AWS News Blog
Amazon Kinesis Analytics – Process Streaming Data in Real Time with SQL

|
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
As you may know, Amazon Kinesis greatly simplifies the process of working with real-time streaming data in the AWS Cloud. Instead of setting up and running your own processing and short-term storage infrastructure, you simply create a Kinesis Stream or Kinesis Firehose, arrange to pump data in to it, and then build an application to process or analyze it.
While it is relatively easy to build streaming data solutions using Kinesis Streams and Kinesis Firehose, we want to make it even easier. We want you, whether you are a procedural developer, a data scientist, or a SQL developer, to be able to process voluminous clickstreams from web applications, telemetry and sensor reports from connected devices, server logs, and more using a standard query language, all in real time!
Amazon Kinesis Analytics
 Today I am happy to be able to announce the availability of Amazon Kinesis Analytics. You can now run continuous SQL queries against your streaming data, filtering, transforming, and summarizing the data as it arrives. You can focus on processing the data and extracting business value from it instead of wasting your time on infrastructure. You can build a powerful, end-to-end stream processing pipeline in 5 minutes without having to write anything more complex than a SQL query.
Today I am happy to be able to announce the availability of Amazon Kinesis Analytics. You can now run continuous SQL queries against your streaming data, filtering, transforming, and summarizing the data as it arrives. You can focus on processing the data and extracting business value from it instead of wasting your time on infrastructure. You can build a powerful, end-to-end stream processing pipeline in 5 minutes without having to write anything more complex than a SQL query.
When I think of running a series of SQL queries against a database table, I generally think of the data as staying more or less static while the queries come and go pretty quickly. Rows are added, changed, and deleted all the time, but this does not generally matter when considering a single query that runs at a particular point in time. Running a Kinesis Analytics query against streaming data turns this model sideways. The queries are long-running and the data changes many times per second as new records, observations, or log entries arrive. Once you wrap your head around this, you will see that the query processing model is very easy to understand: You build persistent queries that process records as they arrive.
In order to control the set of records that will be processed by a given query, you make use of a processing “window.” Kinesis Analytics supports three different types of windows:
Tumbling windows are used for periodic reports. You could use a tumbling window to summarize data over time. Perhaps you get thousands or millions of requests per second, and would like to know how many arrive each minute. When the current tumbling window closes, the next one begins after it. A new result is generated each time the window fills up.
Sliding windows are used for monitoring and other types of trend detection. For example, you could use a sliding window to compute a real-time moving average for an error rate. Records enter the window, contribute to the result as long as they are within it, and the window advances. A new result is generated each time a new record enters the window. You can adjust the size of the window to control the sensitive of the results.
Custom windows are used when the appropriate grouping is not strictly based on time. If you are processing clickstream data or server logs, you can use a custom window to perform an action known as sessionization. In other words, you can bound each query by the first and last actions performed by each user, as identified by a session identifier within the incoming data. You can write a query that computes the number of pages visited by each user or the time that they spend on your site.
While all of this might sound somewhat complicated, it is actually pretty easy to implement. Kinesis Analytics will analyze a sample of the incoming records and then propose a suitable schema. You can use it as-is, or you can fine-tune it to better reflect your actual data model. Once the schema has been defined, you can use the built-in SQL editor (complete with syntax checking and easy testing against live data). You can configure Kinesis Analytics to route the results of the query to up to four destinations including Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, or an Amazon Kinesis Stream.
When you build your first Amazon Kinesis Analytics application you need to write a pair of cooperating SQL statements (more complex applications can use more, but all it takes is two to get up and running):
A statement to create an in-application stream to store intermediate SQL results (a stream is a like a SQL table that is continuously updated, which you can select from and insert into).
Your SQL query, which selects from one in-application stream and inserts into another in-application stream.
Your SQL statements can also JOIN the records to reference data that originates in S3. This can be handy when you want to enhance or modify the records to include additional, perhaps more descriptive, information.
Amazon Kinesis Analytics in Action
Let’s spend a few minutes looking at Amazon Kinesis Analytics in action!
