亚马逊AWS官方博客
Zenjoy 基于 Amazon Bedrock 和 EKS 构建 AIOps Agent:打通 Prometheus、ES 与夜莺的智能化告警实战
摘要:随着微服务架构的规模化演进,传统基于静态阈值的监控告警体系面临误报率高、漏报频发、人工排查效率低等瓶颈。本文介绍了一种将确定性数学算法与大语言模型深度解耦的 AIOps Agent 方案——由 Z-Score、IQR、线性回归等统计算法完成全量监控数据的确定性分析与过滤,再由 Amazon Bedrock 上的LLM模型对精简后的结论进行智能总结与报告生成,最终通过夜莺平台实现告警的统一管理与多渠道通知。该方案运行在 Amazon EKS 之上,使用 AWS 开源的 Strands Agents 框架构建 Agent,实现了告警信噪比的大幅提升和运维效率的显著改善。
一、背景:常规的监控与处理流程
目前,我们在 Amazon EKS 集群里跑着几十个核心微服务。在引入 AIOps 之前,我们和大多数技术团队一样,采用了一套非常经典的云原生监控标准流:
当前的常规告警处理链路:
- 数据抓取:各个集群的 Prometheus 定期去拉取业务与系统组件的 Metrics。
- 规则触发:在 Prometheus 或相关节点上配置静态告警规则(例如:
CPU 使用率 > 80% 持续 5 分钟、5xx 状态码 > 10等)。 - 分发路由:告警触发后推送到对应的钉钉群。
- 人工介入与排查:
- 开发者收到告警通知:
[Critical] pod-xxx CPU使用率 85%。 - 登录 Grafana 查看最近两小时波形,再去对比昨天同一时间的数据。
- 接着去 Elasticsearch 里翻看同时段有没有 Error 日志,或者检查资源。
- 经过排查,定位出问题或者确认是误报。
二、痛点
这套基于静态规则和纯人力排查故障的链路,在早年应对单体或简单架构时非常管用。但随着微服务数量激增和业务复杂度增加,我们开始发现它越来越”力不从心”——每天产生大量告警,真正需要关注的可能只有很少的几条。
具体来说,这套常规流程在以下三个场景中彻底暴露出瓶颈:
- 静态阈值应付不了天然的周期性规则
我们的业务有着较为明显的周期性差异。如果我们给 CPU 设定 80% 的静态报警红线,正常业务高峰期,稍微有一点流量激增就会狂响;于是为了免受打扰,我们把阈值调高到 90%,结果到了低谷期,即便服务真的出现了异常死循环卡在 85%,系统却沉默漏报了。
- 告警信息太机械,难以提前识别趋势,人肉排查故障严重拉长 MTTR
目前的告警通知只单纯依靠阈值触发,有时资源出现尖峰,实际系统依然健康运行,但是依旧会触发告警。从人眼看到告警,到判断是否需要立刻干预,需要工程师手动去 Grafana 看图表、查趋势、翻监控。并且大概是误报,并未出现问题。这种频繁误报,会对工程师造成告警疲劳,容易耗费注意力和精力在不必要的误报上。并且有时持续的资源上涨又达不到阈值,无法告警,只能等事故出现再进行解决排查,难以提前发现问题。
