Amazon Web Services ブログ
Amazon ES、Amazon Athena、および Amazon QuickSight を使用して AWS WAF ログを分析する
これで AWS WAF に、サービスによって検査されたすべてのウェブリクエストをログに記録する機能が追加されました。AWS WAF は同じリージョンの Amazon S3 バケットにこれらのログを保存できますが、ほとんどのお客様は、アプリケーションをデプロイする場合はいつでも、複数のリージョンにわたって AWS WAF をデプロイします。ウェブアプリケーションのセキュリティを分析するとき、組織はデプロイされたすべての AWS WAF リージョンにわたって全体像を把握する能力を必要とします。
この記事では、AWS WAF ログを中央データレイクリポジトリに集約するための簡単なアプローチを紹介します。これにより、チームは組織のセキュリティ体制をよりよく分析し、理解することができます。 リージョンの AWS WAF ログを専用の S3 バケットに集約する手順を説明します。ログデータを視覚化するために Amazon ES をどのように使用することができるかを実演することによってこれをフォローアップします。 また、AWS Glue ETL を使用して履歴データをオフロードして処理するためのオプションも提示します。データが 1 か所に収集されたところで、Amazon Athena および Amazon QuickSight を使用して履歴データをクエリし、ビジネス上の洞察を抽出する方法を最後に示します。
アーキテクチャの概要
この記事では、クライアント IP アドレスによる分散サービス拒否 (DDoS) 攻撃を識別するための AWS WAF アクセスログをフォレンジックに使用するケースに焦点を当てます。このソリューションにより、セキュリティチームは、インフラストラクチャ内のすべての AWS WAF にヒットしたすべての受信リクエストのビューが得られます。
IP アクセスパターンが時間の経過とともにどのように見えるのかを調べ、短期間にどの IP アドレスがサイトに複数回アクセスしているのかを評価します。このパターンは、IP アドレスが攻撃者になる可能性があることを示唆しています。 このソリューションを使用すると、単一のアプリケーションに対する DDoS 攻撃者を特定し、お客様の世界中の IT インフラストラクチャ全体で DDoS パターンを検出できます。

