Amazon Web Services ブログ
Amazon ElastiCache for Valkey の耐久性機能のお知らせ
本記事は 2026 年 6 月 2 日に公開された “Announcing durability for Amazon ElastiCache for Valkey” を翻訳したものです。
Amazon ElastiCache は数十万のお客様にサービスを提供し、Valkey、Memcached、Redis OSS のワークロード全体で毎秒数十億のリクエストをマイクロ秒のレイテンシーで処理しています。多くの組織では、ElastiCache のマルチ AZ レプリケーションと自動フェイルオーバーがレジリエンスの要件を満たしていますが、お客様がキャッシュだけでなく永続的なデータストアとして ElastiCache を採用するケースが増えるにつれ、データ損失が主要な懸念事項となっています。
本日、Amazon ElastiCache for Valkey の耐久性機能の提供開始を発表します。これにより、データ損失を許容できないワークロードに ElastiCache を使用できるようになります。
この記事では、耐久性がどのように機能するかを説明し、アーキテクチャを詳しく見ていき、耐久性が ElastiCache でお客様が期待するマイクロ秒単位のレイテンシーを損なわないことを示すパフォーマンス結果を共有します。
耐久性の仕組み
ElastiCache の耐久性は、マルチ AZ トランザクションログを使用して、インフラストラクチャ障害時の高速リカバリと再起動によるデータ保護を提供します。ElastiCache は 2 つの耐久性オプションを提供しています。ゼロデータ損失を設計した同期書き込みと、マイクロ秒単位の書き込みレイテンシーを実現する非同期書き込みです。
同期書き込みは、データ損失が許容できない場合に適した選択肢です。ElastiCache は、クライアントに応答する前に、マルチ AZ トランザクションログ内の少なくとも 2 つのアベイラビリティーゾーン (AZ) にデータを永続化します。確認応答された書き込みはすべて永続的であり、書き込みレイテンシーは 1 桁台のミリ秒です。プライマリノードは強い整合性を持ち、プライマリでの読み取り操作は常に最新のデータを返します。この整合性はフェイルオーバー時にも保持されます。同期書き込みは、RAG アプリケーション向けのナレッジベース、AI エージェントの長期メモリ、AI エージェントのワークフロー状態、決済トークン化、ストリーミングメタデータ、ゲームプレイヤーの状態、リアルタイム在庫管理など、書き込みの損失が誤ったアプリケーション動作を引き起こす場合に最適です。
