- Amazon Builders' Library›
- Evitare il fallback nei sistemi distribuiti
Evitare il fallback nei sistemi distribuiti
ARCHITETTURA | LIVELLO 300
Introduzione
Gli errori critici impediscono a un servizio di produrre risultati utili. Ad esempio, in un sito Web di e-commerce, se una query di database relativa alle informazioni del prodotto non va a buon fine, il sito Web non può visualizzare correttamente la pagina del prodotto. I servizi di Amazon devono gestire la maggior parte degli errori critici per poter essere affidabili. Sono presenti quattro grandi categorie di strategie per la gestione di errori critici:
-
Riprova: esegue nuovamente l'attività non riuscita, immediatamente o dopo un certo ritardo.
-
Riprova proattiva: esegui l'attività più volte in parallelo e utilizza la prima per terminare.
-
Failover: esegui nuovamente l'attività su una copia diversa dell'endpoint o, preferibilmente, esegui più copie parallele dell'attività per aumentare le probabilità che almeno una di esse abbia successo.
-
Fallback: utilizza un meccanismo diverso per ottenere lo stesso risultato.
Questo articolo si occuperà di strategie di fallback e del perché non vengono quasi mai utilizzate qui ad Amazon. Potrebbe sorprendervi. Dopo tutto, gli ingegneri utilizzano spesso il mondo reale come punto di partenza per le loro progettazioni. E, nel mondo reale, le strategie di fallback devono essere pianificate in anticipo e impiegate quando necessario. Ammettiamo che i tabelloni di un aeroporto si spengano. Deve essere presente un piano di contingenza (come scrivere a mano su lavagne le indicazioni relative ai voli) per poter gestire la situazione, poiché i passeggeri devono comunque trovare i loro gate. Ma considerate l'insostenibilità del piano di contingenza: la difficoltà di leggere le lavagne, il problema di tenere i passeggeri aggiornati e il rischio che il personale aggiunga informazioni sbagliate. La strategia di fallback della lavagna è necessaria, ma piena di problemi.
Nel mondo dei sistemi distribuiti, le strategie di fallback sono tra le sfide più difficili da gestire, in particolare nel caso di servizi urgenti. A complicare il problema interviene il fatto che le cattive strategie di fallback possono impiegare molto tempo (addirittura anni) prima di occasionare ripercussioni e la differenza tra una buona o cattiva strategia è davvero sottile. In questo articolo, ci concentreremo su come le strategie di fallback possano causare più problemi di quanti ne risolvano. Includeremo esempi relativi a dove le strategie di fallback hanno dato luogo a difficoltà ad Amazon. Infine, discuteremo le alternative al fallback utilizzate ad Amazon.
L'analisi delle strategie di fallback per i servizi non è intuitiva e gli effetti a catena sono difficili da prevedere nei sistemi distribuiti, pertanto, cominciamo prima con l'esaminare le strategie di fallback per un'applicazione su macchina singola.
Fallback su macchina singola
Considerate il seguente frammento in C che illustra uno schema comune nella gestione degli errori di allocazione della memoria in molte applicazioni. Questo codice alloca la memoria attraverso la funzione malloc() e copia in seguito un buffer di immagini all'interno della stessa, mentre esegue una sorta di trasformazione:
pixel_ranges = malloc(image_size); // allocates memory
if (pixel_ranges == NULL) {
// On error, malloc returns NULL
exit(1);
}
for (i = 0; i < image_size; i++) {
pixel_ranges[i] = xform(original_image[i]);
}Fallback su una sola macchina, (continua)
Il ripristino del codice non avviene correttamente nel caso in cui malloc non vada a buon fine. In pratica, è molto raro che le chiamate a malloc non vadano a buon fine, perciò gli sviluppatori ignorano spesso gli errori all'interno del codice. Perché tale strategia è così frequente? La ragione risiede nel fatto che, su una macchina singola, l'errore di malloc è probabilmente dovuto all'esaurimento della memoria. Ci sono pertanto problemi più gravi di una chiamata malloc che non va a buon fine: la macchina potrebbe presto arrestarsi in modo anomalo. E, nella maggior parte dei casi, si tratta di un buon ragionamento per una macchina singola. Molte applicazioni non sono abbastanza critiche da valere lo sforzo di risolvere un problema così spinoso. Ma se invece aveste voluto gestire l'errore? In questa situazione risulta difficile cercare di fare qualcosa di utile. Ammettiamo di implementare un secondo metodo chiamato malloc2 che alloca la memoria in modo diverso e ricorriamo a malloc2 nel caso in cui l'implementazione del malloc predefinito non vada a buon fine:
pixel_ranges = malloc(image_size);
if (pixel_ranges == NULL) {
pixel_ranges = malloc2(image_size);
}Fallback su una sola macchina, (continua)
A prima vista, sembra che questo codice possa funzionare, ma sono presenti problemi, alcuni meno evidenti di altri. Per cominciare, la logica di fallback è difficile da testare. Potremmo intercettare la chiamata a malloc e inserire un errore, ma ciò potrebbe non simulare accuratamente cosa accadrebbe nell'ambiente di produzione. In produzione, l'errore di malloc è probabilmente dovuto all'esaurimento o alla quantità insufficiente di memoria della macchina. In che modo è possibile simulare questi problemi di memoria più ampi? Anche se fosse possibile generare un ambiente di memoria insufficiente all'interno del quale eseguire il test (diciamo, in un container Docker), in che modo impostereste la condizione di memoria insufficiente per farla coincidere con l'esecuzione del codice di fallback malloc2?
Un altro problema è che il fallback stesso potrebbe fallire. Il codice di fallback precedente non gestisce l'errore di malloc2, pertanto il programma non fornisce i benefici che potreste pensare. La strategia di fallback rende gli errori totali meno probabili, ma non impossibili. Noi di Amazon abbiamo scoperto che impiegare risorse ingegneristiche nel rendere il codice primario (non di fallback) più affidabile incrementa di solito maggiormente le nostre probabilità di successo rispetto all'investire in una strategia di fallback poco utilizzata.
Inoltre, se la disponibilità è la nostra massima priorità, la strategia di riserva potrebbe non valere il rischio. Perché disturbarsi con malloc, se malloc2 ha maggiori probabilità di successo? Logicamente, malloc2 deve trovare un compromesso in cambio della sua più elevata disponibilità. Forse alloca memoria in uno storage basato su SSD con maggior latenza, ma più grande. Tuttavia, ciò solleva la questione del perché il compromesso di malloc2 vada bene. Consideriamo una potenziale sequenza di eventi che potrebbero verificarsi con questa strategia di fallback. Prima di tutto, il cliente sta utilizzando l'applicazione. Improvvisamente (a causa dell'errore di malloc), malloc2 entra in funzione e l'applicazione rallenta. Ciò è negativo: va davvero bene essere più lenti? E i problemi non finiscono qui. Considerate che la macchina abbia probabilmente esaurito la memoria o non ne disponga a sufficienza. Il cliente ora avrà due problemi (applicazione più lenta e macchina più lenta) al posto di uno. Gli effetti collaterali del passaggio a malloc2 potrebbero addirittura peggiorare l'intero problema. Ad esempio, altri sottosistemi potrebbero inoltre contendersi lo stesso storage basato su SSD.
La logica di fallback può anche comportare un carico imprevedibile sul sistema. Anche una logica comune e semplice quale scrivere un messaggio di errore per un log con una traccia dello stack può apparire innocua in superficie, ma se qualcosa cambia all'improvviso per far sì che quell'errore si verifichi ad un ritmo elevato, un'applicazione legata alla CPU potrebbe improvvisamente trasformarsi in un'applicazione basata su I/O. E se non era stato effettuato il provisioning del disco perché gestisse la scrittura a tale velocità o memorizzasse tale volume di dati, l'applicazione può essere rallentata o arrestata in modo anomalo.