チュートリアル
このソリューションでは、一元化されたリポジトリでログファイルの受信を開始することを可能にするアーキテクチャ設定と、ログデータを有用な結果に処理する分析のために別々のタスクが必要です。
前提条件
この記事の手順に従うには、以下のリソースが必要です。
- 2 つの AWS アカウント。 AWS のマルチアカウントのベストプラクティスに従って、以下の 2 つのアカウントを作成します。
- ロギングアカウント
- AWS WAF を使用してウェブアプリケーションをホストするリソースアカウント。マルチアカウント設定の詳細については、「AWS Landing Zone」を参照してください。複数のアカウントを使用すると、ログがリソース環境から分離されます。これにより、ログファイルの整合性が維持され、すべてのアプリケーション、ネットワーク、およびセキュリティログを監査するための中央アクセスポイントが提供されます。
- アカウントに新しいリソースを投入する能力。 リソースは、無料利用枠の使用に適格ではない可能性があるため、コストが発生する可能性があります。
- できれば複数のリージョンで、Application Load Balancer で実行されているアプリケーション。まだ持っていない場合は、AWS ウェブアプリケーション参照アーキテクチャを起動してこのソリューションをテストし実装することができます。
このチュートリアルでは、ecs-refarch-cloudformation GitHub リポジトリから Amazon ECS のサンプルを起動できます。 これは、Application Load Balancer を使用して ウェブアプリケーションを自動的にセットアップする「ワンクリックでデプロイする」サンプルです。これを 2 つの異なるリージョンで起動して、グローバルなインフラストラクチャをシミュレートします。最終的に両方のリージョンがログ記録する集中型のバケットを設定してから、フォレンジック分析ツールがそこから引き出します。選択したリージョンでサンプルアプリケーションを起動するには、[Launch Stack] を選択します。
セットアップ
アーキテクチャ設定により、一元化されたリポジトリでログファイルの受信を開始できます。
ステップ 1: 権限を与える
このプロセスは、あるアカウントに別のアカウントのリソースにアクセスするための適切な権限を付与して開始します。リソースアカウントには、ロギングアカウントのバケットにアクセスするためのクロスアカウント権限が必要です。
- ロギングアカウントで中央ロギング S3 バケットを作成し、権限の下に次のバケットポリシーをアタッチします。その際、バケットの ARN を書き留めてください。今後のステップでこの情報が必要になります。
- アカウントの実際の値に基づいて、RESOURCE-ACCOUNT-ID および CENTRAL-LOGGING-BUCKET-ARN を正しい値に変更します。
ステップ 2: Lambda の権限を管理する
次に、リソースアカウントで作成した Lambda 関数には、その場所にファイルを書き込むことができるように、中央ロギングアカウントの S3 バケットにアクセスするための権限が必要です。前の手順で既に基本的なクロスアカウントアクセスを提供していましたが、Lambda には依然としてリソースレベルで細かい権限が必要です。 AWS WAF で監視する予定のアプリケーションを起動した両方のリージョンで、これらの権限を忘れずに付与してください。
- リソースアカウントにログインします。
- Lambda 関数の IAM ロールを作成するには、Lambda コンソールで [ポリシー]、[ポリシーの作成] を選択します。
- [JSON] を選択して、以下のポリシードキュメントを入力します。このチュートリアルで使用しているバケットの相対 ARN で YOUR-SOURCE-BUCKET と YOUR-DESTINATION-BUCKET を置き換えます。
- [ポリシーの確認] を選択し、ポリシー名を入力して保存します。
- 作成したポリシーで、Lambda 関数用の新しいロールを作成し、そのロールにカスタムポリシーをアタッチします。これを行うには、IAM ダッシュボードに戻ります。
- ロールを使用するサービスとして [ロールの作成] を選択し、[Lambda] をクリックします。このステップの前半で作成したカスタムポリシーを選択して、[次へ] を選択します。必要に応じてタグを追加してから、この新しいロールに名前を付けて作成することができます。
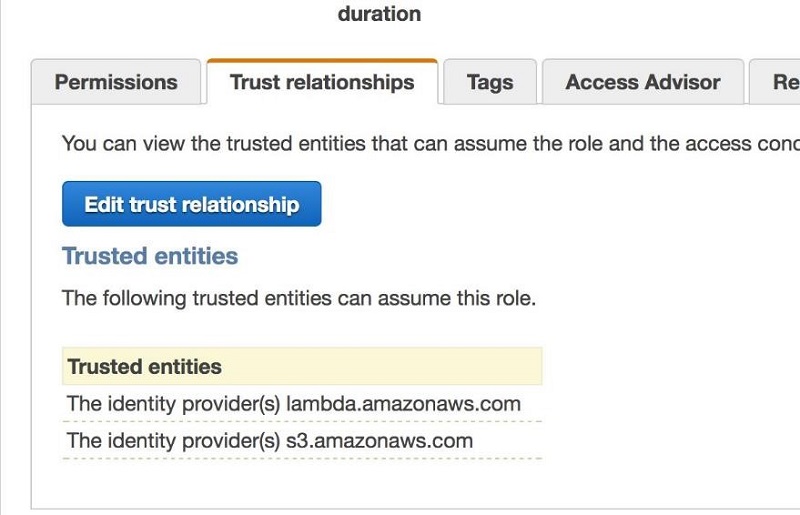
- ロールの信頼関係セクションにも、信頼できるエンティティとして S3 を追加する必要があります。次の例に示すように、[信頼関係の編集] を選択し、amazonaws.com をポリシーに追加します。

