亚马逊AWS官方博客
基于 AWS 智能设备助手行业资产,构建社交渠道触达的消费级 Agent 交互应用
摘要:硬件智能体、Amazon Bedrock、 AgentCore、设备助手、设备控制、 Device Assistant、Agent、Telegram 、人机交互。
目录
一、引言
智能硬件这一类设备——空调、热水器、灯、扫地机器人——的人机交互,过去基本停在两种形态:在 App 里点菜单,或者对着固定唤醒词喊单步指令。两种都不擅长处理带条件、带时序、跨设备的复杂意图,比如:
“每个工作日下班前半小时把空调打开,周末别开。”
“我要回家了。”——一句话,空调、热水器、净化器一起启动。
这些诉求并不是堆功能就能解决。菜单点不出条件分支,唤醒词背不下时序逻辑。问题出在交互范式本身。
LLM 加 Agent 技术出现之后,自然语言可以做统一入口:用户说意图,Agent 拆任务、调工具、跨设备编排、保留多轮上下文。AWS 围绕这条路径沉淀了一套面向智能硬件行业的解决方案资产 Intelligent Device Assistant(IDA,智能设备交互助手),覆盖语音、模型推理、Agent设计、工具编排、定时调度、多渠道接入。客户基于 IDA 做适配落地,不需要从零搭。
这篇文章按三层展开:
- 场景:Agent 范式下,硬件交互发生了什么变化
- 能力:自然语言加 Agent 怎么把”定时”这类传统应用层逻辑收成 Agent 工具
- 工程:以Telegram为例,怎么通过社交App把这套助手低摩擦交付给消费者
二、Agent 范式下,硬件交互的变化
2.1 三轮交互的局限
| 范式 | 代表 | 用户表达 | 局限 |
| 遥控器 / 物理按键 | 空调遥控、电视遥控 | 单按键单功能 | 不能跨设备 |
| 移动 App | 智能家居 App | 点菜单、拉滑块 | 复杂意图要点 5–10 步 |
| 智能音箱 | 音箱 | 固定唤醒词 + 单步指令 | 不理解条件和时序 |
| Agent 自然语言 | 跨终端 | 多轮对话 | 时延 |
传统的App 把所有设备能力暴露成 UI 控件,把”控制意图”翻译成”控件操作”留给用户。传统语音助手的本质是基于传统 ML 模型的关键词匹配加槽位填充,遇到复杂意图或超出训练范围的语句就无法做出回应。
Agent 范式不一样的地方在于:模型理解意图,工具负责执行。用户说”今晚回家路上提前把空调打开”,模型自己拆成估到家时间、选哪台空调、设温度、调定时工具这几步。
2.2 用户的习惯也在变
OpenClaw 这一类现象级应用出现之后,普通消费者已经习惯通过 Telegram、WhatsApp、Slack、Discord 这些熟悉的社交工具直接跟 AI Agent 打交道——加好友、发一句话、AI 帮忙读文件、跑命令、串多步任务,整套动线和日常聊天没什么区别。这件事把”对话式 AI”从浏览器里那个独立 Tab 拉进了消费者每天都在用的社交 App。
习惯一旦形成就会迁移。一个已经在 Telegram 里用 OpenClaw 类 Bot 帮自己处理事的用户,再让他用同样的方式控制空调,没什么教育成本。
对厂商来说这是个直接信号:助手的入口不一定非得做在自家 App 里。把 Bot 投到用户已经在用的社交平台,比拉新用户下载一个新 App 摩擦低得多。
2.3 厂商角度的变化
对智能设备厂商来说,Agent 范式带来一个具体的研发转变:以前每加一种交互要做一个 App 页面,设计一套菜单层级;现在每加一种能力做一个 Agent 工具就行,模型自动学会什么时候调它。
