Amazon Web Services ブログ
AWS における Amazon SageMaker と AWS Data Exchange を使ったアルゴリズム取引
本投稿は AWSのソリューションアーキテクトである Diego Colombatto, Balaji Gopalan と Oliver Steffmann による寄稿を翻訳したものです。
株式取引の大部分が、こちら や こちら の記事で説明されているように、自動化されていることはよく知られています。たとえば、取引戦略を実装するためにアプリケーションや「ロボット」が使用されています。最近の金融サービス業界の新たなトレンドは、取引ソリューション (アルゴリズム取引ソリューション等) をクラウドに移行することです (こちら や こちら の記事で説明されています)。
移行の理由は 2 つあります。1 つ目はクラウドが提供するメリットを得るため、2 つ目はデータプロバイダーや証券取引所に近付くための新しい方法としてです。
まず、クラウドの主なメリットの 1 つは、ビジネスの俊敏性です。AWS のサービスが提供するテクノロジー、およびほぼ連続的に行われているイノベーションにすばやく簡単にアクセスできる能力、そして従量課金モデルが相まって、関連する先行投資なしに新しいテクノロジーとソリューションを実験し、「パイロット運用」とすることができます。具体的には、キャピタルマーケット業界における企業が AWS に移行し、オンプレミスソリューションをクラウドに拡張したり、クラウドネイティブソリューションを構築したりすることに関し、さまざまな ユースケース やメリットがあります。
2つ目に、金融機関はしばしば、取引所に距離的に近くなるよう、コロケーションスペースを採用することがよく知られています。Bloomberg、 Goldman Sachs、 iSTOX、 Nasdaq、 S&P など、取引所やデータプロバイダーがクラウドに移行すればするほど、金融機関(例: データコンシューマー)も、 (クラウドにおいて) 取引所やデータプロバイダーに近づきクラウドのメリットを活用するためには、同様にクラウドに移行したほうが都合が良くなります。クラウドへの移行は、低レイテンシーを実現する鍵でもあります。これは、高頻度取引などのユースケースにとって非常に重要です。
この移行により、実現できるようになるユースケースもあります。1 つはハイブリッドクラウドアーキテクチャです。例えば、数千ものシミュレーションを実行したり、短期間で機械学習モデルをトレーニングしたりするなど、コンピューティング能力の需要の急上昇に対応するためにクラウドリソースを使用します。このシナリオは、クラウドのメリットと既存のコロケーションリソースの両方を活用します。もう 1 つは、Amazonの機械学習やアナリティクスのサービスを利用して、トレーダーに質の高いシグナルを提供できる定量分析の能力です。
本記事では、アルゴリズム取引ソリューションの大まかなコンポーネントについて簡単に説明し、取引戦略のバックテストという、 特定のユースケースに焦点を当てます。また、AWS で簡単かつ迅速に取引ソリューションを開始することができることを示すため、「ワンクリック」デプロイ、および、AWS クラウドにモジュール式で拡張可能なアルゴリズム取引ソリューションをデプロイして使用する手順を記載します。
このソリューションは、先に述べたユースケースような追加のユースケースに合うよう、後から変更および拡張できます。取り上げてほしいユースケースがありましたら、フィードバックをお待ちしております。
アルゴリズム取引ソリューションの大まかなコンポーネント
大まかに説明すると、アルゴリズム取引ソリューションは、次の図のような構成になっています。