非同期書き込みは、データが復旧可能であるものの、ソースからの再構築が遅い、または運用コストが高い場合に適した選択肢です。非同期書き込みでは、クライアントへの応答後にデータが Multi-AZ トランザクションログに永続化されるため、追加コストなしでマイクロ秒単位の書き込みレイテンシーを維持できます。万が一障害が発生した場合、最大 10 秒間のコミットされていないデータが失われる可能性があります。潜在的なデータ損失を制限するため、ElastiCache は耐久性ラグを監視します。これは、まだログに永続化されていない最も古い書き込みからの経過時間です。このラグが 10 秒に達すると、プライマリノードはログが追いつくまで書き込みの受け入れを停止します。非同期書き込みは、セッションストア、ゲームのリーダーボード、リアルタイム分析、事前ロードされたデータセットなど、数秒間の最近の書き込みを失うことは許容できるものの、より大きなギャップが生じると調整にコストがかかる場合に最適です。
耐久性を有効にしていない ElastiCache は、データがオンデマンドで簡単に再構築できる場合に適しています。元となるデータベースに基づくリードスルーキャッシュ、レート制限カウンター、または欠落したエントリをその場で取得または再計算できるワークロードに使用してください。
同期書き込みと非同期書き込みの両方で、マイクロ秒単位の読み取りレイテンシーが維持されます。いずれのオプションでも、レプリカノードは結果整合性を持ち、レプリカからの読み取り操作は常に最新の書き込みを反映するとは限りません。次の表に、2 つの耐久性オプションをまとめます。
| 同期書き込み | 非同期書き込み | |
| 標準的な読み取りレイテンシー | マイクロ秒 | マイクロ秒 |
| 標準的な書き込みレイテンシー | 1 桁ミリ秒 | マイクロ秒 |
| データ損失に関する保証 | データ損失ゼロ。確認された書き込みはすべて、少なくとも 2 つのアベイラビリティーゾーンにわたって永続化されます | 万が一障害が発生した場合、最大 10 秒間の確認された書き込みが失われる可能性があります。 |
| 一般的なユースケース | RAG アプリケーションのナレッジベース、AI エージェントの長期メモリとワークフロー状態、支払いトークン化、リアルタイム在庫管理 | セッションストア、ゲームリーダーボード、リアルタイム分析、事前ロード済みデータセット |
アーキテクチャ
次の図は、Multi-AZ のトランザクションログを使用した ElastiCache の耐久性がどのように機能するかを示しています。
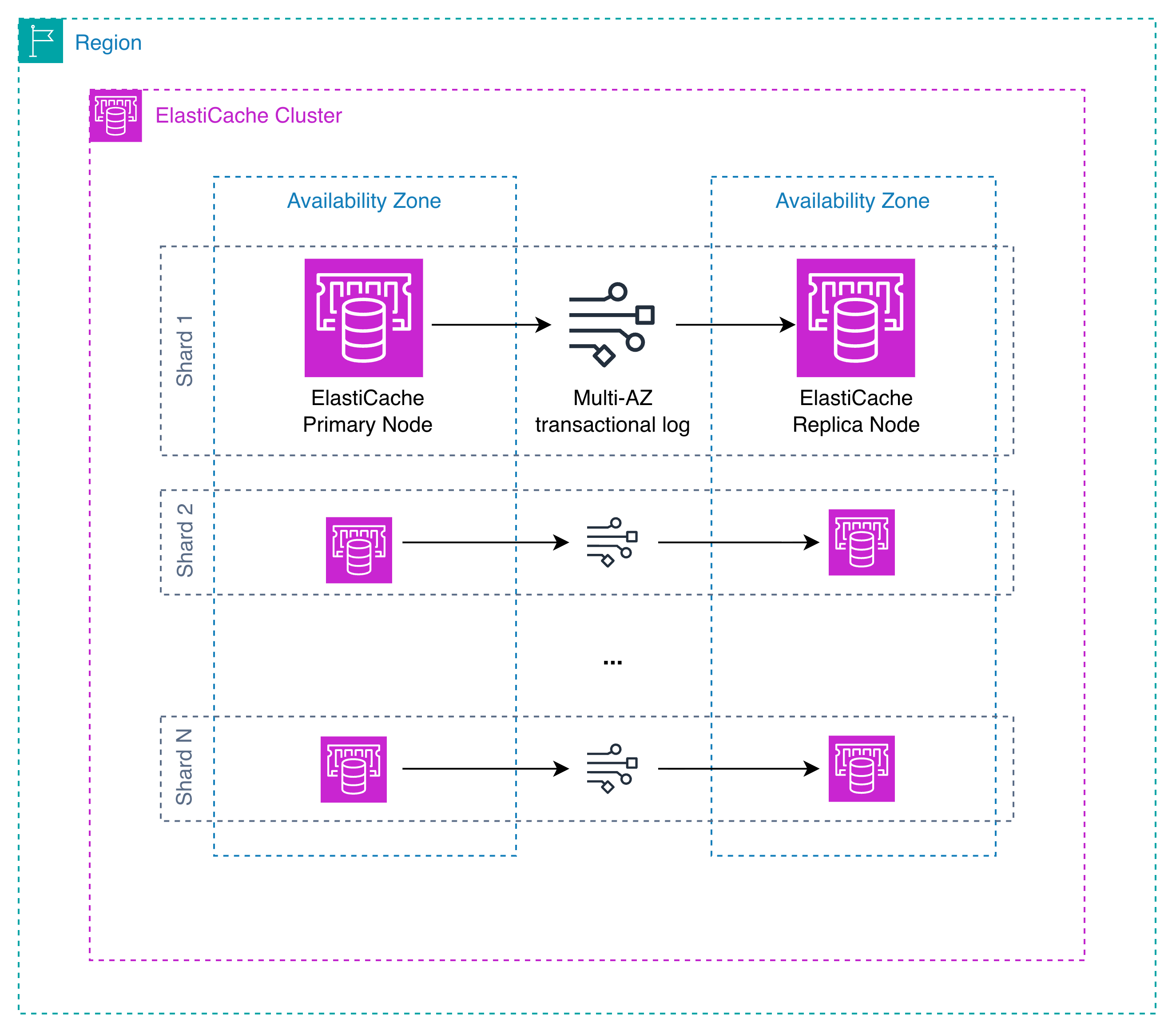
同期書き込み
同期書き込みが設定されたクラスターにクライアントが書き込みコマンドを送信した場合:
- プライマリノードがメモリ内で書き込みコマンドを受信して実行します。
- 書き込みは、少なくとも 2 つのアベイラビリティゾーンにまたがる Multi-AZ トランザクションログに永続化されます。
- 永続化が確認されると、プライマリはクライアントに成功レスポンスを返します。
これは、クライアントが成功レスポンスを受け取った後、その書き込みが永続化されることを意味します。プライマリノードがその直後に障害を起こしても書き込みは失われず、新しいプライマリへのフェイルオーバー後を含め、プライマリからの今後のすべての読み取りにその書き込みが反映されます。トレードオフは書き込みレイテンシーです。各書き込みはトランザクションログへの AZ 間ネットワークラウンドトリップが発生するため、数ミリ秒の書き込みレイテンシーが生じます。