研发产出从”功能页面”变成”能力工具”。十几个工具的组合空间能覆盖几十个 App 页面也做不到的复杂意图。
分发上,同一套 Agent 后端,前端可以是自家 App、Web 控制面板、Telegram、WhatsApp、智能音箱。只要有文本或语音入口就够。这件事让硬件厂商不必再在”做一个大而全的私域 App”这条路上死磕。
2.4 Intelligent Device Assistant 智能设备助手
IDA 解决方案以 Amazon Bedrock 为模型与生成式 AI 底座,由 Amazon Bedrock AgentCore 承担 Agent 主体的托管与工具网关,工具实现层落在 AWS Lambda 上,对内可直接对接 AWS IoT 系列服务实现设备直连,对外则可承接厂商 IoT 平台的能力。语音相关能力由 Amazon SageMaker 与 Amazon Polly 共同提供——前者基于开源模型打造,用于语音识别与语种识别,后者用于多语种语音合成;定时调度借助 Amazon EventBridge Scheduler 实现 Serverless 高可用;用户数据、Token 与会话状态分别存放在 Amazon RDS 与 Amazon DynamoDB 中;企业相关的业务知识库使用Amazon OpenSearch Service。整体方案部署运行在 Amazon VPC 内,由 AWS IAM 完成多租户的权限隔离。
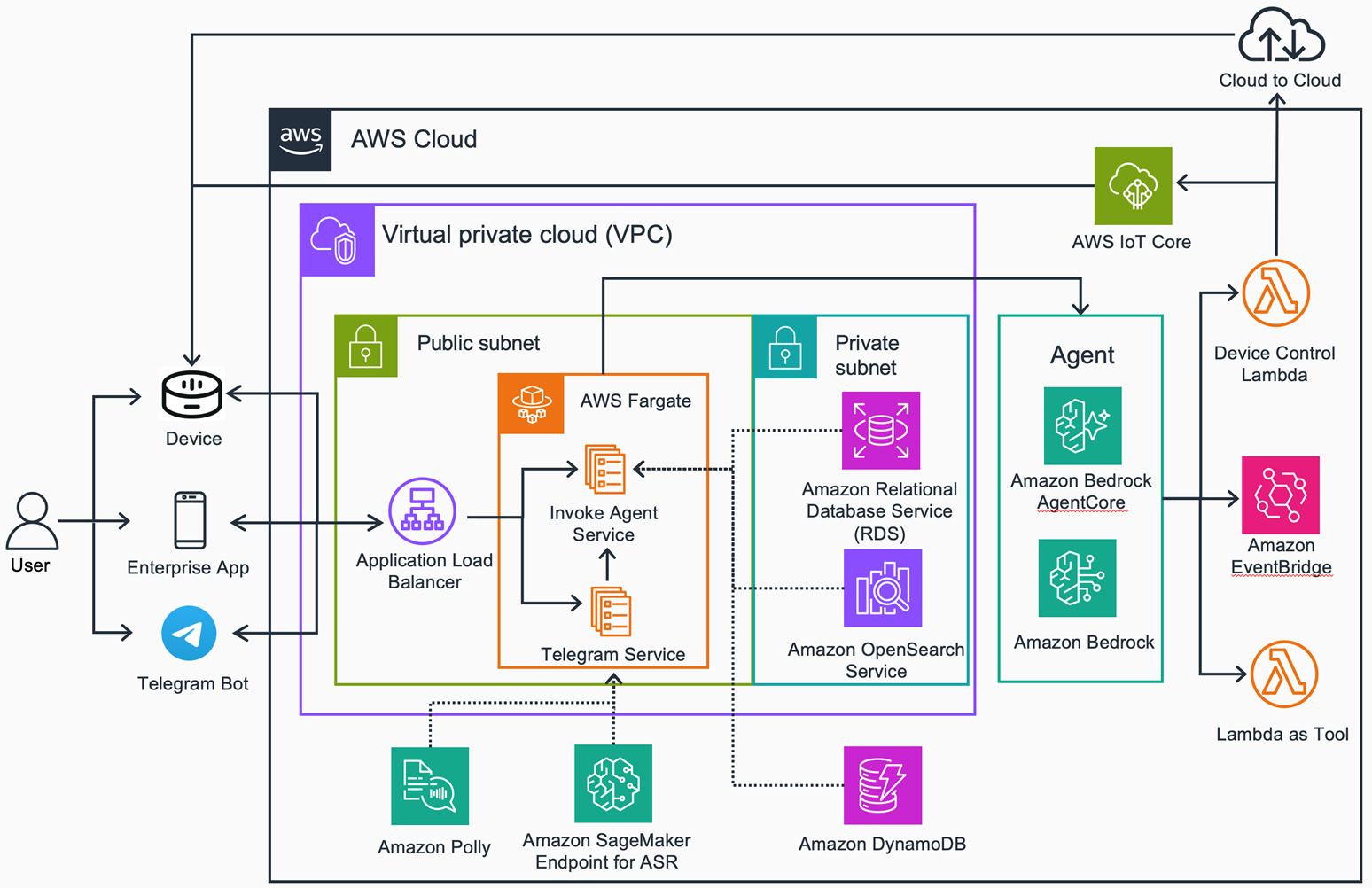
[图 2-1:智能设备交互助手参考架构] |
三、Agent 设计与运行
3.1 Agent 形态与模型选型
Agent 形态选择:在动手写代码之前,需要先回答一个设计问题:用什么形态的 Agent。常见的几种设计如下:
- Single agent:单一 Agent 持有全部工具,独立完成端到端任务。适合工具数量可控、任务边界清晰的场景。
- Workflow:以预定义流程编排多个步骤——控制流由LLM推理决定,但节点之间的依赖关系不需要由模型在运行时决定。适合流程标准化、可枚举所有分支的业务场景。
- Agent loop:Agent 在自身循环内反复推理与执行,直到达成目标或触发终止条件。适合任务步数不可预知的探索型工作。
- Agent as tool:将一个 Agent 封装为另一个 Agent 可调用的工具,用于将复杂子能力(例如多步推理或专业领域问答)作为模块复用。
- Supervisor agent:上层 Agent 负责任务拆解与调度,将子任务路由给若干下层专业 Agent。适合多领域协同的复杂任务,例如同时涉及多意图、多设备的服务请求。
设备控制助手在实际业务中并非天然只对应某一种形态——它涉及自然语言理解、设备状态读写、定时任务、跨设备协同、多语言、多渠道接入等多类子能力,复杂度差异很大。形态选择最终是在成本、延迟、智能程度这三个维度之间取舍:Workflow 与 Single agent 在成本与延迟上更可控,但能处理的意图边界相对有限;Agent loop、Agent as tool、Supervisor agent 等组合形态扩展了处理深度与跨域协同能力,但单次交互的成本与延迟也会相应上升。具体到本文讨论的设备控制场景——用户输入一句意图,Agent 在有限步骤内完成”理解—调工具—生成回复”的闭环——Single agent 形态在三者之间的平衡点较为合适,因此作为主线展开。需要更复杂调度(例如同时跨家居、出行、家电跨域协同)时,可在此基础上向 Supervisor agent 等形态演进。
模型选型:模型选型不是一个一次性的、全局唯一的决定——需要配合 Agent 设计与具体业务诉求展开。在多模块、多节点的 Agent 系统中,不同模块完全可以采用不同模型:复杂任务的拆解与调度(例如 Supervisor 上层、跨域决策节点)建议选用智能程度更高的模型,承担单一职责的子节点则可挑选推理速度更快、单次成本更低的轻量模型。这种”按节点选型”的策略可以在保证整体智能水平的同时,把延迟与成本压在合理区间。
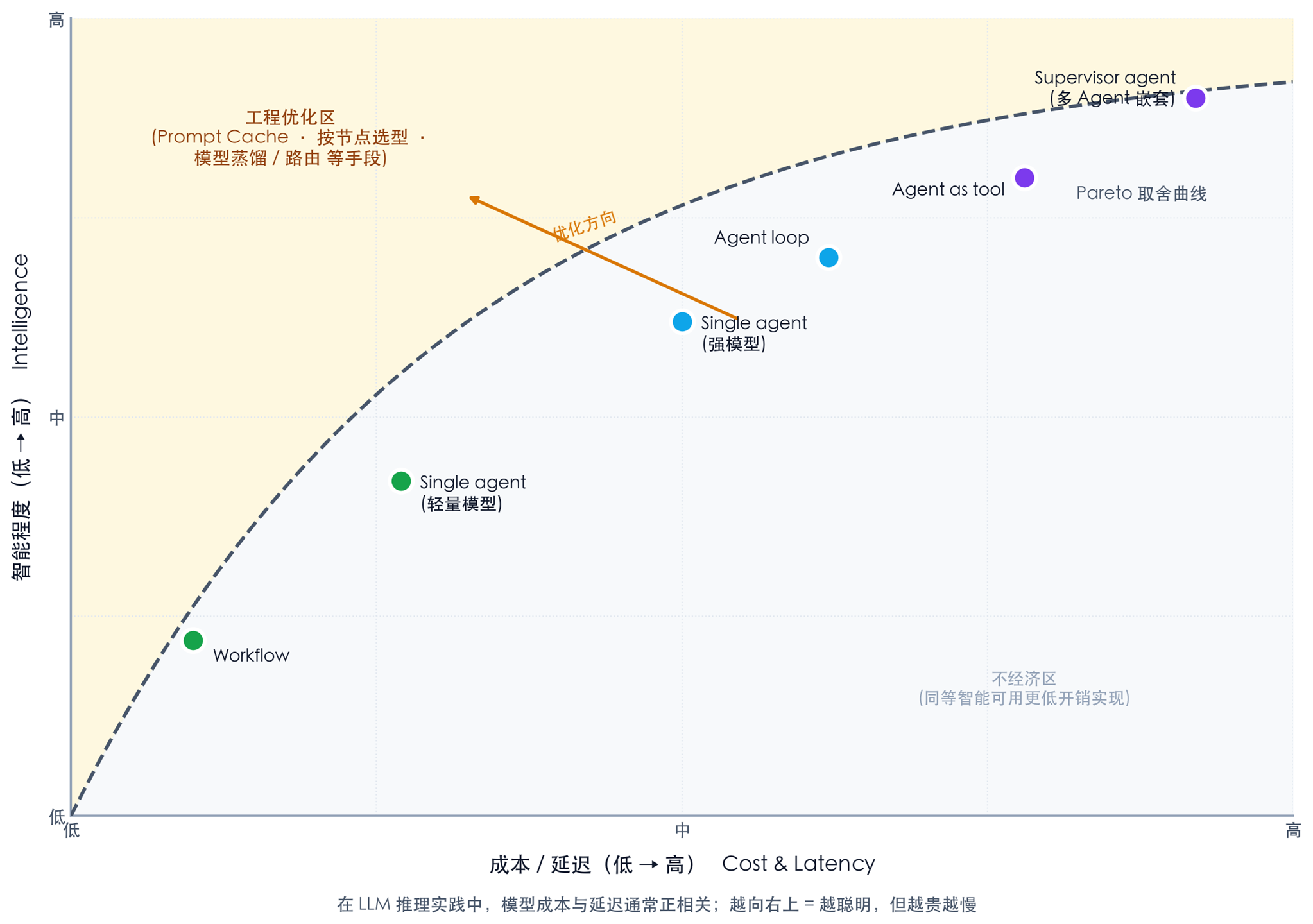
[图 3-1:成本、延迟与智能程度的三维取舍] |
3.2 Prompt 与 Prompt Cache 设计
Prompt Cache 是 Amazon Bedrock 提供的提示词前缀缓存能力——将 Prompt 中稳定的前缀缓存住,命中后直接复用,对应区段不再重新计算与计费,从而显著降低单次推理的延迟与成本。在多用户、多轮次的 Agent 场景下,正确利用这项能力是把整体推理成本压在合理区间的关键设计点。
System Prompt 中通常包含大量稳定内容:业务规则、风格约束、few-shot 示例,以及工具的元信息(name、description、input_schema)。这些内容每一轮推理都会被完整重发,直接拉高单次推理的延迟与计费成本,但Prompt Cache可以稳定缓存这部分,数倍降低成本和推理时延。
对消费级场景而言 Prompt Cache 还有一项额外价值——缓存不绑定用户,只要前缀逐字节一致,所有用户共享同一份缓存,规模化下成本曲线明显平缓。
要让缓存真正生效,提示词设计须遵守一条原则:用户个性化内容(用户名、偏好、设备清单、历史摘要等)一律放在 Prompt 末尾,绝不混入前缀——一旦混入,缓存即被切碎,跨用户共享变为零。
cache point 标记可缓存前缀的结束位置:其前的内容被纳入缓存,其后的内容作为本轮动态输入参与计算。我们在三处打点:System Prompt 之后、工具定义之后、多轮对话末尾。下面是 Bedrock Converse API 的伪代码示意:
三个打点的命中模式由稳定到易变递推:
- ① system 层 — System Prompt 在所有用户、所有轮次中保持一致,命中率最高,跨用户共享。
- ② tools 层 — 工具集合稳定时命中。工具增删时该点缓存失效,但 ① 仍然有效。
- ③ rolling 层 — 单用户多轮对话内命中。在每轮 user 消息末尾打点,让本轮的对话历史在下一轮自动成为可命中的前缀。
请求到达时,Bedrock 从最长前缀开始匹配缓存,命中部分跳过重计算与重计费。Bedrock 默认 5 分钟 TTL 适配高频对话;System Prompt 与工具定义这类访问间隔可能跨会话的稳定段,可显式声明 1 小时 TTL({"ttl":"1h"})以提高命中率。
3.3 Agent 托管:Amazon Bedrock AgentCore
Agent 主体的设计与提示词策略明确之后,下一步是把它放到一个生产级的运行时里跑起来。Amazon Bedrock AgentCore Runtime 是 AWS 为 Agent 应用提供的托管运行时,承担 Agent 容器化部署、弹性伸缩、会话隔离与多渠道接入等基础设施关注点——开发者只需提交 Agent 代码,无需自行管理底层资源。直接部署在 Runtime 上的好处是:开箱即得生产级别的高可用与扩缩容,配合 VPC、IAM 等 AWS 原生安全机制,可以快速进入正式上线状态,省去自建运行时的工程投入。
