Amazon Web Services ブログ
ブロックストレージとしての Amazon FSx for NetApp ONTAP
本ブログは、NetApp Japan が主催する Amazon FSx for NetApp ONTAP Advent Calendar 2025 の 19 日目の記事です。
皆様は Amazon FSx シリーズと聞くと、ファイルストレージサービスを想起するのではないでしょうか?私もそんな一人です。しかし、FSx シリーズの 1 つである Amazon FSx for NetApp ONTAP (FSx for ONTAP) はブロックストレージとしても利用できます。
FSx for ONTAP は高性能なブロックストレージであるとともに、マルチ AZ やマルチリージョンの構成を容易に実現できます。本ブログでは FSx for ONTAP について振り返りながら、FSx for ONTAP のブロックストレージとしての特徴を確かめてみたいと思います。
FSx for ONTAP の特徴
利用できるプロトコル
FSx for ONTAP では、第 1 世代のファイルシステムと第 2 世代のファイルシステムがあります。後者については、こちらのブログを参照してください。

図 1: 利用できるプロトコル
そのほか、Amazon S3 Access Point を利用した、HTTPS アクセスも東京と大阪リージョンの FSx for ONTAP でご利用いただけます。NetApp Japan の小寺さんが作成した本アドベントカレンダーのブログもご参照ください。
マルチ AZ とマルチリージョン
FSx for ONTAP は、シングル AZ 構成でもマルチ AZ 構成でも同様に 2 台のファイルシステムから成る冗長構成を採用しています。また、どちらの構成においても NFS や SMB で指定する接続先の IP アドレスは、フェイルオーバーの前後で変わりません。一方で、iSCSI や NVMe-over-TCP アクセス先の IP アドレスは ENI ごとに存在します。そのため、FSx for ONTAP でフェイルオーバーが発生した場合には、クライアント側で接続先のパスを切り替える必要があります。
なお、ENI が存在する VPC 外部からマルチ AZ 構成の FSx for ONTAP へと NFS や SMB でアクセスする場合、AWS Transit Gateway が必要となります。詳しくはこちらのリンクをご参照ください。
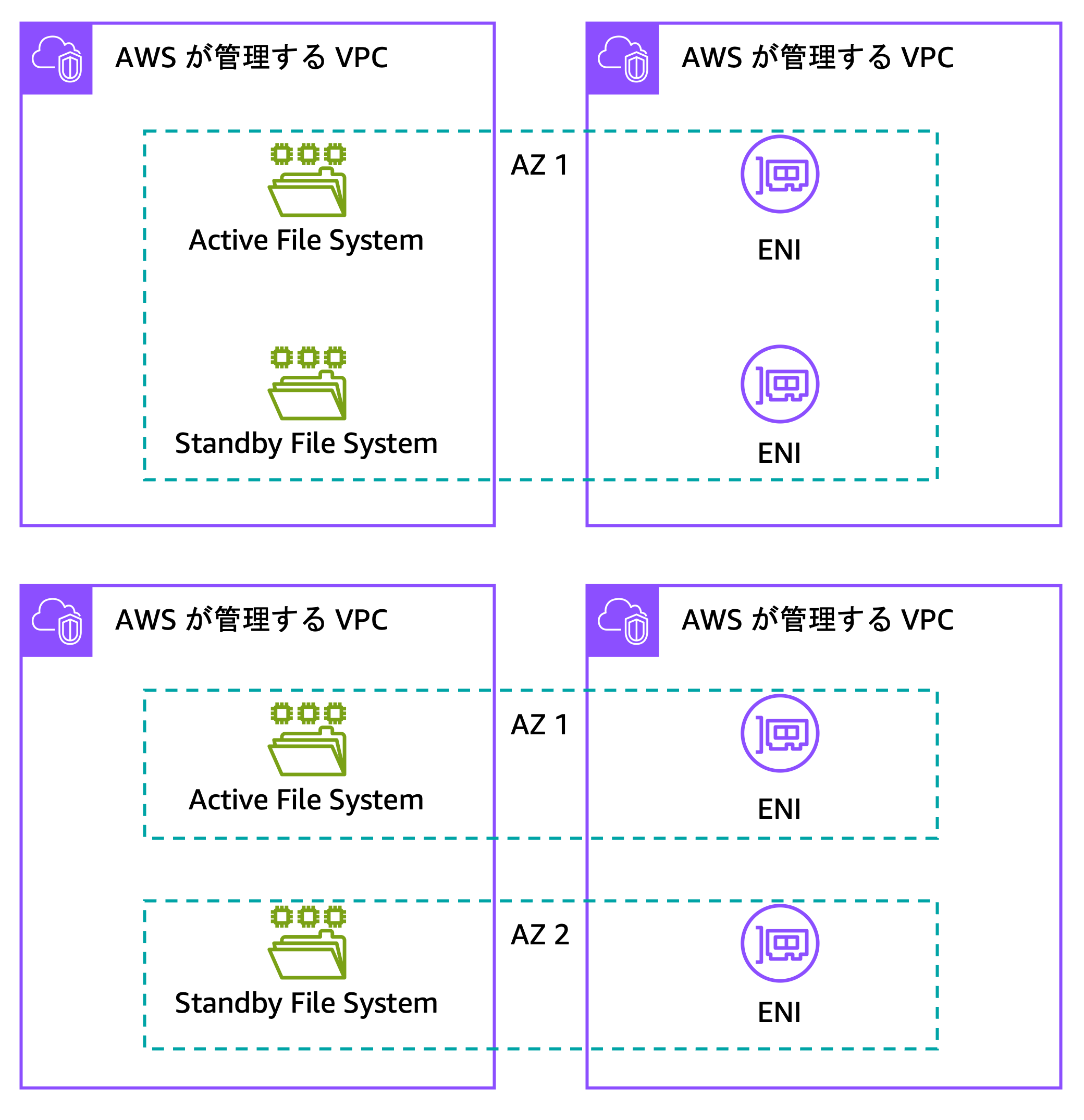
図 2 FSx for ONTAP の構成。上がシングル AZ、下がマルチ AZ。
マルチリージョン構成を採用する場合、SnapMirror を活用できます。SnapMirror を用いると、プライマリリージョンにある FSx for ONTAP のストレージボリュームからセカンダリリージョンのストレージボリュームへと、スナップショット単位でデータをレプリケーションすることができます。災害復旧やバックアップ、データ保護の目的で広く活用されており、ビジネス継続性の確保に重要な役割を果たします。初回は全データをコピーし、その後は差分のみを転送することで、ネットワーク帯域の効率的な利用を実現しています。
ストレージ容量の効率化
FSx for ONTAP は、次の 3 つの方法で、データ容量を効率化します。マネジメントコンソールでボリュームを作成する際に、一括で設定することができます。
- 重複排除
- 圧縮
- コンパクション

図 3 マネジメントコンソール上でのストレージ容量の効率化設定
ストレージの階層化
FSx for ONTAP ではアクセス頻度に応じて、ブロック単位でパフォーマンス重視の SSD ストレージ階層から低コストのキャパシティプール層へとデータを移動します。
FSx for ONTAP でブロックストレージを構成
今回は東京リージョンにシングル AZ の FSx for ONTAP を構築し、同じ VPC 内の Amazon EC2 から NVMe-over-TCP でアクセスします。NVMe-over-TCP は第 2 世代のファイルシステムのみ利用可能ですので、マネジメントコンソールでは「シングル AZ 2」を選択します。
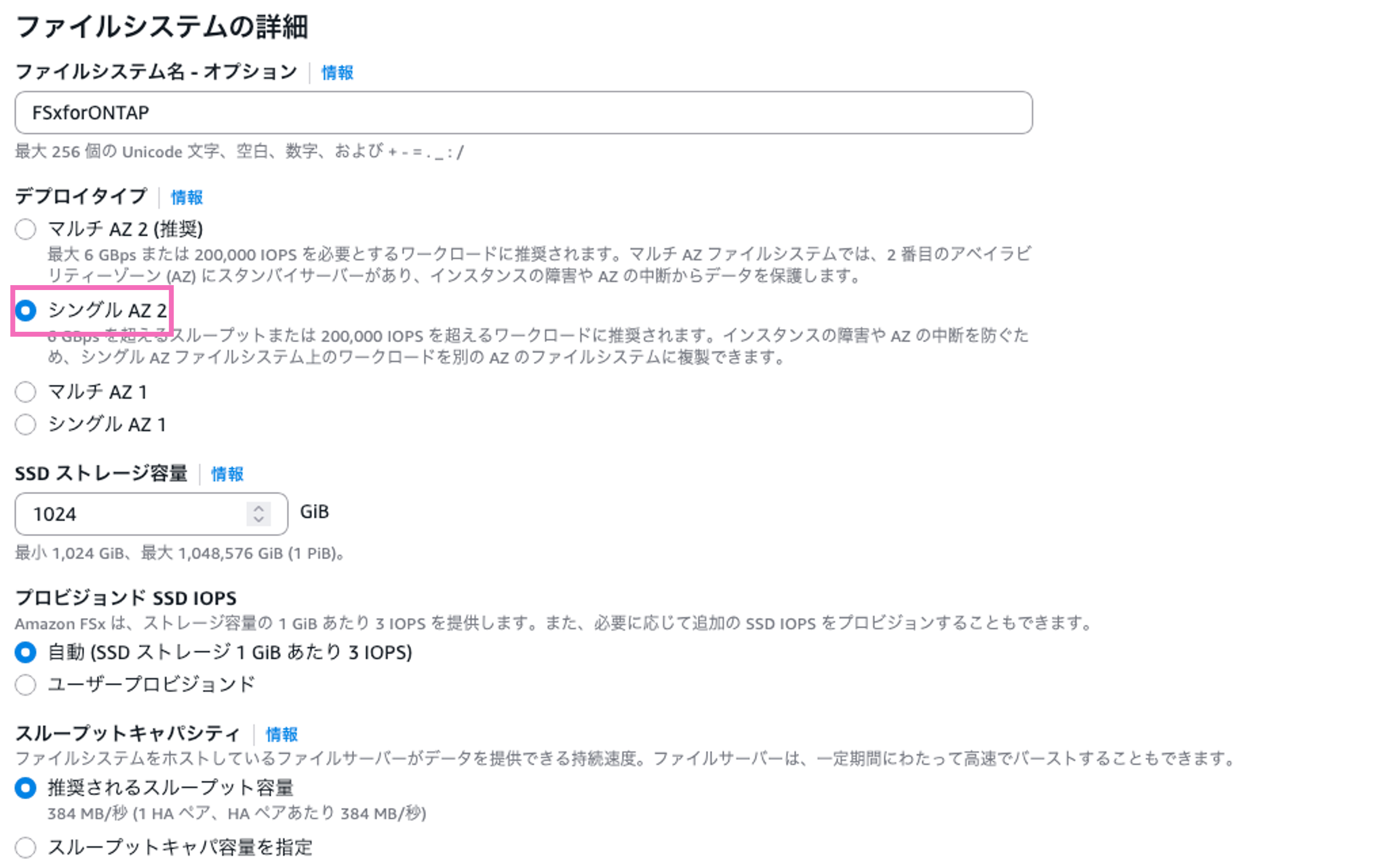
図 4 マネジメントコンソール上での設定
ファイルシステムが作成されたら、FSx for ONTAP のファイルシステムへと接続し、NVMe-over-TCP プロトコルを用いて、Amazon EC2 からマウントします。詳細な手順はこちらのドキュメントに従います。なお、FSx for ONTAP 側での準備が完了すると、次の図のように NVMe-over-TCP に対応したネットワークインタフェースが 2 つ表示されます。これらの IP アドレスは、ストレージ仮想マシン(SVM)の iSCSI IP アドレスに対応しています。
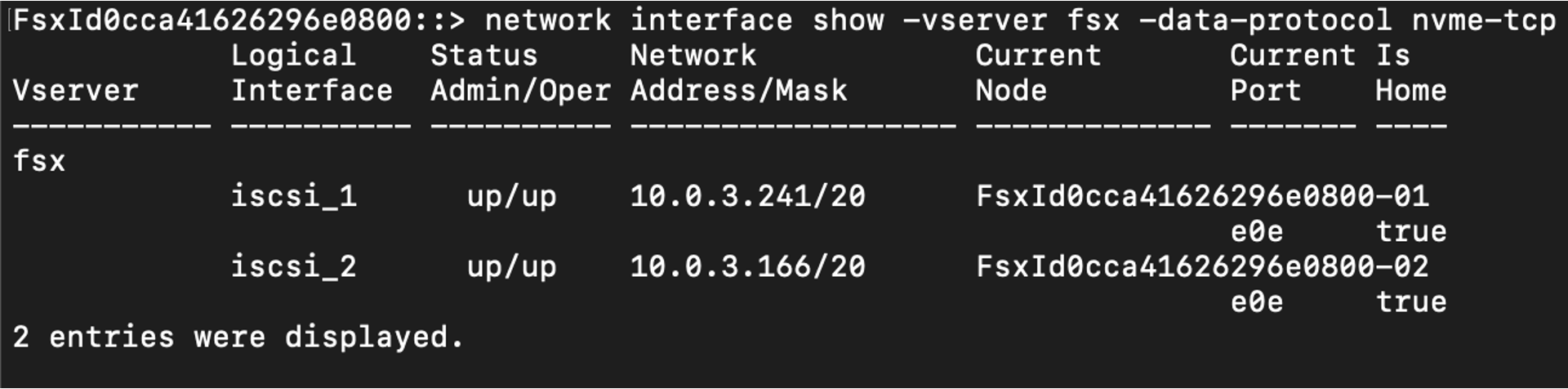
図 5 FSx for ONTAP において、NVMe-over-TCP プロトコルを使用するネットワークインターフェース
第 2 世代のFSx for ONTAP では、スループットと IOPS はそれぞれ 6 GBps と 200,000 IOPS まで設定することができ、高いパフォーマンスが必要なワークロードにも利用できます。スループットと IOPS 以外にも、細かいファイル操作が必要なワークロードではレイテンシが重要となるケースがあります。そこで、本ブログではレイテンシを fio というツールを用いて検証してみました。
今回は単純なコマンドのみ実行します。書き込みブロックサイズは 4 KB または 16 KB とします。1 GB のファイルを、ランダムリードとランダムライトで処理を行った時のレイテンシを測定します。なお、今回はレイテンシの測定が目的なため、ジョブの並列度は 1 としました。4 KB のブロックサイズで 1 GB のファイルをランダムリードしたときのサンプルコマンドを記載します。
fio --name=test --ioengine=libaio --rw=randread --bs=4k --direct=1 --size=1G --numjobs=1 --runtime=60 --group_reporting --filename=/fsx/ontap/example1.datまた、本ブログでは性能の検証が目的ではないので厳密な議論は行いませんが、レイテンシが低いことが分かります。
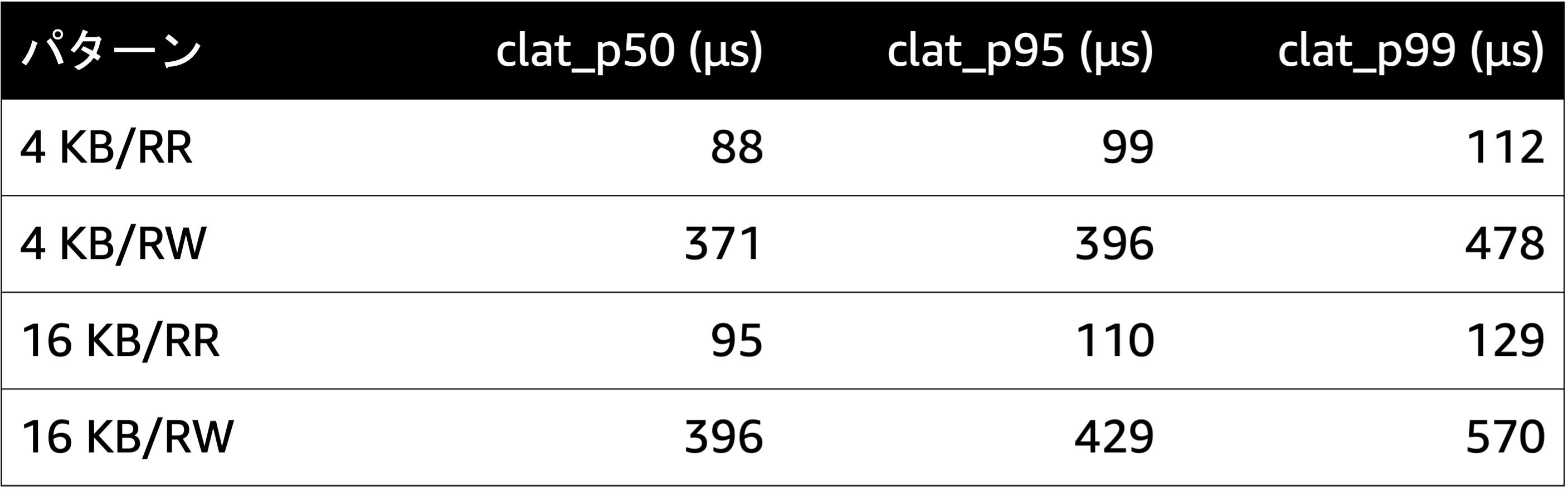
図 6 レイテンシの測定結果。RR、RW はそれぞれランダムリード、ランダムライトの略。clat_p50/clat_p95/clat_p99 はそれぞれ、Completion Latency における 50/95/99 パーセンタイル。
マルチリージョン構成
東京リージョンと大阪リージョンでシステム構成を統一する場合には、iSCSI を用いたブロックアクセスも有効です。iSCSI の設定方法はこちらをご覧ください。
まずは東京リージョンで作成したボリュームに対して、iSCSI でクライアントからアクセスします。そして、iSCSI でブロックアクセスしたボリューム上に、「Hello world!」と記載した hello.txt を作成します。このファイルは後ほど大阪リージョンのボリュームへと転送し、大阪リージョンのクライアントからアクセスできることを確認します。
次に、東京リージョンの FSx for ONTAP のボリュームから、大阪リージョンの FSx for ONTAP のボリュームへと SnapMirror でデータをレプリケーションします。
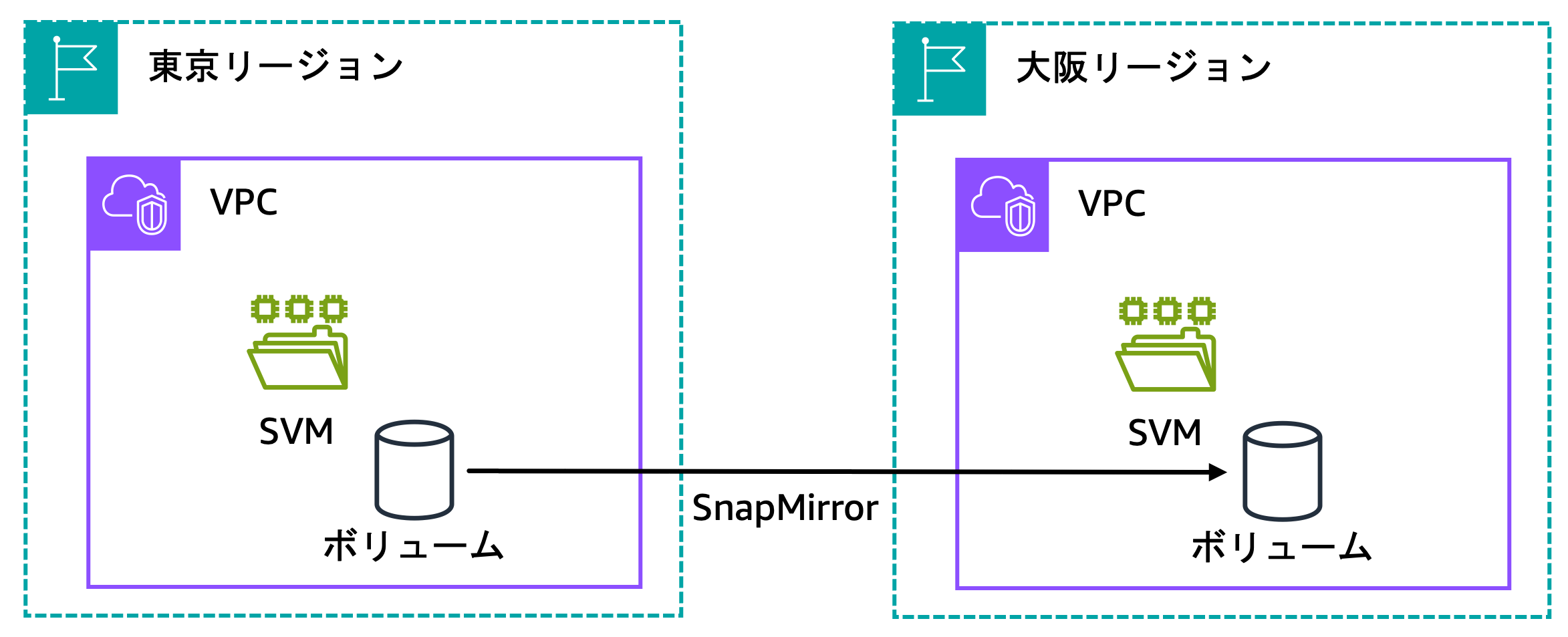
図 7 マルチリージョン構成
SnapMirror を転送する流れは、次の通りです。詳細はこちらのドキュメントを参照してください。
- 送信元と送信先の FSx for ONTAP のファイルシステム間でピアリング関係を構築
- 送信元と送信先の SVM 間でピアリング関係を構築
- SnapMirror 関係を構築
- SnapMirror でデータをレプリケーション
SnapMirror で全てのデータの転送が完了した後、snapshot show コマンドを実行すると、大阪リージョンのファイルシステムに「snapmirror」というスナップショットが転送されていることが分かります。これは東京リージョンのファイルシステムから転送されたスナップショットで、上記の「hello.txt」を含んでいるはずです。

図 8 スナップショットの確認
この後、SnapMirror 関係を停止します。そして、大阪リージョンの FSx for ONTAP のボリュームに対して、iSCSI でクライアントからマウントすることで、ボリューム中のファイルへとアクセスすることができます。例えば、東京リージョンの FSx for ONTAP のボリュームに作成した hello.txt ファイルは大阪リージョンのボリュームへも転送され、下図のようにアクセスすることができます。

図 9 大阪リージョンのボリューム中のファイルへとアクセス
FSx for ONTAP は、SnapMirror によってネイティブにマルチリージョンレプリケーションを実現できます。これにより、通常の AWS ブロックストレージで必要な AWS Elastic Disaster Recovery やアプリケーション層での実装が不要となり、シンプルな構成でリージョン間レプリケーションが可能です。
まとめ
FSx for ONTAP はファイルストレージだけでなく、ブロックストレージとしても活用することができます。NVMe-over-TCP を利用することで、低レイテンシかつ高い可用性が要求されるシステムにも対応することができます。また、東京リージョンと大阪リージョンで同様の構成を採用したい場合には、iSCSI をプロトコルに採用した上で、SnapMirror によるレプリケーションで実現できます。
本ブログが皆様のお役に立てれば幸いです。