为了改善这种误报和漏报并存的情况,我们决定不再单纯依靠机械的告警规则,而是迭代出 AIOps Agent 这套监控分析算法。利用数学算法对监控数据进行分析,尽可能过滤出有效的告警,并传递给 LLM 生成报告,同时上报夜莺产生告警。
三、整体流程图与 AIOps 核心工作流
3.1 整体打通 AIOps Agent、Prometheus、ES 与夜莺架构流程图
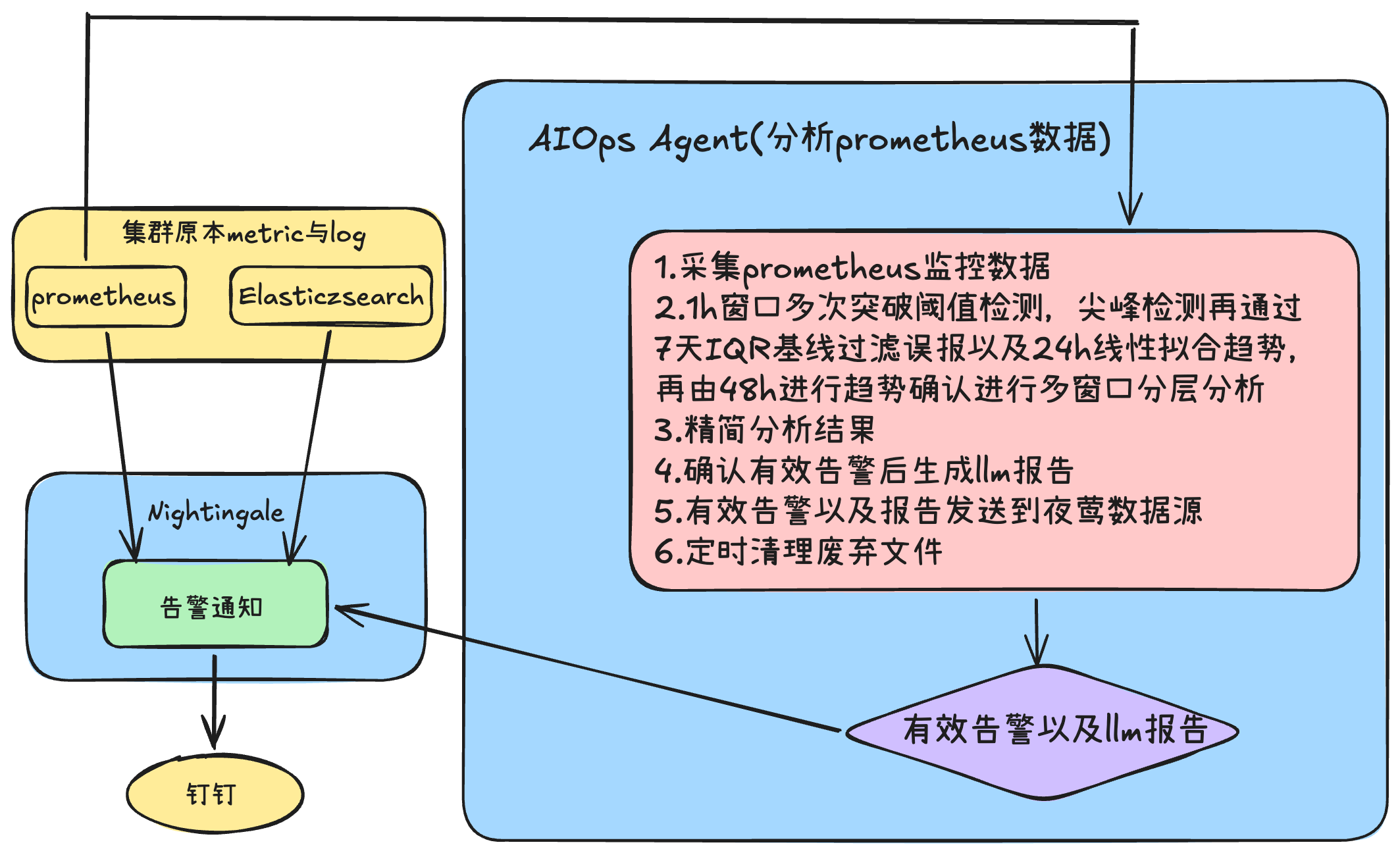
[图1] |
在 AIOps 的架构设计上,我们坚持”程序计算,AI 总结”的原则,将时序数据的确定性计算与大语言模型的分析能力解耦。整体工作流包含以下核心阶段:
1. 数据采集:由 Python 脚本定时向 Prometheus 请求过去 1h、24h、48h、7d 等不同跨度的监控数据。采集到的原始数据以 JSON 格式存入本地,不对 LLM 直接暴露繁杂的原始指标,后续使用确定的程序算法来进行计算。
2. 多窗口分层分析机制:对于上述多个时间窗口采集到的数据,由各类纯粹的代码检测器加载历史 JSON 数据。运用 NumPy 等库完成去噪、平滑,并提取多维特征(如 Z-Score / IQR / 线性回归),进行稳定的数学分析,判断是否有短窗口资源告警或者资源存在趋势持续上涨,可能需要告警。所有的数学计算与趋势判定均由确定性的程序完成,无需依赖大语言模型。
(注:此阶段还会实施全局数据完整性校验 (Data Completeness)。一旦发现任何时间窗口的点数低于安全界限——比如 1h < 60 点,24h < 200 点等,立刻上报高危数据缺失告警。)
3. 结果保存 (Summary & Decision Caching):分析器运行结束后,提炼出精简的判断依据(如 trend_increase=24.5%, spike_ratio=2.1),并生成摘要 JSON 文件。
4. LLM 生成报告:出现有效告警时,将第 3 阶段高度浓缩的结论摘要文件输入给 LLM。此时的 LLM 不需要做任何推算,只需根据程序明确给出的异常列表和数值体征生成排查和建议报告。即先程序分析全量数据,确定异常情况再将精简数据让 LLM 分析。
5. 告警上报:夜莺后台支持 API 上报时序数据,aiops 程序将计算出的告警信息作为时序通过 /opentsdb/put 接口上报到夜莺。并且在夜莺后台根据上报的告警数据配置好告警规则以及通知规则,aiops 计算出的告警就可以通过夜莺方便在多个渠道进行告警通知了。
6. 历史文件垃圾回收:根据保留规则触发执行存储管理,定期清理废弃中间态文件与历史周期(如超 7 天)文件。
四、AIOps 的多窗口分层分析机制
在核心的”程序计算”层面,系统严格区分了不同时长的时间窗口。不同窗口拥有不同的执行频率、采样步长,以及其核心算法检测侧重点:
1 小时窗口 (1h Window):实时尖峰告警
- 定位:实时检测报警。
- 调度间隔:约每 5 分钟执行一次(最高频)。