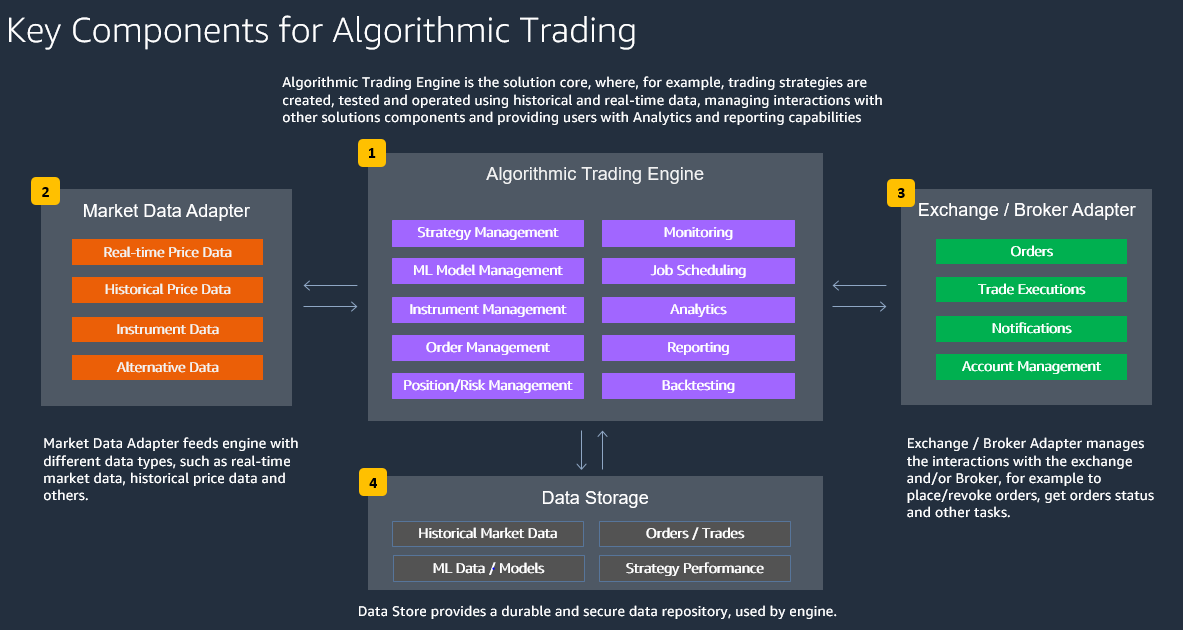
- Algorithmic Trading Engine がソリューションの中核となります。ここでは、例えば取引戦略は過去データおよびリアルタイムデータを使用して作成、テスト、運用されます。また、アルゴリズム取引エンジンは、他のソリューションコンポーネントとのやり取りを管理し、ユーザーに分析およびレポート機能を提供します。
- Market Data Adapter は、 リアルタイムの市場データ、過去の株価データなど、さまざまなデータ型をエンジンにフィードします。
- Exchange / Broker Adapter は、発注 / 注文の取り消し、注文ステータスの取得、その他のタスクなど、取引所やブローカーとのやり取りを管理します
- Data Store は、Algorithmic Trading Engine が使用する、耐久性のある安全なデータリポジトリを提供します。
AWS は、アルゴリズム取引のような専門的なソリューションや垂直ソリューションなど、さまざまなソリューションを作成できる幅広いサービスを提供しています。アルゴリズム取引ソリューションのアーキテクチャを定義する目的で、以下の評価項目を推奨します。
- 取引速度
取引速度と処理する必要があるデータ量によって、各々のコンポーネントに対し使用するAWS 製品は異なる場合があります。低頻度の取引では、Amazon EventBridge と AWS Lambda で十分でしょう。準リアルタイムの取引では、Amazon MSK と Amazon ECS が必要になる場合があります。 - データと分析のニーズ
特にバックテストや機械学習ベースの戦略では、分析目的で AWS Glue、Amazon Athena、および Amazon QuickSight と統合された Amazon Simple Storage Service(Amazon S3) を使用したスケーラブルなストレージソリューションが必要です。注文 / 取引 / ポジションの運用データには、Amazon DynamoDB や Amazon Relational Database Service (Amazon RDS) などのデータベースエンジンを使用できます。 - 柔軟性と拡張性
すべてのアーキテクチャコンポーネントを分離させるには、標準化された API を通じてAlgorithmic Trading Engine を Market Data アダプタおよび外部取引所 / ブローカーに接続するイベント駆動型設計が推奨されます。 - 責任分担と回復性
インフラストラクチャ管理に集中することなく、組み込みの回復性を活用するには、Amazon Virtual Private Cloud(Amazon VPC) で実行される AWS サービスよりも、抽象化された AWS サービスまたはマネージド型AWS サービスが推奨されます(全体の要件に適合する場合)。 - セキュリティ
データの認証、認可、暗号化、および分離には、AWS Identity and Access Management(IAM)、AWS Key Management Service(AWS KMS)、AWS Lake Formation などの AWS ソリューションを使用できます。機密性の高い取引戦略では、データ暗号化にはカスタマー管理型のキーが推奨されます。 - ガバナンス、リスク、コンプライアンス
規制要件(MiFID II、取引レポート)、リスク管理要件、コンプライアンス要件(電子取引セーフガード、記録簿)により、アルゴリズム取引コンポーネントと、この機能を提供する既存のシステムとの統合がさらに強化されます。
