亚马逊AWS官方博客
将数据仓库迁移到 Amazon Redshift 时的考虑事项
由于 Amazon Redshift 快速、可扩展且经济高效等特点,客户将数据仓库迁移到其中。但是,数据仓库迁移项目可能非常复杂,颇具挑战性。在这篇文章中,我将帮助您了解数据仓库迁移的常见推动因素、迁移策略,以及可帮助您开展迁移项目的工具和服务。
我们首先讨论一下大数据的形势、智能湖仓架构的含义,以及在构建智能湖仓架构时需要考虑数据仓库迁移项目中的哪些事项。
业务机会
数据正在改变我们的工作、生活和娱乐方式。在过去的 20 年中,所有这些行为改变以及向云的迁移带来了数据的爆炸式增长。物联网和智能手机的激增使得每天生成的数据量不断增加。业务模式也发生了变化,因此运营这些业务的人的需求也发生了变化。仅仅几年前,我们讨论的还是 TB 级的数据,而现在已经转变为 PB 级和 EB 级。通过高效地利用数据开展工作并从收集的数据中发掘深入的业务洞察,各种行业和规模的企业可以实现广泛的业务成果。这些核心业务成果可以大致分为以下几类:
- 提高运营效率 – 通过理解从各种运营流程中收集的数据,企业可以改善客户体验、提高生产效率并提高销售和营销敏捷性
- 制定更明智的决策 – 通过整合整个企业的数据,发掘更有意义的洞察,让企业可以制定更明智的决策
- 加速创新 – 将内部和外部数据源结合起来,实现各种 AI 和机器学习(ML, Machine Learning)使用场景,帮助企业实现流程自动化并开启以前无法实现或难以实现的商机
业务挑战
指数级的数据增长也带来了业务挑战。
首先,企业需要访问整个组织中的所有数据,而数据可能会分布在不同的孤岛中。数据源自各种来源,数据类型广泛,数量大,生成速度快。有些数据可能作为结构化数据存储在关系数据库中。另一些数据可能作为半结构化数据存储在对象存储中,例如媒体文件和不断从移动设备流式传输的点击流数据。
其次,要从数据中获得洞察,企业需要通过分析来深入研究数据。这些分析活动通常涉及数十乃至上百名需要同时访问系统的数据分析师。提供一个高性能的系统,能够扩展以满足查询需求,通常是一项挑战。当企业需要与客户共享分析的数据时,情况会变得更加复杂。
最后同样重要的是,企业需要一种经济高效的解决方案来解决数据孤岛、性能、可扩展性、安全性和合规性难题。企业需要能够直观地可视化和预测成本,这样才能衡量其解决方案的成本效益。
为了解决这些挑战,企业需要面向未来的智能湖仓架构以及强大、高效的分析系统。
智能湖仓架构
智能湖仓架构使企业能够以开放格式存储任意数量的数据,打破彼此分离的数据孤岛,让用户能够使用自己偏好的工具或技术运行分析或 ML,并通过适当的安全和数据治理控制措施管理对特定数据的访问权限。