La strategia di fallback non solo potrebbe peggiorare il problema, ma probabilmente si presenterà come un bug latente. È semplice sviluppare strategie di feedback che si attivano raramente in produzione. Potrebbero volerci anni prima che una delle macchine del cliente esaurisca davvero la memoria proprio nel momento giusto per attivare la linea di codice specifica con il fallback a malloc2 mostrato in precedenza. Nel caso in cui sia presente un bug nella logica di fallback o qualche tipo di effetto secondario che peggiora l'intero problema, gli ingegneri che hanno scritto il codice si saranno probabilmente dimenticati di come funziona e sarà più difficile correggerlo. Per un'applicazione su macchina singola, ciò potrebbe rappresentare un compromesso aziendale accettabile, ma nei sistemi distribuiti le conseguenze sono molto più significative, come vedremo in seguito.
Tutti questi problemi sono spinosi, ma secondo la nostra esperienza possono essere spesso ignorati in tutta sicurezza nelle applicazioni su macchina singola. La soluzione più comune è quella menzionata in precedenza: lasciare semplicemente che gli errori di allocazione della memoria arrestino l'applicazione in modo anomalo. Il codice che alloca la memoria possiede una proprietà di fate-sharing con il resto della macchina ed è abbastanza probabile che, in questo caso, il resto della macchina stia per smettere di funzionare. Anche se non possedesse una proprietà di fate-sharing, l'applicazione sarebbe ora in uno stato non anticipato e smettere di funzionare velocemente si rivela una buona strategia. Il compromesso aziendale è ragionevole.
Per le applicazioni critiche su macchina singola che devono funzionare in caso di errori nell'allocazione della memoria, una soluzione consiste nel pre-allocare tutta la memoria heap all'avvio e non fare mai più affidamento su malloc, nemmeno in condizioni di errore. Amazon ha attuato questa strategia diverse volte, ad esempio, nel monitoraggio di deamon eseguiti su server di produzione e deamon di Amazon Elastic Compute Cloud (Amazon EC2) che controllano tutte le espansioni della CPU dei clienti.
Fallback distribuito
Noi di Amazon non consentiamo ai sistemi distribuiti, in particolare quelli configurati per rispondere in tempo reale, di effettuare gli stessi compromessi delle applicazioni a macchina singola. Una delle ragioni è la mancanza della proprietà di fate-sharing con il cliente. Supponiamo che le applicazioni siano in esecuzione sulla macchina posizionata di fronte al cliente. Se l'applicazione esaurisce la memoria, il cliente probabilmente non si aspetta che continui a funzionare. I servizi non vengono eseguiti sulla stessa macchina utilizzata direttamente dal cliente, quindi l'aspettativa è diversa. Oltre a ciò, i clienti utilizzano solitamente i servizi proprio perché sono più disponibili rispetto ad un'applicazione in esecuzione su un unico server, pertanto, dobbiamo renderli tali. In teoria, ciò dovrebbe condurci ad attuare il fallback come modo per rendere il servizio più affidabile. Sfortunatamente, il fallback distribuito possiede tutti gli stessi problemi, se non di più, quando si tratta di errori di sistema critici.
Le strategie di fallback distribuite sono più difficili da testare. Il fallback del servizio è più complicato rispetto al caso dell'applicazione su macchina singola, poiché la presenza di più macchine e i servizi di downstream svolgono un ruolo negli errori. Le stesse modalità di errore, come gli scenari di sovraccarico, sono difficili da riprodurre in un test, anche se l'orchestrazione del test su più macchine è facilmente disponibile. La combinatoria aumenta inoltre l'elevato numero dei casi da testare, perciò sono necessari più test di più difficile configurazione.
Le stesse strategie di fallback distribuite possono fallire. Sebbene possa sembrare che le strategie di riserva garantiscano il successo, secondo la nostra esperienza, di solito migliorano solo le probabilità di successo.
