亚马逊AWS官方博客
使用 Amazon CloudWatch Contributor Insights 简化时间序列分析
检查多个日志组和日志流将会加大实时分析和诊断问题影响的难度,并会增加其耗时。哪些客户会受影响? 影响程度如何? 一些客户的受影响程度是否会比另一些大,或者是否有异常对象? 或许您已使用阶段式推出战略部署更新,且现在想要在继续进行之前了解是否有任何客户遇到了问题,或者目标客户的一切行为是否按照预期。帮助回答这些问题的所有数据点可能藏在大量日志中,工程师需要查询它们来获取临时测量结果,或者构建并维护自定义控制面板来帮助跟踪。
Amazon CloudWatch Contributor Insights 今天已正式推出,它是一项新功能,可帮助在 CloudWatch Logs 中简化时间序列数据前 N 个贡献因素的分析,从而有助于您更加快速的实时大规模了解影响系统和应用程序性能的人或物。它通过帮助您了解造成操作问题的原因及最受影响的人或物来为您在操作问题期间节省时间。Amazon CloudWatch Contributor Insights 还可以帮助进行系统和业务优化的持续分析,因为它一眼就能轻松发现异常对象、性能瓶颈、主要客户或利用最多的资源。除了日志之外,Amazon CloudWatch Contributor Insights 还可以与 CloudWatch 产品组合中的其他产品结合使用,包括指标和警报。
Amazon CloudWatch Contributor Insights 可以分析 JSON 或通用日志格式 (CLF) 的结构化日志。日志数据可以来源于 Amazon Elastic Compute Cloud (EC2) 实例、AWS CloudTrail、Amazon Route 53、Apache 访问和错误日志、Amazon Virtual Private Cloud (VPC) 流日志、AWS Lambda 日志和 Amazon API Gateway 日志。您还可以选择使用直接发布到 CloudWatch 的结构化日志,或使用 CloudWatch 代理。Amazon CloudWatch Contributor Insights 将实时评估这些日志事件,并显示其中包含数据集中主要贡献因素及唯一贡献因素数量的报告。贡献因素指的是基于各维度的聚合指标,在 CloudWatch Logs 中包含为日志字段,例如 Amazon Virtual Private Cloud 流日志中的 account-id 或 interface-id,或者任何其他自定义维度集。您可以根据自己的自定义标准排序和筛选贡献因素数据。Amazon CloudWatch Contributor Insights 中的报告数据可以显示在 CloudWatch 控制面板上,与 CloudWatch 指标一起绘制成图表,并添加到 CloudWatch 警报中。例如,客户可以将两个 Amazon CloudWatch Contributor Insights 报告中的值与一个指标绘制成图表,以描述受故障影响的客户百分比,并将警报配置为在此百分比违反预定义阈值时发出提醒。
开始使用 Amazon CloudWatch Contributor Insights
要使用 Amazon CloudWatch Contributor Insights,我只需定义一个或多个规则。规则只是一个数据代码片段,用于定义针对 CloudWatch Logs 报告的指标要提取什么情景式数据。要配置一个规则来确定特定指标的主要贡献因素,我提供三个数据项目,即日志组(或组)、评估主要贡献因素所依据的维度及缩小这些主要贡献因素范围所用的筛选条件。为执行此操作,我前往 Amazon CloudWatch 控制台控制面板并从左侧导航链接中选择 Contributor Insights。然后,我进入 Amazon CloudWatch Contributor Insights 主页,在此我可以点击创建规则以开始使用。