AWS 数据湖架构是一种智能湖仓架构,使您能够将数据存储在数据湖中,并使用一系列围绕数据湖构建的专用数据服务,如下图所示。这使您能够制定出快速、敏捷、大规模且经济高效的决策。有关详细信息,请参阅 AWS 上的现代数据架构。
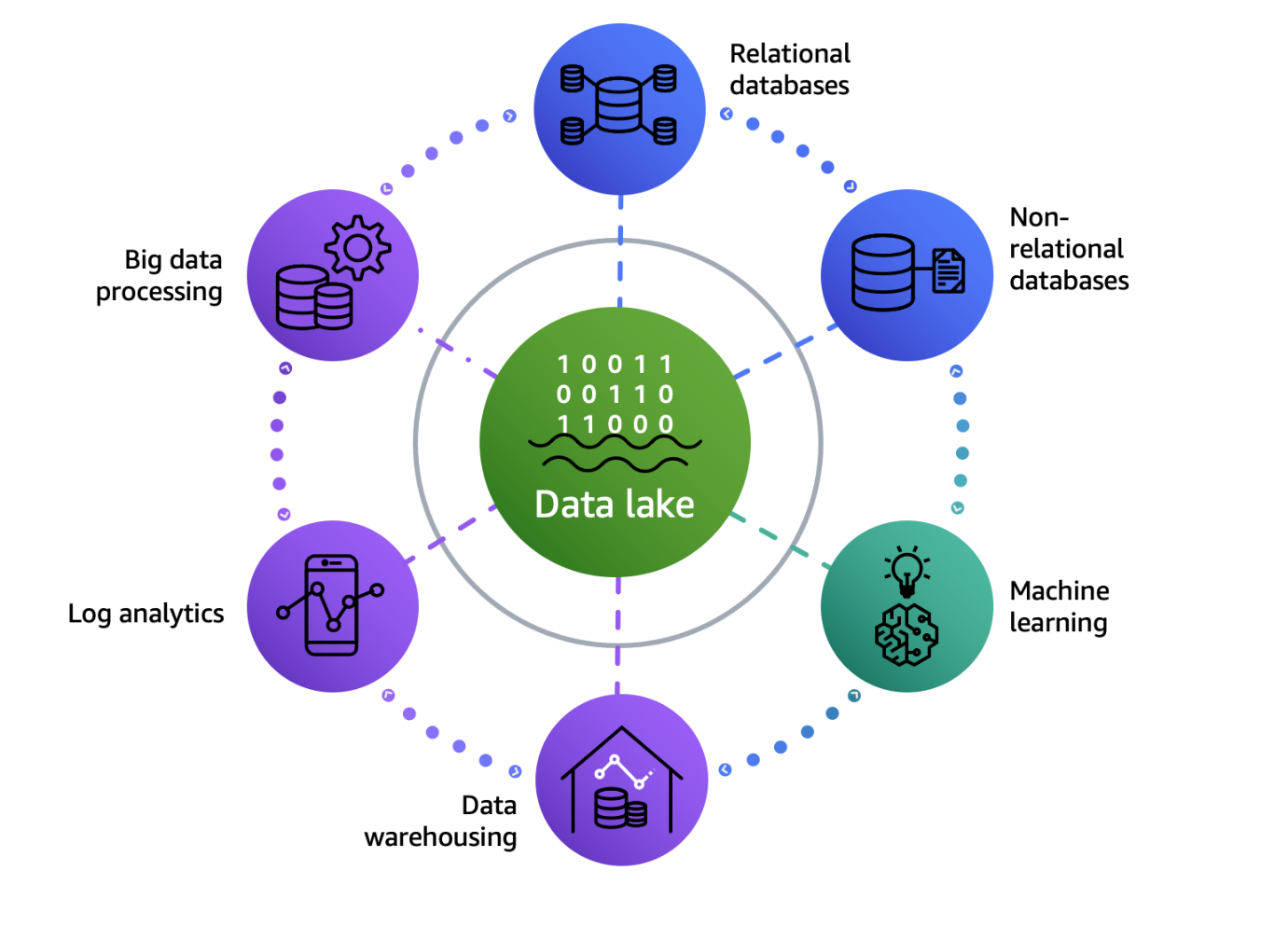
现代化数据仓库
Amazon Redshift 是一个完全托管式、可扩展的现代化数据仓库,提供快速、轻松且安全的大规模分析,加快获取洞察的速度。借助 Amazon Redshift,您可以分析所有数据,在任意规模下都能以低廉且可预测的成本获得高性能。
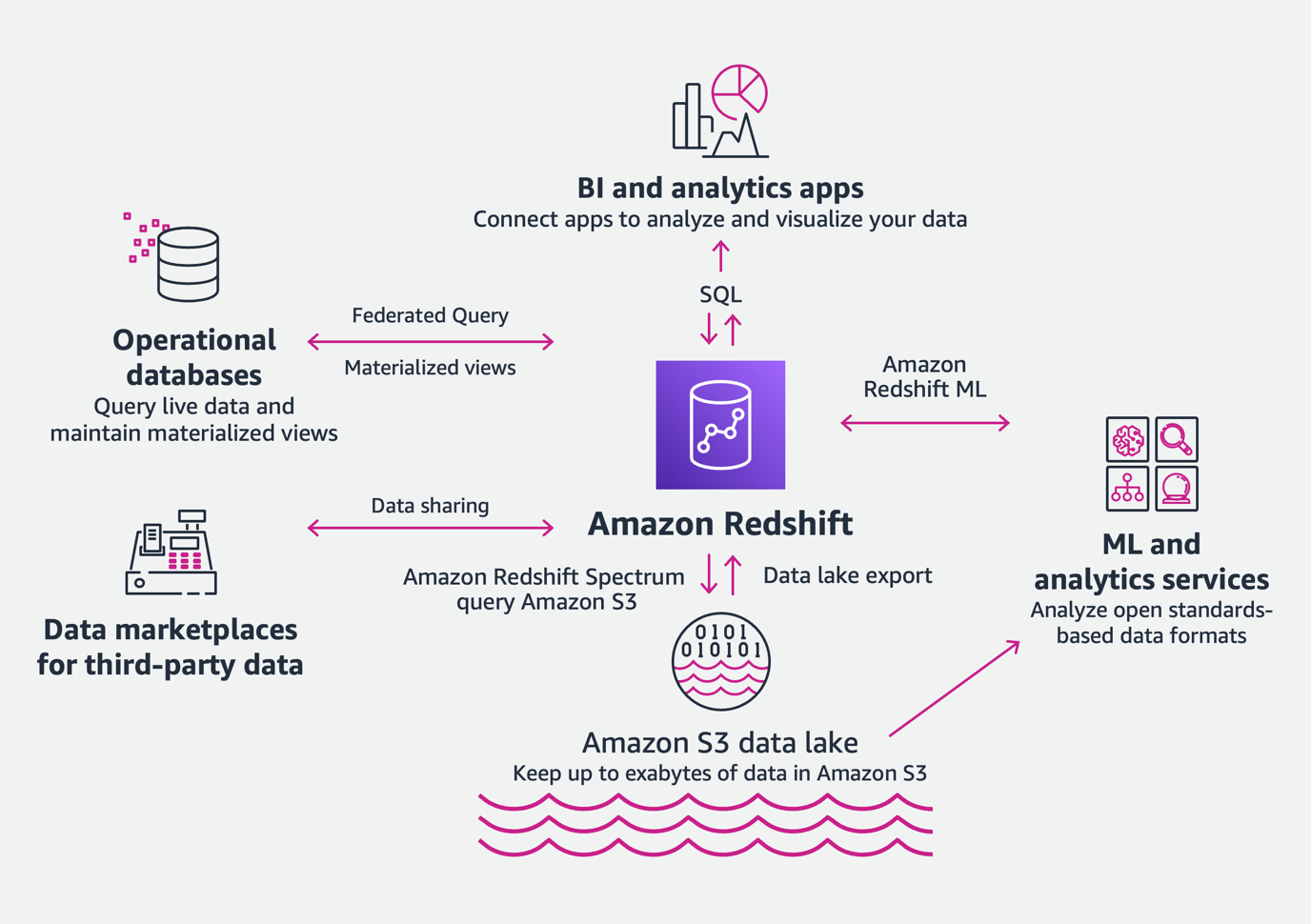
Amazon Redshift 提供以下好处:
- 分析所有数据 – 通过 Amazon Redshift,您可跨数据仓库和数据湖,采用一致的安全和治理策略,轻松分析所有数据。我们将这种架构称为智能湖仓架构。使用 Amazon Redshift Spectrum,您可以在数据湖中查询数据,而无需加载数据或进行其他数据准备工作。通过数据湖导出,您可以将 Amazon Redshift 查询的结果保存回数据湖中。这意味着您可以充分利用实时分析和 ML/AI 使用场景,而无需重新架构,因为 Amazon Redshift 与数据湖完全集成。借助数据共享等新功能,您可以轻松地跨 Amazon Redshift 集群在内部和外部分享数据,因此每个人都可以实时查看一致的数据。借助 Amazon Redshift ML,您可以轻松地对数据执行更多操作 – 您可以直接在 Amazon Redshift 数据仓库中使用熟悉的 SQL 命令,创建、训练和部署 ML 模型。
- 任意规模下的高速性能 – Amazon Redshift 是一种自我调整和自学系统,为您的工作负载提供最佳性能,而无需完成定义排序键和分配键等无差别的繁重任务来优化数据仓库,而且还提供了物化视图、自动刷新和自动查询重写等新功能。Amazon Redshift 可进行扩展,无论是 GB 还是 PB 级数据,无论是几个用户还是成千上万的用户,都可以稳定地快速提供结果。在用户群扩展到数千个并发用户时,并发扩展功能会自动部署必要的计算资源来管理额外的负载。具有托管存储的 Amazon Redshift RA3 实例将计算和存储分开,因此您可以独立扩展资源,只为所需的存储付费。适用于 Amazon Redshift 的 AQUA(高级查询加速器)是一种新的分布式硬件加速缓存,可自动提升特定类型查询的性能。