Le strategie di fallback distribuite spesso peggiorano l'interruzione. Nella nostra esperienza, le strategie di fallback aumentano la portata dell'impatto degli errori, nonché i tempi di ripristino.
Spesso le strategie di fallback distribuito non valgono il rischio. Come nel caso di malloc2, la strategia di fallback comporta spesso un qualche tipo di compromesso, altrimenti vi faremmo ricorso in continuazione. Perché il ricorso a un fallback dovrebbe peggiore la situazione, se c'è già qualcosa che va storto?
Le strategie di fallback distribuite presentano spesso bug latenti che si manifestano solo quando si verifica una serie improbabile di coincidenze, potenzialmente mesi o anni dopo la loro introduzione.
Un'importante, reale interruzione dell'attività causata da un meccanismo di fallback nel sito Web di vendita al dettaglio di Amazon illustra tutti questi problemi. L'interruzione dell'attività si è verificata attorno al 2001 ed è stata dovuta ad una nuova caratteristica che forniva le velocità di spedizione aggiornate per tutti i prodotti mostrati sul sito Web.
La nuova caratteristica era più o meno così:

Quindi abbiamo aggiunto un livello di caching in esecuzione come processo separato su ogni server web
All'epoca, l'architettura del sito Web possedeva solamente due livelli e, dal momento che i dati erano memorizzati in un database della catena di distribuzione, i server Web dovevano interrogare direttamente il database. Tuttavia, il database non riusciva a tenere il passo con il volume di richieste del sito Web. Il sito Web possedeva un elevato volume di traffico e alcune pagine mostravano 25 o più prodotti, con la velocità di spedizione visualizzata assieme ad ogni prodotto. Quindi abbiamo aggiunto un livello di caching in esecuzione come processo separato su ogni server web (un po' come Memcached):
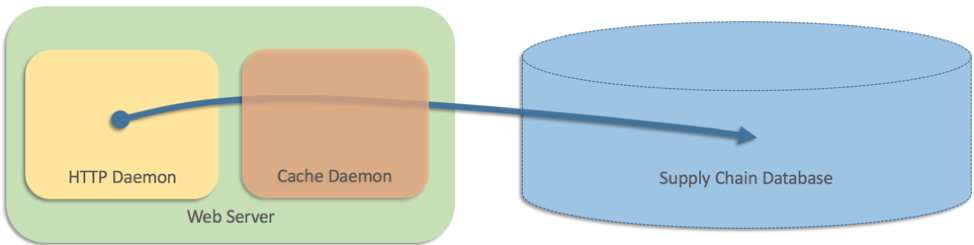
In pseudocodice, abbiamo scritto più o meno questo:
Ciò ha funzionato, ma il team ha inoltre cercato di gestire il caso in cui la cache (un processo separato) non andasse a buon fine per qualche ragione. In questo scenario, i server Web venivano ripristinati per interrogare direttamente il database. In pseudo-codice, abbiamo scritto qualcosa del genere: ricorrere alle query dirette al database è stata una soluzione intuitiva che ha funzionato per diversi mesi. Ma, alla fine, si è verificato l'errore di tutte le cache più o meno nello stesso momento, stando a significare che ogni server Web aveva colpito direttamente il database. Ciò ha creato un carico sufficiente da bloccare completamente il database. L'intero sito Web si è interrotto perché tutti i processi di server Web erano bloccati sul database. Questo database della catena di fornitura era fondamentale anche per i centri logistici, quindi l'interruzione si è ulteriormente estesa e tutti i centri logistici in tutto il mondo si sono fermati fino alla risoluzione del problema. Tutti i problemi riscontrati nel caso con una sola macchina erano presenti nel caso distribuito con conseguenze più gravi. È stato difficile testare il caso di fallback distribuito; anche se avessimo simulato l'errore della cache, non avremmo trovato il problema, che richiedeva errori su più macchine per attivarsi. E in questo caso, la strategia di riserva stessa ha amplificato il problema ed è stata peggiore di nessuna strategia di riserva. Il fallback ha trasformato un'interruzione parziale del sito Web (impossibilità di visualizzare le velocità di spedizione) in un'interruzione dell'intero sito (nessuna pagina caricata) e ha bloccato l'intera rete logistica di Amazon nel back-end. Il pensiero alla base della nostra strategia di riserva in questo caso era illogico. Se colpire il database direttamente risultava più affidabile di impiegare la cache, perché disturbarsi del tutto con la cache? Temevamo che non usando la cache il database si sarebbe sovraccaricato, ma perché preoccuparci di avere un codice di fallback se poteva potenzialmente risultare così dannoso? Potremmo aver notato il nostro errore all'inizio, ma il bug era latente e la situazione che ha causato l'interruzione si è manifestata mesi dopo il lancio.
