为什么嵌入至关重要?
嵌入使深度学习模型能够更有效地理解真实世界的数据域。它们简化了真实世界数据的表示方式,同时保留了语义和语法关系。这使得机器学习算法可以提取和处理复杂的数据类型,并支持创新的人工智能应用。以下部分介绍了一些重要因素。
降低数据维度
数据科学家使用嵌入在低维空间中表示高维数据。在数据科学中,维度一词通常是指数据的特征或属性。人工智能中的高维数据是指具有定义每个数据点许多特征或属性的数据集。这可能涉及数十、数百甚至数千个维度。例如,可以将图像视为高维数据,因为每个像素颜色值都是一个单独的维度。
当提供高维数据时,深度学习模型需要更多计算能力和时间,才能进行准确地学习、分析和推断。嵌入通过识别各种特征间的共同点和模式来减少维度的数量。因此,这可以减少处理原始数据所需的计算资源和时间。
训练大型语言模型
在训练大型语言模型 (LLM) 时,嵌入可以提高数据质量。例如,数据科学家使用嵌入来清理训练数据中影响模型学习的不规则性。机器学习工程师还可以通过为迁移学习添加新的嵌入来重新利用预训练的模型,但这需要使用新的数据集来完善基础模型。借助嵌入,工程师可以针对现实世界的自定义数据集精细调整模型。
打造创新性应用程序
嵌入式支持新的深度学习和生成式人工智能(生成式 AI)应用程序。神经网络架构中应用的不同嵌入技术能够在各个领域和应用中开发、训练和部署精确的人工智能模型。例如:
- 借助图像嵌入,工程师可以构建用于对象检测、图像识别和其他视觉相关任务的高精度计算机视觉应用程序。
- 通过单词嵌入,自然语言处理软件可以更准确地理解单词的上下文和关系。
- 图嵌入从互连节点提取相关信息并进行分类,从而支持网络分析。
计算机视觉模型、人工智能聊天机器人和人工智能推荐系统都使用嵌入来完成模仿人类智能的复杂任务。
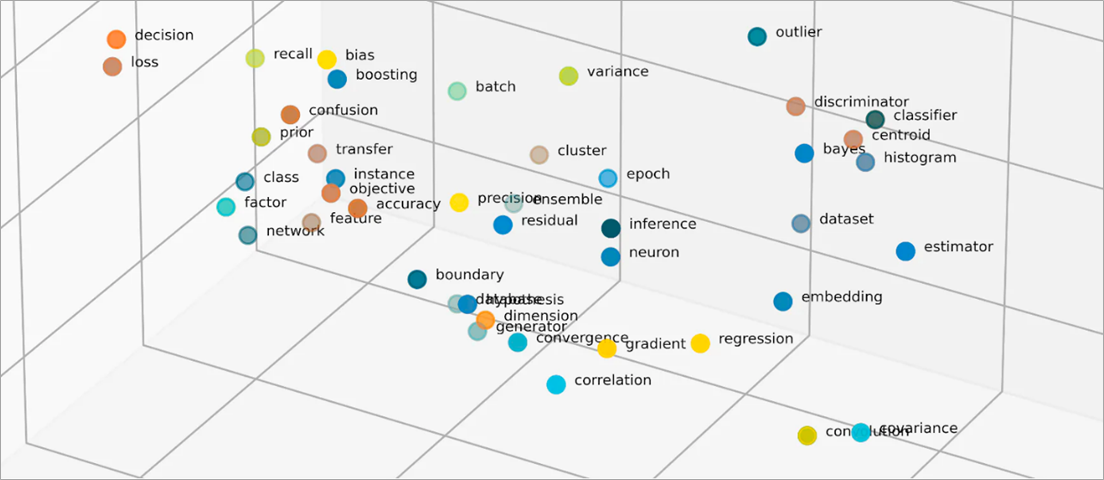
嵌入中的向量是什么?
机器学习模型无法以原始格式明确解读信息,需要以数值数据作为输入。它们使用神经网络嵌入将实词信息转换为称为向量的数字表示形式。向量是以多维空间形式表示信息的数值。它们可以帮助机器学习模型找到稀疏分布的项目间的相似之处。
机器学习模型学习的每个对象都有不同的特征。举一个简单的例子,思考以下电影和电视剧。每种都以体裁、类型和发行年份为特征。
The Conference(恐怖片,2023 年,电影)
Upload(喜剧,2023 年,电视剧,第 3 季)
Tales from the Crypt(恐怖片,1989 年,电视剧,第 7 季)
Dream Scenario(恐怖喜剧,2023 年,电影)
机器学习模型可以解读年份等数值变量,但无法比较体裁、类型、剧集和总季数等非数字变量。嵌入向量将非数字数据编码为机器学习模型可以理解和关联的一系列值。例如,以下是前面列出的电视剧的假设表示。
The Conference(1.2、2023、20.0)
Upload(2.3、2023、35.5)
Tales from the Crypt(1.2、1989、36.7)
Dream Scenario(1.8、2023、20.0)
向量中的第一个数字对应于特定的体裁。机器学习模型会发现 The Conference 和 Tales from the Crypt 是相同的体裁。同样,该模型还会根据代表形式、季数和剧集的第三个数字,发现 Upload 和 Tales from the Crypt 间的更多关系。随着更多变量的引入,您可以优化模型,将更多信息浓缩到更小的向量空间中。
嵌入的工作原理是怎样的?