- 每个人都能轻松进行分析 – Amazon Redshift 是一个完全托管式数据仓库,消除了繁琐的基础设施管理或性能优化负担。您可以专注于获取洞察,而不是执行诸如预置基础设施、创建备份、设置数据布局之类的维护任务及其他任务。您可以操作开放格式的数据,使用熟悉的 SQL 命令,并利用新 Query Editor v2 提供的查询可视化效果。您还可以通过安全数据 API 从任何应用程序访问数据,无需配置软件驱动程序、管理数据库连接。Amazon Redshift 与商业智能(BI, Business Intelligence)工具兼容,为在 BI 工具中进行操作的企业用户带来了 Amazon Redshift 的强大功能和集成能力。
采用数据湖架构的智能湖仓架构与采用 Amazon Redshift 的现代化数据仓库结合起来,可以帮助任意规模的企业解决大数据难题,充分了解大量数据,并推动实现业务成果。您可以通过将数据仓库迁移到 Amazon Redshift,开启您的智能湖仓架构构建之旅。
迁移注意事项
在项目复杂性方面,以及所造成的资源、时间和成本风险方面,数据仓库迁移带来了巨大的挑战。为了降低数据仓库迁移的复杂性,您必须根据现有的数据仓库形势和迁移到 Amazon Redshift 所需的转换量,选择合适的迁移策略。以下是可能影响您的迁移策略决策的关键因素:
- 大小 – 要迁移的源数据仓库的总大小,由迁移中包含的对象、表和数据库决定。充分了解需要迁移到 Amazon Redshift 的数据源和数据域,确定迁移项目的最佳规模。
- 数据传输 – 数据仓库迁移涉及在源数据仓库服务器和 AWS 之间的数据传输。您可以通过源位置与 AWS 之间的网络互连(例如,AWS Direct Connect)传输数据,也可以通过 AWS Snow Family 等工具或服务离线传输数据。
- 数据更改率 – 数据仓库中的数据更新或更改频率是多少? 现有数据仓库的数据更改率确定将源数据仓库与目标 Amazon Redshift 保持同步所需的更新间隔。数据更改率较高的源数据仓库要求在一个更新间隔内,将服务从源数据仓库切换到 Amazon Redshift,这导致了较短的迁移转换窗口。
- 数据转换 – 将现有数据仓库迁移到 Amazon Redshift 是异构迁移,涉及到数据转换,例如数据映射和架构更改。数据转换的复杂性决定了迭代迁移所需的处理时间。
- 迁移和 ETL 工具 – 迁移以及提取、转换和加载(ETL, Extract, Transform, and Load)工具的选择可能会影响迁移项目。例如,部署和设置这些工具所需的工作可能会有所不同。我们将在下文中详细讨论 AWS 工具和服务。
在考虑了所有这些因素之后,您可以为 Amazon Redshift 迁移项目选取迁移策略选项。
迁移策略
您可以从三种迁移策略中进行选择:一步式迁移、两步式迁移或波浪式迁移。