- 核心算法与逻辑:
- 静态阈值兜底 (Threshold Violation):一旦绝对峰值超过高压红线(如 CPU > 80%),即刻报警。
- 高频突破率检测 (High Breach Rate):1h 内虽未触及极端最高红线阈值,但多次接近告警阈值,也会产生报警。
- 尖峰检测 (Spike Detection):系统提取最后 30s 的最新瞬时数据,与前 5m 的中位数进行对比。公式为
尖峰 / 基线 >= 倍率(默认1.5倍)。这一步专门用于抓取最后瞬时的尖峰,防止突发流量在 1h 算数平均值中被稀释漏报。 - 内存阈值自适应:在判定 1h 内存水位时,优先级最高的是 Prometheus 抓取的
Limit 水位 * 80%;次优选取 7 天基线的 P99(即P99 * 1.2);若二者皆无/失效,才降级判定静态1024MB阈值。 - Z-Score 正态离群值判断:基于均值和标准差,检测当前点是否发生了 3 倍标准差以上的陡降或陡升。(弥补短期内整体水位高居不下时,IQR 找不到波动的盲区)。
- 宕机/假死检测 (Data Completeness):如果 1h 内采集到的监控点数少于预期,直接触发报警。
24 小时窗口 (24h Window):缓慢趋势发现
- 定位:趋势发现。
- 调度间隔:约每 30 分钟执行一次。
- 核心算法与逻辑:
- IQR 噪声过滤预处理:先通过 IQR 剔除极端离群值,还原出相对平滑的数据基本盘。
- 最小二乘法线性回归拟合 (Linear Regression):通过过滤后的干净数据,回归斜率 (Slope)。重点看函数置信度 R² 与首尾增幅比率。只有 R² > 0.6(说明极其平滑)且首尾总体有 20% 以上明确增幅的上升直线,才会被程序判定为资源确实存在上涨趋势。
48 小时窗口 (48h Window):历史趋势确认
- 定位:24h 趋势确认。
- 调度间隔:同 24h 窗口一并,约每 30 分钟。
- 核心算法与逻辑:
- 加长版线性回归 (Extended Trend Confirmation):核心操作与 24h 一致。
- 作用目的:防范单日流量抖动造成的”伪趋势”误报。把观测线拉长到 48 小时看长期斜率,如果连续两天依然稳定上升,正式下发严重警告。
7 天窗口 (7d Window / IQR Baseline):全局抗噪过滤层
- 定位:过滤/降级短期误报。
- 调度间隔:约每 2 小时执行一次获取 7d 数据并落盘。
- 核心算法与逻辑:
- 历史同期 IQR 检测:将当下的告警时段,”平移回溯”到过去 7 天每天的同一时段划出正常水位。(注:我们曾跑过 ACF(自相关函数)+ FFT(快速傅里叶变换) 算法,但实测易受干扰,最终使用 IQR 进行分析)。
- 基线失效控制对齐:必须过 4 关:1h 的历史点数需 > 10;计算出的