前述の評価項目に応じて、AWS のさまざまなサービスを使用して、特定のニーズに合わせて調整されたアルゴリズム取引ソリューションを構築できます。
本記事では、取引戦略のバックテストのためのアルゴリズム取引ソリューションを簡単かつ迅速に作成して開始する方法を説明します。
このソリューションはモジュール式であり、拡張可能な設計になっています。そのため、このソリューションの使用を開始した後に、ニーズに合わせて変更または拡張することができます。たとえば、後から以下のようなことを行えます。
- 入力データの変更、使用する金融商品の変更、取引戦略の変更など、ソリューションコンポーネントの変更。
- Market Data Adapter や Broker Adapter などのコンポーネントを追加して、マーケットオーダーをブローカーに送信。
本ソリューションのアーキテクチャにおける主要な役割は、AWS Data Exchange と Amazon SageMaker が担っています。
- AWS Data Exchange を利用することで、クラウド上のサードパーティーのデータを簡単に検索、サブスクライブ、利用することができます。AWS Data Exchange は、AWS Marketplace において 80 を超える認定データプロバイダーから入手可能な 1,000 を超えるデータ製品を提供しています。対象となるデータプロバイダーには、Reuters、TransUnion、Virtusa、Pitney Bowes、TP ICAP、Vortexa、Enigma、TruFactor、ADP、Dun & Bradstreet、Compagnie Financière Tradition、Verisk、Crux Informatics、TSX Inc. などのカテゴリをリードする新進ブランドが含まれます。
- Amazon SageMaker は、すべての開発者とデータサイエンティストに、機械学習モデルの迅速な構築、トレーニング、デプロイを行う機能を提供します。Amazon SageMaker は、機械学習に使用されるすべてのコンポーネントを 1 つのツールセットで提供しているため、モデルをより少ない労力、かつより低コストで迅速に本番環境へ移行できます。
以下の図は、Market Data とBroker アダプタを含む、包括的なアルゴリズム取引ソリューションの アーキテクチャ を示しています。

本記事で取り上げるソリューションによって実装されるデータフローは以下のようになります。後から適用可能な変更や拡張を含みます。
1. 当日終値データが AWS Data Exchange から取得され、S3 バケットに保存されます。本記事では、Alpha Vantage から取得した過去データを使用します。テストするバックテスト戦略に応じて、AWS Data Exchange または内部データソース(例: 既に利用可能または社内で生成されたデータ)の両方から取得された追加のデータを使用できます。このステップの詳細を以下に説明します。
2.データカタログが AWS Glue で定義されます。Amazon Athena が、AWS Glue データカタログを使用して S3 バケットのデータを直接クエリします。本記事で提供する AWS CloudFormation テンプレートは、AWS Glue データカタログを自動的に作成します。
3.SageMaker ノートブックインスタンスでは、このアーキテクチャに含まれている Jupyter Notebook を使用して ML モデルをトレーニングできます。このアーキテクチャで使用されるノートブックは、S3 バケットから直接データを読み取ります。提供されたノートブックは、必要に応じて更新または置き換えることができます。