非同期書き込み
非同期書き込みが設定されたクラスターにクライアントが書き込みコマンドを送信する場合:
- プライマリノードがメモリ内で書き込みコマンドを受信して実行します。
- プライマリはマイクロ秒のレイテンシーで即座にクライアントに応答を返します。
- バックグラウンドで、書き込みは Multi-AZ トランザクションログに書き込まれます。
クライアントが成功レスポンスを受信した時点では、書き込みはプライマリノードのメモリ内にのみ存在します。まだトランザクションログには書き込まれていません。書き込みが永続化される前にプライマリノードに障害が発生すると、その書き込みは失われます。これが非同期書き込みの基本的なトレードオフです。マイクロ秒単位の書き込みレイテンシーと引き換えに、データ損失が発生しうる限られた時間枠が存在します。
非同期書き込みの耐久性バッファ
非同期書き込みによる潜在的なデータ損失を制限するため、ElastiCache は最大 10 秒の耐久性バッファを強制します。プライマリノードは、受け入れられたがまだ Multi-AZ トランザクションログに永続化されていない最も古い書き込みの経過時間を継続的に追跡し、この値を DurabilityLag メトリクスとして Amazon CloudWatch に公開します。
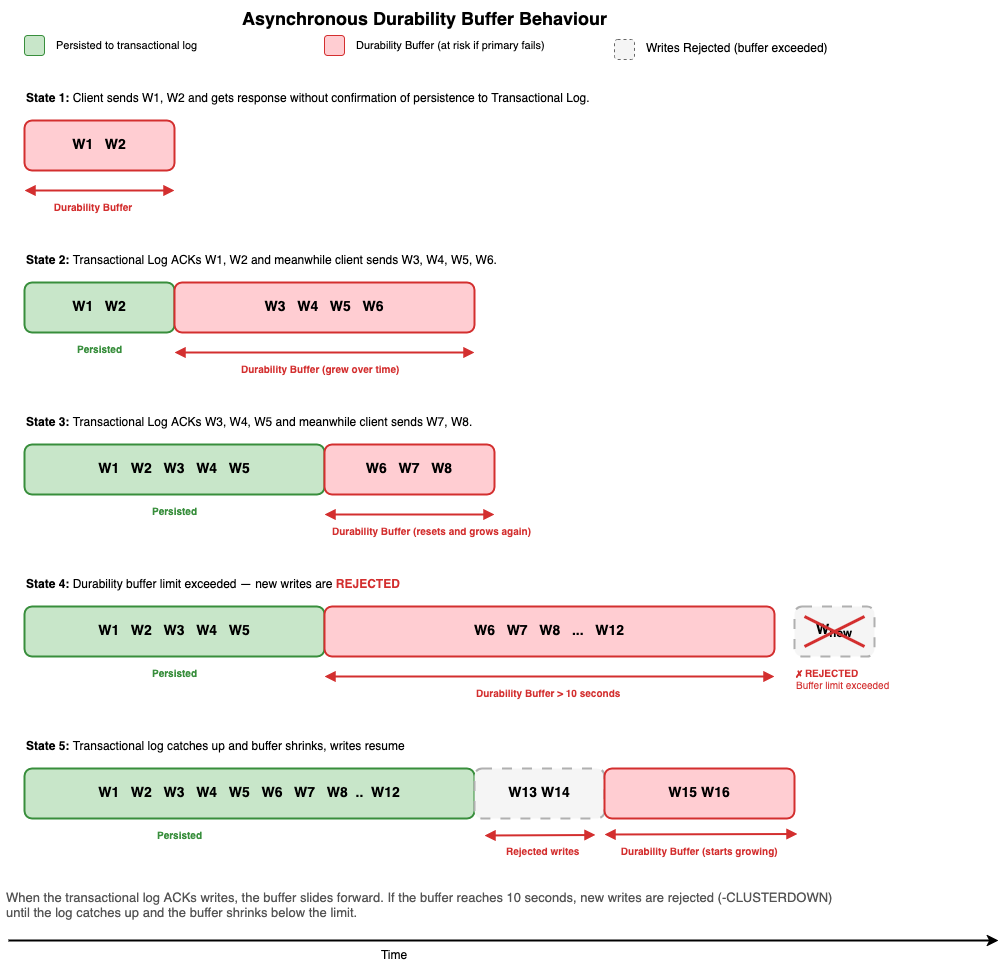
この経過時間が 10 秒未満である限り、ノードは通常通り新しい書き込みを受け入れ続けます。バッファが 10 秒を超えて増加した場合、例えばトランザクションログへの一時的なネットワーク輻輳が原因である場合、プライマリは追いつくまで一時的に受信する書き込みコマンドを拒否します。この期間中も読み取り操作はマイクロ秒のレイテンシーで提供され続けます。トランザクションログが追いつき、耐久性ラグがしきい値を下回ると、手動介入を必要とせず書き込みが自動的に再開されます。実際には、ほとんどの書き込みは 10 秒のしきい値内に十分永続化され、ほとんどのクラスターは通常の動作条件下で拒否状態に入ることはありません。非同期耐久性クラスターにトラフィックを送信するようにクライアントを構成する場合、一時的に拒否された書き込みコマンドに対して指数バックオフによる自動リトライを有効にすることをお勧めします。Valkey の公式オープンソースクライアントライブラリの 1 つである Valkey GLIDE をお勧めします。これは信頼性と高可用性を考慮して設計されています。GLIDE は指数バックオフによる自動リトライとアベイラビリティーゾーン認識ルーティングをサポートしています。クライアント構成のベストプラクティスについては、Best practices: Valkey/Redis OSS clients and Amazon ElastiCache を参照してください。
障害シナリオ
ElastiCache の耐久性は、以下の障害タイプから保護します。
