AWS Big Data Blog
How OrthoFi delivers better insights for customers with Amazon Redshift and AWS Glue
This is a guest post by Christa Pierson and Jon Fearer at OrthoFi.
OrthoFi is an orthodontic industry leader in revenue cycle management (RCM), and has partnered with more than 550 orthodontic practices across the country, delivering an end-to-end platform that enables orthodontists to bring on more patients and run their businesses more effectively. To date, OrthoFi has helped their clients provide more than half a million patients with high-quality, affordable orthodontic treatment, and has been named to the Inc. 5000 list of the nation’s fastest-growing private companies three times.
In this post, we discuss how OrthoFi migrated to Amazon Redshift and AWS Glue to deliver better insights for customers.
The challenge
OrthoFi is a leader in the services that we provide; however, many of our clients use a tool called Gaidge for data and analytics. Specifically, our customers use our platform to manage patient payment plans and the insurance claim lifecycle, but use Gaidge and custom analytics to get the big picture view of things like cash flow and business health. Without an integration between our systems, many of these clients were struggling to get an accurate picture of the performance of their businesses because their data was siloed.
To solve this problem, we decided to build an integration between our two platforms. The primary goal of the integration was to provide a single comprehensive view of business metrics to our customers in order to help them better run their orthodontic practices. A secondary goal was to extend it to support internal business intelligence and future integrations for clients building their own data lakes or data warehouses. In the past, we had started down the path of building a data warehouse, but struggled with managing complex extract, transform, and load (ETL) pipelines as well as configuring compute usage in a way that was cost-efficient. Taking from these learnings, we knew that we wanted to choose mature tools that were also affordable.
Solutions considered and decisions made
Given the problem at hand and our own needs for custom analytics, we decided to migrate off of our existing ETL and Snowflake data warehouse solution in order to address the following requirements:
- Easily move data from our line of business (LOB) applications to a centralized data warehouse
- Efficiently aggregate the data after it’s in the data warehouse
- Build an API layer to serve up this data to integration partners and customers, while accounting for things such as security and performance
For the data pipelines, we decided to go with an ETL solution over streaming tools like Kafka or Amazon Kinesis because our use cases didn’t dictate that our data be constantly fresh up to the minute or even hour. For example, Gaidge only needs to ingest our data nightly. We also wanted to spend as little time as possible integrating our LOB applications with the warehouse, so we could focus more time on accurately calculating business metrics and standing up the API. An issue that added to the complexity of our existing ETL pipelines was the management of the Amazon Elastic Compute Cloud (Amazon EC2) instances used to run the jobs as well as the associated software licensing. A final requirement was to use a tool that tightly integrates with other AWS services, as we almost exclusively use AWS company-wide.
Each of these decision points led us to go with AWS Glue, so we could take advantage of code generation and ease of integration with OLTP databases that we already use, such as SQL Server and Amazon Aurora PostgreSQL. AWS Glue also doesn’t require software licensing and is serverless, which meant that we wouldn’t have to manage EC2 instances.
When it came to choosing the primary database engine to support the data warehouse, we had to decide whether it would be worthwhile to migrate off of Snowflake. We wanted to reduce our operating costs, but also needed to deliver results quickly. We had already decided on AWS Glue and wanted to run the API layer on AWS as well, so we needed a tool that easily integrated with other AWS services. When looking at the flexible pricing models of Amazon Redshift and ease of integration with AWS Glue and AWS Lambda, we determined that we could deliver both the migration and the new integration rapidly.
Finally, the API layer was perhaps the easiest choice for us. We were already using Amazon API Gateway and Lambda extensively for other projects, so we decided to build a .NET Core API running on Lambda to serve up data to integration partners. One concern we had was avoiding cold starts and timeouts, so we used provisioned concurrency to mitigate this. If we need to serve up larger or more complex datasets in the future, we’ll probably consider a container or Amazon EC2-based solution instead.
Technical details
With regards to the ETL pipelines, we were able to generate all of our Python-based AWS Glue jobs using the ETL script-generation API within the AWS SDK. This arguably saved us months of development time compared to writing our own custom ETL. The ETL scripts (Python files) and AWS Glue jobs are all managed and deployed with Terraform. We’re also considering using AWS Database Migration Service (AWS DMS) for its ongoing replication feature. Although most of our reporting requirements aren’t near-real time, adding an ongoing replication pipeline would allow us to satisfy future needs for data that is up to date within the last few minutes.
For aggregating the data, we use materialized views that are refreshed after the data is loaded by the AWS Glue jobs. We went with this approach because much of the business logic for OrthoFi’s proprietary reporting was already written in SQL, so a port of this logic to Amazon Redshift materialized views was relatively straightforward. Tools are available for converting SQL between dialects, but in our case, the required changes were minimal enough to make them by hand. The actual refresh commands are run by a Lambda function that is triggered by an Amazon CloudWatch Events rule. We chose to run the refreshes on a schedule in order to guarantee that the latest data is always available for the Gaidge integration, but we also plan to use the automatic refresh feature in Amazon Redshift for future use cases.