围绕 Runtime,AgentCore 还提供了一组配套服务:AgentCore Gateway 把各类后端能力以 MCP 协议统一暴露给 Agent,本文 2.4 节展开使用;AgentCore Memory 提供会话与长期记忆管理;AgentCore Identity 处理 Agent 与下游系统之间的身份与访问控制;AgentCore Observability 提供调用链追踪、指标监控与运行时审计——观测与评估在生产环境中同样重要,缺乏可观测性的 Agent 在出问题时几乎无法定位,缺乏评估机制的 Agent 也很难在迭代过程中量化质量变化。这些服务可按业务需要按需启用,完整服务能力与文档可参考 Amazon Bedrock AgentCore。
3.4 工具:Agent 与外部能力的契约
Agent 主体只承担意图理解与决策职责,所有需要与外部系统交互或改变系统状态的操作(调用 IoT API、写入调度系统、读写数据库等)一律以工具(Tool)的形式暴露给模型。这种职责切分有三方面收益:
- 可验证:工具是结构化输入输出的接口,调用契约明确,可独立做单元测试与契约测试。
- 可观测:每次工具调用对应一条独立的执行记录,调用链完整可追溯。
- 可演进:业务规则的调整收敛在工具实现内,不必随之回归整个系统 Prompt。
如果将业务规则写入 Prompt(例如在 Prompt 中描述各类条件分支与执行顺序),上述三项收益均无法获得,且 Prompt 的脆弱性会随业务复杂度快速放大。
Agent 主体与工具实现之间通过 Amazon Bedrock AgentCore Gateway 解耦。Gateway 将各类后端能力(AWS Lambda、HTTP API、内部服务等)统一封装为 Model Context Protocol(MCP)格式的工具,模型侧以一致的接口调用,无需感知底层实现细节。这一层抽象带来两个工程上的好处:一是 Agent 主体(Prompt 与模型配置)保持稳定,工具实现可独立迭代而无需重启 Runtime;二是底层后端形态可自由替换,例如从 Lambda 迁移到 ECS 仅需更新 Gateway target 配置。
3.5 设备 IoT 控制工具
设备控制类工具的核心动作是下发 IoT 指令。常见的工具形态有三个:list_devices 获取设备清单及在线状态,query_device 查询设备实时状态,control_device 下发控制指令。
底层链路按设备厂商的 IoT 平台形态有两种典型选择:
- 云云对接:厂商已有自建 IoT 云平台,对外开放 OAuth2 等标准协议。Agent 工具实现层(例如 AWS Lambda)按用户身份获取 Token,再调用厂商云端 API 完成指令下发与状态查询。本场景采用此种形态,下文细节也以此为基准。
- AWS IoT Core 直连:厂商在 AWS 上构建 IoT 后端,设备直接接入 AWS IoT Core 并通过 MQTT topic 与设备影子(Device Shadow)维持双向通信。此情形下,工具实现层调用 AWS IoT Core API(如
Publish、UpdateThingShadow)即可完成指令下发,无需经过外部 OAuth 与公网 API,链路更短、延迟更低。
工具实现统一部署在 AWS Lambda 中,运行于 VPC 私有子网。云云对接形态下出网经由 NAT Gateway,因为多数厂商 IoT 云端会拒绝 AWS Lambda 默认公网 IP 段;AWS IoT Core 直连形态下则可通过 VPC Endpoint 走内网调用,无需 NAT。