if (cache_healthy) {
shipping_speed = get_speed_via_cache(sku);
} else {
shipping_speed = get_speed_from_database(sku);
}In che modo Amazon evita i fallback
Visti i tranelli in cui siamo caduti nel fallback distribuito, preferiamo ora quasi sempre alternative al fallback. Eccole evidenziate di seguito.
Migliorare l'affidabilità dei casi non di fallback
Come menzionato in precedenza, le strategie di fallback riducono semplicemente la probabilità di errori totali. Un servizio può essere molto più disponibile se il codice principale (non di fallback) viene rafforzato. Ad esempio, invece di implementare una logica di fallback tra due diversi store di dati, un team può investire nell'utilizzo di un database con una disponibilità intrinseca più elevata, quale Amazon DynamoDB. Tale strategia è spesso utilizzata con successo ad Amazon. Ad esempio, questo talk descrive l'utilizzo di DynamoDB per potenziare amazon.com nel Prime Day 2017.
Lasciare che gli intermediari gestiscano gli errori
Una soluzione agli errori critici del sistema non è il ricorso al fallback, ma il lasciar gestire questi ultimi al sistema in chiamata (attraverso nuovi tentativi, ad esempio). Si tratta di una strategia preferita per i servizi AWS, dove le interfacce a riga di comando e i kit SDK possiedono già una logica integrata di ripetizione dei tentativi. Quando possibile preferiamo questa strategia, in particolare in situazioni in cui sono stati compiuti molti sforzi nella proprietà di fate-sharing e nella riduzione della probabilità di errore del caso principale (e la logica di fallback non migliorerebbe proprio, molto probabilmente, la disponibilità).
Inviare i dati proattivamente
Un altro approccio che impieghiamo per evitare di ricorrere al fallback è la riduzione del numero di parti mobili nella risposta alle richieste. Se, ad esempio, un servizio necessita di dati per soddisfare una richiesta e tali dati sono già presenti localmente (non devono essere recuperati), la strategia di failover non è necessaria. Un esempio di successo è l'implementazione dei ruoli AWS Identity and Access Management (IAM) per Amazon EC2 . Il servizio IAM deve fornire credenziali firmate e in rotazione al codice in esecuzione sulle istanze EC2. Per evitare del tutto il bisogno di fallback, le credenziali vengono inviate proattivamente ad ogni istanza e restano valide per molte ore. Ciò significa che le richieste collegate al ruolo IAM continuano a funzionare nell'improbabile caso di un errore nel meccanismo di invio.
Convertire il fallback in un failover
Una delle caratteristiche peggiori di un fallback è che non viene esercitato regolarmente ed è molto probabile che non vada a buon fine o che aumenti la portata dell'impatto quando viene attivato durante un'interruzione dell'attività. Le circostanze che attivano il fallback potrebbero non verificarsi naturalmente per mesi o addirittura anni! Per affrontare il problema degli errori latenti nella strategia di fallback, è importante esercitarla regolarmente in produzione. Un servizio deve eseguire in continuazione la logica sia di fallback che di non fallback. Non deve semplicemente eseguire il caso di fallback, ma trattarlo inoltre come fonte di dati ugualmente valida. Ad esempio, un servizio potrebbe scegliere casualmente tra le risposte di fallback e non di fallback (quando le riceve indietro) per assicurarsi che entrambe funzionino. Tuttavia, a questo punto la strategia non può più essere considerata di fallback e ricade decisamente nella categoria del failover.
