里都是 try/except + time.sleep,散落在代码里难以维护。把它们提升成 Agent 的“修复策略”后,脚本本身可以保持简洁,运维知识沉淀在 spec 里。
Step 4:让 spec 自带验收标准。 Kiro 的 acceptance 段允许我们声明“这次任务做完后必须满足什么”。在我们的 spec 里:
- Amazon S3 bucket 存在且 Block Public Access 全勾。
- Amazon Kinesis Data Streams 状态为 ACTIVE、模式为 ON_DEMAND。
- Amazon Kinesis Data Firehose 状态为 ACTIVE,目的地为指定 bucket。
- 4 张证书已注册、已 attach 生产 Policy、已绑定 Thing。
- verify_e2e.py 报告 s3_ok = True。
任何一项不满足,Agent 都会标记任务为失败、产出 root-cause 报告,而不是默默退出。这把“工程师肉眼检查 9 个控制台页面”的工作完全自动化了。
4.4 三种形态的对比
| 维度 | 手动步骤指南 | boto3 脚本 | Kiro AI 工作流 |
| 可重放性 | 低(依赖人记忆) | 高(幂等) | 高 |
| 跨环境复用 | 需要重写文档 | 参数化 CLI | 参数化 spec |
| 边界情况处理 | 工程师自行判断 | 写在 try/except 里 | LLM 推理 + 修复策略 |
| 学习曲线 | 任何人能读 | 懂 Python + boto3 | 懂 Kiro spec |
| 适用场景 | 应急兜底、培训 | CI/CD、批量铺设 | 多账户治理、对话式运维 |
我们建议三种形态共存:spec 跑不起来时回退到脚本,脚本跑不起来时回退到手册。这种“逐级降级”的架构,比追求“100% AI 自动化”更稳。
五、持续运营成本分析
为给读者一个相对量级的概念,我们按一个工厂 4 网关、平均每秒每网关 1 条约 2 KB 消息的流量估算(约 700 MB/天)。
| 服务 | 主要计费维度 | 量级 | 备注 |
| Amazon IoT Core | 消息数、连接时长 | 低 | 4 长连接 + 约 350 万消息/月 |
| Amazon Kinesis Data Streams On-Demand | 写入 GB + 读取 GB + shard 小时 | 低-中 | On-Demand 单价高于 Provisioned,但运维更省力 |
| Amazon Kinesis Data Firehose | 写入 GB | 低 | 单价低于 Streams |
| Amazon S3 标准 | 存储 GB-月 + PUT 次数 | 低 | PUT 次数受 buffer interval 影响 |
| Amazon CloudWatch Logs | Ingestion GB + 存储 | 中 | 持续运营中容易被低估,建议关注 |
| 数据传输 | 跨 AZ / 跨 region | 低 | 同 region 内大部分免费 |
几个值得在长期运营中关注的成本维度:
- Amazon CloudWatch Logs 的持续成本。Amazon Kinesis Data Firehose error logging、IoT Logs(如果启用了 INFO 级别)都会持续写入 Amazon CloudWatch,按 ingestion GB 计费。生产环境建议把 IoT Logs 设到 ERROR 级别,把 Firehose log 的保留时间限定在 7-14 天。
- Amazon S3 PUT 次数。如果把 Amazon Kinesis Data Firehose buffer interval 从 300 s 降到 60 s 追求低延迟,PUT 次数会增加 5 倍,PUT 费用相应上升。建议根据业务时延要求权衡。
- Amazon Kinesis Data Streams On-Demand 的 retention。默认 24 h retention 不额外收费,扩展到 7 天会按 GB-小时计费。我们目前用默认 24 h,足够覆盖一次 BI 入仓的回放窗口。
- 跨账户数据传输。本架构里下游 BI 通过 Amazon S3 Bucket Policy 跨账户拉数据,没有 NAT Gateway,也没有跨 region 流量,因此数据传输费用接近 0。如果把 BI 部署到不同 region,会引入 inter-region transfer 费用,是另一个量级。
我们没有给出“每月 XX 元”的精确数字,原因是单个工厂的成本较低、放大到 100 个工厂时主要成本会从 IoT 转移到 BI 数仓侧。对工业 IoT 这个场景,下游数仓和分析的成本通常比 IoT 链路本身高一个数量级——这意味着持续优化精力建议优先投向那里。
六、运维与可观测性
6.1 推荐的监控指标
我们建议至少打开下面四组监控:
- Amazon IoT Core:Connect.AuthError(证书或 Policy 出问题)、PublishIn.AuthError(topic 发布权限)、RuleMessageThrottled(Rule 被限流)。