4.トレーニングが完了すると、ML モデルは実際のバックテストに使用され、S3 バケットで利用可能なデータを活用し、結果が要件を満たしたときにデプロイできます。
5-6.Market Data Adapter と Broker Adapter は、 AWS Fargate と Amazon Elastic Container Services(Amazon ECS)を使用してコンテナとしてデプロイおよび運用されます。Amazon ECS は完全マネージド型のコンテナオーケストレーションサービスであり、AWS Fargate を使用すると、コンテナ化されたアプリケーションを Amazon ECS で実行できるため、クラスター容量のスケーリングやサイズ変更など、サーバーの選択、プロビジョニング、管理が不要になります。Market Data Adapter と Broker Adapter は、本記事で実装するソリューションには含まれていませんが、追加することができます。これは、このアーキテクチャを拡張する方法の一つとなりますが、今後のブログ記事でこの方法についてお読みになりたい場合は、お知らせください。
7. Trading Strategy は、ポイント 4 で作成された ML モデルによって実装され、 AWS Fargate と Amazon Elastic Container Services(Amazon ECS)を使用してコンテナにデプロイされます。
参照されている GitHub リポジトリには、多層パーセプトロン(順伝播型ニューラルネットワーク) および Layer Normalizationを行ったLSTMパーセプトロンネットワークを持つProximal Policy Optimization(PPO) モデルに基づく長期/短期予測など、ML ベースの取引戦略のサンプルがあります。 これらの戦略の実装方法と運用方法の詳細については、提供されている Jupyter ノートブックで直接確認できます。
8. 戦略がデプロイされ、Broker / Market Dataとの自動的なやり取りが行われると、運用上の優秀性の観点からは、ジョブのスケジューリング、モニタリング、アラート、ログ記録などの機能が必要になります。たとえば、PNL が定義されたしきい値を超えたときに準リアルタイムのアラートを生成し、アラートを人に送信し、アラートを使って自動化された是正措置をトリガーすることができます。
Algorithmic Trading Engine にデータを供給 : AWS Data Exchange にフォーカスする
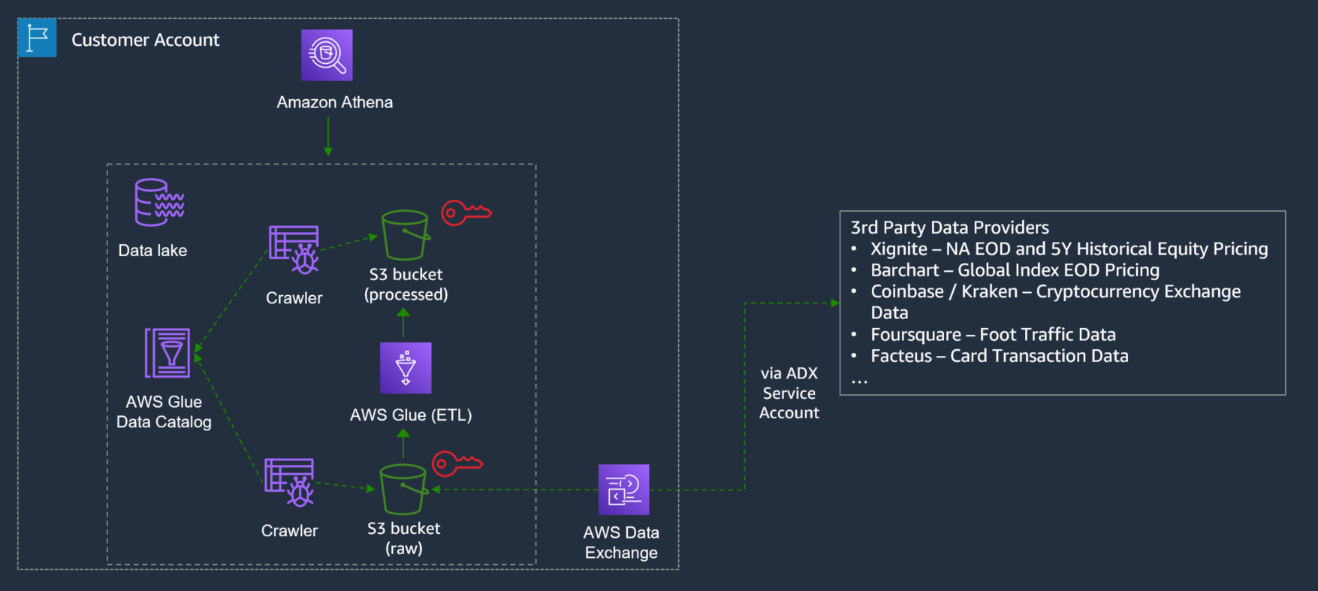
前述のアーキテクチャは、本記事で実装されるアーキテクチャの拡張部分であり、AWS Data Exchange で利用できるデータソースプロバイダーからAlgorithmic Trading Engine へのシームレスなデータフローを実装できます。大まかなデータフローは次のとおりです。AWS Data Exchange で利用可能な、必要なデータプロバイダーを検索してサブスクライブします。データは選択した S3 バケットに保存されます。
AWS Glue クローラは、Amazon S3 上のデータをクロールできます。完了すると、AWS Glue データカタログに 1 つ以上のテーブルを作成できます。
AWS Glue で定義した抽出、変換、ロード (ETL) ジョブでは、これらのデータカタログテーブルをソースとターゲットとして使用し、必要に応じてデータを変換でき、変換されたデータに対して後から分析と ML を実行できるようになります。
デプロイと使用状況の説明
本記事では、 GitHub プロジェクトを使用して環境をセットアップし、データを取得、分析、可視化し、取引戦略をバックテストする手順を説明します。GitHub プロジェクトに直接移動する場合は、 このリンクを使用できます。