- プライマリノードの障害。 プライマリノードに障害が発生した場合、ElastiCache は自動的にレプリカへのフェイルオーバーをトリガーします。レプリカはトランザクションログから追いつき、その後新しいプライマリとして書き込みを受け入れ始めます。障害が発生したノードは置き換えられ、ログから同期されます。同期書き込みでは、データは失われません。非同期書き込みでは、プライマリが障害を起こす前にトランザクションログにすべての書き込みが記録されていない可能性があるため、最大 10 秒間の確認応答済みの書き込みが失われる可能性があります。
- リードレプリカの障害。 リードレプリカに障害が発生した場合、障害が発生したノードは置き換えられ、選択された耐久性オプションに関係なく、Multi-AZ トランザクションログから同期されます。データ損失は発生しません。
- シャード全体の障害 (シャード内のすべてのノード)。 シャード全体に障害が発生した場合、すべてのノードが置き換えられ、Multi-AZ トランザクションログから同期されます。同期書き込みでは、データは失われません。非同期書き込みでは、最大 10 秒間の確認応答済みの書き込みが失われる可能性があります。コミットされたデータが復元された後、置き換えられたノードの 1 つが自動的に新しいプライマリとして選出されます。
パフォーマンス分析
ElastiCache の耐久性を有効にした場合と無効にした場合のスループットと読み取り/書き込みレイテンシーを測定し、それらを比較しました。その結果、ElastiCache で耐久性を有効にしても、お客様が ElastiCache に期待するマイクロ秒単位のレイテンシーが損なわれないことを実証しました。
テスト方法
r7g.4xlarge ノードを使用して、耐久性なし、同期書き込み、非同期書き込みの Valkey 9.0 for Amazon ElastiCache クラスターを起動しました。各クラスターは、1 つのプライマリノードと 1 つのリードレプリカで構成され、テスト実行前にサンプルデータが事前に投入しました。Valkey のデフォルトのパフォーマンス測定ツール (valkey-benchmark) を使用して、300 万個のキーでコマンドパイプラインなしで実行し、プライマリノードと同じ AZ 内の 10 個の Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを使用してクラスターにトラフィックを向けました。一般的なお客様のワークロードパターンを代表する混合ワークロード (80% 読み取り、20% 書き込み) を使用して、50K と 100K TPS の 2 つのスループットレベルでテストしました。ElastiCache クラスターはマルチ AZ 分散システムであるため、同一のセットアップでも下の表の数値からある程度のばらつきが観察される場合があります。
次の表は、r7g.4xlarge ノードにおけるすべての ElastiCache オプションの読み取りおよび書き込みレイテンシーを比較したものです。
| ワークロード (80% 読み取り、20% 書き込み) | ElastiCache オプション | ノードタイプ | 読み取り P50 | 読み取り P90 | 書き込み P50 | 書き込み P90 |
| 50K TPS | 耐久性機能なしの ElastiCache | r7g.4xlarge | 260 µ s | 301 µ s | 147 µ s | 185 µ s |
| 50K TPS | 非同期書き込み | r7g.4xlarge | 245 µ s | 289 µ s | 112 µ s | 152 µ s |
| 50K TPS | 同期書き込み | r7g.4xlarge | 245 µ s | 288 µ s | 2.15 ms | 2.36 ms |
| 100K TPS | 耐久性機能なしの ElastiCache | r7g.4xlarge | 263 µ s | 301 µ s | 160 µ s | 196 µ s |
| 100K TPS | 非同期書き込み | r7g.4xlarge | 245 µ s | 286 µ s | 128 µ s | 158 µ s |
| 100K TPS | 同期書き込み | r7g.4xlarge | 879 µ s | 992 µ s | 2.72 ms | 3.12 ms |
重要なポイント:
- すべてのオプションでマイクロ秒の読み取りレイテンシーを維持します。同期か非同期かに関わらず、耐久性は両方のスループットレベルでマイクロ秒の読み取りパフォーマンスを維持するため、実際のユースケースの大半を占める読み取り中心のワークロードに適しています。
- 非同期書き込みは、耐久性を有効にしていない ElastiCache と同等のレイテンシーを実現します。50K TPS と 100K TPS の両方で、読み取りと書き込みのレイテンシーはいずれもマイクロ秒レベルです。追加料金なしで耐久性を追加でき、一般的なワークロードレベルでのスループットへの影響はごくわずかです。データ損失ゼロを必要としないすべてのワークロードに対して、非同期書き込みをデフォルトとして推奨します。このオプションは、レイテンシーのペナルティなしで耐久性を提供します。
- 同期書き込みは、中程度のスループットでマイクロ秒の読み取りレイテンシーを維持します。50K TPS では、読み取りレイテンシーは 300 µ s 未満のままです。100K TPS では、システムがトランザクションログへのより高い並行性を処理するため、読み取りレイテンシーはサブミリ秒 (879 µ s) に増加します。書き込みレイテンシーは、両方のスループットレベルでミリ秒の 1 桁台に留まります。これは、書き込みを確認する前に 2 つのアベイラビリティーゾーンにデータを永続化するための予想されるトレードオフです。アプリケーションがデータ損失を一切許容できない場合は、同期書き込みを使用する必要があります。
ElastiCache の耐久性を使い始める
前提条件
始める前に、以下を確認してください。
- アクティブな AWS アカウント
- AWS CLI バージョン 2.x 以降がインストールおよび設定されていること
elasticache:CreateReplicationGroupとelasticache:ModifyReplicationGroupの IAM 権限