 要快速开始使用,我可以从发送日志到 CloudWatch Logs 的各种服务的示例规则库中进行选择。在上面,您可以看到当前有很多示例规则可用于 Amazon API Gateway、Amazon Route 53 查询日志、Amazon Virtual Private Cloud 流日志和容器服务日志。或者,我可以定义自己的规则,在本博文的剩余部分,我将这样做。
要快速开始使用,我可以从发送日志到 CloudWatch Logs 的各种服务的示例规则库中进行选择。在上面,您可以看到当前有很多示例规则可用于 Amazon API Gateway、Amazon Route 53 查询日志、Amazon Virtual Private Cloud 流日志和容器服务日志。或者,我可以定义自己的规则,在本博文的剩余部分,我将这样做。
比如说,我部署了一个应用程序,它将 JSON 格式的结构化日志数据直接发布到 CloudWatch Logs 中。该应用程序有两个 API 版本,一个以使用一段时间并且被认为很稳定,另一个刚刚开始向客户推出。我希望尽早知道,是否有收到新版本、将目标对准新 API 的任何人收到任何故障情况及触发的故障有多少。我的稳定 API 版本将日志数据发送到一个日志组,我的新版本使用另一个组,因此我需要监控多个日志组(因为我还想知道是否有人遇到任何错误,无论版本如何)。
定义规则、报告我的任何 API 所产生的 500 错误及将账户 ID、HTTP 方法和资源路径用作维度的 JSON 如下所示。
{
"Schema": {
"Name": "CloudWatchLogRule",
"Version": 1
},
"AggregateOn": "Count",
"Contribution": {
"Filters": [
{
"Match": "$.status",
"EqualTo": 500
}
],
"Keys": [
"$.accountId",
"$.httpMethod",
"$.resourcePath"
]
},
"LogFormat": "JSON",
"LogGroupNames": [
"MyApplicationLogsV*"
]
}
我可以使用向导选项卡设置规则,或者可以将上述 JSON 粘贴到语法选项卡上的规则正文中。即使我已经有上述 JSON,在本博文中,我仍将使用向导选项卡,您可以看到下面的已完成字段。选择日志组时,我可以从下拉菜单(如果它们已经存在)中选择,或者可以使用按前缀匹配选择选项中的通配符语法(例如 MyApplicationLogsV*)。
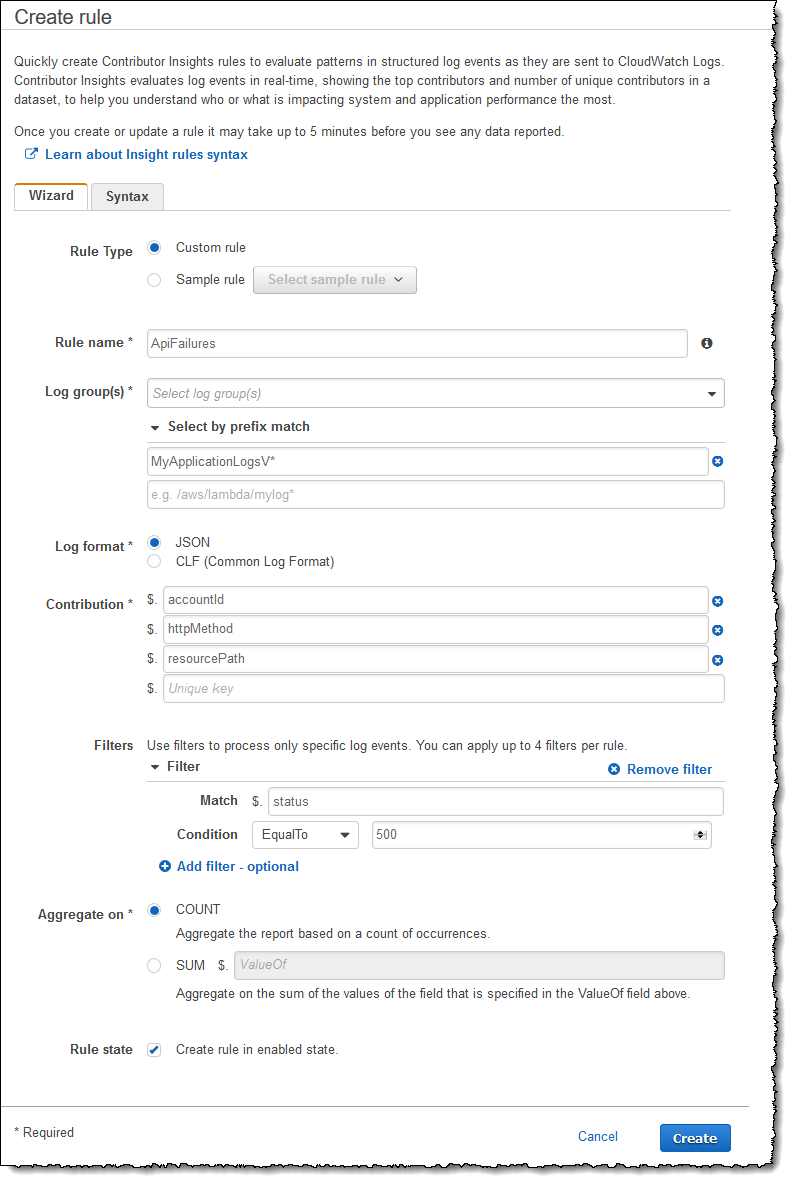 点击创建保存新规则,并使其立即开始处理和分析数据(当然,除非我选择在禁用状态下创建它)。请注意,Amazon CloudWatch Contributor Insights 在规则激活后立即处理新日志数据,它不执行历史检查,因此,我需要为未来预期会发生的操作场景构建规则。
点击创建保存新规则,并使其立即开始处理和分析数据(当然,除非我选择在禁用状态下创建它)。请注意,Amazon CloudWatch Contributor Insights 在规则激活后立即处理新日志数据,它不执行历史检查,因此,我需要为未来预期会发生的操作场景构建规则。
有了规则后,我需要开始生成一些日志数据! 为执行此操作,我将使用通过 AWS Tools for PowerShell 编写的脚本,以模拟被一组客户调用的已部署应用程序。在这些客户中,少数几个精选的客户(我们将他们称之为不幸的客户)将被导向至新 API 版本,他们将会随机出现 HTTP POST 请求失败。使用旧 API 版本的客户将一直成功。运行 5000 次迭代的脚本显示如下。被用于处理 CloudWatch Logs 的 cmdlets 为名称里有 CWL 的脚本,例如 Write-CWLLogEvent。