I log in to the Amazon Kinesis Analytics Console and clicking on Create new application. Then I enter a name and a description for my app:
Now I can manage my data source, my queries, and the destination(s):
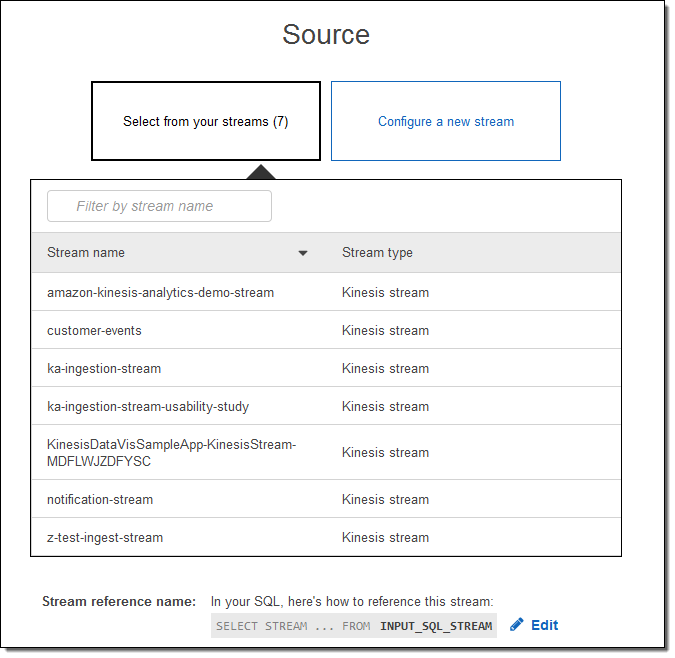
I can select one of my existing input streams:
Or I can configure a new one (I’ll do that):
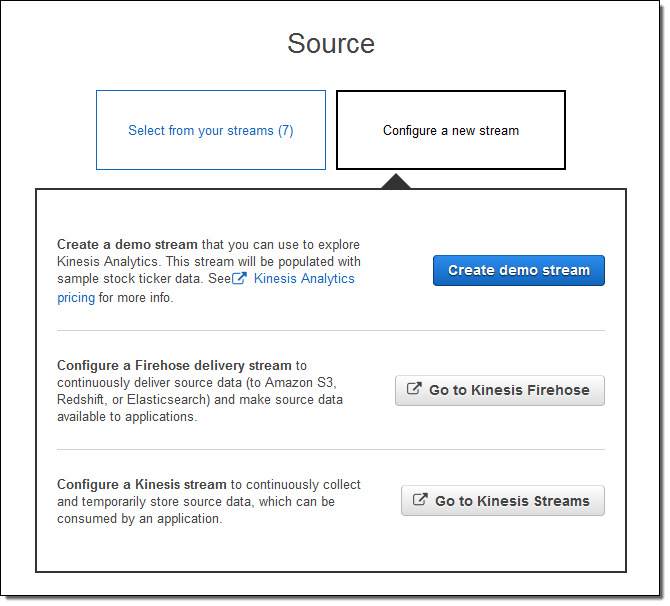
I click on Create demo stream to create a stream that will be populated with sample stock ticker data. This takes 30 to 40 seconds!
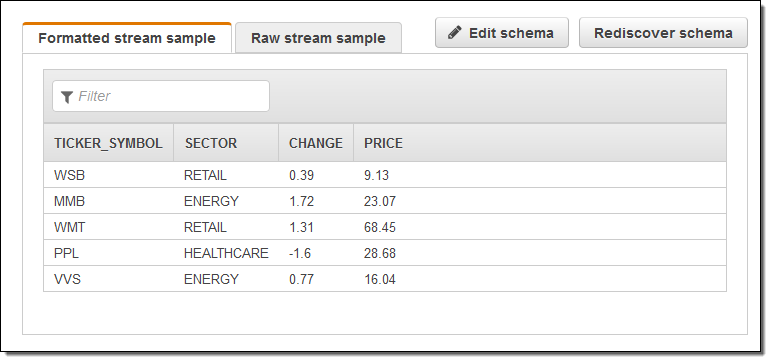
Kinesis Analytics peeks at the stream and proposes a schema. I can accept it as-is or fine tune it:
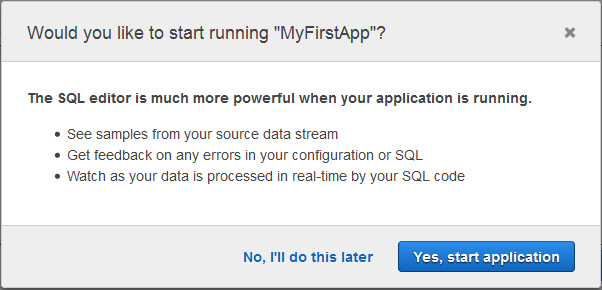
Then I hop over to the SQL editor. It offers to start my app. That seems like a good idea, so I agree and click on Yes, start application:
Here’s the actual SQL editor:
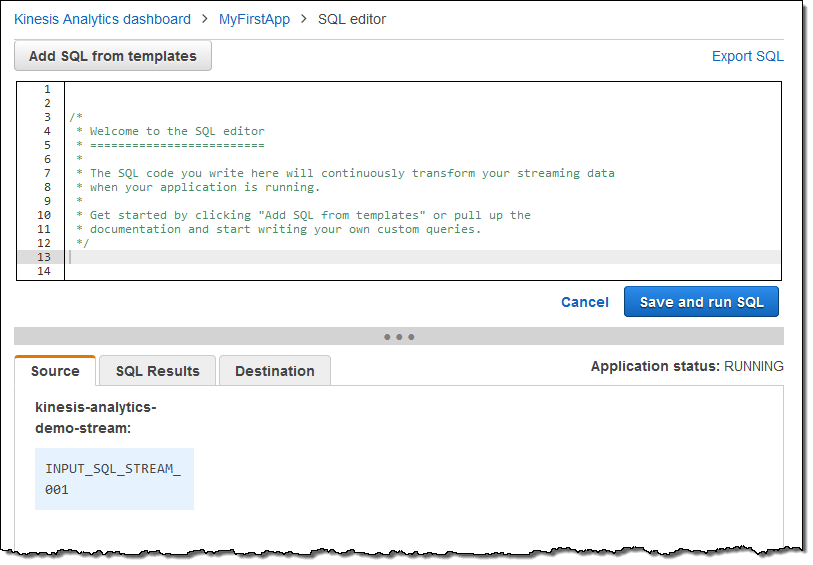
I can write my query from scratch or I can use a template:
I picked Continuous filter; here’s the SQL:
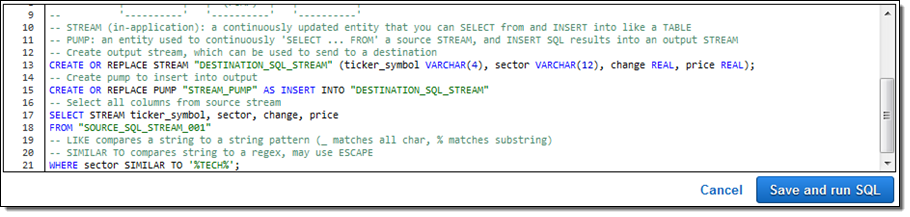
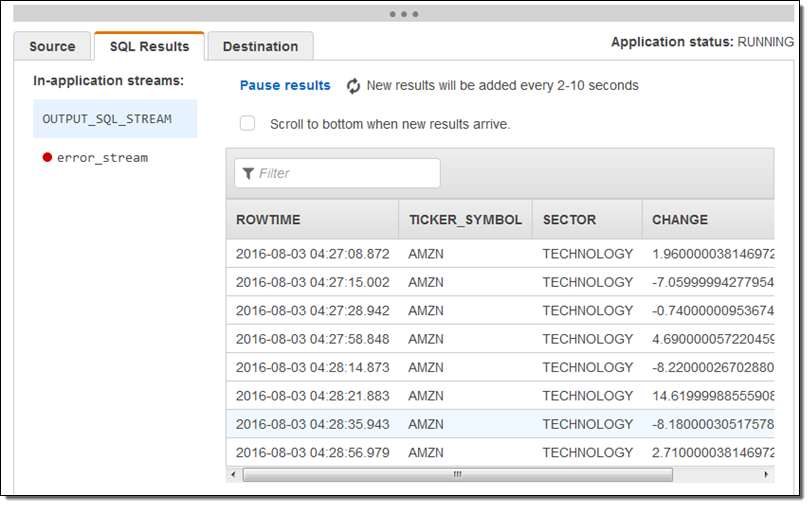
I inspected it, nodded in agreement, and then clicked on Save and run SQL. Within seconds, results began to flow in and were visible in the Console:
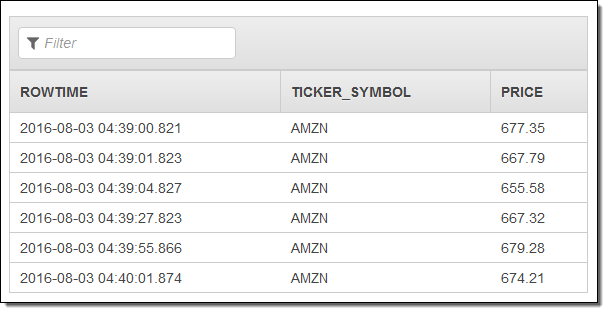
I used the SQL editor to modify the query to remove the sector and price columns and ran the query again. When I did this I learned that I needed to remove the columns from the CREATE STREAM statement (this is obvious in retrospect but it was the end of a long day).
Here’s the revised result set:
In most cases the next step would be to route the results to a new or existing stream. I can do that from the Console:
With just a couple of clicks and a little bit of typing, I have created an Amazon Kinesis Analytics app that is capable of process a production-scale stock ticker stream. This “demo” needs no changes whatsoever before being used in production. I think that’s kind of cool.
Learn More & Try it Yourself
As usual, I have barely scratched the surface of this exciting new service! To learn more, you should read the new post, Writing SQL on Streaming Data with Amazon Kinesis Analytics.
You should be able to replicate my steps above in 5 minutes or less and I strongly recommend that you do so. Create your application, customize the SQL query, and learn how to process streaming data at scale.
Available Now
Amazon Kinesis Analytics is available now and you can start running queries against your streaming data today!
— Jeff;