- Amazon Kinesis Data Streams:IncomingRecords(流量异常下降意味着上游断了)、WriteProvisionedThroughputExceeded(极端突发下短暂限流)、IteratorAgeMilliseconds(消费滞后)。
- Amazon Kinesis Data Firehose:DeliveryToS3.Success、DeliveryToS3.DataFreshness(数据从进 Firehose 到落 Amazon S3 的时延)、ThrottledRecords。
- Amazon S3:用 aws_s3_object_count 监控按小时分区的 object 数量,下降到 0 是最直接的“链路断了”信号。
我们把这套监控做成了一份 Amazon CloudWatch dashboard JSON,跟 setup_all.py 一起跑——这样新账户里资源创建完成后,dashboard 也是现成的。
6.2 调试 IoT 连接失败的标准流程
工业 IoT 现场最常见的问题是“设备连不上”,原因通常是以下几种:
- TLS 握手失败:检查 endpoint 是不是 iot:Data-ATS 的地址(不是 iot:Data 也不是 iot:CredentialProvider);CA 必须是 AmazonRootCA1.pem;证书必须 ACTIVE。
- 认证通过但被 Policy 拒绝:表现是 UNEXPECTED_HANGUP。检查证书 attach 的 Policy、aws:SourceIp 条件。
- Thing 没绑证书:Amazon IoT Core 不强制 Thing-Certificate 绑定,但很多 SDK 默认 client_id 用 Thing 名,如果 Thing 没绑证书会出现混乱。
- Region 错误:cn-north-1 的设备必须连 cn-north-1 的 endpoint。
这套排错流程我们在 Kiro spec 里也写成了一个独立的 diagnose-mqtt-connection step,输入是设备的 endpoint + 证书,输出是结构化的诊断报告。Agent 出现连接失败时会自动调起这个 step,而不是把原始 boto3 错误丢给用户。
七、割接 Checklist
迁移真正的难点不是建出来一套环境,而是何时切流。我们的 checklist 来自手动步骤指南,并固化进 Kiro spec:
割接前:所有资源已在新账户创建、新建证书的链路验证通过、注册旧证书的链路再次验证通过、生产 IP 在白名单里、测试 Policy 已清理。
割接:设备端只改 endpoint 域名、监控新账户至少 24 小时。
割接后:旧账户 IoT Rule 设为 disabled、旧证书 deactivate(不删除,留作回滚后路)、观察 1-2 周后再清理旧账户资源。
回滚预案:设备端把 endpoint 改回旧账户即可,因为证书在两个账户都有效——这是这套迁移方案最关键的工程优势。
八、安全考量
8.1 最小权限的 AWS IAM Role
setup_all.py 里给 IoT Rule 和 Amazon Kinesis Data Firehose 创建了独立的 Role,权限范围精确到资源 ARN而不是 Resource: “*”。例如 IoT Rule 的 inline policy 只允许对一个具体 Stream PutRecord:
这是 AWS IAM 最小权限的标准做法。在工程实践中部分团队为了省事会写 kinesis:* + Resource: “*”,给后期审计埋下隐患。我们的脚本把“窄权限”作为默认行为,工程师不需要再做选择。
8.2 IoT Policy 的两层防御
证书提供了身份(Authentication),IoT Policy 提供了授权(Authorization)。即使设备端私钥被盗,攻击者还需要从 IP 白名单里的网络出口才能连进来——这是一种简单但有效的纵深防御。
我们也讨论过用 AWS IoT Device Defender 做异常检测(连接频率突变、消息大小异常),但客户当前阶段优先满足核心功能,留作未来增强项。
8.3 证书与私钥的存储
迁移过程中永远不要把私钥从设备端导出。我们的方案设计如此:旧账户只导公钥 PEM,新账户用 register-certificate-without-ca 注册,私钥始终保留在设备里。这一条规则也写进了 Kiro spec 的 input validation——如果用户传入的 cert_dir 包含 .private.key 文件,Agent 会拒绝执行并提示“私钥不应离开设备”。
8.4 Amazon S3 的默认安全
Amazon S3 Bucket 默认开启 Block Public Access、SSE-S3 加密。我们没有上 AWS KMS CMK,原因是 BI 拉取方在另一个账户,引入 AWS KMS 会增加跨账户授权复杂度。如果合规要求强制使用 CMK,需要相应配置 AWS KMS Key Policy 允许 BI 账户的 Role decrypt——这是个独立的工作量。
九、未来架构持续优化方向
每一种架构选择都有其 pros 与 cons。这套链路面向 BI 看板与能耗分析场景已经足够稳定,但仍有几个值得在未来持续演进的方向,列在这里供后续团队参考:
- 入仓时延优化(pros:满足实时控制;cons:复杂度上升)。当前 5 分钟入仓时延适合 BI 看板与能耗分析,但不适合产线实时反馈控制。若业务需要秒级闭环,可叠加 Amazon IoT Core → AWS Lambda → 设备 shadow / Amazon SNS 的旁路。