For sizing our Amazon Redshift cluster, we tried out a few different sizes and looked at the performance of our materialized view refreshes and latency of our API layer. We found that when loading the data via AWS Glue and refreshing the views, a cluster size of six DC2.Large nodes gave us the performance that we needed. At all other times, we keep the cluster size at three nodes to reduce cost. We use elastic resizing to scale up and down between the two configurations. As our data volumes increase in the future due to OrthoFi’s organic growth and additional analytic needs, we may consider using RA3 node types in order to take advantage of the managed storage and performance improvements.
In the effort to move from our previous ETL tool to AWS Glue, we needed to reproduce our jobs in AWS Glue to point to Amazon Redshift. AWS Glue allowed for the replication of tables and views directly from our database to Amazon Redshift with minimal setup. This allowed a complete transfer of our ETL processes in less than an hour. Next, we needed to move our data warehouse in Snowflake over to Amazon Redshift. Because Amazon Redshift can interact with Amazon Simple Storage Service (Amazon S3) so easily, we were able to do bulk transfers of data from Snowflake to Amazon Redshift with minimal effort.
Our strategy for the data migration was to use the Snowflake COPY command to first copy the data into an S3 bucket. This was immediately followed by a Redshift COPY command which was used to load the data from S3 into Redshift. We were able to take advantage of the infrequent nature of our ETL jobs in order to avoid data loss during the migration. Note that with this process, you must create a “storage integration” in Snowflake first in order to connect to S3, and you should unload the data in a format that is easily consumable by Redshift. In our case, pipe-delimited CSVs with a maximum file size of 1024 MB worked well. You must also create the appropriate IAM roles for both Snowflake and Redshift to connect to S3. The example scripts below can be used to reproduce this pattern:
The following diagram reflects the architecture discussed.
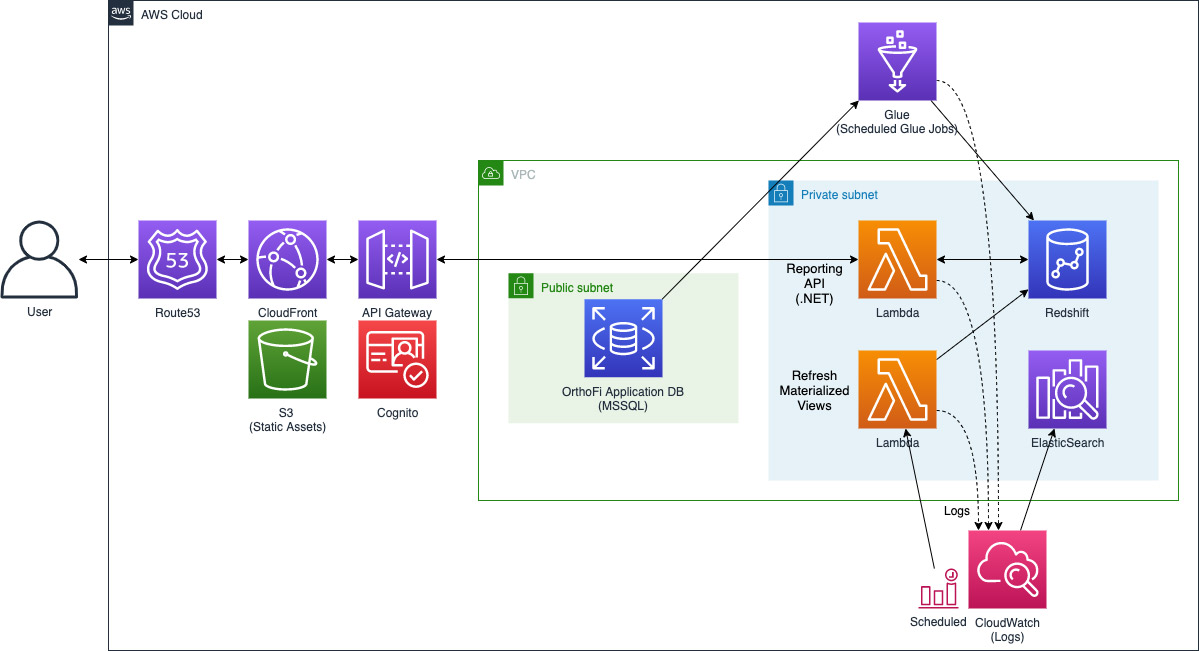
Results
Our integration with Gaidge is in the beta phase, so we’re continuing to iterate by adding new metrics and features frequently. In addition to the initial success of the integration, we’ve found that the operational overhead required is minimal, thanks to the serverless nature of AWS Glue and the built-in fault tolerance features of Amazon Redshift. Adding new practices to the integration and scaling to support larger data volumes has been trivial thanks to these tools. We look forward to enabling the integration for more of our clients in order to empower them to better understand their performance of their businesses.
Next steps
In addition to the Gaidge integration, we have exposed the API to a handful of our larger clients that are building their own data warehouses. This gives OrthoFi’s power users the freedom to explore their own data as needed and aggregate or visualize using the tools of their choice. We’re also hoping to improve our own internal and user-facing analytics in the future. Our goal is to make it as simple as possible for all of our clients to access and analyze their data, and we’ve found it extremely easy to make that happen with AWS data and analytics offerings.
About the Authors
 Christa Pierson, Data & Analytics Lead at OrthoFi
Christa Pierson, Data & Analytics Lead at OrthoFi
 Jon Fearer, Lead Software Engineer at OrthoFi
Jon Fearer, Lead Software Engineer at OrthoFi