Assicurarsi che i nuovi tentativi e i timeout non diventino fallback
I tentativi e i timeout sono discussi nell'articolo Timeout, Retries e Backoff with Jitter. L'articolo afferma che i nuovi tentativi sono un potente meccanismo per fornire un'elevata disponibilità a fronte di errori transitori e casuali. In altre parole, i nuovi tentativi e i timeout forniscono un'assicurazione contro gli errori occasionali dovuti a questioni minori quali perdita di pacchetti spuri, errori su macchina singola non correlati e simili. Tuttavia, è semplice che si verifichino errori con i nuovi tentativi e i timeout. Possono trascorrere spesso mesi o più prima che i servizi necessitino di molti nuovi tentativi, che potrebbero alla fine manifestarsi durante scenari mai testati dal vostro team. Per questo motivo, manteniamo parametri che monitorano i tassi generali di nuovi tentativi e allarmi che avvisano i nostri team nel momento in cui i nuovi tentativi ricorrono con frequenza.
Un altro modo per evitare che i tentativi si trasformino in fallback è eseguirli continuamente con un ritentativo proattivo (noto anche come hedging o richieste parallele). Tale tecnica è intrinsecamente progettata in sistemi che eseguono letture o scritture dei quorum, dove un sistema potrebbe richiedere una risposta di due server su tre per poter rispondere. La ripetizione proattiva segue lo schema di progettazione del lavoro costante. Poiché vengono sempre effettuate richieste ridondanti, i nuovi tentativi non aggiungono un ulteriore carico al sistema quando la necessità di richieste ridondanti aumenta.
Conclusione
Noi di Amazon evitiamo il fallback all'interno dei nostri sistemi poiché è difficile da provare e la sua efficacia è complicata da testare. Le strategie di fallback introducono una modalità operativa a cui il sistema accede solo nei momenti più caotici, quando le cose cominciano a rompersi, e il passaggio a questa modalità non fa altro che incrementare la confusione. Spesso l'intervallo tra il momento in cui viene attuata una strategia di fallback e il momento in cui viene riscontrata in un ambiente di produzione è ampio.
Al contrario, preferiamo percorsi del codice che vengono continuamente esercitati in produzione piuttosto che raramente. Ci concentriamo sul miglioramento della disponibilità dei nostri sistemi primari, attraverso schemi quali l'invio di dati ai sistemi che li necessitano, invece di caricarli e rischiare che una chiamata remota non vada a buon fine in un momento critico. Infine, facciamo attenzione a piccoli comportamenti del mostro codice che potrebbero proiettarlo in una modalità operativa simile al fallback, come l'eseguire troppi nuovi tentativi.
Se il fallback è essenziale in un sistema, facciamo in modo di esercitarlo il più possibile in produzione, in modo che si comporti con la stessa prevedibilità e affidabilità della principale modalità operativa.
Informazioni sull'autore
Jacob Gabrielson è Senior Principal Engineer presso Amazon Web Services. Lavora presso Amazon da 17 anni, principalmente sulle piattaforme di microservizi interne. Negli ultimi 8 anni ha lavorato su EC2 ed ECS, compresi i sistemi di distribuzione del software, i servizi di pannello di controllo, il mercato di istanze Spot, Lightsail e, più recentemente, i container. Le passioni di Jacob sono la programmazione di sistemi, i linguaggi di programmazione e il calcolo distribuito. La sua antipatia più grande riguarda il comportamento dei sistemi bimodali, in particolare in condizioni di errore. Ha conseguito una laurea in Scienze informatiche presso L'Università di Washington a Seattle.