用户身份的区分。 多租户场景下,每次工具调用都必须携带当前用户的 user_id。user_id 由应用层在 Agent 调用入口注入,并在 AgentCore Gateway 的 tool schema 中声明为 required 字段,由 Gateway 强制校验,避免 LLM 遗漏或伪造。user_id 解析自接入渠道的会话上下文:Web 来自 session cookie,即时通讯渠道来自渠道用户标识到内部 user_id 的绑定映射(绑定流程见 3.4 节)。
云云对接下的 OAuth Token 维护。 Lambda 拿到 user_id 后,按 ID 取出对应的 OAuth Token 调厂商 API。Token 持久化在 RDS 表 oauth_tokens(user_id, access_token, refresh_token, expires_at),FastAPI 与 Lambda 各自维护内存缓存,30 秒安全裕量。刷新分主动与被动两路:FastAPI 后台线程每 30 分钟批量刷新所有 Token;调用时若发现过期则就地刷新。
3.6 时序调度工具
时序调度类工具的核心是把”什么时间做什么事”这件事整体下沉到 Amazon EventBridge Scheduler,应用层不再维护任何定时器或常驻调度进程。Agent 一侧暴露三个工具:create_schedule 创建一次性延迟(delay_minutes)或周期性(cron_expression)任务,list_schedules 列出当前用户的所有任务,cancel_schedule 取消任务。模型负责把”明天早上 7 点开空调”翻译成调度参数,剩下的交由 EventBridge 处理。
到点之后 EventBridge 回调同一个 Lambda 的 execute_scheduled_task action,再走一次和实时控制完全一样的 IoT 调用路径。这套机制带来三个好处:调度状态由 EventBridge 托管,应用层无状态、可任意水平扩容;一次性任务通过 ActionAfterCompletion: DELETE 自动回收,不残留垃圾数据;Scheduler 单租户最高支持 100 万 schedule,多租户基于名字前缀(sched-{user_id}-...)做天然隔离。

[图 3-2:定时任务端到端链路] |
四、社交软件的集成:以 Telegram 为例
前两章讲 Agent 怎么扩能力,这一章讲 Agent 怎么走向用户。
Telegram、WhatsApp这类即时通讯渠道是消费级 AI Agent 触达用户最低摩擦的分发方式——用户加好友就能用,本章以 Telegram 为例,介绍社交软件如何与智能设备交互Agent集成。
4.1 两种接入方式
Telegram Bot API 提供两种接入:
- Long Polling(`getUpdates`):后端进程主动轮询 Telegram 服务端拉取新消息。
- Webhook(`setWebhook`):向 Telegram 注册一个 HTTPS URL,新消息由 Telegram 主动 POST 推送过来。
4.2 Polling 模式
Polling 由后端进程定期向 Telegram 发起请求拉取最新 Update。Telegram 在指定 timeout 内若有新消息即返回,否则空响应。
实现非常轻量,对基础设施零要求——不需要公网 HTTPS、不需要证书、不需要域名:
每个 bot 占用一个 asyncio.Task,task 内部维护一条出向 HTTPS long-polling 连接到 api.telegram.org。
适用场景:开发调试、单机部署、用户量较小的内部测试环境。
4.3 Webhook 模式
Webhook 由后端调用 setWebhook 注册一个 HTTPS URL 给 Telegram,新消息时 Telegram 主动 HTTPS POST 这个 URL,body 是一个 Update JSON。后端零常驻出向连接,承载能力只取决于 HTTP 入口的扩展能力。
入口典型实现只做签名校验和异步分发:
异步处理(小流量阶段进程内 asyncio.create_task 即可,规模化时换队列)按 telegram_user_id 路由到对应租户,再调下游 Agent,回复通过独立的 sendMessage 调用送达。
适用场景:生产环境、多租户公共 Bot、需要水平扩容的大流量服务。
4.4 规模化对比:为什么选 Webhook
在进入对比之前,先点明一个产品形态层面的选择:Bot 的拥有者是谁。落到实际业务里通常有两种走法:
- 企业级公共 Bot:企业(即业务运营方)创建并持有一个公共 Bot,所有用户都是这个 Bot 的好友。绑定流程在业务后端完成,Bot 名称、头像、菜单全局统一。这是消费级 IoT 与 ToC 场景的默认形态。
- 每用户自带 Bot:每个租户/家庭/商家在 BotFather 自建一个 Bot,将 token 提交给业务后端代管。这种形态下租户可以自定义 Bot 品牌,单 Bot 被封不影响他人,但用户冷启动需要自行操作 BotFather,门槛较高。
两种形态对 Polling 与 Webhook 的承载能力要求差异极大——Bot 数量为 1 还是为 N,是后续讨论扩展性的前提。下面分别看两种接入方式在用户量爬升后的表现差异。
Polling 的资源开销随用户数线性增长。 在 Polling 模式下,每个 Bot 进程都要维持一条到 api.telegram.org 的出向长连接,并持续承担拉取、解析、分发的全过程。”每用户自带 Bot”形态下,进程数、TCP 连接数、CPU 占用三项都随租户数线性上升——10 个 Bot 与 10 万 Bot 之间没有任何复用空间。即便选择”企业级公共 Bot”只有单个 token,该 token 也只能由单个进程独占,因为多进程并发同一 token 会被 Telegram 直接拒绝。两种形态下,Polling 在用户量上来后都会撞墙。
Webhook 的资源开销与用户数解耦。 Webhook 把”何时来消息”的判断让出给 Telegram,后端只需在消息到达时才分配资源处理一次,没有空跑的拉取循环。HTTP 入口本身无状态,背后挂多少实例由 ALB / CloudFront 自由分发,水平扩容只看后端处理能力。出向连接为 0,入向连接由 Telegram 端按需建立。
消息送达时延。 Polling 的延迟受轮询间隔与 timeout 影响,最坏情况下用户感知到的”卡顿”可达几秒;Webhook 是事件驱动,消息生成到推送的延迟稳定在几百毫秒以内。
真正高并发场景:自建 Bot API Server。 若并发规模进一步突破,Telegram 官方支持自建 Bot API Server,将 HTTP→MTProto 的代理层搬到自己机房。自建版相比云版在并发连接数、文件上传上限、webhook 端口与协议等方面均有显著放宽。代价是要自己运营这层服务的可用性。一般业务用云版 Webhook 已经足够,自建版主要服务于超大文件传输或单 Bot 极致并发的情形。
结论:生产环境、规模化场景一律选 Webhook。Polling 仅作为开发调试或小规模过渡形态使用。
4.5 Webhook 模式下的鉴权与用户绑定
确定走 Webhook 加企业级公共 Bot 之后,要落地一套完整的鉴权与绑定机制——这套机制要解决两类问题:企业侧如何把 Telegram Bot 与 Agent 后端在通信链路上接通并完成请求鉴权;用户侧如何在首次接入时完成身份绑定,并在之后的每一次对话里被准确识别。下面分别按这两条线设计。
4.5.1 企业视角:把 Bot 和 Agent 接通
对企业来说,整个事情从一次”申请”开始。在 Telegram里建一个公共 Bot,拿到 bot_token,这就是企业对外的入口——同一个名称、同一个头像、同一个菜单,给所有用户用。
然后回到后端。按前面两章的设计把 Agent 主体搭起来——AgentCore Runtime 跑模型,AgentCore Gateway 接工具,工具按 IoT 控制和时序调度两类组织好。再向公网暴露一个 HTTPS 入口,等着 Telegram 把消息推进来。
最后一步是将 Telegram 平台与企业后端在协议层面接通。业务后端调用 Telegram 的 setWebhook 接口,将入口 URL 与一个自定义的 secret_token 一并注册,注册成功后该 Bot 的所有用户消息均由 Telegram 平台主动推送至该入口。secret_token 会随每一次请求附在 HTTP header 中传回,业务后端通过比对该 header 即可验证请求来源,避免伪造。Telegram 同时公布了平台侧的回源 IP 段,可在 ALB 或 WAF 上配置白名单作为辅助校验;但官方说明该 IP 段未来可能变更,因此主鉴权应以 Secret Token 为准。
至此,企业侧通信链路完成搭建:用户在 Telegram 上添加该 Bot 后,所有消息均会由 Telegram 平台推送至企业 Agent 后端。
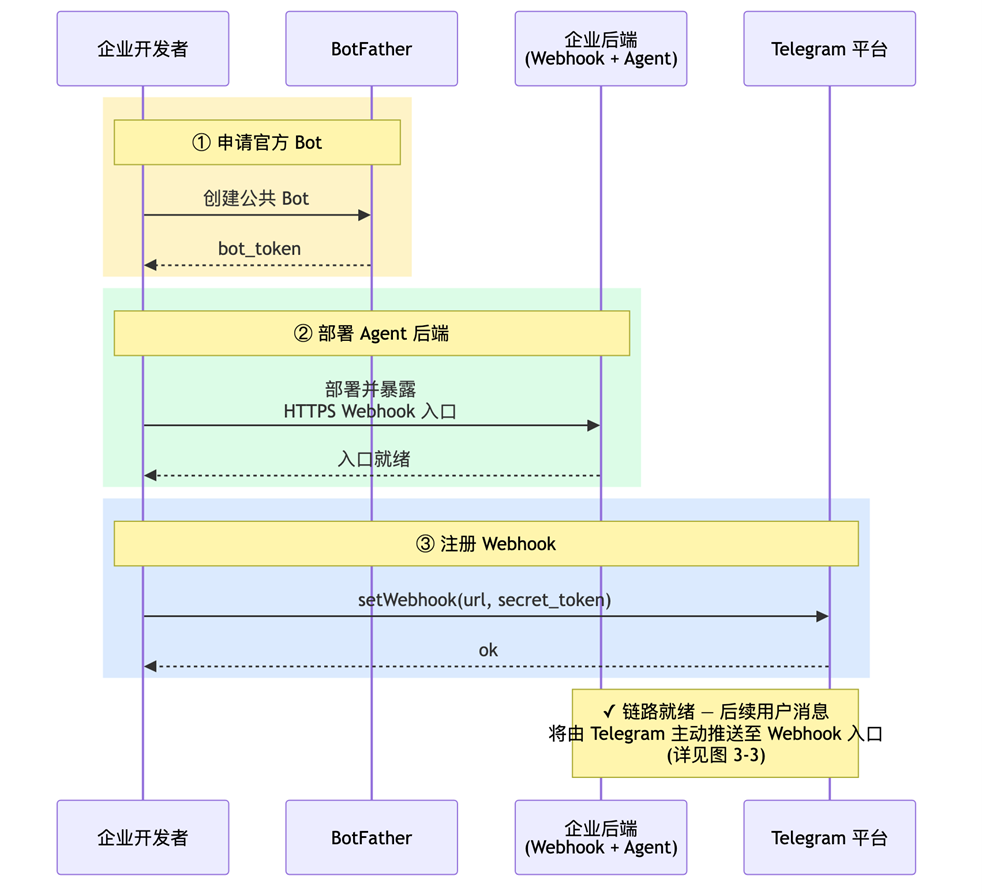
[图 4-1:企业视角 — 通信链路] |
4.5.2 用户视角的使用体验
链路通了之后,问题转到另一面:消息是谁发的。在 Telegram 上每个用户的身份是一串 telegram_user_id,但企业的业务体系里只认它自己的账号——只有通过企业的账号体系,才能找到并控制该用户名下绑定的设备。
为了在便利与安全之间取得平衡,我们采用一次性令牌的绑定方案。用户的旅程是这样:先在企业的 App 或官网用既有账号完成登录——这一步本身就是一次正规的身份认证,依赖企业既有的密码、二次验证或风控体系,安全责任不外溢到 Telegram 一侧。登录后点击”绑定 Telegram”,业务后端生成一个一次性令牌,与当前账号在数据库内建立映射,赋予较短的有效期(典型为分钟级),且只能消费一次。前端将令牌展示给用户,并提示:”请到 Telegram 中向官方 Bot 发送 /bind <令牌>“;反向地,若用户先在 Telegram 上找到官方 Bot,后端检测到该 telegram_user_id 尚未绑定时,也应引导用户回到官方 App 生成令牌并复制回来完成绑定。