对于不需要连续操作(例如连续复制以使正在进行的数据更改在源和目标之间保持同步)的数据库,一步式迁移是一个很好的选择。您可以将现有数据库提取为逗号分隔值(CSV)文件或列式格式(如 Parquet),然后使用 AWS Snow Family 服务(如 AWS Snowball )将数据集传输到 Amazon Simple Storage Service(Amazon S3),以加载到 Amazon Redshift 中。然后,您可以测试目标 Amazon Redshift 数据库与源数据库的数据一致性。所有验证通过后,数据库将切换到 AWS。
两步式迁移通常用于需要连续操作(例如连续复制)的任意规模的数据库。在迁移过程中,源数据库会出现持续的数据更改,而持续复制可在源数据库与 Amazon Redshift 之间保持数据更改同步。两步式迁移策略的细分如下:
- 初始数据迁移 – 从源数据库中提取数据,最好是在非高峰使用期间以尽可能减少影响。然后,按照前面介绍的一步式迁移方法,将数据迁移到 Amazon Redshift。
- 更改过的数据迁移 – 在切换之前,源数据库中在初始数据迁移后发生过更改的数据将传播到目标数据库。此步骤将源数据库与目标数据库同步。迁移完所有更改过的数据后,可以验证目标数据库中的数据并执行必要的测试。如果所有测试均通过,就可以切换到 Amazon Redshift 数据仓库。
波浪式迁移适用于大规模数据仓库迁移项目。波浪式迁移原理是采取预先措施,将复杂的迁移项目划分为多个逻辑化的系统性波次。这种策略可以显著降低复杂性和风险。首先,您需要处理覆盖了大量数据源和主题区域且复杂性为中等的工作负载,然后在接下来的每一轮波次中添加更多数据源和主题区域。使用此策略,您可以并行运行源数据仓库和 Amazon Redshift 生产环境一段时间,直至源数据仓库完全停用。有关如何使用波浪式迁移方法,识别和分组要从源数据仓库迁移到 Amazon Redshift 的数据源和分析应用程序的详细信息,请参阅开发应用程序迁移方法以利用 Amazon Redshift 打造现代化的数据仓库。
要指导您的迁移策略决策,请参阅下表,将考虑因素与首选迁移策略对应起来。
| . | 一步式迁移 | 两步式迁移 | 波浪式迁移 |
| 迁移范围中的主题区域数量 | 少量 | 中等到大量 | 中等到大量 |
| 数据传输量 | 少量到大量 | 少量到大量 | 少量到大量 |
| 迁移期间的数据更改率 | 无 | 极少到频繁 | 极少到频繁 |
| 数据转换的复杂性 | 任意 | 任意 | 任意 |
| 从源切换到目标的迁移更改窗口 | 数小时 | 几秒 | 几秒 |
| 迁移项目持续时间 | 数周 | 数周到数月 | 数月 |
迁移过程
在此部分中,我们将查看迁移过程的三个高级步骤。两步式迁移策略和波浪式迁移策略涉及所有三个迁移步骤。但是,波浪式迁移策略包括多次迭代。因为一步式迁移仅适用于无需连续操作的数据库,所以该迁移过程中只涉及到步骤 1 和步骤 2。