次のスクリーンショットに示すように、Lambda と S3 は [信頼関係] タブの下に信頼できるエンティティとして表示されます。
ステップ 3: Lambda 関数を作成してログファイルをコピーする
リソースアカウントの S3 バケットと同じリージョンに Lambda 関数を作成します。この関数は、リソースアカウントのバケットからログファイルを読み取り、その内容をロギングアカウントのバケットにコピーします。AWS WAF で監視する予定のアプリケーションを起動したすべてのリージョンに対してこの手順を繰り返します。
- リソースアカウントにログインします。
- コンソールで Lambda に移動して、[関数の作成] を選択します。
- Author from scratch 関数を選択して、名前を付けてください。前の手順で作成した IAM ロールを選択して、それを Lambda 関数にアタッチします。

- [関数の作成] を選択します。
- この Lambda 関数は、ネストされた JSON 文字列データを含むドキュメントを S3 から受け取ります。このデータを処理するには、この文字列から JSON を抽出して、ドキュメントとバケットの両方のキー名を取得する必要があります。次のステップで、関数はこの情報を使って中央ロギングアカウントバケットにデータをコピーします。この関数を作成するには、作成した Lambda 関数にこのコードをコピーして貼り付けます。バケット名を以前に作成したバケットの名前に置き換えます。分割方法を決定したら、後でこのスクリプトを変更します。
ステップ 4: S3 を Lambda イベントトリガーに設定する
このステップでは、リソースアカウントの S3 バケットにイベントトリガーを設定します。このトリガーは、AWS WAF ログによって記録されたファイル名と場所を Lambda 関数に送信します。トリガーはまた、新たに到着したファイルを中央ロギングバケットに移動させなければならないことを Lambda 関数に通知します。AWS WAF で監視する予定のアプリケーションを起動したすべてのリージョンに対してこの手順を繰り返します。
- S3 ダッシュボードに移動して S3 バケットを選択し、[詳細設定] の下の [プロパティ] をクリックし、[イベント] を選択します。

- イベントに名前を付けて、[イベント] チェックボックスから [PUT] を選択します。
- [送信先] オプションから [Lambda] を選択し、イベントの送信先として Lambda 関数を選択します。