# Set up some random customer ids, and select a third of them to be our unfortunates
# who will experience random errors due to a bad api update being shipped!
$allCustomerIds = @( 1..15 | % { Get-Random })
$faultingIds = $allCustomerIds | Get-Random -Count 5
# Setup some log groups
$group1 = 'MyApplicationLogsV1'
$group2 = 'MyApplicationLogsV2'
$stream = "MyApplicationLogStream"
# When writing to a log stream we need to specify a sequencing token
$group1Sequence = $null
$group2Sequence = $null
$group1, $group2 | % {
if (!(Get-CWLLogGroup -LogGroupName $_)) {
New-CWLLogGroup -LogGroupName $_
New-CWLLogStream -LogGroupName $_ -LogStreamName $stream
} else {
# When the log group and stream exist, we need to seed the sequence token to
# the next expected value
$logstream = Get-CWLLogStream -LogGroupName $_ -LogStreamName $stream
$token = $logstream.UploadSequenceToken
if ($_ -eq $group1) {
$group1Sequence = $token
} else {
$group2Sequence = $token
}
}
}
# generate some log data with random failures for the subset of customers
1..5000 | % {
Write-Host "Log event iteration $_" # just so we know where we are progress-wise
$customerId = Get-Random $allCustomerIds
# first select whether the user called the v1 or the v2 api
$useV2Api = ((Get-Random) % 2 -eq 1)
if ($useV2Api) {
$resourcePath = '/api/v2/some/resource/path/'
$targetLogGroup = $group2
$nextToken = $group2Sequence
} else {
$resourcePath = '/api/v1/some/resource/path/'
$targetLogGroup = $group1
$nextToken = $group1Sequence
}
# now select whether they failed or not.GET requests for all customers on
# all api paths succeed.POST requests to the v2 api fail for a subset of
# customers.
$status = 200
$errorMessage = ''
if ((Get-Random) % 2 -eq 0) {
$httpMethod = "GET"
} else {
$httpMethod = "POST"
if ($useV2Api -And $faultingIds.Contains($customerId)) {
$status = 500
$errorMessage = 'Uh-oh, something went wrong...'
}
}
# Write an event and gather the sequence token for the next event
$nextToken = Write-CWLLogEvent -LogGroupName $targetLogGroup -LogStreamName $stream -SequenceToken $nextToken -LogEvent @{
TimeStamp = [DateTime]::UtcNow
Message = (ConvertTo-Json -Compress -InputObject @{
requestId = [Guid]::NewGuid().ToString("D")
httpMethod = $httpMethod
resourcePath = $resourcePath
status = $status
protocol = "HTTP/1.1"
accountId = $customerId
errorMessage = $errorMessage
})
}
if ($targetLogGroup -eq $group1) {
$group1Sequence = $nextToken
} else {
$group2Sequence = $nextToken
}
Start-Sleep -Seconds 0.25
}
我开始脚本运行,且在规则启用的情况下,我开始在图表中看到发生失败情况。下面是运行脚本几分钟后的快照。我可以清楚地看到,我的一部分模拟客户在对新 v2 API 进行 HTTP POST 请求时发生问题。

我现在可以从规则面板中的操作下拉列表中继续从此报告创建单个指标,以描述受故障影响的客户百分比,然后将此指标的警报配置为在此百分比违反预定义的阈值时发出提醒。

对于此处概述的示例场景,我将使用警报来停止新 API(如果它已发出)的推出,从而防止影响扩散到其他客户,同时调查故障增加背后的原因。有关如何设置指标和警报的详细信息,可参阅用户指南。
Amazon CloudWatch Contributor Insights 现已在所有商业 AWS 区域(包括中国和 GovCloud)向用户提供。