- 環境を設定し、データにアクセスする
- 続行するには AWS アカウントが必要です。AWS アカウントをお持ちでない場合は、 新しいアカウントを作成することができます。
- AWS CloudFormation に移動し、ウィンドウの右上にある “N. Virginia Region” リージョンを選択し、”Create stack”->”With new resources(standard)” をクリックし、”Template is ready”、”Upload a template file” を選択します。
- ここをクリックして 、アップロードするテンプレートファイルを取得します。
- スタック名として”algotrading”と入力し、最後までウィザードに従います。
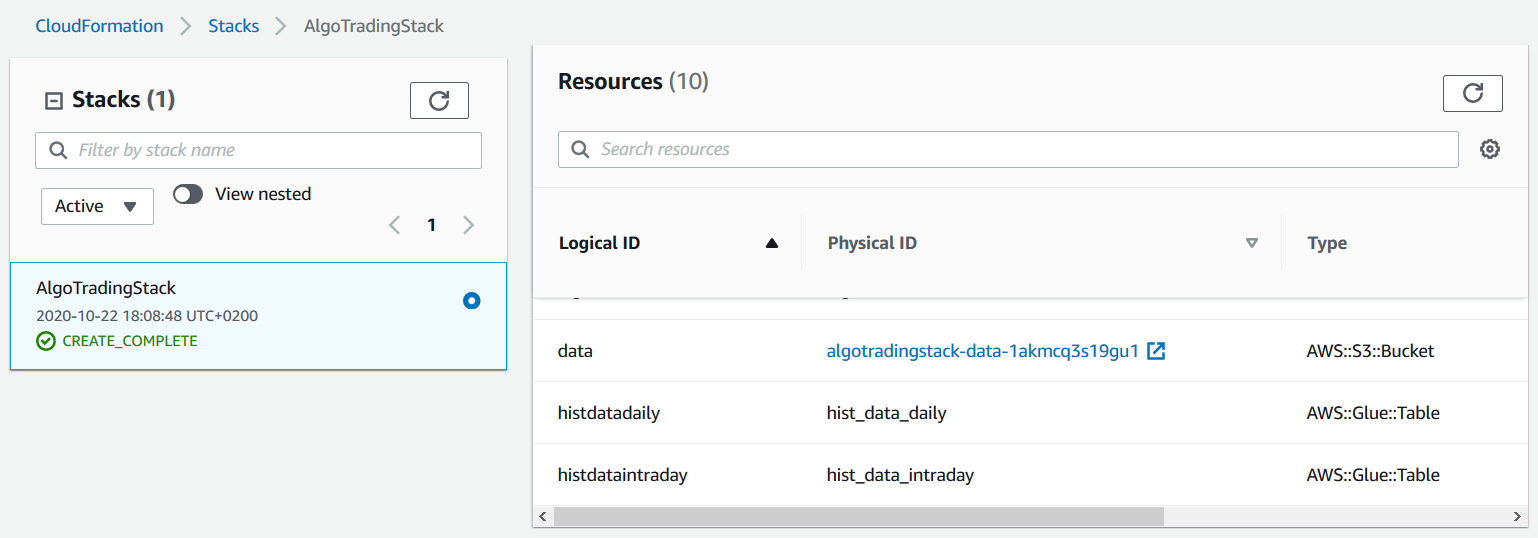
- 次の図に示すように、”AWS CloudFormation resources” タブに移動し、S3 バケット名を確認します。この後すぐにこのバケットを使用して、AWS Data Exchange からデータをコピーします。
- AWS Data Exchange の Alpha Vantage から “20 Years of End-of-Day Stock Data for Top 10 US Companies by Market Cap“というデータ製品にアクセスし、”Continue to Subscribe” をクリックします。

- 自動更新を有効にしたい場合を除き、”Renewal Setting”を”NO”に設定して、”Subscribe” をクリックします。

- サブスクリプションが完了したら、ウィンドウの右上から “Ohio Region”を選択し、”Entitled data” に移動してすべてのアセットを選択し、”Export to Amazon S3″ をクリックして、前に作成したバケットを選択し、”Encryption” で “Amazon S3-manager encryption key(SSE-S3)” を選択します。
- 暗号化はデプロイを完了する上では厳密には必要ではなく、処理時間がわずかに増加する可能性がありますが、セキュリティ上の理由から推奨されます。 Amazon S3 に保存されたデータの暗号化に使用できるさまざまなオプションの詳細については、ここをクリックしてください 。
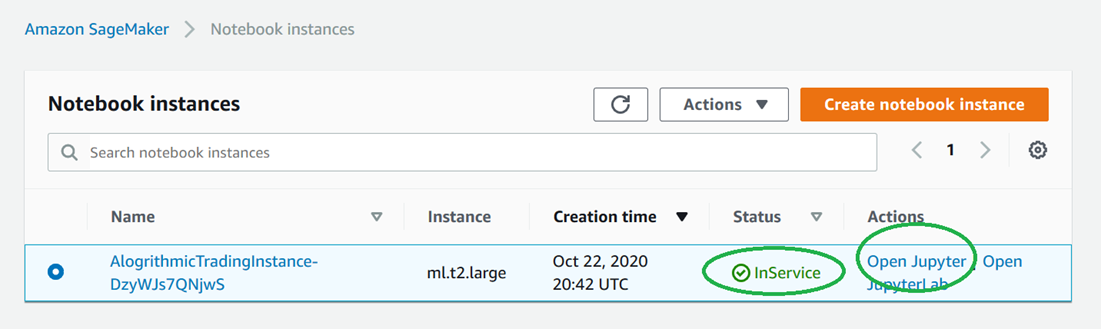
- ノートブックインスタンスに移動し、ステータスが”InService”であることを確認し、次の図に示すように “Open Jupyter”をクリックします。
- 次の図に示すようなコンテンツが表示されます。
- “1_Data” をクリックし、”Load_Hist_Data_Daily.ipynb” をクリックします。
- ノートブックのすべてのステップを実行します。
以下の点に注意してください。
- ステップ 4 では、データプレビューが提供されます。
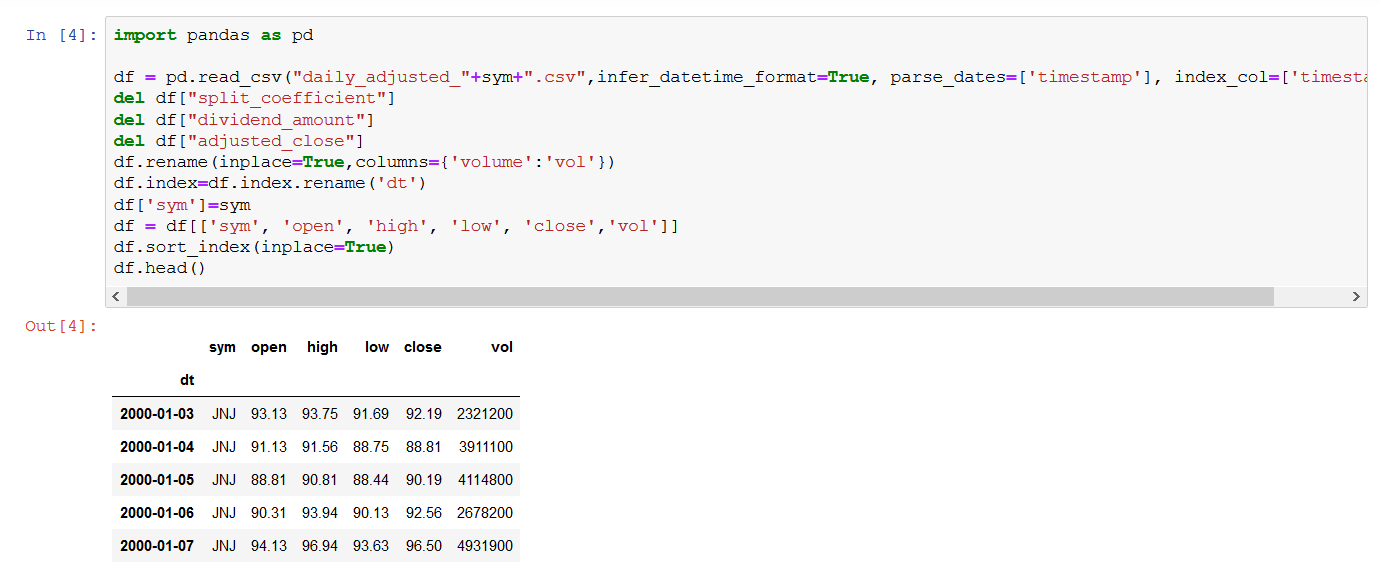
- ステップ 6 が完了すると、hist_data_daily フォルダが作成され、S3 バケットに投入されます。2. データを分析し、可視化する

ここでは、Amazon Athena を使用して、S3 バケットの hist_data_daily フォルダに保存されているデータをクエリします。