- Partition key 分散(pros:吞吐线性扩展;cons:消费侧顺序模型变化)。当前 partitionKey = “1” 让所有消息进同一个 shard,On-Demand 模式会自动 split shard,但 split 期间会有短暂的 hot shard。流量超过约 1 MB/s 时建议提前改为 ${topic()} 或 ${clientid()}。
- Schema 治理(pros:下游兼容性变好;cons:固件升级时引入流程成本)。当前 Amazon Kinesis Data Firehose 直接把 MQTT JSON 原样写到 Amazon S3,未做 schema 校验。可考虑接入 AWS Glue Schema Registry 让 Firehose 在投递前做校验,或在 IoT Rule 里用 SQL 投影固定字段。
- Dashboard 业务化(pros:运营侧可读性更好;cons:需要持续维护映射)。当前 Amazon CloudWatch dashboard 按服务划分(Amazon IoT Core、Streams、Firehose、Amazon S3 分四块),运维易看,运营经理难懂。可按“工厂 → 网关 → 数据”业务维度做 dashboard,并接入 Grafana。
这些都不是这次迁移要解决的问题,列在这里作为长期演进 roadmap。
十、结论
这次跨账户迁移最大的工程收获,不在于“把 IoT 链路成功搬到新账户”这个结果本身,而在于把一份给人看的 SOP 演化成一份给 AI 看的 spec,并保留人能兜底的路径。把这次实践提炼为五条可复用的经验:
- 幂等是底层契约。任何自动化脚本都应假设自己会被反复触发,每个资源都做 check-then-create,而不是 try-then-fail。这是脚本能进 CI/CD 的前提,也是 AI Agent 能复用脚本的前提。
- 测试环境与生产环境共享代码路径。我们用一个 –cert-mode 参数让验证流程和割接流程跑同一份代码,避免了“测试用脚本 A、生产用脚本 B”的双轨问题。
- 把工程师经验沉淀进系统约束。例如“测试 Policy 自动跟随当前公网 IP”原本只是口头规则,写进脚本后就变成系统行为。Kiro spec 的修复策略是这种沉淀的下一阶段——把口头规则变成 Agent 的推理路径。
- 不追求 100% AI 自动化。手册是最后一道防线,脚本是中坚力量,AI 工作流是日常入口。三层共存比追求单一最优更稳。
- 跨账户迁移的护城河在“可回滚”。设备证书在两个账户同时有效、设备端只改一行 endpoint,让回滚路径几乎无成本——这才是工业场景敢做迁移的真正前提。
这套架构的适用与不适用场景
| 适用场景 | 不适用场景 |
| 流量 KB/s 到 MB/s 量级的工业 IoT 数据管道 | 实时控制环路(需要秒级闭环) |
| 对成本敏感、需要多个下游消费 | 需要事务一致性的金融级数据流 |
| 跨账户、跨工厂复制部署 | 入仓时延要求 < 10 s 的告警链路 |
后续我们会把这套 Kiro spec 推到客户的多账户铺设流水线里,目标是把“新工厂上线”从“工程师按手册手工操作 2 天”压缩到“在 Kiro 里说一句话、20 分钟拉起一套可验证的 IoT 数据管道”。当幂等脚本、spec、Agent 修复策略都已经就位时,这并不是一个愿景,而是一个具体的工程任务。
➡️ 下一步行动:
相关产品:
- Amazon Kinesis — 实时流数据处理
- Amazon S3 — 适用于 AI、分析和存档的几乎无限的安全对象存储
- Amazon IoT Core — 设备连接到云
- Amazon CloudWatch — 可观测性工具
- Amazon IAM — 身份管理和访问权限
相关文章:
- 用 Kiro CLI 自动搭建 FluentBit 日志采集方案:两种 EKS 埋点数据落地 S3 Parquet 的实战对比
- 使用 Kiro CLI 和 Agent Client Protocol 构建飞书 AI 聊天机器人
- 用 Kiro Skill 打造你的专属 AI 工作流:以会议纪要自动生成为例
- 一种基于Web访问的Kiro CLI 共享访问实现
- 从 SDLC 到 AIDLC:CI&T 对 AI 驱动软件开发模式的探索及Kiro最佳实践
参考链接
- https://docs.amazonaws.cn/en_us/iot/latest/developerguide/iot-gs.html
- https://docs.aws.amazon.com/firehose/latest/dev/what-is-this-service.html
- https://aws.amazon.com/cn/kinesis/data-streams/
- https://kiro.dev/docs/skills/
- https://kiro.dev/docs/specs/best-practices/
- https://github.com/mildone82/iot-migration
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