这一设计有几个关键的安全考量。其一,令牌不携带任何账号身份信息,仅作为一次性凭据,即便被截获也无法反推用户身份;其二,令牌生命周期短且单次消费,配合每次生成新令牌即作废上一枚的策略,将泄露窗口压到最低;其三,业务密码不进入 Telegram 通道,避免在 Bot 进程或第三方平台上留下密码痕迹;其四,令牌的核销与映射写入是同一笔原子事务,杜绝并发条件下被重复绑定到不同 Telegram 账号的可能。
用户切到 Telegram,复制粘贴发出去。这条消息走了和日常对话一模一样的链路——Telegram 推到企业的 Webhook 入口,校验 Secret Token,进到业务后端。后端识别出这是一条绑定指令,原子地把令牌核销掉,同时在数据库里写下一行:这个 telegram_user_id 对应那个企业账号。Bot 回一句”绑定成功”,整段旅程结束。

[图 4-2:用户绑定旅程] |
绑定一次之后,事情就变得非常顺了。用户后面在 Telegram 上随便说一句”打开客厅空调”,Webhook 收到 update,从 payload 里拎出 telegram_user_id,到映射表里一查得到企业账号 user_id,把它注入到 Agent 调用的上下文里——剩下的就是第二章已经设计好的那套:模型理解意图,Gateway 派工具,Lambda 凭 user_id 取出 OAuth Token 调下游 IoT API,回复异步通过 sendMessage 发回 Telegram。从用户视角看,就是发一句话、过几秒、收到回复,跟跟朋友聊天没差。

[图 4-3:绑定后的日常通信链路] |
五、总结
智能硬件的人机交互正在被 Agent 重写——用户在 Telegram 这样熟悉的社交工具里开口说话,企业后端的 Agent 听懂意图、派发工具、控制设备,回复又顺着同一条链路送回。这套范式背后并不需要从零搭建:Amazon Bedrock AgentCore 把 Agent 主体托管起来,AgentCore Gateway 把工具调用解耦,IoT 控制与时序调度落到 Lambda 与 EventBridge Scheduler,公共 Bot 加一次性令牌把用户身份和企业账号干净地对上。AWS 把这些常用能力沉淀为 Intelligent Device Assistant 行业解决方案,客户做适配落地即可。如果你正在做类似的智能硬件、IoT 或消费级 Agent 集成,欢迎联系您的 AWS 解决方案架构师进一步交流。
➡️ 下一步行动:
相关产品:
- Amazon Bedrock — 用于构建生成式人工智能应用程序和代理的端到端平台
- AWS Lambda — 无需服务器即可运行代码
- Amazon Bedrock AgentCore — 加快代理投入生产的速度
- Amazon EventBridge — 大规模构建事件驱动应用程序
- Amazon IoT Core — 设备连接到云
相关文章:
- 自己的工具自己控:MCP Server、Amazon Bedrock AgentCore、Quick Suite集成指南
- 当 AI Agent 学会”忘记”:Amazon Bedrock AgentCore Memory 的记忆哲学”
- 实现工作流程现代化:Amazon WorkSpaces 现已为人工智能代理提供专属桌面(预览版)
- 当 OpenClaw 学会”团队记忆”:一个面向多客户服务的企业级共享记忆系统设计
- (上篇)基于 AWS Bedrock AgentCore 构建企业级航空客服智能体 —— 基于AIDLC方法从需求分析到生产部署的完整实践
六、相关资料
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