步骤 1:转换架构和主题区域
在此步骤中,您可以使用架构转换工具(如 AWS Schema Conversion Tool(AWS SCT),以及 AWS 合作伙伴提供的其他工具)转换源数据仓库架构,从而使源数据仓库架构与 Amazon Redshift 架构兼容。在某些情况下,您可能还需要使用自定义代码来执行复杂的架构转换。我们将在后面的部分中深入探讨 AWS SCT 和迁移最佳实践。

步骤 2:初始数据提取和加载
在此步骤中,您将完成初始数据提取,并将源数据首次加载到 Amazon Redshift 中。如果您的数据大小和数据传输要求允许通过互联的网络传输数据,则您可以使用 AWS SCT 数据提取器从源数据仓库中提取数据,并将数据加载到 Amazon S3 中。或者,如果存在网络容量等限制,您可以将数据装入 Snowball,然后将数据加载到 Amazon S3。当源数据仓库中的数据在 Amazon S3 上可用时,它就会加载到 Amazon Redshift 中。如果源数据仓库原生工具能够比 AWS SCT 数据提取器更好地完成数据卸载和加载作业,可以选择使用原生工具来完成此步骤。
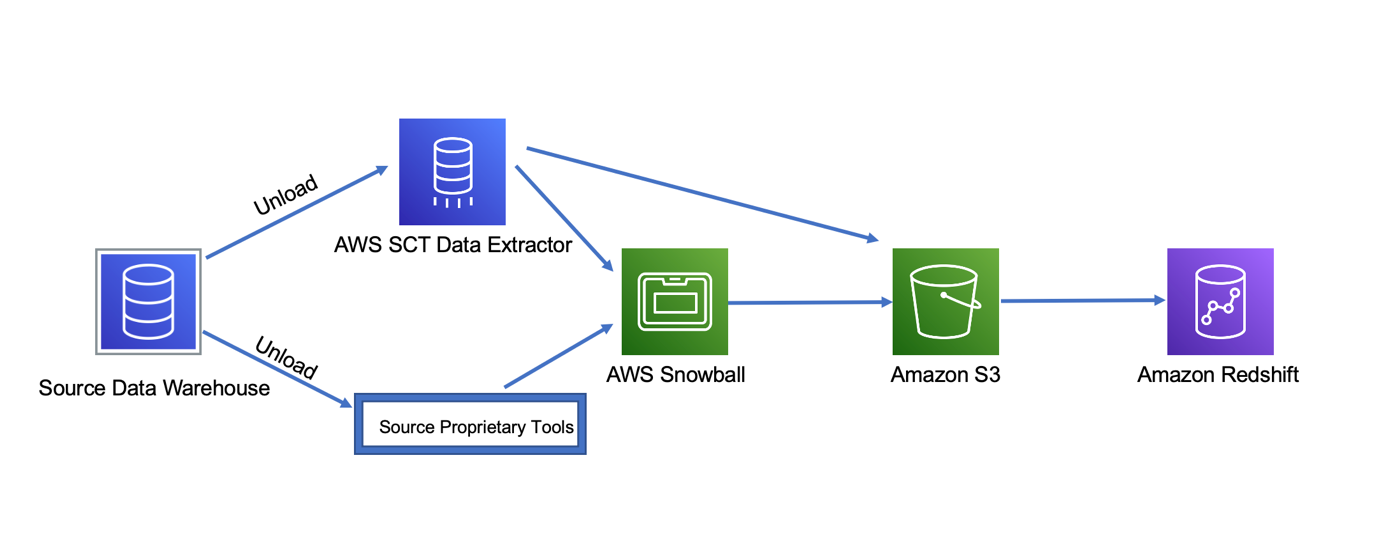
步骤 3:差异或增量加载
在此步骤中,您将使用 AWS SCT,有时也可使用源数据仓库原生工具来捕获差异数据或增量数据,并将其从源加载到 Amazon Redshift。这通常被称为更改数据捕获(CDC, Change Data Capture)。CDC 过程捕获在数据库中所做的更改,并确保将这些更改复制到目标位置,例如数据仓库。
现在,您应该掌握了足够的信息,可以开始为数据仓库制定迁移计划。在接下来的部分中,我将深入探讨帮助您将数据仓库迁移到 Amazon Redshift 的 AWS 服务,以及使用这些服务加速成功交付数据仓库迁移项目的最佳实践。
数据仓库迁移服务
数据仓库迁移涉及到使用一系列的服务和工具来支持迁移过程。首先,您将创建数据库迁移评估报告,然后使用 AWS SCT 将源数据架构转换为与 Amazon Redshift 兼容的架构。要迁移数据,您可以使用与 AWS Data Migration Service(AWS DMS)集成的 AWS SCT 数据提取工具,创建和管理 AWS DMS 任务以及编排数据迁移。