嵌入将原始数据转换为机器学习模型可以理解的连续值。过去,机器学习模型使用独热编码将类别变量映射为可以学习的形式。此编码方法将每个类别分为行和列,并为其分配二进制值。考虑以下类别的农产品及其价格。
|
水果 |
价格 |
|
苹果 |
5.00 |
|
奥兰治 |
7.00 |
|
胡萝卜 |
10.00 |
下表使用独热编码结果表示值。
|
苹果 |
奥兰治 |
梨 |
价格 |
|
1 |
0 |
0 |
5.00 |
|
0 |
1 |
0 |
7.00 |
|
0 |
0 |
1 |
10.00 |
此表以数学方式表示为向量 [1,0,0,5.00]、[0,1,0,7.00] 和 [0,0,1,10.00]。
独热编码可扩展 0 和 1 维度值,但不提供帮助模型关联不同对象的信息。例如,尽管苹果和橙子都是水果,但该模型无法找到其相似之处,也无法按水果和蔬菜区分橙子和胡萝卜。随着更多类别添加到列表中,编码会生成稀疏分布的变量,其中包含许多空值,会占用大量内存空间。
嵌入通过使用数值表示对象间的相似之处,将对象向量化到低维空间。神经网络嵌入可在扩展输入特征的情况下,维度数量仍然可以管理。输入特征是机器学习算法负责分析的特定对象特征。降维让嵌入可以保留信息,而机器学习模型可以使用这些信息来查找输入数据间的相似之处和不同之处。数据科学家还可以对二维空间中的嵌入可视化,从而更好地理解分布式对象间的关系。
什么是嵌入模型?
嵌入模型是经过训练的算法,可在多维空间中将信息封装为密集式表示。数据科学家使用嵌入模型让机器学习模型能够理解和推理高维数据。这些是机器学习应用中使用的常见嵌入模型。
主成分分析
主成分分析(PCA)是一种降维技术,可将复杂的数据类型简化为低维向量。它会找到具有相似性的数据点,并将它们压缩成反映原始数据的嵌入向量。虽然 PCA 让模型可以更有效地处理原始数据,但在处理过程中可能会出现信息丢失。
奇异值分解
奇异值分解(SVD)是一种嵌入模型,可将矩阵转换为其奇异矩阵。生成的矩阵保留了原始信息,同时模型也能更好地理解它们所代表的数据的语义关系。数据科学家使用 SVD 来执行各种机器学习任务,包括图像压缩、文本分类和推荐。
Word2Vec
Word2Vec 是一种机器学习算法,训练后,可以关联单词并在嵌入空间中表示。数据科学家为 Word2Vec 模型提供大量文本数据集,实现自然语言理解。此模型通过考虑单词的上下文和语义关系来发现单词的相似之处。
Word2Vec 有两种变体:连续词袋(CBOW)和跳字。CBOW 让模型可以根据给定上下文预测单词,而跳字则可以从给定单词推导上下文。尽管 Word2Vec 是一种有效的单词嵌入技术,但它无法准确区分用于暗示不同含义的同一单词的上下文差异。
BERT
BERT 是一种基于转换器的语言模型,使用海量数据集进行训练后可以像人类一样理解语言。和 Word2Vec 一样,BERT 可以根据训练所用的输入数据创建单词嵌入。此外,当应用于不同的短语时,BERT 可以区分单词的上下文含义。例如,BERT 为“play”创建了不同的嵌入,比如“I went to a play”和“I like to play”。
嵌入是如何创建的?
工程师使用神经网络来创建嵌入。神经网络由隐藏的神经元层组成,它们以迭代方式做出复杂的决策。创建嵌入时,其中一个隐藏层将学习如何将输入特征分解为矢量。这发生在特征处理层之前。此过程由工程师监督和指导,步骤如下:
- 工程师向神经网络提供一些手动准备的矢量化样本。
- 神经网络从样本中发现的模式中学习,并利用这些知识从看不见的数据中做出准确的预测。
- 有时,工程师可能需要对模型进行微调,以确保其将输入特征分布到适当的维度空间中。
- 随着时间的推移,嵌入会独立运行,从而允许 ML 模型根据矢量化表示生成推荐。
- 工程师继续监控嵌入的性能并使用新数据进行微调。
AWS 如何帮助您应对嵌入要求?
Amazon Bedrock 是一项完全托管的服务,提供来自领先人工智能公司的高性能基础模型 (FM) 供您选择,以及用于构建生成式人工智能 (generative AI) 应用程序的广泛功能。Amazon Nova 是新一代最先进的 (SOTA) 基础模型 (FM),可提供前沿情报和行业领先的性价比。它们是功能强大的通用模型,旨在支持各种用例。您可以按原样使用,也可以根据自己的数据对其自定义。
Titan Embeddings 将文本转换为数字表示的 LLM。Titan Embeddings 模型支持文本检索、语义相似性和集群。最大输入文本为 8K 个标记,最大输出向量长度为 1536。
机器学习团队还可以使用亚马逊 SageMaker 来创建嵌入内容。Amazon SageMaker 是一个中心,在这里,您可以在安全且可扩展的环境中构建、训练和部署 ML 模型。它提供了一种名为 Object2Vec 的嵌入技术,工程师可以使用该技术在低维空间中对高维数据进行矢量化。您可以使用已学习的嵌入来计算下游任务(例如分类和回归)的对象间的关系。
立即创建一个账户,开始在 AWS 上进行嵌入。
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages