AWS for Industries
Algorithmic Trading on AWS with Amazon SageMaker and AWS Data Exchange
It is well known that the majority of stock transactions are automated (as described here and here), for example using applications or “robots” implementing a trading strategy. More recently, an emerging trend in the financial services industry is the movement of trading solutions, such as algorithmic trading solutions, to the cloud (as described here and here).
The reasons for this movement are twofold: first, the advantages provided by the cloud; second, new ways to be close to data providers and stock exchanges.
First, one of the major benefits of the cloud is business agility, leveraging the ability to quickly and easily access technology and nearly continuous innovation provided by AWS services, coupled with a pay-as-you-go model, which allows you to experiment and “pilot” new technologies and solutions without relevant upfront investments. More specifically, there are different use cases and benefits for Capital Markets firms turning to AWS to extend their on-premises solutions to the cloud or to build cloud-native solutions.
Second, it is well known that financial firms often adopt co-location spaces to be closer to the exchanges. The more exchanges and data providers turn to the cloud (like Bloomberg, Goldman Sachs, iSTOX, Nasdaq, S&P), the more convenient it is for financial firms (i.e., data consumers) to turn as well to the cloud, in order to be nearer (in the cloud) to exchanges and data providers and leverage cloud benefits. This movement to the cloud is also key to obtaining low latencies, which in turn is of paramount importance for use cases like high-frequency trading.
This movement enables other use cases as well: one is hybrid cloud architecture, where cloud resources are used to meet demand spikes of compute power, e.g. running thousands of simulations or training machine learning models in a short timeframe; this scenario leverages both cloud benefits and existing co-location resources. Another is the quantitative analysts ability to benefit from Amazon Machine Learning and Analytics services for providing quality signals to traders.
In this blog, we briefly describe the high-level components of an algorithmic trading solution and then we focus on one specific use case, which is the back testing of trading strategies. In order to show you how easy and quick it is to get started with a trading solution on AWS, we also provide a “one-click” deployment and instructions to deploy and use a modular and extensible algorithmic trading solution on AWS.
This solution can later be changed and extended to match additional use cases, like the ones mentioned previously. We welcome feedback on the use cases you’d like to see covered.
High-level Components of an Algorithmic Trading Solution
At a high level, algorithmic trading solutions are composed as shown in the following image.
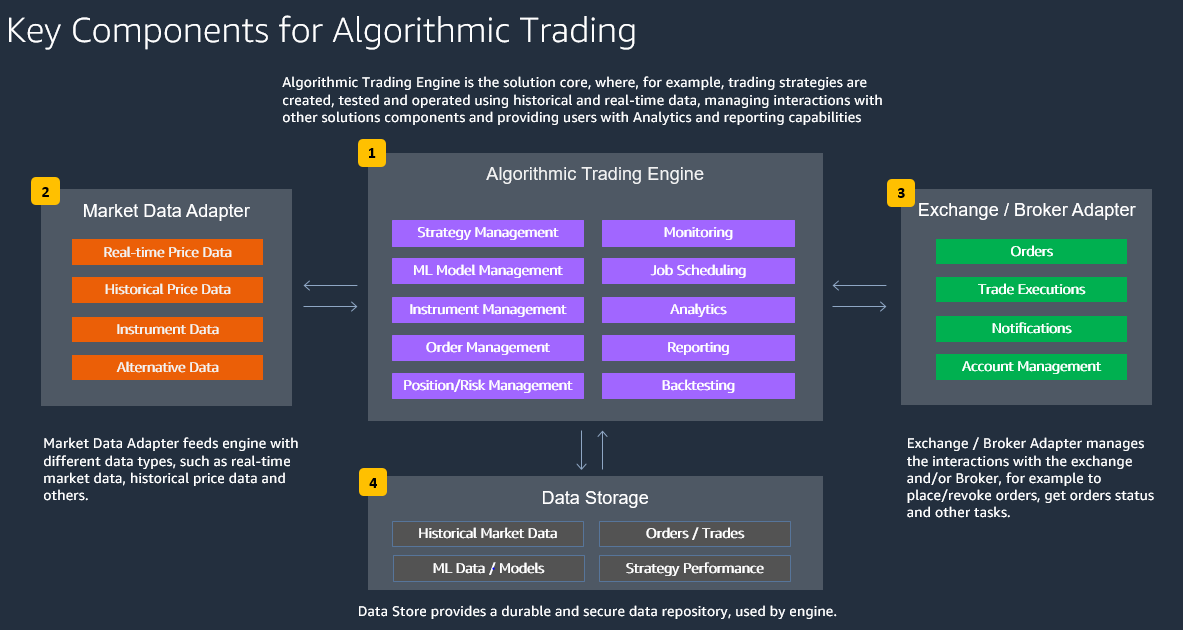
- Algorithmic Trading Engine is the solution core, where, for example, trading strategies are created, tested, and operated using historical and real-time data, managing interactions with other solutions components and providing users with analytics and reporting capabilities.
- Market Data Adapter feeds engine with different data types, such as real-time market data, historical price data, and others.
- Exchange / Broker Adapter manages the interactions with the exchange and/or Broker, for example to place/revoke orders, get orders status, and other tasks.
- Data Store provides a durable and secure data repository, used by algorithmic trading engine.
AWS provides a wide breadth of services that allows the creation of many different solutions, including specialized and vertical solutions, like algorithmic trading. In order to define the algorithmic trading solution architecture, the following evaluations are recommended:
- Speed of Trading
Depending on the speed of trading and the amount of data that needs to be processed, AWS products can vary for the individual components. For low frequency trading, Amazon EventBridge and AWS Lambda could be sufficient. For near-real-time trading, Amazon MSK and Amazon ECS might be required.
- Data and Analytics Needs
Especially for backtesting and machine learning based strategies, a scalable storage solution using Amazon Simple Storage Service (Amazon S3) is required that is integrated with AWS Glue, Amazon Athena, and Amazon QuickSight for analytics purposes. For operational data for orders/trades/ positions, a database engine like Amazon DynamoDB or Amazon Relational Database Service (Amazon RDS) can be used.
- Flexibility and Extensibility
To decouple all architecture components, an event-driven design is preferred that connects the algorithmic trading engine to market data adapters and to external exchanges/brokers through a standardized API.
- Shared Responsibility and Resiliency
In order to focus less on infrastructure management and to take advantage of built-in resiliency, an abstracted or managed AWS service is preferred over an AWS service running in Amazon Virtual Private Cloud (Amazon VPC), if this fits the overall requirements.
- Security
For authentication, authorization, encryption, and segregation of data, AWS solutions like AWS Identity and Access Management (IAM), AWS Key Management Service (AWS KMS), and AWS Lake Formation can be used. For highly sensitive trading strategies, customer managed keys are preferred for data encryption.
- Governance, Risk, and Compliance
Regulatory requirements (MiFID II, trade reporting), risk management requirements, and compliance requirements (electronic trading safe guards, book of records) will lead to further integrations of the algorithmic trading components with already existing systems that provide this functionality.
Depending on the preceding evaluations, different AWS services can be used to architect an algorithmic trading solution, tailored on specific needs.
In this post we’ll show you how to easily and quickly create and get started with an algorithmic trading solution for backtesting of trading strategies.
This solution is designed to be modular and extensible; this enables you to start using this solution and later change/extend it to adapt it to your needs. For example you can later:
- Change solutions components, such as changing input data, financial instrument(s) used, or trading strategies.
- Add additional components, such as Market Data Adapter and Broker Adapter, for example to send market orders to a broker.
A key role in this solution architecture is played by AWS Data Exchange and Amazon SageMaker:
- AWS Data Exchange makes it easy to find, subscribe to, and use third-party data in the cloud. AWS Data Exchange offers more than 1,000 data products available from more than 80 qualified data providers in AWS Marketplace. Qualified data providers include category-leading and up-and-coming brands such as Reuters, TransUnion, Virtusa, Pitney Bowes, TP ICAP, Vortexa, Enigma, TruFactor, ADP, Dun & Bradstreet, Compagnie Financière Tradition, Verisk, Crux Informatics, TSX Inc., and many more.
- Amazon SageMaker provides every developer and data scientist with the ability to build, train, and deploy machine learning models quickly. Amazon SageMaker provides all of the components used for machine learning in a single toolset so models get to production faster with much less effort and at lower cost.
The following image shows the architecture of a comprehensive algorithmic trading solution, which includes Market Data and Broker adapter as well.

The following is a description of the data flow implemented by the solution described in this blog, with possible changes and extensions that can be later applied:
1. EOD price data is retrieved from AWS Data Exchange and saved on S3 bucket; for the purposes of this blog historical data from Alpha Vantage will be used. Depending on the backtesting strategy to be tested, additional data can be used, both retrieved from AWS Data Exchange or from internal data sources (i.e. data already available, or produced, in-house). A focus on this step is provided in the following.
2. Data Catalog is defined in AWS Glue. Amazon Athena, using AWS Glue Data Catalog, queries data on S3 bucket directly. AWS CloudFormation template provided in this post will create AWS Glue Data Catalog automatically.
3. SageMaker notebook instance enables you to train the ML model using Jupyter notebook included in this architecture. Notebook used in this architecture reads data directly from S3 bucket. Notebook provided can be updated or replaced as required.
4. Once trained, the ML model is used for actual backtesting, leveraging data available on S3 bucket, and can be deployed when the results meet your requirements.