IQR/中位数若 > 0.5(说明历史天天乱闪)则废弃基线;若 7 天中位数直接越过红线,废弃基线;总采集点数 < 150,废弃基线。 - 作用目的:当 1h 或 48h 计算出高危抛出异常时,必须经由 7d 窗口会诊。如果该指标当下虽然高,但它刚好落在过去 7 天每天同期同一时段的 IQR 正常波动范围之内,则该告警将被静默抑制(Suppression)或降级处理。
五、实现过程中出现过的问题
问题 1:周期检测走了太多弯路
为了识别出业务的周期特性,一开始引入了较为复杂的 ACF(自相关函数)+ FFT(快速傅里叶变换),但是实际落地进行测试时经常识别不准。换了 STL(Seasonal-Trend decomposition using LOESS),效果也比较差,很难识别出业务的真正周期,并且算法比较复杂,理解成本和开发成本较高。
解决方法:
7 天同时段 IQR。放弃复杂的周期检测算法,直接拿 7 天内同一小时的历史数据做四分位距计算,真实落地时相较于上述复杂周期检测算法,误报率大大降低,且维护成本极低,降低周期趋势校验的复杂度。
问题 2:只信 Z-Score 导致误差大
早期单靠 Z-Score 做均值偏离检测,Z-Score 对异常值非常敏感,只要出现一两个偶发尖峰,标准差会被拉高,导致正常数据被视为异常值。
解决方法:
引入 IQR 中位数测算作为互补。IQR 对极端值不敏感,并且仍能发现异常值,两者结合后误报率下降,使异常值检测更加精准。
问题 3:Token 爆炸与 LLM 幻觉
最开始将大量原始数据交给 LLM 分析,单次消耗 Token 很多,并且有时会超出上下文。数据量过大,LLM 会产生幻觉,得出与事实不符的结论。
解决方法:
使用程序算法进行稳定的计算,将大量的原始数据精简成结构化的数据;并在 System Prompt 明确要求:”必须给出具体 Pod 名、具体指标值与判断依据,不允许使用模糊表述!” 治理后 Token 锐减,并且根据程序计算得到的精简数据,LLM 得到的分析和总结也变得更加准确和有条理。
问题 4:24h 趋势较短,容易将正常增长进行误报
我们发现如果只看 24h 窗口,业务晚高峰的自然上涨全被标记为”异常趋势上涨”。
解决方法:
引入 48h 同比昨日验证,当 24h 和 48h 的趋势一致时,才会被判定为异常趋势。
六、架构优化点
1. 从”死阈值”转向”动态基线”,极大降低误报率
优化点:架构图中引入了 7 天 IQR(四分位距)基线过滤。
优点:传统的 Prometheus 告警只看那一瞬间是否超过 80%,而 AIOps Agent 会回溯 7 天的历史数据。如果某个峰值符合业务的”周期性规律”(比如每天中午流量都会激增),Agent 会将其识别为正常波动并过滤掉。
价值:告警信噪比大幅提升,运维人员不再被”虚假告警”疲劳轰炸。
2. 从”事后补救”转向”趋势预判”
优化点:引入了 24h 线性拟合与 48h 趋势确认机制。
优点:即使当前指标没达到阈值,但如果 Agent 发现指标在过去 24-48 小时内呈现持续上升趋势(例如内存缓慢泄漏),它会提前识别出潜在风险。
价值:在故障发生前提前识别风险,不必等到故障发生再进行紧急修复,而是能够提前预警,拥有了充足的排查缓冲时间。
3. 从简单机械告警转向智能分析
优化点:增加了 LLM 生成报告这一环节。
优点:以前钉钉收到的可能只是 CPU > 90% 这种字符串。现在,Agent 在确认”有效告警”后,会调取上下文(指标 + 日志)让大模型分析,并输出一份包含故障原因推测和处理建议的 Markdown 报告。
价值:降低了排查故障的门槛。能够根据 LLM 报告获取更多的信息,快速定位问题,同时 LLM 会给出排查和处理建议,缩短了处理故障的时间。
4. 将告警统一集中到夜莺
优化点:通过 /opentsdb/put 接口将结果回流至夜莺,以及将日志系统和 Prometheus 的告警也统一集中到夜莺。
优点:夜莺是一个具有优秀告警与通知体系的开源项目,数据源和告警通知渠道十分丰富,同时配置也较为简单。
价值:用很低的成本实现了数据源聚合,通过夜莺进行 AIOps Agent、Prometheus、ES 告警集中到夜莺这一个平台。实现了告警的统一配置、管理和通知。
七、AWS 服务在方案中的角色
上述 AIOps Agent 的算法设计和告警流程是整个方案的核心。在工程落地层面,我们选择基于 AWS 服务来构建底层基础设施和 AI 能力,使团队能够专注于算法逻辑本身,而非基础设施运维。以下是各 AWS 服务在方案中承担的具体角色。
AWS 服务全景架构图
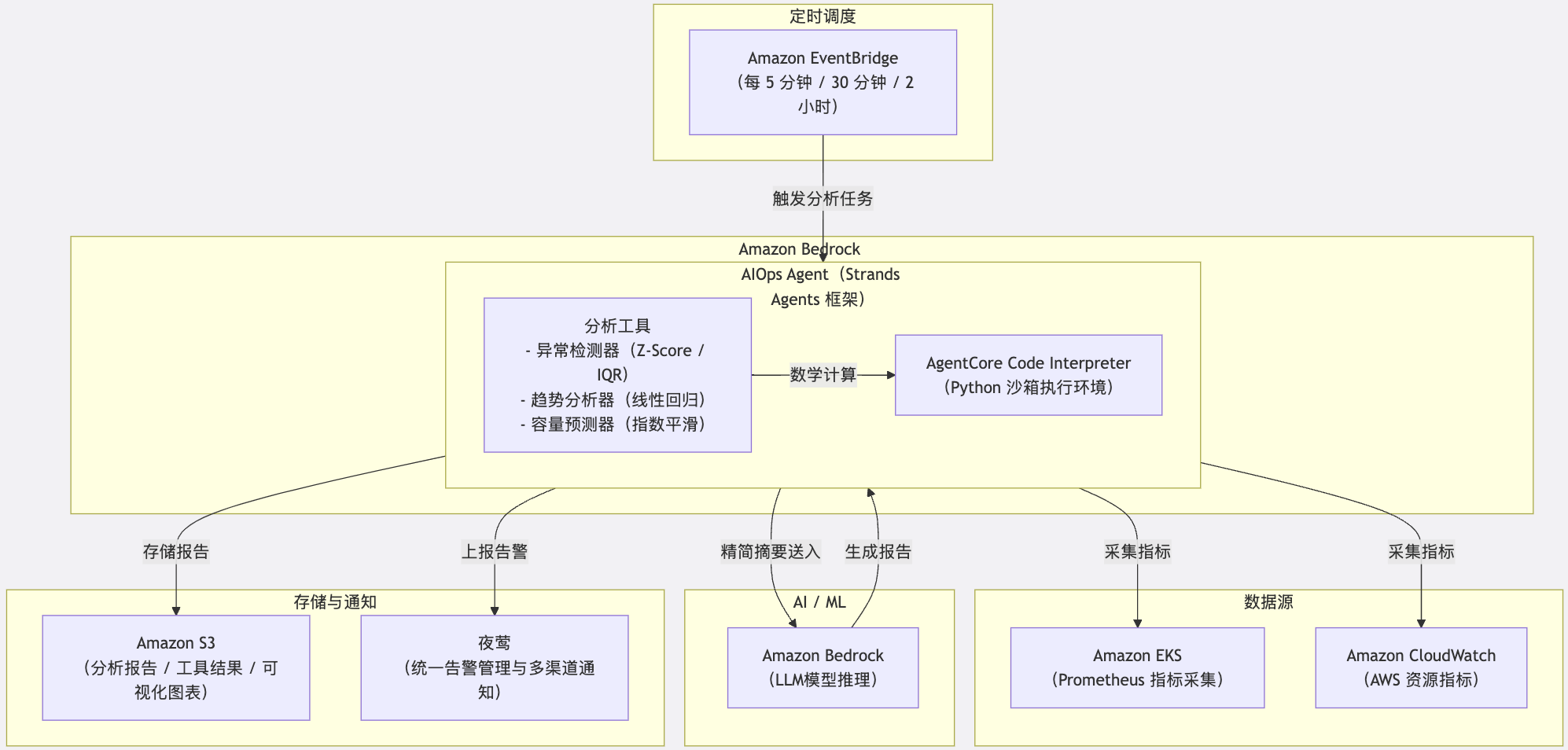
[图2] |
7.1 Amazon EKS:微服务运行平台
我们的几十个核心微服务运行在 Amazon EKS 上。EKS 提供了托管的 Kubernetes 控制平面,免去了集群管理的运维负担。Prometheus 部署在 EKS 集群内,直接采集 Pod 级别的 CPU、内存、网络、重启次数等指标,这些数据构成了 AIOps Agent 多窗口分析的输入源。
7.2 Amazon Bedrock 与 Strands Agents:LLM 推理与 Agent 编排
在第三章工作流的第 4 阶段”LLM 生成报告”中,我们使用 Amazon Bedrock 调用 LLM大模型来完成智能总结。Bedrock 提供了全托管的基础模型推理服务,按 Token 计费,无需自建 GPU 推理基础设施。这与我们”仅在有效告警时才调用 LLM”的设计高度契合——大部分时间算法判定为正常状态时,不会产生任何 LLM 调用费用。
Agent 的编排使用了 AWS 开源的 Strands Agents 框架。Strands Agents 采用 Tool-use 模式,每个分析模块(如异常检测、趋势分析)被封装为一个可调用的工具(Tool),Agent 根据任务需要自主决定调用哪些工具以及调用顺序。这种模式天然适配我们”程序计算 + AI 总结”的架构——数学算法作为 Tool 执行确定性计算,LLM 仅在最后环节介入做总结。