要通过源与 AWS 之间的互联网络传输源数据,您可以使用 AWS Storage Gateway、Amazon Kinesis Data Firehose、Direct Connect、AWS Transfer Family 服务、Amazon S3 Transfer Acceleration 以及 AWS DataSync。对于涉及大量数据的数据仓库迁移,或者如果互联网络容量有限,您可以使用 AWS Snow Family 服务传输数据。通过这种方法,您可以将数据复制到设备,然后将设备送回 AWS,通过 Amazon S3 将数据复制到 Amazon Redshift 中。
对于帮助您加快数据仓库向 Amazon Redshift 的迁移,AWS SCT 是一项必不可少的服务。我们来更深入地研究一下。
使用 AWS SCT 进行迁移
AWS SCT 可自动执行将数据仓库架构转换为 Amazon Redshift 数据库架构的大部分流程。由于源数据库引擎和目标数据库引擎可能会有许多不同的特性和功能,因此 AWS SCT 会尝试尽可能在目标数据库中创建等效的架构。如果无法直接转换,AWS SCT 会创建数据库迁移评估报告来帮助您转换架构。数据库迁移评估报告提供了有关从源数据库到目标数据库的架构转换的重要信息。该报告汇总所有模式转换任务,并针对无法转换为目标数据库的数据库引擎的架构对象,详细说明了操作项。该报告还针对为无法转换的架构在目标数据库中编写等效代码的工作,估算了所需的工作量。
存储优化是数据仓库转换的重中之重。使用您的 Amazon Redshift 数据库作为源,将测试 Amazon Redshift 数据库作为目标,AWS SCT 可以推荐用于优化数据库的排序键和分配键。
借助 AWS SCT,您可以将以下数据仓库架构转换为 Amazon Redshift:
- Amazon Redshift
- Azure Synapse Analytics(版本 10)
- Greenplum Database(版本 4.3 及更高版本)
- Microsoft SQL Server(2008 版及更高版本)
- Netezza(版本 7.0.3 及更高版本)
- Oracle(版本 10.2 及更高版本)
- Snowflake (版本 3)
- Teradata(版本 13 及更高版本)
- Vertica(版本 7.2 及更高版本)
在 AWS,我们将不断发布新功能和增强功能来改进产品。有关最新支持的转换,请访问 AWS SCT 用户指南。
使用 AWS SCT 数据提取工具迁移数据
您可以使用 AWS SCT 数据提取工具,从本地部署数据仓库中提取数据并将其迁移到 Amazon Redshift。代理会提取您的数据并将数据上传到 Amazon S3,对于大规模迁移,可以将数据上传到 AWS Snowball Family 服务。然后,您可以使用 AWS SCT 将数据复制到 Amazon Redshift。Amazon S3 是一种存储和检索服务。要在 Amazon S3 中存储对象,您需要将所存储的文件上传到 S3 存储桶。上传文件时,您可以在对象上设置权限,也可以对任何元数据设置权限。