- Athena に移動し、トップメニューの “Workgroup:”をクリックし、”MyWorkGroup”、”Switch workgroup”、”Query Editor”、”+”記号をクリックして次のクエリを挿入し、”Run query” をクリックします。次の図に示すような結果が得られます。
- Select * from hist_data_daily limit 10

ここでは、Amazon QuickSight が JNJ データにアクセスできるようにアクセス許可を設定します。
これを行うには、Amazon QuickSight ユーザー ARN を使用する必要があります。
ここで示されているように、以下の AWS CLI コマンドを使用して Amazon QuickSight ユーザー ARN を取得できます。
aws quicksight list-users –aws-account-id 111122223333 –namespace
default –region egion us-east-1
where 111122223333 is your account-id
となります
代わりに、次のパターンを使用して、AWS CLI を使用せずに Amazon QuickSight ユーザー ARN を手動で構成することもできます。
arn:aws:quicksight:us-east-1:<AccountId>:user/<UserName>
where <AccountId> is your account-id and <UserName> is your user name
An example of Amazon QuickSight user arn is
arn:aws:quicksight:us-east-1:111122223333:user/default/DiegoColombatto
- AWS Lake Formation で “Grant” をクリックし、次に示すようにアクセス許可を設定してから、”Grant” をクリックします。
- “SAML and Amazon QuickSight users and groups” ボックスに Amazon QuickSight user arn を挿入します。

ここでは、Amazon QuickSight を使用してデータを可視化し、Amazon Athena をデータソースとして使用します。
- Amazon QuickSight にサブスクライブしていない場合は、 ここをクリックし 、手順に従ってサブスクライブします。本ブログ記事の目的に適うようにするには、サブスクリプションプロセスにおいて “Standard Edition” または “Enterprise Edition” のいずれかを選択してください。
- Amazon QuickSight にすでにログインしていて、別の Amazon QuickSight アカウントを使用するためにログアウトする場合は、画面の右上にあるユーザーアイコンをクリックし、”log out” をクリックします。その後、既に持っている別のアカウントでログインするか、前述のように新しいアカウントを作成してください。
- Amazon QuickSight リソースにアクセスします。”Amazon Athena” オプションをチェックし、”Next” をクリックし、”S3 buckets linked to QuickSight account” をクリックします。次に、AWS CloudFormation で作成された S3 バケットを選択し、”Write permission for Athena Workgroup” にチェックして “Finish” をクリックします。