在 Prompt 工程方面,我们在 System Prompt 中加入了严格的反幻觉约束,要求 LLM 必须基于程序计算的实际数据生成报告,不允许编造指标值或模糊表述。这与第五章问题 3 中提到的”Token 爆炸与 LLM 幻觉”解决方案一脉相承。
7.3 Amazon Bedrock AgentCore Runtime:生产级 Agent 托管
算法和 Agent 编排逻辑开发完成后,如何将其部署为一个可靠的生产服务?我们使用了 Amazon Bedrock AgentCore Runtime 来解决这个问题。
AgentCore Runtime 是一个 Serverless 的 Agent 托管环境,为 AIOps Agent 提供了以下关键能力:
- 零基础设施管理:无需自行管理服务器、容器编排或扩缩容策略。Agent 代码打包部署后,即可通过 API 或 CLI 调用,运行时的资源分配和会话管理由平台自动处理。
- 会话隔离:每次 Agent 调用运行在独立的 MicroVM 中,多个分析任务并发执行时互不干扰,适合多集群、多团队共用同一个 AIOps Agent 的场景。
- 内置 Code Interpreter 沙箱:AgentCore 提供了安全的 Python 执行环境,我们的数学分析代码(NumPy、SciPy 等)在沙箱中运行,与 LLM 推理完全隔离。分析工具产生的中间结果文件也存储在沙箱的文件系统中,天然支持了第三章工作流中”结果保存”阶段的需求。
- 灵活的调度集成:AgentCore Runtime 可以与 Amazon EventBridge 配合,按 cron 表达式定时触发分析任务。例如每 5 分钟执行一次实时异常检测,每 30 分钟执行一次趋势分析——对应第四章中各时间窗口的调度间隔。
部署和调用流程非常简洁:
AgentCore Runtime 按执行时长计费,Agent 空闲时不产生费用,与我们”定时触发、按需分析”的使用模式非常匹配。
7.4 结果持久化与 Token 优化
在第三章工作流的第 3 阶段”结果保存”中,分析工具将完整的计算结果存入文件,仅向 Agent 返回精简的摘要信息。这种设计在 Strands Agents 框架中的实现方式是:每个 @tool 函数执行完毕后,将完整结果写入 JSON 文件,仅返回文件路径和关键指标汇总(不到 1KB),而非将全量数据(通常 50KB+)直接传入 LLM 上下文。
这种架构带来了两个直接收益:
- Token 消耗降低 90% 以上,直接降低了 Bedrock API 的调用成本
- 消除了上下文溢出风险,使 Agent 可以分析大规模集群的监控数据而不受 Token 限制
分析报告最终可存储在 Amazon S3 中进行归档,配合 S3 的生命周期策略实现自动的冷热分层存储。
7.5 与夜莺的协同