在涉及将数据上传到 AWS Snowball Family 服务的大规模迁移中,您可以使用 AWS SCT 中基于向导的工作流,这样数据提取工具可以自动编排 AWS DMS 以执行实际迁移的流程。
Amazon Redshift 迁移工具的注意事项
要改进向 Amazon Redshift 的数据仓库迁移,加快迁移速度,请考虑以下提示和最佳实践。这份清单并未列出所有事宜。请确保您充分了解了数据仓库配置文件,确定哪些最佳实践可用于迁移项目。
- 使用 AWS SCT 创建迁移评估报告并确定迁移工作的范围。
- 尽可能使用 AWS SCT 自动执行迁移。我们客户的经验表明,AWS SCT 可以自动创建大多数 DDL 和 SQL 脚本。
- 如果无法自动进行架构转换,请使用自定义脚本完成代码转换。
- 在尽可能靠近数据源的位置安装 AWS SCT 数据提取器代理,以提高数据迁移性能和可靠性。
- 要提高数据迁移性能,请确定合适的 Amazon Elastic Compute Cloud(Amazon EC2)大小,及其安装数据提取器代理的等效虚拟机大小。
- 配置多个数据提取器代理以并行运行多个任务,通过最大限度地利用分配的网络带宽来改进数据迁移性能。
- 调整 AWS SCT 内存配置以改进架构转换性能。
- 使用 Amazon S3 存储现有数据仓库中的大型对象,如图像、PDF 和其他二进制数据。
- 要迁移大型表,请使用虚拟分区并创建子任务以改进数据迁移性能。
- 了解 AWS 服务的使用场景,例如 Direct Connect、AWS Transfer Family 和 AWS Snow 系列。选择合适的服务或工具来满足您的数据迁移要求。
- 了解 AWS Service Quotas 并制定明智的迁移设计决策。
小结
数据量和复杂性的增长速度远超从前。但是,这笔宝贵资产中只有一小部分可供分析。传统本地部署数据仓库的架构僵化,无法针对现代化大数据分析使用场景进行扩展。这些传统的数据仓库的设置和运行成本很高,并且需要大量的软件和硬件前期投资。
在这篇文章中,我们将讨论 Amazon Redshift,这是一款完全托管式、可扩展、现代化的数据仓库,可以帮助您分析所有数据,并可在任意规模下以低廉且可预测的成本实现高性能。要将数据仓库迁移到 Amazon Redshift,您需要考虑一系列因素,例如数据仓库的总大小、数据更改率和数据转换复杂性,这样才能选取合适的迁移策略和流程,降低数据仓库迁移项目的复杂性和成本。借助 AWS SCT 和 AWS DMS 等 AWS 服务,通过采用这些服务提示和最佳实践,您可以自动完成迁移任务、扩大迁移规模、加快数据仓库迁移项目的交付,让客户满意。