- 以下の図に示すように、Amazon QuickSight dataset に移動し 、”Athena” をクリックして、データソースとして Athena を使用して新しいデータセットを作成します。”MyWorkGroup” ワークグループを選択し、”Validate Connection” をクリックして “Create data source”をクリックします。

- “Choose your table” ウィンドウで、”Use custom SQL”をクリックし、次のクエリを挿入します。
- SELECT cast(date_parse(dt,’%Y-%m-%d’) as date) as day, sym, open, close, high, low, vol FROM algo_data.hist_data_daily limit 1000
- “Confirm Query”、”Directly query your data”、”Visualize”の順にクリックします。
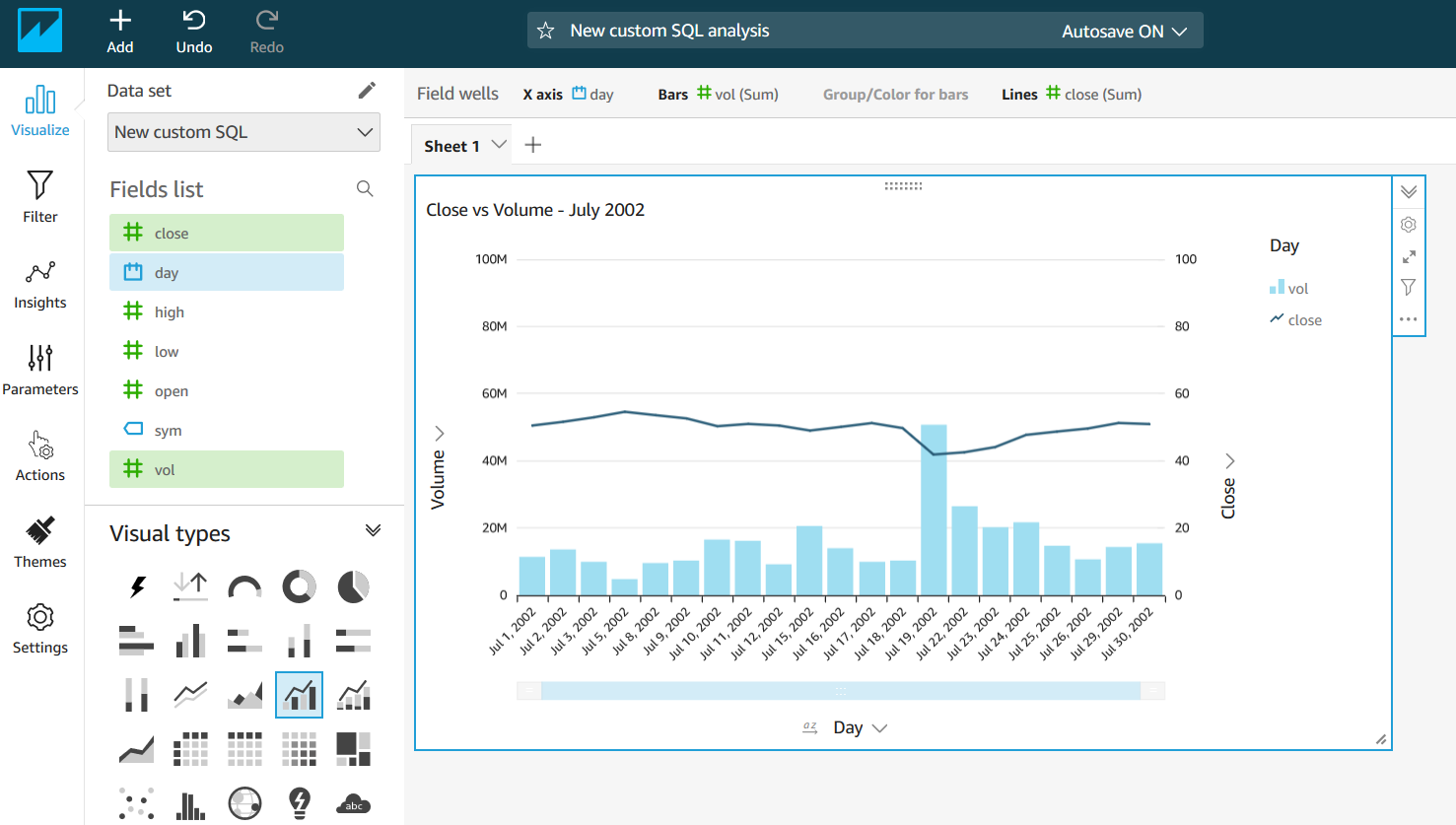
ここではグラフを作成するのに使用したいビジュアルタイプとフィールドを選択できます。以下の例では、”day”、”vol”、”close”の各フィールドを使用して”Clustered bar combo chart”を選択し、2002 年 7 月でフィルタリングしました。
3. 取引戦略のバックテスト
- ノートブックインスタンスに移動し、ステータスが”InService”であることを確認し、”Open Jupyter”をクリックします。
- “3_Models” をクリックし、”Train_Model_Forecast.ipynb” をクリックします。
すべてのコードセルを実行すると、ノートブックは最初にデータをローカルに準備してから、Amazon SageMaker 経由でモデルをリモートでトレーニングします(以下の図を参照)。
- 2_Strategies に移動し、Strategy_ML_Forecast を開きます。
- 1 から 8 までのすべてのコードセルを実行します。8 が完了すると、戦略の結果を示す以下のグラフが表示されます。ステップ 2 から 4 を変更して再実行することで、戦略を改善し、パフォーマンスを向上させることができます。ノートブックは、戦略を改善するためのヒントとリファレンスを提供します。
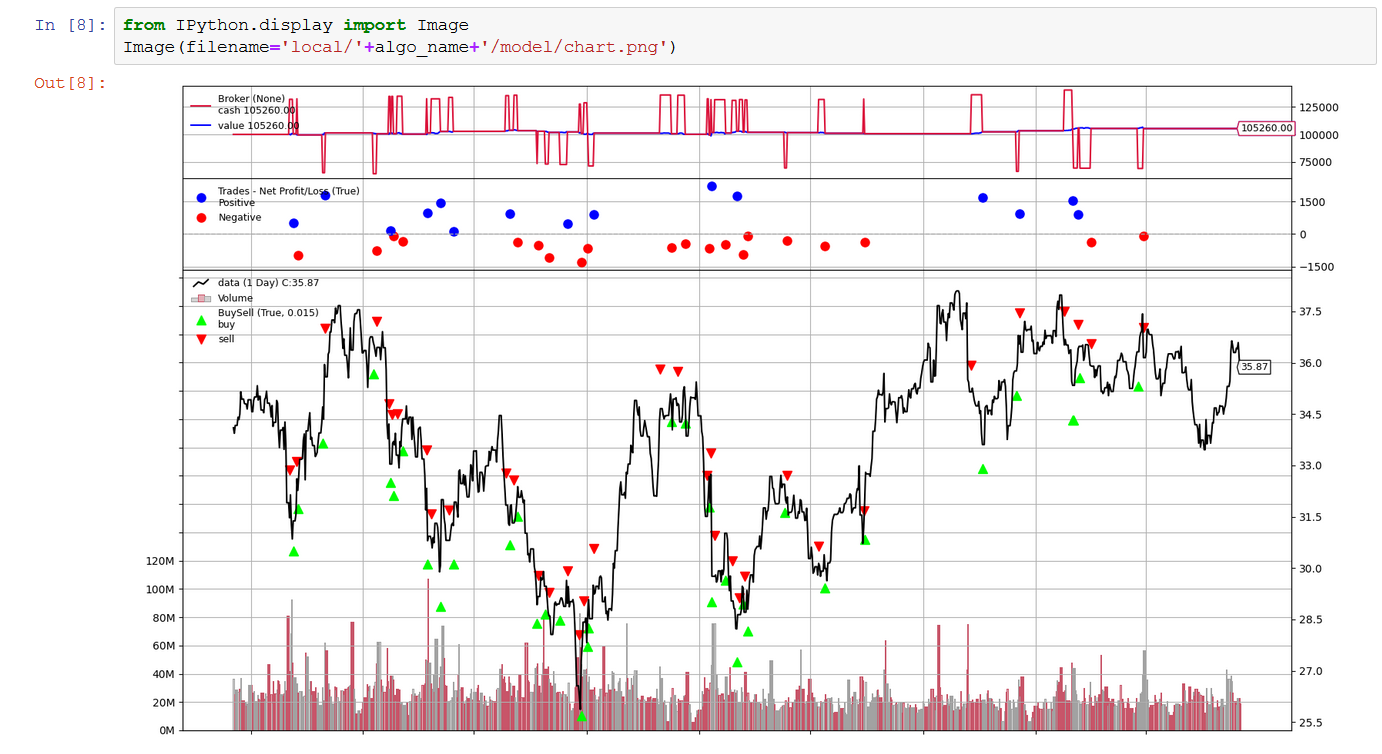
- 結果が要件と一致したら、9 から 12 までのコードセルに進むことができます。11 の出力は、PNL と Sharpe の比率を提供し、12 の出力は、コードセル 8 と同じチャートタイプを提供します。

使用したリソースのクリーンアップ
上記のステップでプロビジョニングされたリソースを削除するには、以下のステップに従ってください。
1) デプロイされた CloudFormation スタックを削除します :
- AWS CloudFormation に移動し 、ウィンドウの右上から “N. Virginia Region” リージョンを選択します。
- “algotrading” スタック を選択し、 Deleteを選択します。
- 削除の確認ウィンドウで、 Delete stack を選択します。
2) S3 バケットの削除 :
- S3 に移動し 、ステップ1 「環境を設定し、データにアクセスする」 で作成したバケットを選択します。
- バケットを空にします。 空にするには、バケット内のすべてのオブジェクトを選択して削除するか、 ここで説明されている空にする機能を使用できます。
- このページの説明に従って、バケットを削除します。
3) Amazon QuickSight のサブスクリプション解除
まとめ