永続化クラスターの作成
耐久性を使い始めるには、新しい ElastiCache クラスターを作成し、AWS Management Console、AWS Software Development Kit (SDK)、または AWS Command Line Interface (CLI) を使用して、希望する耐久性オプションを選択する必要があります。
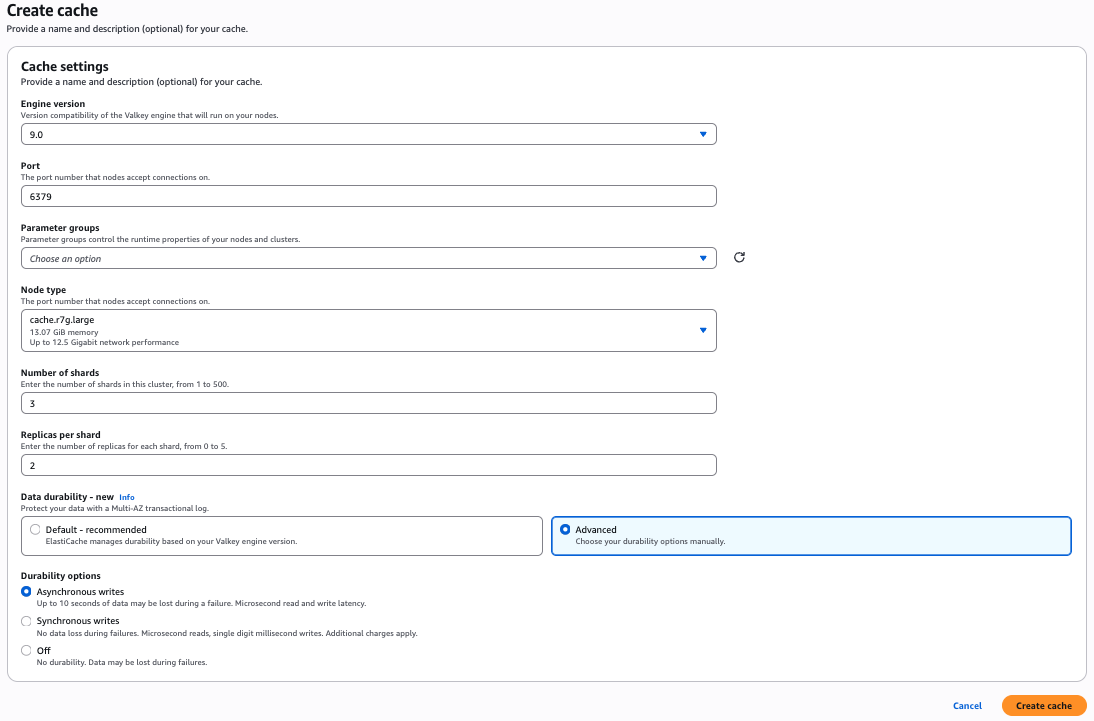
AWS マネジメントコンソールの使用
新しいクラスターを作成する際は、Valkey 9.0 以降を選択してください。クラスター設定で希望する耐久性オプションを選択します。
AWS CLI の使用
同期書き込みを使用する新しい耐久性のあるクラスターを作成するには:
非同期書き込みを使用するクラスターを作成するには、--durability async を設定します。
クラスターの検証
クラスターを作成した後、耐久性が有効になっている状態で実行されていることを確認できます。
出力には、ステータスが available として、選択した耐久性オプションが表示されるはずです。
耐久性オプションの切り替え
既存のクラスターを同期書き込みと非同期書き込みの間で切り替えるには、modify-replication-group を使用します。
クリーンアップ
継続的な料金が発生しないように、作成した ElastiCache クラスターを削除してください。
注意: この操作により、クラスターとすべてのデータが永久に削除されます。続行する前に、必要なデータをバックアップしていることを確認してください。
まとめ
ElastiCache の耐久性により、ElastiCache をキャッシングと永続的なデータストアの両方のユースケースで使用できます。同期書き込みは、マイクロ秒の読み取りレイテンシーと 1 桁ミリ秒の書き込みレイテンシーでデータ損失ゼロを実現するように設計されており、データ損失を許容できないワークロードに適しています。非同期書き込みは、追加料金なしで耐久性のない ElastiCache と同等のパフォーマンスを提供し、まれに障害が発生した場合に最大 10 秒の潜在的なデータ損失を許容できるワークロードに適しています。耐久性のない ElastiCache は、データをオリジンソースから再構築でき、書き込みの完全な可用性が最重要な従来のキャッシングワークロードに適した選択肢です。
ElastiCache の耐久性は、Valkey 9.0 から、すべての AWS 商用リージョン、AWS 中国リージョン、および AWS GovCloud (US) リージョンでご利用いただけます。料金の詳細については、Amazon ElastiCache 料金ページをご覧ください。詳細については、ElastiCache ドキュメントをご覧ください。
著者について
本記事は、Announcing durability for Amazon ElastiCache for Valkey を翻訳したものです。翻訳は Solutions Architect の Hayato Tsutsumi が担当しました。