ステップ 5: AWS WAF を Application Load Balancer に追加する
AWS WAF を Application Load Balancer に追加して、イベントのログ記録を開始できるようにします。 Lambda がコピーした後に、オプションで元のログファイルを削除できます。これによりコストは削減されますが、ビジネス上およびセキュリティ上のニーズにより、そのデータを保持する側で誤る可能性があります。
AWS Glue がそれらを適切に分割できるように、中央ロギングアカウントのバケット waf-central-logs の各リージョンに個別のプレフィックスを作成します。AWS Glue を使用したパーティション分割のベストプラクティスについては、「AWS Glue でのパーティション分割データの使用」を参照してください。AWS Glue はデータを取り込み、Amazon Athena でのクエリに最適化された列形式で保存します。これにより、データを視覚化して潜在的な攻撃を調査することができます。
AWS WAF で監視する予定のアプリケーションを起動したすべてのリージョンに対してこの手順を繰り返します。この手順では、このエクササイズに使用できる AWS WAF がすでに有効になっていることを前提としています。次のステップに進むには、AWS WAF を有効にして、ログ配信のため Amazon Kinesis Data Firehose に接続する必要があります。
AWS WAF のセットアップと設定
まだウェブ ACL を設定していない場合は、この時点で AWS WAF をセットアップして設定します。このソリューションは、複数のアカウントからの複数のリージョンでの複数の AWS WAF ログからのロギングデータを処理します。
これを効率的に行うには、データに対するパーティション分割戦略を検討する必要があります。セキュリティチームにネットワークの包括的なビューを与えることができます。Application Load Balancer に関連付けられている特定の AWS WAF の Kinesis Data Firehose 配信ストリームに基づいて各パーティションを作成します。この分割方法では、セキュリティチームがリージョン別およびアカウント別にログを表示することもできます。その結果、S3 バケット名とプレフィックスは次の例のようになります。
s3://central-waf-logs/<account_id>/<region_name>/<kinesis_firehose_name>/...filename...
ステップ 6: Lambda コードを使用してログをコピーする
この手順では、ログファイルのコピーを開始するように Lambda 関数を更新します。Lambda 関数を更新する際は、分割方法を念頭に置いてください。AWS WAF で監視する予定のアプリケーションを起動したすべてのリージョンに対してこの手順を繰り返します。
パーティション分割に対応するには、GitHub リポジトリの例と一致するように Lambda コードを変更します。
サンプルコードの <kinesis_firehose_name> を AWS WAF にアタッチされた Kinesis Data Firehose 配信ストリームの名前に置き換えます。<central logging bucket name> を、中央ロギングアカウントの S3 バケット名に置き換えます。
Kinesis Data Firehose は、正しいパーティション分割で、中央 S3 ロギングバケットへのファイルの書き込みを開始します。ログを生成するには、ウェブアプリケーションにアクセスします。
分析
Kinesis Data Firehose が収集したファイルをロギングアカウントの S3 バケットに書き込むことができるようになったので、中央ロギングバケットと同じリージョンのロギングアカウントに Elasticsearch クラスターを作成します。また、中央ロギングバケットが新しいログファイルを受け取るときに S3 イベントを処理するための Lambda 関数を作成する必要があります。これにより、集中ログファイルと検索エンジンの間に接続が確立されます。Amazon ES では、潜在的なセキュリティ上の脅威を探すために、すばやくログをクエリすることができます。Lambda 関数はデータを Amazon ES クラスターにロードします。Amazon ES には Kibana という名前のツールも含まれています。これはデータの管理と視覚化に役立ちます。
ステップ 7: Elasticsearch クラスターを作成する
- 中央ロギングアカウントで、AWS コンソールの Elasticsearch Service に移動します。
- [クラスターの作成] をクリックし、クラスターのドメイン名を入力して、[Elasticsearch バージョン] のドロップダウンから [バージョン 3] を選択します。[次へ] を選択します
 。この例では、クラスターにセキュリティーポリシーを実装せず、インスタンスを 1 つだけ使用します。実際の本番作業では、Elasticsearch Cluster を VPC 内に配置してください。
。この例では、クラスターにセキュリティーポリシーを実装せず、インスタンスを 1 つだけ使用します。実際の本番作業では、Elasticsearch Cluster を VPC 内に配置してください。 - ネットワーク設定の場合は、[パブリックアクセス] を選択し、[次へ] をクリックします。

- アクセスポリシーおよびこのチュートリアルでは、指定されたアカウント ID または ARN アドレスからのドメインへのアクセスのみを許可します。このケースでは、アカウント ID を使ってアクセスします。
- [次へ] を選択し、最後の画面で確認します。ドメインのために厳格なアクセスポリシーを作成したいけれども、パブリックアクセスを許可したくないのが一般的です。この例では、AWS のサービスの機能を簡単に説明するためにのみこの設定を使用します。本番環境ではこれをお勧めしません。
AWS が Amazon ES を終了してアクティブ化するのに数分かかります。稼働すると、2 つのエンドポイントが見えます。エンドポイントの URL は、クラスターにデータを送信するために使用する URL です。
ステップ 8: ログファイルをコピーするための Lambda 関数を作成する
中央ログバケットにイベントトリガーを追加します。このトリガーは、ログファイルから Amazon ES にデータを書き込むように Lambda 関数に指示します。S3 トリガーを作成する前に、ロギングアカウントにイベントを処理するための Lambda 関数を作成します。
この Lambda 関数では、aws-samples GitHub リポジトリのコードを使用して、S3 ファイルのデータを 1 行ずつ Amazon ES にストリーミングします。この例では amazon-elasticsearch-lambda-samples のコードを使用しています。新しい Lambda 関数に myS3toES という名前を付けます。
- 次のコードをコピーして js という名前のテキストファイルに貼り付けます。
- このコードをコピーしてテキストファイルに貼り付け、json という名前を付けます。
- これらのファイルが含まれているフォルダで次のコマンドを実行します。
> npm install - インストールが完了したら、js ファイルと node_modules フォルダを含む .zip ファイルを作成します。
- ロギングアカウントにログインします。
- .zip ファイルを Lambda 関数にアップロードします。[コード入力タイプ] には、[.zip ファイルのアップロード] を選択します。
- この Lambda 関数には、S3 との信頼関係を持つ適切なサービスロールが必要です。[信頼関係の編集] を選択し、信頼できるエンティティとして amazonaws.com と lambda.amazonaws.com を追加します。
- S3 読み取り専用権限と Lambda Basic Execution 権限を使用して IAM ロールを設定します。ロールに適切なアクセス権を付与するには、コンソールの Lambda 実行ロールセクションから Lambda 関数に割り当てます。

- Lambda 関数に環境変数を設定して、データの送信先がわかるようにします。[エンドポイント] を追加して、ステップ 7 で作成したエンドポイント URL を使用します。[インデックス] を追加して、インデックス名を入力します。[リージョン] の値を追加して、アプリケーションをデプロイしたリージョンを詳しく説明します。

ステップ 9: S3 トリガーを作成する
Lambda 関数を作成したら、その関数を実行するために S3 バケットにイベントトリガーを作成します。これで、Amazon ES へのログ配信パイプラインが完成しました。これは、S3 から Amazon S3 にデータをストリーミングするための一般的なパイプラインアーキテクチャです。
- 中央ロギングアカウントにログインします。
- S3 コンソールに移動してバケットを選択し、[プロパティ] ペインを開いてイベントまでスクロールします。
- [通知の追加] を選択して、新しいイベントに s3toLambdaToEs という名前を付けます。
- [イベント] の下で、[PUT] のチェックボックスをオンにします。プレフィックスおよびサフィックスはそのままにしておきます。
- [送信先] の下で [Lambda Function] を選択し、前のステップで作成した Lambda 関数の名前 (この例では myS3toES) を入力します。
- [保存] を選択します。
これが完了すると、Lambda は ウェブアプリケーションにアクセスするたびに Elasticsearch インデックスへのデータ送信を開始します。
ステップ 10: Amazon ES を設定する
これでパイプラインは自動的に Elasticsearch クラスターにデータを追加します。次に、Kibana を使用して、中央ロギングアカウントの S3 バケット内の AWS WAF ログを視覚化します。これが、フォレンジック調査アーキテクチャを組み立てる最後のステップです。
Kibana には、セキュリティチームがログデータを確認するのに役立つ視覚化とダッシュボードを作成するためのツールが用意されています。ログデータを使用して、IP アドレスでフィルタリングして、IP アドレスが毎月ファイアウォールに到達した回数を確認できます。これにより、使用量の異常を追跡し、潜在的に悪意のある IP アドレスを隔離することができます。この情報を使用して、そのような IP アドレスに対する保護を強化するウェブ ACL ルールをファイアウォールに追加できます。
Kibana は次のスクリーンショットのような視覚化を生成します。

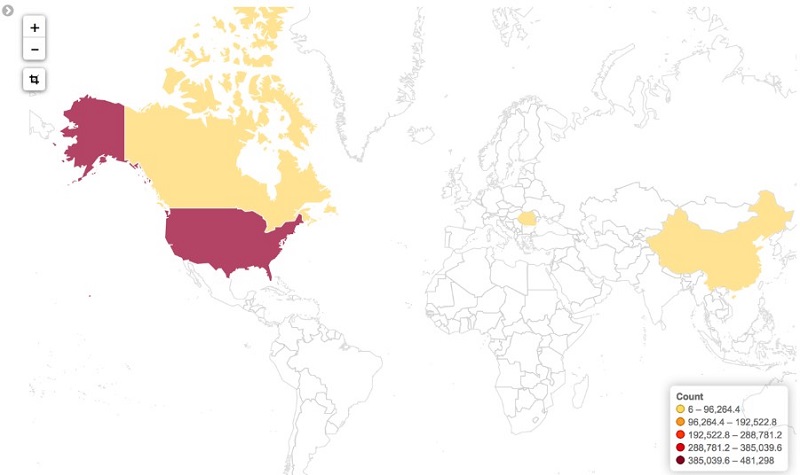
一定期間の IP 数の視覚化に加えて、IP アドレスをその発信元の国に関連付けることもできます。相関関係により、攻撃者から保護するために潜在的なウェブ ACL ルールに対するさらに正確なフィルタリングが行えます。そのデータの視覚化は次の図のようになります。
Elasticsearch の設定
AWS WAF データを設定して視覚化するには、「Amazon Elasticsearch Service を使用して AWS WAF ログを分析する方法」の記事の手順に従ってください。このソリューションを使用すると、孤立したリージョンではなくグローバルデータセットを調査できます。
Amazon ES の代用
Amazon ES は、大規模なデータセットに対して高性能な検索機能を提供するため、フォレンジック作業に優れたツールです。ただし、Amazon ES では、将来の成長に備えてクラスター管理と複雑なキャパシティプランニングが必要です。Amazon ES から最高のパフォーマンスを引き出すには、十分にスケーリングする必要があります。調査のより直接的なデータを使用して、代わりにより伝統的な SQL クエリを使うことができます。
フォレンジックデータは急速に増加するため、リレーショナルデータベースを使用すると、キャパシティをすぐに上回ってしまう可能性があります。代わりに、AWS Glue、Athena、Amazon QuickSight などの AWS サーバーレステクノロジーを利用することもできます。これらのテクノロジーにより、Elasticsearch やリレーショナルデータベースで発生する可能性のある運用上のオーバーヘッドなしに、フォレンジック分析が可能になります。このオプションの詳細については、「AWS Glue を使用した分析処理からのデータの抽出、変換、ロード方法」や「AWS Glue のパーティション分割されたデータを使用した作業」といった記事を参照してください。
Athena クエリ
フォレンジックツールが整ったので、Athena を使用してデータをクエリし、結果を分析できます。これにより、Kibana 視覚化のデータを調整したり、さらに視覚化するために Amazon QuickSight に直接読み込むことができます。視覚的なニーズに最適なクエリが得られるまで、Athena コンソールを使って試してみてください。データベースを AWS Glue Catalog に含めると、Athena でアドホッククエリを実行してデータを調べることができます。
Athena コンソールで、新しい [クエリ] タブを作成して、以下のクエリを入力します。
<your-database-name> と <your-table-name> をご使用の環境に適した値に置き換えます。 このクエリは、Presto 0.176 のドキュメントに従って、SQL を使用して数値のタイムスタンプを実際の日付形式に変換します。以下の結果が返されるはずです。
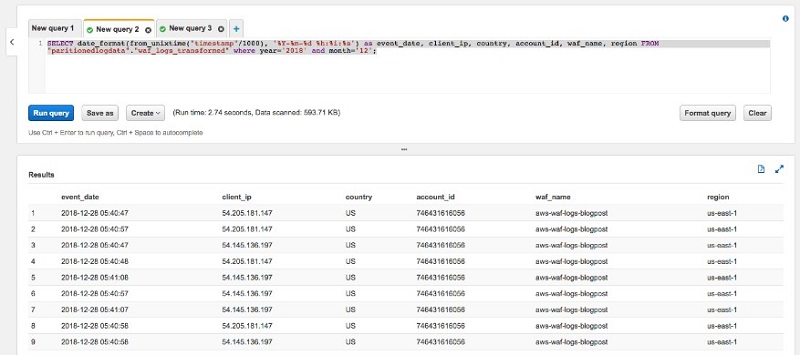
どの IP アドレスがどの期間でお使いの環境に最もヒットしたかがわかります。本番環境では、ETL ジョブを実行してこのデータを再分割し、それをクエリ用に最適化された列形式に変換します。それを行う詳細については、「AWS Glue で Athena を使用する際のベストプラクティス」の記事をご覧ください。
Amazon QuickSight の視覚化
Athena でデータをクエリできるようになったので、Amazon QuickSight を使用して結果を視覚化できます。まず、Athena クエリ結果が存在する S3 バケットへのアクセスを Amazon QuickSight に付与します。
- Amazon QuickSight コンソールでログインします。
- [管理者/ユーザー名]、[QuickSight の管理] を選択します。
- [アカウント設定]、[セキュリティと権限] を選択します。
- ccAWS のサービスへの QuickSight アクセスの下で、[追加または削除] を選択します。

- [Amazon S3] を選択してから、[S3 バケットの選択] をクリックします。

- 中央 AWS WAF ログの出力バケットを選択します。また、Athena クエリ結果バケットを選択します。クエリ結果バケットは aws-athena-query-results-* で始まります。
これで Amazon QuickSight がデータソースにアクセスできるようになりました。視覚化を設定するには、次の手順に従います。
- QuickSight コンソールで、[データの管理]、[新しいデータセット] を選択します。
- [ソース] には、[Athena] を選択します。
- 新しいデータセットに名前を付けて、[接続の検証] を選択します。
- 接続を検証した後、[データソースの作成] を選択します。

- [カスタム SQL を使用] を選択して、SQL クエリに名前を付けます。
- 先に Athena で使用したものと同じクエリを入力し、[クエリの確認] を選択します。

- [より迅速な分析のために SPICE にインポート]、[視覚化] を選択します。
Amazon QuickSight の処理が終わるまで数分待ちます。インポートが完了すると、その旨のアラートが表示されます。
データを分析にインポートしたので、次に視覚化を適用できます。
- Amazon QuickSight で、[新しい分析] をクリックします。

- 前に作成した最後のデータセットを選択して、[分析の作成] をクリックします。
- 画面左下で、[折れ線グラフ] を選択します。
- event_date を X 軸にドラッグアンドドロップします
- client_ip を値にドラッグアンドドロップすると、次の図のような視覚化が作成されます。

- 視覚化の左上にある右矢印を選択し、[「他の」カテゴリを隠す] を選択します。これにより、視覚化が次の図のように変更されます。

リクエストの発信元の国をマッピングして、グローバルアクセスの異常を追跡することもできます。QuickSight でこれを行うには、「マップ上のポイント」視覚化タイプを選択し、視覚化するデータポイントとしてその国を選択します。

特定の IP アドレスから発生した異常なアクセスパターンがあるかどうかを確認するために、IP アドレスの数を追加することもできます。

結論
Amazon ES と Amazon QuickSight は同様の最終結果をもたらしますが、この記事で強調した技術的アプローチにはトレードオフがあります。ユースケースでリアルタイムのデータ分析が必要な場合は、Amazon ES のほうがニーズに適しています。キャパシティプランニングやクラスター管理を必要としないサーバーレスアプローチを好む場合は、AWS Glue、Athena や Amazon QuickSight を使用したソリューションがより適しています。
この記事では、重要なメトリクスを追跡する運用ダッシュボードを簡単に構築する方法について説明しました。AWS Glue、Athena、および Amazon QuickSight を使用してこれを行うと、サーバーとインフラストラクチャの管理にかかる多大な負担が軽減されます。代わりにリアルタイムでメトリクスを監視するために、Amazon ES ソリューションは、わずかな運用上のオーバーヘッドでこれを実行する方法を提供します。ここで重要なのは、ソリューションの適応性です。さまざまなサービスを組み合わせることで、正確なニーズに合わせてさまざまなソリューションを問題に対応させることができます。
詳細とユースケースについては、以下のリソースを参照してください。
- AWS CloudFormation テンプレート (AWS WAF)
- Amazon ECS、AWS CloudFormation、および Application Load Balancer を使用したマイクロサービスのデプロイ
- Amazon S3 から Amazon ES へのストリーミングデータのロード
- Amazon Elasticsearch Service ドメインの VPC サポート
- Amazon QuickSight ML insight を使用して詐欺電話を検出する
この記事が役に立ち、紹介したソリューションが興味深いものであれば幸いです。AWS はフィードバックやコメントをいつでも歓迎します。
著者について
 Aaron Franco は、アマゾン ウェブ サービスのソリューションアーキテクトです。
Aaron Franco は、アマゾン ウェブ サービスのソリューションアーキテクトです。