本記事では、Amazon SageMaker ノートブックインスタンスを使用して、取引データを Amazon S3 にすばやく簡単にインポートする方法、Athena を使用してデータ分析を実行する方法、インポートされたデータに対する取引戦略をバックテストする方法について説明しました。
このアーキテクチャはモジュール式で、使用するデータとテストする取引戦略には依存しません。AWS Data Exchange を使用してさまざまなデータセットを取得でき、Jupyter ノートブックは必要に応じて更新したり、他のノートブックに置き換えたりできます。
冒頭で言及したように、私たちは、皆様が実装してほしい追加のユースケースや、機能に関するフィードバックを歓迎しています。このアーキテクチャに拡張機能が追加されるのを乞うご期待ください。
本記事は純粋に教育目的で書かれています。過去の取引パフォーマンスは、将来のパフォーマンスを保証するものではありません。
AWS Data Exchange でさらに多くのデータを見つけることも、 金融サービスデータを直接確認することもできます。Amazon SageMaker ノートブックのその他の例については、 SageMaker Examples の GitHub リポジトリを参照してください。

Diego Colombatto
Diego Colombatto は、AWS のシニアパートナーソリューションアーキテクトであり、エンタープライズ向けのデジタルトランスフォーメーションプロジェクトの設計とデリバリーにおいて 15 年以上の経験を有しています。AWS において、Diego はパートナーやお客様が AWS テクノロジーを理解して活用し、ビジネスニーズをソリューションに変えるための手助けをしています。彼が情熱を持って取り組んでいることの一つにIT アーキテクチャとアルゴリズム取引があり、いつでもこれらのトピックに関する会話を歓迎しています。

Balaji Gopalan
Balaji は、アマゾンウェブサービスのプリンシパルソリューションアーキテクトで、金融サービスのお客様が、安全性、運用効率、信頼性、パフォーマンス、費用対効果の高いアプリケーションをクラウド上に構築できるよう導いています。また、クラウド上のデータを活用して情報バリューチェーンを進める方法についてお客様に助言してきました。業界全体の EDM Council の Cloud Management Capabilities ワーキンググループのアクティブなメンバーとして、クラウドデータ管理のベストプラクティスの定義を支援しています。Balaji は 20 年以上にわたる資本市場の経験を持ち、バイサイド(クオンツヘッジファンドで)とセルサイド (Tier 1 投資銀行) の両方で働き、株式部門と債権部門全体の電子取引、アルゴリズム取引、時系列分析にフォーカスしてきました。Balaji は、イリノイ大学アーバナ・シャンペーン校のコンピュータサイエンスの修士号を保持し、また、マドラス大学の情報工学の学士号を保持しています。

Oliver Steffmann
Oliver Steffmann は、ニューヨークを拠点とする AWS のエンタープライズソリューションアーキテクトです。IT アーキテクト、ソフトウェア開発マネージャー、および国際金融機関の管理コンサルタントとして 18 年以上の経験を有しています。コンサルタントとして勤務していた際には、ビッグデータ、機械学習、クラウドテクノロジーに関する豊富な知識を活用して、顧客がデジタルトランスフォーメーションを開始できるよう支援しました。それ以前は、ニューヨークにあるTier 1 投資銀行で地方自治体取引技術の責任者であり、ドイツで自身のスタートアップ企業を設立しキャリアを開始しました。
翻訳はソリューションアーキテクトの澤野佳伸が担当しました。原文はこちらです。