亚马逊AWS官方博客
对数据库中存储的程序进行现代化改造,以使用 Amazon Aurora PostgreSQL 联合查询、pg_cron 和 AWS Lambda
对数据库进行现代化改造没有一刀切的方法。您需要仔细规划自己的转型之旅,并制定明确的目标和成果。如果在数据库层处理某些逻辑符合您的业务需求,则可以考虑本文中介绍的方法。有关其他指导,请参阅将 Oracle 数据库迁移到 AWS Cloud 和将 Microsoft SQL Server 数据库迁移到 AWS Cloud。
PostgreSQL 扩展
在开始之前,我们看看我们的解决方案中使用的 PostgreSQL 扩展。
postgres_fdw 是一个外部数据封装器,用于访问远程 PostgreSQL 服务器中的数据。Amazon Relational Database Service (Amazon RDS) for PostgreSQL 和 Aurora PostgreSQL 支持此扩展。借助 postgres_fdw,您可以实现联合查询,以便从远程 PostgreSQL 数据库实例检索数据、将其存储在集中式数据库中或生成报告。
AWS Lambda 在高度可用的计算基础设施中运行代码,无需预调配或管理服务器和操作系统维护。Lambda 中的代码以函数形式组织,支持多种编程语言,例如 Python、Node.js、Java 和 Ruby。aws_lambda 扩展提供从 Aurora PostgreSQL 调用 Lambda 函数的功能。此扩展还需要 aws_commons 扩展,它为 aws_lambda 和许多其他 PostgreSQL 的 Aurora 扩展提供帮助程序函数。如果存储过程中出现错误,您可以将错误消息发送到 Lambda 函数,然后使用 Amazon Simple Notification Service(Amazon SNS)向数据库管理员发送通知。
您可以使用 pg_cron 来调度 SQL 命令,它使用与标准 CRON 表达式相同的语法。我们可以使用此扩展调度存储的程序并自动执行日常维护任务。
解决方案概览
源数据库由我们要检索并加载到报告数据库中的表和数据组成。pg_cron 扩展根据预定义的计划运行存储的程序。存储的程序基于预定义的业务逻辑复制数据。如果遇到任何错误,它将调用 Lambda 函数,向订阅了 SNS 主题的用户发送错误通知。下图展示了该解决方案的架构和流程。

在这篇博文中,我们将引导您完成使用 AWS CloudFormation 创建资源、配置存储的程序和测试解决方案的步骤。
先决条件
请务必完成以下必备步骤:
- 设置 AWS 命令行界面(AWS CLI)以运行用于与 AWS 资源交互的命令。
- 拥有与您的 AWS 账户中的资源进行交互的适当权限。
使用 AWS CloudFormation 创建资源
此解决方案的 CloudFormation 模板部署了以下关键资源:
- 用于源数据库和报告数据库的两个 Aurora PostgreSQL 集群,包含数据库表和存储的程序
- 用于将错误消息转发到 Amazon SNS 的 Lambda 函数
- 电子邮件通知的 SNS 主题
- AWS Cloud9 实例,用于连接到数据库进行设置和测试。
在运行此解决方案之前,使用 AWS 定价计算器估算成本。部署的资源不符合免费套餐的条件,但如果您选择堆栈默认设置,假设您在一小时内清理了堆栈,则所产生的费用应低于 3.00 美元。
要创建资源,请完成以下步骤:
- 通过从终端运行以下命令克隆 GitHub 项目:
- 使用以下代码部署 AWS CloudFormation 资源。将
youreamil@example.com替换为有效的电子邮件地址。资源预调配大约需要 15 到 20 分钟才能完成。您可以前往 AWS CloudFormation 控制台并验证状态是否显示为
CREATE_COMPLETE,从而确保成功部署堆栈。

创建堆栈时,您会收到一封确认订阅 SNS 的电子邮件。 - 在电子邮件中选择确认订阅。


将打开一个浏览器窗口,其中包含您的订阅确认。
配置存储的程序
要配置存储的程序,请完成以下步骤:
- 在 AWS Cloud9 控制台的 Your environments(您的环境)下,选择环境
PostgreSQLInstance。 - 选择 Open IDE(打开 IDE)。
这将打开一个 IDE,用于配置、部署和测试存储的程序。 - 在您的 Cloud9 终端中,运行以下命令以克隆存储库并安装所需的工具:
该脚本需要 5 分钟来安装所有必需的工具。在进入下一步之前,请确保安装已完成。

- 运行以下命令初始化环境变量:
- 通过运行以下 shell 脚本命令创建源数据库对象和报告数据库对象:
此脚本创建
employee表和department表,并在源数据库中插入一些示例记录。脚本在源数据库中创建数据库对象后,它会在
reporting数据库中创建employee表以及employee_sp、error_handler_sp和schedule_sp_job存储的程序。作为最后一步,它将创建postgres_fdw扩展、外部服务器、用户映射和外部表,以便从源数据库中提取数据。要了解有关postgres_fdw的更多信息,请参阅 PostgreSQL 文档。 - 逐个运行以下命令,观察源数据库中的表和模式:

employee表存储原始数据,其中可能包含空值和重复值。department表用作部门名称的查找表。 - 使用以下命令退出源数据库:
- 逐个运行以下命令,观察报告数据库中存储的程序和表:
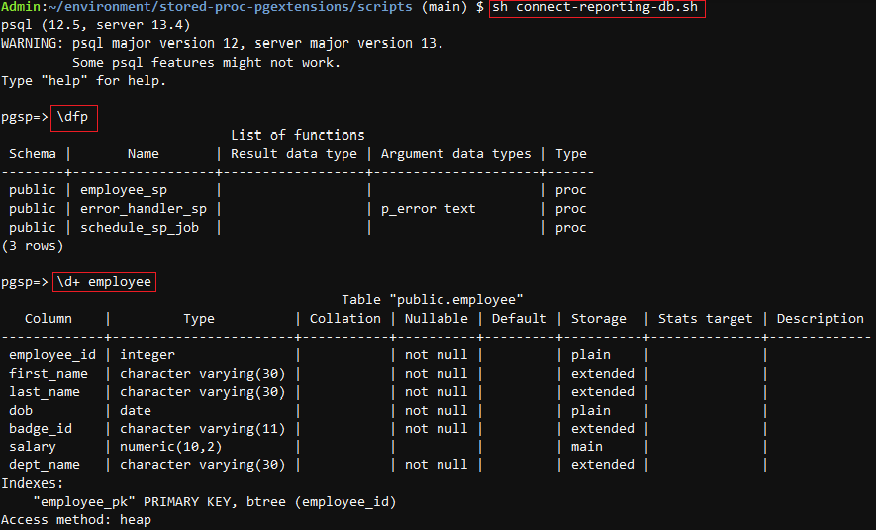
employee_sp存储的程序验证员工源表中的原始数据并将其复制到报告数据库中的员工表。error_handler_sp处理错误并向注册的电子邮件地址发送通知。schedule_sp_job通过创建 cron 作业自动调度employee_sp程序的运行。 - 使用以下命令退出数据库:


测试存储的程序
我们创建了所有必需的表和存储的程序之后,就可以测试解决方案了。运行以下 shell 脚本:
这将调用报告数据库中的 employee_sp 存储的程序。它使用以下代码验证员工和部门数据并将其从源数据库复制到报告数据库中的 employee 表:
逐个运行以下命令,验证报告数据库的 employee 表中插入的记录:

使用以下命令退出数据库:
测试错误通知
源表可能包含重复的记录,我们不希望在报告数据库中插入重复的记录。您可以验证存储的程序在尝试将重复记录插入报告数据库的员工表时是否会引发错误并发送电子邮件通知。
我们通过运行以下 shell 脚本来模拟错误场景:
该脚本在源数据库的 employee 表中插入一条重复的记录,然后运行 execute_sp.sh 调用 employee_sp() 存储的程序将数据从源数据库复制到远程数据库。
在报告数据库中插入重复记录时,会发生主键冲突。此异常会在 exception 块中捕获,并调用 error_handler_sp 存储的程序。请参阅以下代码:
调用 error_handler_sp 存储的程序时,如果不存在,它将创建 aws_lambda 扩展。然后它将错误消息传递给调用该函数的 Lambda 函数 ExceptionLambda。
Lambda 函数将错误消息发布到 SNS 主题。您会收到一封主题为“存储的程序错误”的电子邮件,通知您在尝试插入重复记录时出现异常。
调度您的存储的程序
在生产环境中,您可能希望调度存储的程序以自动方式运行。
- 运行以下 shell 脚本以调度存储的程序的运行:
该脚本刷新数据库对象以进行测试,并调用
schedule_sp_job存储的程序。schedule_sp_job创建pg_cron扩展(如果 pg_cron 不存在),并调度每 10 分钟运行一次employee_sp存储的程序的 cron 作业。 - 在报告数据库中运行以下 SQL 查询,以确认 cron 作业的创建。我们使用 cron 表达式
*/10 * * * *来允许作业每 10 分钟运行一次。 - 您可以使用以下 SQL 查询查看计划作业的状态:
10 分钟后,清理后的数据将填充到报告数据库的
employee表中。 - 现在,您可以通过运行以下 SQL 命令来取消调度 cron 作业:
使用 pg_cron,您可以定期调度 SQL 命令的执行以执行重复性任务。
清理
为避免产生持续的费用,请从 AWS CloudFormation 控制台中删除 AmazonAuroraPostgreSQLStoredProc 堆栈来清理基础设施。删除作为本练习的先决条件而创建的任何其他资源。
结论
在这篇博文中,我们演示了如何使用 Aurora PostgreSQL 扩展(例如 postgres_fdw、pg_cron 和 aws_lambda)对存储的程序进行现代化改造。Aurora PostgreSQL 扩展通过提供与商业数据库同等的功能来增强数据库开发体验。在规划现代化之旅时,请仔细考虑您的业务目标和成果。
有关 Aurora 扩展的更多信息,请参阅使用扩展和外部数据封装器。有关使用数据库触发器通过 Lambda 和 Amazon SNS 启用近实时通知的信息,请参阅使用数据库触发器、AWS Lambda 和 Amazon SNS 启用来自 Amazon Aurora PostgreSQL 的近实时通知。
告诉我们这篇博文对您的数据库现代化之旅有何帮助。
关于作者
 Prathap Thoguru 是 Amazon Web Services 的一名企业解决方案构架师。他在 IT 行业拥有 15 年以上的经验,是一名已获 9 项 AWS 认证的专业人员。他帮助客户将本地工作负载迁移到 AWS Cloud。
Prathap Thoguru 是 Amazon Web Services 的一名企业解决方案构架师。他在 IT 行业拥有 15 年以上的经验,是一名已获 9 项 AWS 认证的专业人员。他帮助客户将本地工作负载迁移到 AWS Cloud。
 Kishore Dhamodaran 是 Amazon Web Services 的高级解决方案架构师。Kishore 利用他多年的行业和云经验,帮助客户制定云企业战略和迁移之旅。
Kishore Dhamodaran 是 Amazon Web Services 的高级解决方案架构师。Kishore 利用他多年的行业和云经验,帮助客户制定云企业战略和迁移之旅。