需要强调的是,AWS 服务与夜莺在本方案中是协同关系而非替代关系。AWS 负责提供底层的计算平台(EKS)、AI 推理能力(Bedrock)和 Agent 编排框架(Strands Agents),而夜莺作为统一的告警管理平台,负责告警规则配置、多渠道通知分发和告警生命周期管理。AIOps Agent 的计算结果通过 /opentsdb/put 接口上报到夜莺,与 Prometheus 原生告警和 ES 日志告警汇聚在同一个平台上,实现了真正的告警统一视图。
八、总结
AIOps Agent 的智能化告警实战证明,通过深刻理解业务自身的周期性规律,并将”算法确定性分析”与”大模型总结”深度解耦,技术团队能够显著突破传统静态规则监控的性能与体验边界。
在技术选型上,Amazon EKS 为微服务提供了稳定的运行平台,Amazon Bedrock 上的大模型为 Agent 提供了按需调用的智能总结能力,Strands Agents 框架则以轻量级的 Tool-use 模式将算法模块与 LLM 推理自然地编排在一起。而夜莺作为告警管理的统一入口,将 AIOps Agent、Prometheus、ES 的告警汇聚到一个平台,实现了告警的统一配置、管理和通知。
对于面临类似微服务雪崩与告警风暴挑战的技术团队,建议同样采取这种极其务实的渐进式演进策略:
- 建立基础监控池:依托 Amazon EKS、Prometheus、ES 和夜莺等成熟组件建立完善的数据采集与告警通知体系
- 引入算法分析漏斗:逐步引入多窗口分析机制与数理统计算法(如 IQR / Z-Score / 线性回归)进行特征拦截去噪
- 按需引入大模型:在核心环节通过 Amazon Bedrock 按需引入大模型进行报告生成,构建出完整的 AIOps 闭环
这种”算法执行计算过滤,大模型负责推演翻译”的方法,不仅能以极低的二次改造成本和 Token 开销带来告警信噪比的明显提升,还能有效释放运维与研发人员的排障精力,更早地发现潜伏的系统隐患,从而为企业的云原生架构建立起更可靠的稳定性保障。
九、相关资源
相关产品:
- Amazon EKS — 托管 Kubernetes 服务
- Amazon Bedrock — 托管基础模型服务
- Strands Agents — AWS 开源 Agent 框架
- Amazon S3 — 对象存储服务
- 夜莺监控(Nightingale) — 开源告警管理平台
相关文章:
- 用AI Agent重新定义数据分析:从数小时到数分钟的效率革命
- 简化故障注入,读懂应用影响:用 AI Agent 做混沌工程
- Agentic AI基础设施实践经验系列(四):MCP服务器从本地到云端的部署演进
- 利用 CloudWatch AIOps 实现智能化根因分析与故障排查
- 基于 AWS DevOps Agent 构建 AI 驱动的运维分析系统
*前述特定亚马逊云科技生成式人工智能相关的服务目前在亚马逊云科技海外区域可用。亚马逊云科技中国区域相关云服务由西云数据和光环新网运营,具体信息以中国区域官网为准。
本篇作者
AWS 架构师中心:云端创新的引领者探索 AWS 架构师中心,获取经实战验证的最佳实践与架构指南,助您高效构建安全、可靠的云上应用
|
 |