5-6. Market Data Adapter and Broker Adapter are deployed and operated as containers using AWS Fargate and Amazon Elastic Container Services (Amazon ECS). Amazon ECS is a fully managed container orchestration service and AWS Fargate enables you to run containerized applications on Amazon ECS removing the need to choose, provision and manage servers, including scaling and rightsizing cluster capacity. Market Data Adapter and Broker Adapter can be added to, but are not included into, the solution implemented in this blog. This is one of the possible extension to this architecture; let us know if you would like to see this in a future blog.
7. Trading Strategy, implemented by ML model created at point 4, is deployed on containers using AWS Fargate and Amazon Elastic Container Services (Amazon ECS)
In the referenced GitHub repository, there are some sample ML-based trading strategies, such as long/short prediction based on Multilayer Perceptron (Feedforward NN) and Proximal Policy Optimization (PPO) model with a layer-normalized LSTM perceptron network. More details on how these strategies are implemented and how they operate can be found directly on Jupyter Notebooks provided.
8. Once the strategy is deployed and interacting automatically with Broker/Market Data, functionalities like job scheduling, monitoring, alerting, and logging are required from an operational excellence standpoint. For example, near-real time alerts can be generated when PNL is breaching defined thresholds and alerts can be both sent to humans and used to trigger automated corrective actions.
Feeding Algorithmic Trading Engine with Data: Focus on AWS Data Exchange
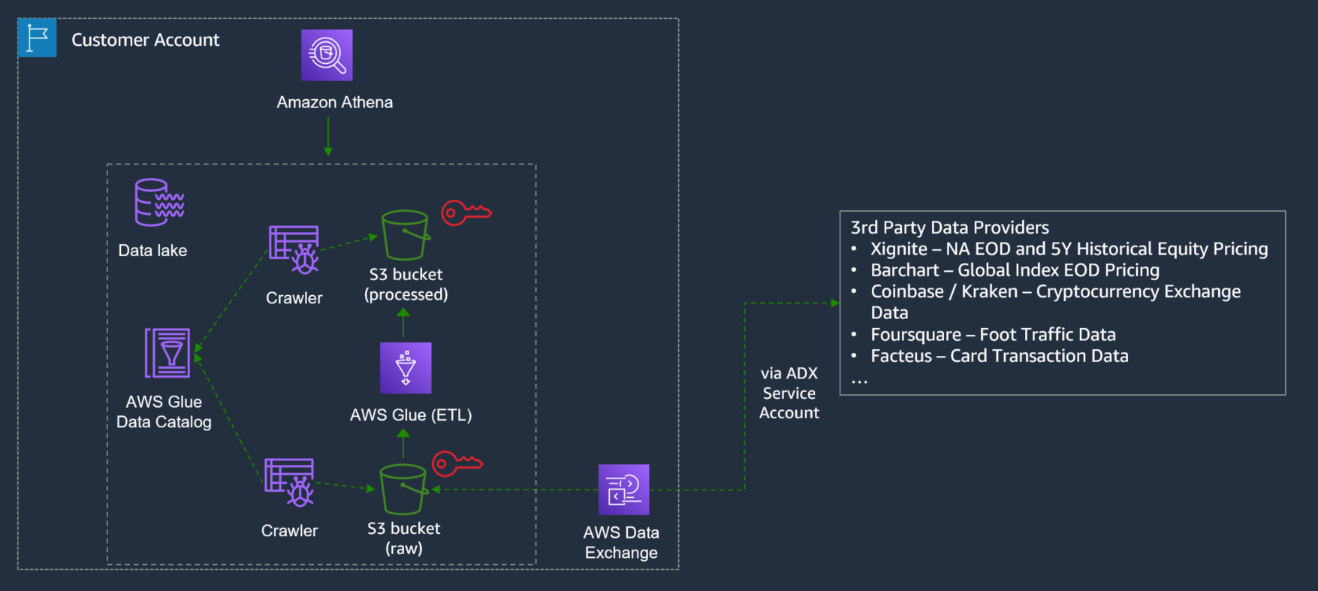
The preceding architecture is a possible extension to the architecture implemented in this blog and allows you to implement a seamless data flow from data source providers, available on AWS Data Exchange to algorithmic trading engine. The high-level data flow is as follows: you search and subscribe to the required data provider(s), available on AWS Data Exchange; data is saved on an S3 bucket of your choice.
An AWS Glue Crawler can crawl your data on Amazon S3 and, upon completion, can create one or more tables in AWS Glue Data Catalog.
Extract, transform, and load (ETL) jobs that you define in AWS Glue use these Data Catalog tables as sources and targets and allows you to transform the data as required to later run analytics and ML on transformed data.
Deployment and Usage Description
This blog walks you through the steps to set up the environment, retrieve, analyze, and visualize data and backtest trading strategies using a GitHub project. If you want to go directly to the GitHub project, you can use this link.
-
Set up environment and access data
- An AWS account is required to proceed, if you do not have an AWS account you can open a new one.
- Go to AWS CloudFormation, select N. Virginia Region at top right of the window, click on “Create stack” -> “With new resources (standard),” then select “Template is ready” and “Upload a template file.”
- Click here to get the template file to upload.
- Type “algotrading” as stack name and follow the wizard till the end.
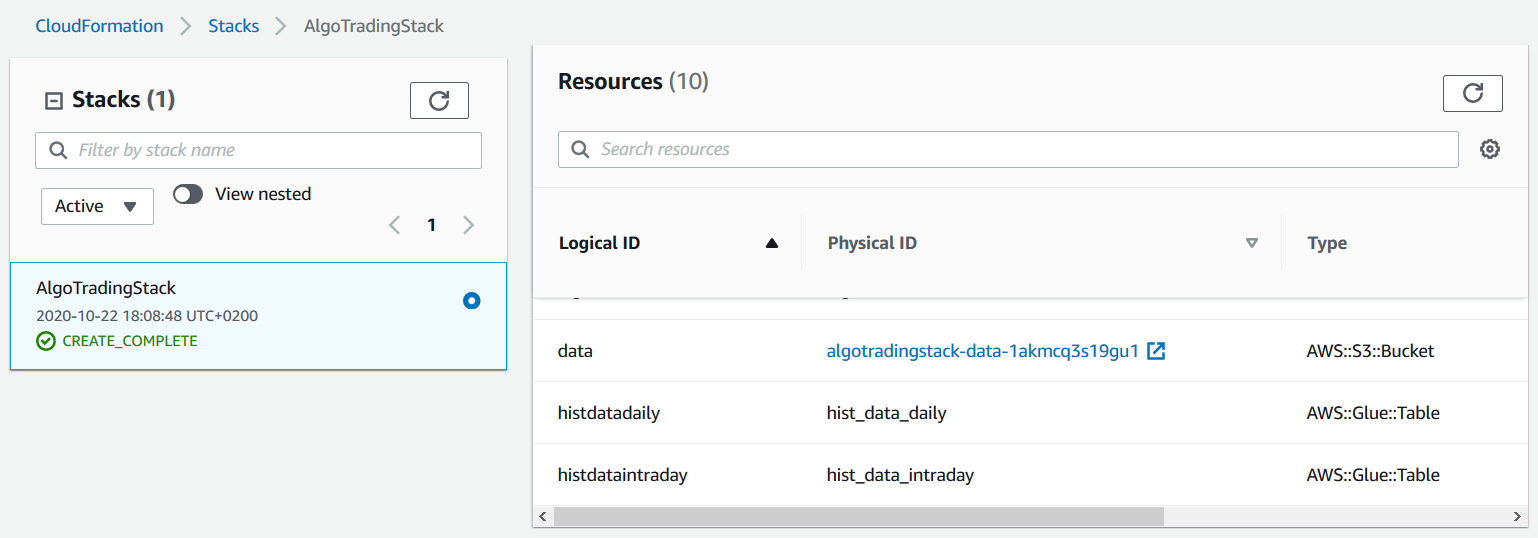
- Go to AWS CloudFormation resources tab and notice the S3 bucket name, as show in the following image. We’ll use this bucket in a moment to copy data from AWS Data Exchange.
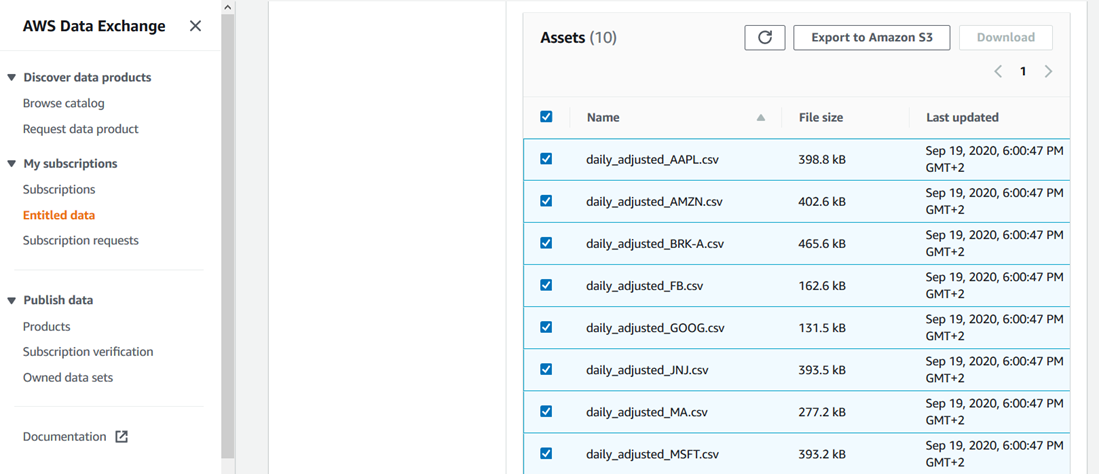
- Go to “20 Years of End-of-Day Stock Data for Top 10 US Companies by Market Cap” data product, from Alpha Vantage on AWS Data Exchange, and click on “Continue to Subscribe.”

- You can set Renewal Setting to NO, unless you want to activate automated renewal, then click on Subscribe.

- Once subscription is completed, select Ohio Region at top right of the window, go to Entitled data, select all the assets, click on “Export to Amazon S3,” select the previous bucket created and under “Encryption” select “Amazon S3-manager encryption key (SSE-S3).”
- Encryption is not strictly necessary to complete the deployment and can slightly increase processing time, but it’s recommended for security reasons. Click here for further information on the different options available to encrypt data stored on Amazon S3.
- Go to notebook instance, check that status is “InService” and then click on Open Jupyter, as shown in the following image.
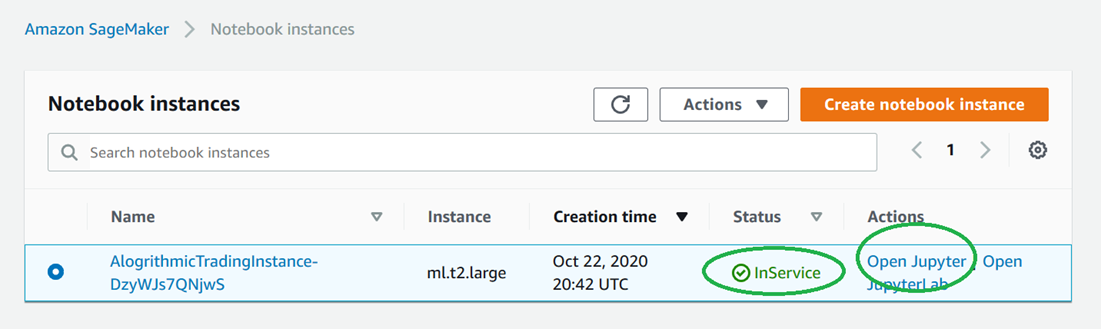
- You’ll see the content shown in the following image.
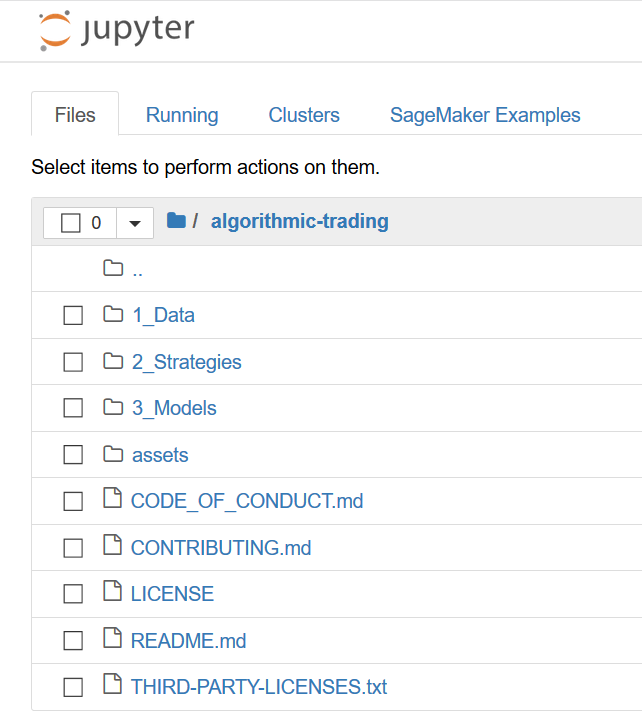
- Click on 1_Data and then click on Click on Load_Hist_Data_Daily.ipynb
- Run all the steps of the notebook.
Notice that:
- Step 4 will provide a data preview.
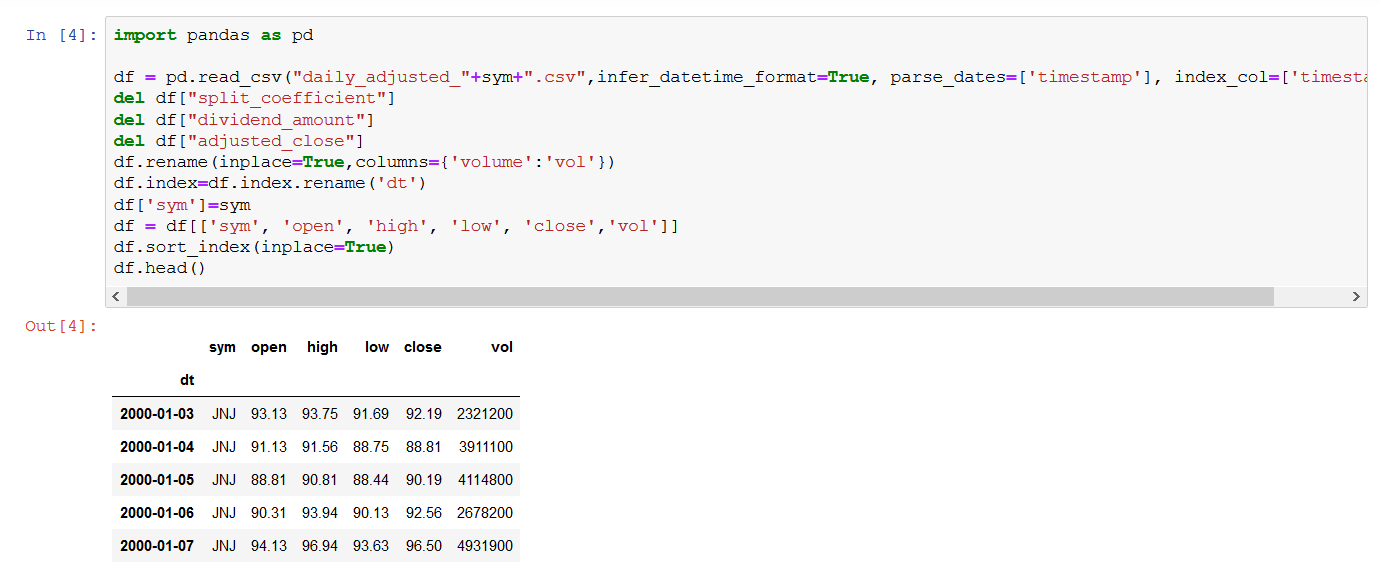
- When step 6 is completed, hist_data_daily folder will be created and populated into S3 bucket.

-
Analyze and visualize data
Now we’re going to query the data stored in hist_data_daily folder of your S3 bucket, using Amazon Athena.
- Go to Athena, click on “Workgroup : ” on the top menu, select “MyWorkGroup”, click on “Switch workgroup,” click on “Query Editor,” click on the “+” symbol, insert the following query and click on Run query. You’ll get results as shown in the following image.
- Select * from hist_data_daily limit 10

Now we’re going to configure permissions to allow Amazon QuickSight to access JNJ data.
To do this, we need to use the Amazon QuickSight user arn.
You can get Amazon QuickSight user arn using the following AWS CLI command, as shown here
aws quicksight list-users –aws-account-id 111122223333 –namespace
default –region egion us-east-1
where 111122223333 is your account-id
As an alternative, you can compose Amazon QuickSight user arn manually, without using AWS CLI, using the following pattern:
arn:aws:quicksight:us-east-1:<AccountId>:user/<UserName>
where <AccountId> is your account-id and <UserName> is your user name
An example of Amazon QuickSight user arn is
arn:aws:quicksight:us-east-1:111122223333:user/default/DiegoColombatto
- Go to AWS Lake Formation click on “Grant,” then configure the permissions as shown in the following and then click on “Grant”
- Insert Amazon QuickSight user arn into the box “SAML and Amazon QuickSight users and groups”

Now we’re going to use Amazon QuickSight to visualize the data, using Amazon Athena as a data source.
- If you’re not subscribed to Amazon QuickSight, click here and follow the procedure to subscribe. For the purposes of this blog, during the subscription process, you can either choose Standard or Enterprise Edition.
- If you’re already logged in Amazon QuickSight and you want to log out to use another Amazon QuickSight account, click the user icon at the top right of the screen and then click log out, then you can log in with another account you already have or you can create a new account as explained previously.
- Go to Amazon QuickSight resources. Check the option “Amazon Athena,” click “Next,” click on “S3 buckets linked to QuickSight account,” select the S3 bucket created with AWS CloudFormation, check “Write permission for Athena Workgroup” and click “Finish.”
- Go to Amazon QuickSight dataset and click on Athena to create a new dataset using Athena as data source, as shown in the following image. Select “MyWorkGroup” workgroup, click on “Validate Connection” and click on “Create data source.”

- On “Choose your table” window, click on “Use custom SQL” and insert this query:
- SELECT cast(date_parse(dt,’%Y-%m-%d’) as date) as day, sym, open, close, high, low, vol FROM algo_data.hist_data_daily limit 1000
- Click on “Confirm Query,” then on “Directly query your data,” and then on “Visualize.”
Now you can choose the visual types and the fields you prefer to compose your graph. In the following example, we selected “Clustered bar combo chart” using “day,” “vol,” and “close” fields, filtered on July 2002.
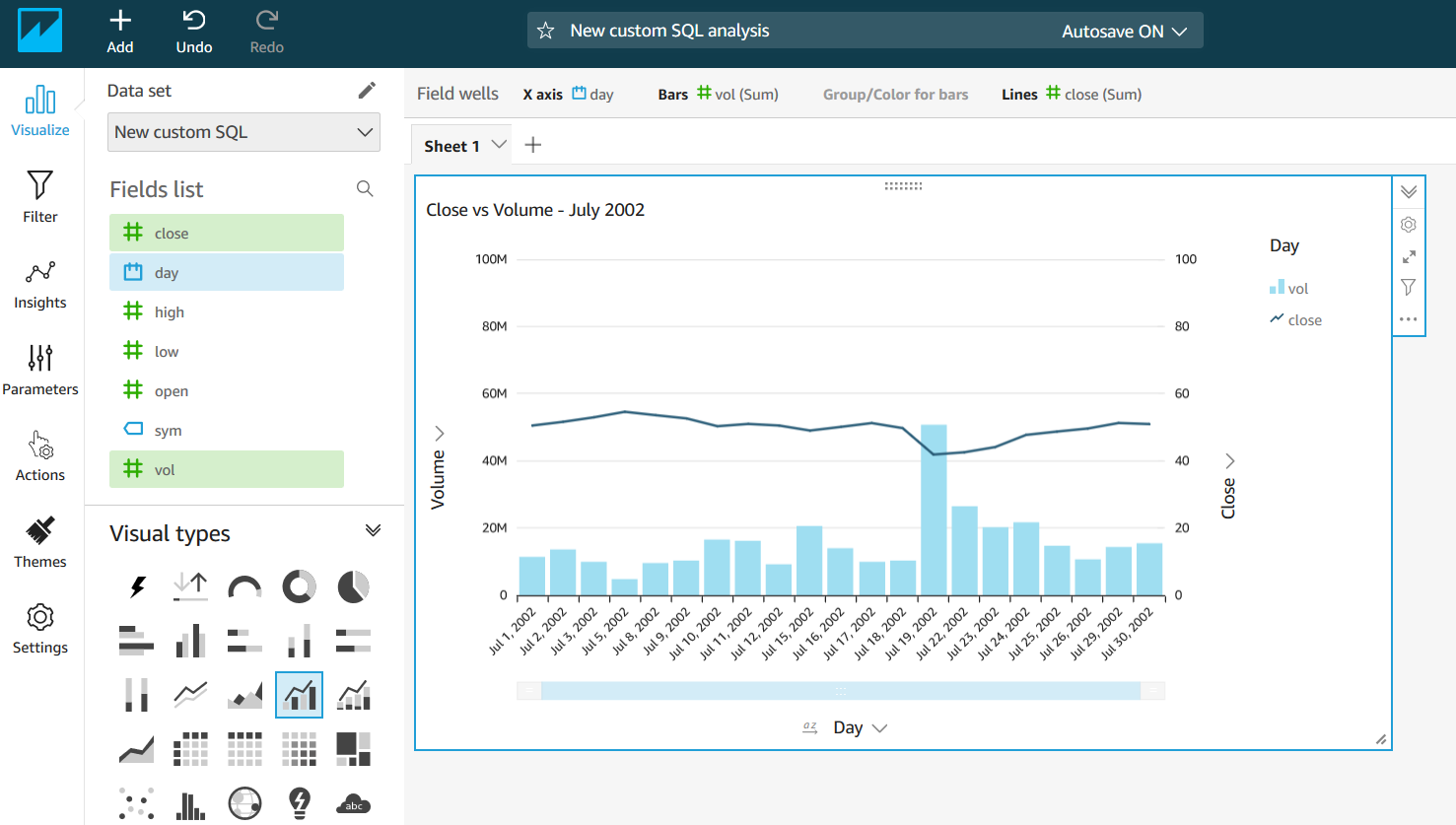
-
Backtesting trading strategies
- Go to notebook instance, check that status is “InService” and then click on Open Jupyter.
- Click on 3_Models and then click on Train_Model_Forecast.ipynb
- Run all of the code cells, the notebook prepares the data locally first and then trains the model remotely via Amazon SageMaker, as shown in the following image.
- Go to 2_Strategies and open Strategy_ML_Forecast
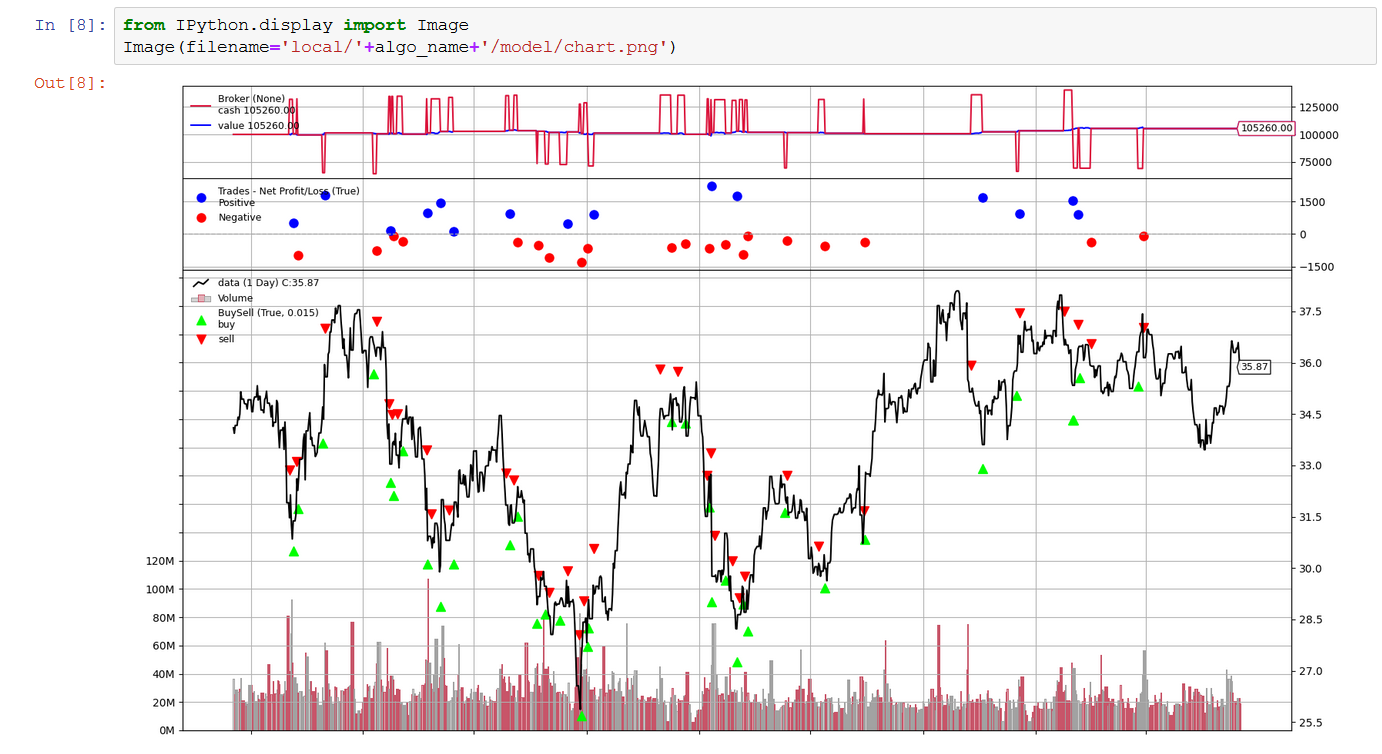
- Run all the code cells from 1 to 8. When 8 is completed, you’ll get the following chart, showing the results of your strategy. You can change and rerun steps from 2 to 4 to improve refine your strategy and improve the performance. Notebook provides some hints and references to improve your strategy.
- When the results match your requirement, you can proceed with code cells from 9 till 12. Output of 11 will provide PNL and Sharpe ratio and output of 12 will provide you the same chart type of code cell 8.

Clean up resources used
To remove the resources provisioned in the steps above, in order not to incur further charges, please follow these steps below.
1) Delete CloudFormation stack deployed:
- Go to AWS CloudFormation and select N. Virginia Region at top right of the window
- Choose “algotrading” stack and choose Delete.
- Choose Delete stack in the delete confirmation window.
2) Delete S3 bucket:
- Go to S3 and select the bucket created during step “1 Set -up environment and access data”
- Empty the bucket: you can do it by selecting and deleting all the object inside the bucket or you can use the empty functionality described here
- Delete the bucket, as described on this page
3) Unsubscribe from Amazon QuickSight
Conclusion
In this post, we’ve seen how to quickly and easily import trading data to Amazon S3, run data analysis using Athena, and backtest trading strategies on the imported data, using Amazon SageMaker notebook instance.
This architecture is modular and agnostic to data used and trading strategy tested: AWS Data Exchange can be used to get different datasets and the Jupyter notebook can be updated, or replaced with other notebooks, as required.
As mentioned in the introduction, we welcome your feedback on additional use cases and capabilities you’d like to see implemented and look out for additional extensions to this architecture.
This post is for educational purposes only. Past trading performance does not guarantee future performance.
You can find more data on AWS Data Exchange or you can look directly into Financial Services Data. You can find more example of Amazon SageMaker notebooks on SageMaker Examples GitHub repo.